
- 1. ビット演算による、与えられた文字列の中の全ての文字列(順序入れ替えなし)を出力するコード(Python)
- 2. 初心者の初心者による初心者のためのDjangoチュートリアルまとめ④
- 3. 言語処理100本ノック 2015をやったら結構Python基礎力がついた 第1章
- 4. for文 range
- 5. Homebrewのエラー
- 6. svmでtfidfとword2vecを比較してみたゾ!
- 7. [モデル構築編] ロイター通信のデータセットを用いて、ニュースをトピックに分類するモデル(MLP)をkerasで作る(TensorFlow 2系)
- 8. 【簡単】PythonでWikipediaをWebスクレイピングしてみよう【初心者向け】
- 9. Docker で作ったWebサーバ(app.py by Flask)を動かすテスト
- 10. ケモインフォマティクスで学ぶPythonのデータ構造
- 11. matplotlibで、2軸、3軸でグラフを描画する
- 12. popn music のプレイ動画から、譜面エディタで読める json ファイルを生成する
- 13. scikits.audiolabのインストール[Python]
- 14. pythonでMongoDB入門するときの設定
- 15. 初心者の初心者による初心者のためのDjangoチュートリアルまとめ③
- 16. 深さ優先探索
- 17. [前処理編] ロイター通信のデータセットを用いて、ニュースをトピックに分類するモデル(MLP)をkerasで作る(TensorFlow 2系)
- 18. for文の continue break else
- 19. Pythonで関数の引数型チェックをデコレータで実装する
- 20. while else
ビット演算による、与えられた文字列の中の全ての文字列(順序入れ替えなし)を出力するコード(Python)
ビット演算によって、与えられた文字列の中の全ての文字列を出力するコードです。Cで書いていましたが、日本語に対応させるため、pythonで書き直しました。
“`alice.py
#!/usr/bin/python3import sys
word=sys.argv[1]
K=1
N=len(word)
t=1def nextset(x):
smallest=x & -x
ripple = x + smallest
new_smallest = ripple & – ripple
ones =((new_smallest // smallest) >>1)-1
return ripple | onesdef printset(s):
for i in range(N):
if (s & 1):
print( word[i] , end=””)
s=s>>1
print(“”)def conv(k):
global t
x= (1 << (k)) -1 while True: if (x&~((1<
初心者の初心者による初心者のためのDjangoチュートリアルまとめ④
#はじめに
この記事はDjangoの公式チュートリアルを進めていくシリーズものです。
今回は4記事目「はじめての Django アプリ作成、その 4」を進めていきます。[初心者の初心者による初心者のためのDjangoチュートリアルまとめ①](https://qiita.com/sanpo_shiho/items/6f2fbfd9bd3a18414fe6)
[初心者の初心者による初心者のためのDjangoチュートリアルまとめ②](https://qiita.com/sanpo_shiho/items/4df3b31ea76775f4a918)
[初心者の初心者による初心者のためのDjangoチュートリアルまとめ③](https://qiita.com/sanpo_shiho/items/71b8cdd68d608897d103)#はじめての Django アプリ作成、その 4
###Write a minimal form
前回の記事で作成した`detail.html`内に投票のためのフォームを設置します。“`polls/templates/polls/detail.ht
言語処理100本ノック 2015をやったら結構Python基礎力がついた 第1章
# はじめに
今更ですが、Pythonの勉強がてら[言語処理100本ノック 2015](http://www.cl.ecei.tohoku.ac.jp/nlp100/)をやってみました。最初は何も見ずにやってみて、その後、他の方の100本ノックの書き方を参考に、より良い(スマートな)書き方でやり直してみます。より良い書き方の参考文献は最後にまとめて記載しています。
# 第1章: 準備運動
## 00. 文字列の逆順
文字列”stressed”の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.“`python:コード
input_str = ‘stressed’
result = input_str[::-1]
print(result)
“`“`:出力結果
desserts
“`### より良いコード
スライスのステップに負の値を設定すると末尾から見てくれる。これより大きく変わるのはなさそう。## 01. 「パタトクカシーー」
「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.“`python:コード
for文 range
0から9まで出力させたい場合
“`python:めんどくさい
num_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]for num in num_list:
print(num)
“`
だとめんどくさい。。。“`py:range
for num in range(10):
print(num)
“`
の方がいい。2から9まで出力させたい場合は、
“`py:2から9まで
for num in range(2, 10):
print(num)
“`2から9までで3差で出力させたい場合は、
“`py:2から9までで3差
for num in range(2, 10, 3):
print(num)
“`“`:2から9までで3差の実行結果
2
5
8
“`Helloを10回出力させたい場合
“`py:Hello10
for i in range(10):
print(‘Hello’)
“`iも一緒に出力させる場合は
“`py:Hello10_index
for i
Homebrewのエラー
### Python update時、venvをリセットする時でたエラー
“`
$ brew cleanup
“`
で下記のWarningがありました。
`Warning: Skipping python: most recent version 3.7.6_1 not installed`—-
アップデートします。“`
$ brew upgrade
“`
で下記のエラー…
“`Traceback (most recent call last):
4: from /usr/local/Homebrew/Library/Homebrew/brew.rb:23:in `‘
3: from /usr/local/Homebrew/Library/Homebrew/brew.rb:23:in `require_relative’
2: from /usr/local/Homebrew/Library/Homebrew/global.rb:13:in `‘
1: from /System/Library/Frame
svmでtfidfとword2vecを比較してみたゾ!
