
- 1. Pythonのいろんなfor文まとめ
- 2. Django2.xからDjango3.xでの変更点(かもしれない)の報告:静的ファイルのタグ書き換え・HttpResponseRedirectの指定方法
- 3. [Python]セミラグランジュ法のメソッド
- 4. 【Python】0で穴埋めするときに必要な桁数を計算する【メモ書き】
- 5. 【Python】MAEとRMSEの計算方法
- 6. 【Python】YouTubeの動画URLから動画IDを取り出す【メモ書き】
- 7. [Python] Travis CI と CodeClimate を使って unittest の coverage を算出
- 8. 最新物理ベースレンダラー Mitsuba2を触ってみる (2) Pythonから動かす編
- 9. 講義で書いたPythonのコードをまとめてみた その2
- 10. [PyTorch]modelとdatasetがcudaモードになっているか確認する
- 11. RaspberryPi で NFC RFID-RC522 を Python3 で使う
- 12. YouTubeコピペスパムを抽出する(モデレータなら自動ブロック?)
- 13. Kaggle Titanic data set – Top 2% guide (Part 04)
- 14. 1.【準備編】NNの使い方を身につけよう!
- 15. Heroku、Flask、Python、にゃん子掲示板をデータベースで作る(その①)
- 16. Python セイウチ演算子で複数行ラムダ
- 17. AtCoder ABC43(ARC59) C,D問題
- 18. Flask-Babelで多言語化をやってみる
- 19. 「コロナ」に関するツイートをpythonで収集して、「コロナ」の影響で話題になった単語を自動検出する
- 20. PythonのプロジェクトをTeamcityで自動テストする
Pythonのいろんなfor文まとめ
## ■基本形
### i=0始まりでn回回す“`input.py
n = 5
for i in range(n):
print(i)
“`
“`output.py
0
1
2
3
4
“`
### i=xから(y-1)まで
“`input.py
x = 1
y = 4
for i in range(x,y):
print(i)
“`“`output.py
1
2
3
“`## ■文字列
### 一文字ずつ取り出す“`input.py
for char in ‘string’:
print(char)
“`“`output.py
s
t
r
i
n
g
“`## ■リスト型
### 要素1つずつ取り出す“`input.py
list = [‘a’,’b’,’c’]
for a in list:
print(a)
“`“`output.py
a
b
c
“`## ■辞書型
### 要素1つずつ取り出す
“`input.py
dict = {‘key1′:’val1’, ‘key2
Django2.xからDjango3.xでの変更点(かもしれない)の報告:静的ファイルのタグ書き換え・HttpResponseRedirectの指定方法
# 経緯
半年ぶりくらいにDjangoを触ったらバージョンが3になってました。更新速いっ!
で、昔作ったプロジェクトをカスタムしてたらエラーが何個か出たので、変更点っぽいのでDjango扱うかたに有益かもしれないので、共有します。# 環境など
Django==2.0.4
で作ったプロジェクトをカスタムして、
Django==3.0.4
で構築した時の気づきPython==3.6.1 (3.7だとエラーが出てしまう。今後要解析。)
# 1 静的ファイル取り扱いタグが昔の奴が使えなくなっていた
“`
TemplateSyntaxError at /
‘staticfiles’ is not a registered tag library. Must be one of:
“`というエラーが出ました。タグを直すだけで直ります!
“`
このタグを
{% load staticfiles %}↓のように直します
{% load static %}
“`# 2 HttpResponseRedirectの飛ぶ先の指定が変わったかもしれない。
NoRever
[Python]セミラグランジュ法のメソッド
移流方程式解くプログラムがネット上に少なかったのと、メソッド化されているものは日英で探した時に無かった(もしくはバグってるやつ)ので作りました。
“`python
#https://github.com/christian512/SemiLagPy/blob/master/advection1D.ipynb
#これを参考にした。import numpy as np
import matplotlib.pyplot as pltclass SemiLagrangian1D:
“””
SemiLagrangian scheme for periodic 1D problems.