# はじめに
前回の記事の続きです。
https://qiita.com/teri/items/bc4e04316a1b14ae8365# 前回の概要と考察
前回は、tfidf、svmを用いて、分類器を作りましたが、学習データにある単語を含めた文章については、期待通りの分類をしてくれました。しかし、学習データにない単語を含めた文章の分類は、期待通りには分類してくれませんでした。
この事象について、考えたのですが、tfidfの言語モデルは、分類器に用いる学習データと同じのデータを使う必要があるので、学習データの量が少ないと、ベクトル化に影響する単語が少なくなるんだと思うんですよ。(結局、データ量って大事なんですよね。。。)
# tfidfとword2vecを比較をしてみたい
前回は、tfidfを使いましたが、今回はword2vecを使った分類器を作って、結果を比較したいと思います。
word2vecはtfidfと違って、分類器の学習データと同じのデータを使う必要がないので、事前に大量のデータを学習させたword2vecの言語モデルを用いれば、色んな単語に対応させることができ
[モデル構築編] ロイター通信のデータセットを用いて、ニュースをトピックに分類するモデル(MLP)をkerasで作る(TensorFlow 2系)
## 前回の前処理編!
この記事は[前処理編]に続く続編です。
[[前処理編] ロイター通信のデータセットを用いて、ニュースをトピックに分類するモデル(MLP)をkerasで作る(TensorFlow 2系)](https://qiita.com/ftnext/items/236145fa41a5e464463e)動作環境についても前処理編をご参照ください。
## モデルの学習
前処理をしたニュース記事のテキスト`x_train`とニュースのラベル`y_train`を使ってモデルを作ります。
今回は単純なモデルとして、2層のMLP(マルチレイヤーパーセプトロン)とします。
“`
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 512) 512512
________
【簡単】PythonでWikipediaをWebスクレイピングしてみよう【初心者向け】
こんにちは。
せら⇒だいひょー?です。
僕のTwitterアカウント
(https://twitter.com/seradaihyo)
では、未経験からエンジニアを目指す方に向けて日々発信しています。
今回はPythonでWikipediaのスクレイピングを行う方法を記事にしたいと思います。
それでは始めていきましょう。
**Pythonでスクレイピングをする上で必ず使うサードパーティ製ライブラリが二つあります。**
それが
**・Requests**
**・BeautifulSoup**です。
それぞれ簡単に説明すると、
**Requests
⇒URLを開くためのライブラリ****BeautifulSoup
⇒HTMLからデータを抽出する**といった感じです。
Requestsでページを開いて、BeautifulSoupでデータを取ってくるイメージです。
Pythonコードの先頭に、この二つのライブラリをインポートするためのコードを書いておきます。
“`python:wikipedia.py
import requests,bs4
Docker で作ったWebサーバ(app.py by Flask)を動かすテスト
Docker を使って、GCPを使って、いろいろやりたいなー、と思っていましたが、冬休みももう終わりそうです。
Docker の使い方がメインで、できたのは以下です。
1. Dockerfile を書く
2. Docker image を作る (docker build)
3. ローカルで動かす (docker run)
4. ローカルで確認 (localhost をWEBブラウザで見る)サーバとして動いているのは、下記のContainer で動いているものです。

## 1. Dockerfile とsource file の用意
こんな`Dockerfile`を作りました。
“`dockerfile
# our base image
FROM ubuntu# Install python
ケモインフォマティクスで学ぶPythonのデータ構造
# はじめに
[ケモインフォマティクスで学ぶPythonの変数とデータ型](https://qiita.com/yukiya285/items/2e800179fcf06aab0fb9)に引き続き、リピドミクス(脂質の網羅解析)を題材として「データ構造」について解説していきます。
ケモインフォマティクスの実践例を中心に説明していきますので、基本を確認したいという人は以下の記事を読んでからこの記事を読んでみてください。[製薬企業研究者がPythonのデータ構造についてまとめてみた](https://qiita.com/yukiya285/items/207b0096b01dc8cc81a9)
# リスト
## リストの作成、要素の値の参照、更新
リスト(list)は、複数の要素を格納したデータ型で、`リスト名 = [要素1, 要素2, ・・・]`で作ることができます。
以下の例は文字列のみを格納したリストですが、数値や真偽値を入れることもできますし、同じ値の要素を複数入れたり、複数のデータ型を混在させたりすることもできます。
リストの中の要素は、`リスト名[インデックス番号
matplotlibで、2軸、3軸でグラフを描画する
# テスト用データ
“`
x=[0,1,2,3]
y1=[1,2,3,4]
y2=[10,25,30,45]
y3=[150,200,350,400]
“`# 2軸でプロット
### ソース
“`
import matplotlib.pyplot as pltfig, ax1 = plt.subplots( )
ax1.plot(x,y1 ,”b-“)
ax1.set_ylabel(“y1”)ax2 = ax1.twinx()
ax2.plot(x,y2 ,”r-“)
ax2.set_ylabel(“y2”)plt.show()
“`
### 結果
### 参考
[Different scales on the same axes](https://matplotlib.org/gallery/subplots_
popn music のプレイ動画から、譜面エディタで読める json ファイルを生成する
# やりたいこと
ポップンミュージックの録画台で録画したプレイ動画から、譜面エディタ(ぽぷどろ)で読み込める譜面データ (json) を生成します。(注:ぽぷどろを作られている方と筆者は無関係です。ただ使わせていただいているだけです(感謝))
こんな感じの動画を入力にして、
“`sample.json
{
“version”: 3,
“bpm”: 111,
“hsp”: 5.8,
“notes”: [
{“frame”: 0, “pixel”: 34, “color”: 5, “timing”: 0, “measure”: 1},
{“frame”: 1, “pixel”: 11, “color”: 5},
{“frame”: 2, “pixel”: 21, “color”: 5},
{“frame”: 3, “pixel”: 31, “color”: 5},
{“frame”: 4, “pixel”: 42,

scikits.audiolabのインストール[Python]
ハマったので自分用にメモ。
## scikits.audiolab
MATLABライクな記法でwavの読み書きが可能なPythonモジュール。
[scikits.audiolab · PyPI](https://pypi.org/project/scikits.audiolab)
## 環境
– OS: macOS Mojave 10.14.6
– Python: 2.7.17以下は先にインストールしておく
– Homebrew
– pip(Python)## 手順
1. libsndfileとPySoundFileのインストール
scikits.audiolabはlibsndfileのラッパーになっているので、libsndfileがないとインストールできません。
~~~ Terminal
$ brew install libsndfile
$ pip install PySoundFile
~~~1. scikits.audiolabのインストール
~~~
$ pip install scikits.audiolab
~~~以上です?
## 参考
[P
pythonでMongoDB入門するときの設定
データ解析用によく使われているデータベースMongoDBの設定方法を記録しています。
# ダウンロード
ダウンロードリンク → https://www.mongodb.com/download-center/community
# インストールの設定
パスの設定は `C:\mongodb` に設定(`C:\Program Files` ではない)インストールは `Complete`ではなく `Custom` に設定、`Cドライブ`の下に新しいフォルダーを作る。↓
[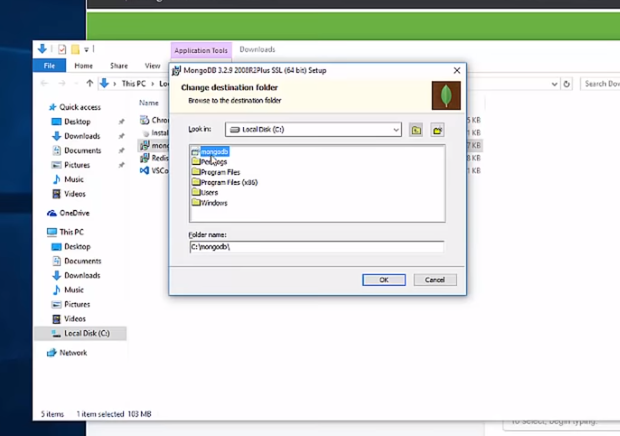](https://gyazo.com/8f63c07e1db35f02941a00c343ff0c7d)インストールは約5分かかる。
インストールができたら、`C:\mongodb\data`フォルダーを作っておいてください。
# サーバーを起動する方法
`cd C:\mongodb\bin` でダイレクトリーを移動し、
(
初心者の初心者による初心者のためのDjangoチュートリアルまとめ③
#はじめに
この記事はDjangoの公式チュートリアルを進めていくシリーズものです。
今回は3記事目「はじめての Django アプリ作成、その 3」を進めていきます。[初心者の初心者による初心者のためのDjangoチュートリアルまとめ①](https://qiita.com/sanpo_shiho/items/6f2fbfd9bd3a18414fe6)
[初心者の初心者による初心者のためのDjangoチュートリアルまとめ②](https://qiita.com/sanpo_shiho/items/4df3b31ea76775f4a918)#はじめての Django アプリ作成、その3
https://docs.djangoproject.com/ja/3.0/intro/tutorial03/###もっとビューを書いてみる
`polls/views.py`に追記します。“`polls/views.py
def detail(request, question_id):
return HttpResponse(“You’re looking at questi
深さ優先探索

具体例として上記の木に対して深さ優先探索をする“`Python3
#python3
#sys.setrecursionlimit(10000) #再帰の回数上限変更 (デフォルト1000回)# 各ノードから,どのノードにエッジ(枝)が伸びているか調べてリスト化する
edge = [[1, 2], [0, 3, 4], [0, 5], [1], [1], [2]]def dfs(now, before=-1):#before:直前に通ったノード
if before==-1:
print(now)
for c in edge[now]: #c:子
if not c ==before: #無限ループを防ぐ
print(c)
dfs(c, now
[前処理編] ロイター通信のデータセットを用いて、ニュースをトピックに分類するモデル(MLP)をkerasで作る(TensorFlow 2系)
## 概要
`keras`を使ったテキスト分類を試し、記事にまとめます。
データセットは`tensorflow`に内蔵されたロイター通信のデータセットです(英語のテキストデータ)。[Keras MLPの文章カテゴリー分類を理解する](http://cedro3.com/ai/keras-mlp-reuters/) というブログ記事を参考に、一度取り組んだことがあります。
今回はドキュメントを引きつつ手を動かしており、理解を深める目的でこの記事をアウトプットします。
構築したモデルは、非常にシンプルなMLPです。分量が長くなったので2つに分けます:
– 本記事で扱うこと
– データセットについて
– 前処理について
– 次の記事で扱うこと
– モデルの学習について
– モデルの性能評価について## 動作環境
“`console
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.14.6
BuildVersion: 18G103
$ python -V # venvモジュールによる仮想環境を利用
Python
for文の continue break else
“`py
players = [‘勇者’, ‘戦士’, ‘魔法使い’, ‘僧侶’]
for player in players:
print(player)
“`“`:実行結果
勇者
戦士
魔法使い
僧侶
“`“`py:無理やりwhile文で書くと
players = [‘勇者’, ‘戦士’, ‘魔法使い’, ‘僧侶’]
i = 0
while i < len(players): print(players[i]) i += 1 ``` ```py:else players = ['勇者', '戦士', '魔法使い', '僧侶'] for player in players: print(player) else: print('終了') ``` ```:elseの実行結果 勇者 戦士 魔法使い 僧侶 終了 ``` ```py:break players = ['勇者', '戦士', '魔法使い', '僧侶'] for player in players: if player == '魔法使い':
Pythonで関数の引数型チェックをデコレータで実装する
# 概要
自作関数に引数の型チェックを実装する際にデコレータとアノテーションを利用して実装する。
これがあればデコレートするだけで型チェックができるね!# 偉大なる先人
[Python関数の引数と返り値の型をチェックするデコレータ](https://qiita.com/calderarie/items/025b769b616e67fccf35)
↑やりたかったことはほぼこれです。
python3.6系でエラーになっていたので一部修正とアノテーション周りの整備をしてみました。
また、返り値のチェックは不要だったので削除しています。# デコレータの実装
今回の型チェックの実装は以下とします。– 関数の引数について型チェックを行う
– アノテーションで型が指定されている引数をチェック対象とする
– アノテーションがコメントだったり、ない場合はスルーする“` python
import inspect
import functoolsdef args_type_check(func):
@functools.wraps(func)
def args_typ
while else
“`python:1
count = 0while count < 5: print(count) count += 1 else: print('終了') ``` ```:1の実行結果 0 1 2 3 4 終了 ``` ```py:2 count = 0 while count < 5: if count == 2: break print(count) count += 1 else: print('終了') ``` ```:2の実行結果 0 1 ``` breakはwhile文全体から抜ける。 なので、 whileと組み合わされたelse以下は breakで抜けなければ実行される。