“””
def __init__(self,x,y,u,dt):
“””
Initizalizes the SemiLagrangian object given initial configuration
x : x positions (must be equidistant)
y : variable
【Python】0で穴埋めするときに必要な桁数を計算する【メモ書き】
`log`を高校で習ったときに`log`っていつ使うねん!って思ってたら使いどきあったのでメモメモ。
“`python
import mathlist = [1,2,3,4,5,6,7,8,9,10,11]
number_of_val = len(list)
number_of_padding_zero = math.ceil(math.log10(number_of_val))
format_pattern = ‘{:0’+ str(number_of_padding_zero) +’d}’for i,val in enumerate(list):
serial_number = format_pattern.format(i)
print(serial_number)
“`実行結果:
“`
00
01
02
03
04
05
06
07
08
09
10
“`連番でファイル出力するときに0で穴埋め(ゼロパディング)するということを想定。
テスト用なのでコード中の`list`には数字入ってますが、ファイルパスとかが入ってると思ってください。
出力
【Python】MAEとRMSEの計算方法
###目的
Pythonを使って平均絶対誤差(Mean Absolute Error:MAE)と二乗平均平方根誤差(Root Mean Squared Error:RMSE)を計算する。記事は[こちら](https://www.aiprogrammers.net/entry/2020/03/09/021517)にまとめました。
【Python】YouTubeの動画URLから動画IDを取り出す【メモ書き】
# まえがき
YouTubeの動画URLを取り出す手法についてはいくつもの記事が上がっているが、「共有」ボタンを押したときに生成される`https://youtu.be/`で始まる短縮URLへの対応や、URLクエリパラメータ(例えば時間を指定する`t=15`や短縮URLからの転送を示す`feature=youtu.be`など)を含む場合は考慮されてないものばかりな気がしたのでここにメモとして書いてみる。
ちなみに、再生開始位置を示すYouTubeのURLクエリパラメータ`t`は、
`https://youtu.be/r4Mkv-q4NmQ?t=5437`や
`https://youtu.be/r4Mkv-q4NmQ?t=5437s`のように
全て秒数で指定するのはもちろん、
`https://youtu.be/r4Mkv-q4NmQ?t=1h30m37s`のように
`◯h△m□s`とすると「◯時間△分□秒」から再生開始するURLになるぞ!
※もちろん、`◯h`を省略して`△m□s`とするのも可。尚、この記事内のYouTubeのURLは基本的に私の投稿動画やチャン
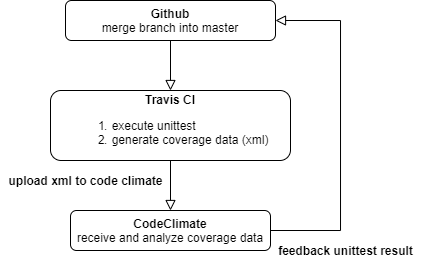
[Python] Travis CI と CodeClimate を使って unittest の coverage を算出
# 概要
[CodeClimate](https://codeclimate.com/) のサービスの1つである test coverage 機能を使おうとしたのですが、予想以上に設定に手こずったので、記事にしておこうと思いました。
ネット上で掲載されている記事と環境が一部違ったりして辛かった…
# 対象者
* Travis CI は既に使えている
* CodeClimateについては、コード品質チェックまではできる
* CodeClimateのtest coverage機能がなぜか動かない…設定がおかしいのかな?という方!(ものすごく限定的です)
## イメージ画像
CodeClimateへの通信経路のイメージを書いてみました。
## environment
|項目||
|:–|:–|
最新物理ベースレンダラー Mitsuba2を触ってみる (2) Pythonから動かす編
# Mitsuba2とは
アカデミック向けのフリーの物理ベースレンダラー。微分可能レンダリングや偏光レンダリングなどの新機能がある。
この記事は[最新物理ベースレンダラー Mitsuba2を触ってみる(1) 導入編](https://qiita.com/kurilab/items/34089636fa570d9a7939)の続きになります。
Mitsuba2のインストールまで終わっているという前提です。
# PythonからMitsuba2を動かす
[公式でも書かれているように](https://mitsuba2.readthedocs.io/en/latest/src/python_interface/intro/)Mitsuba2は非常に強力なPythonバインディングを提供していて、ほぼすべての機能をPythonから

講義で書いたPythonのコードをまとめてみた その2
# はじめに
今回もPythonで解いていきます。
書くことないので早速ゴー。## 問題とコード
ゲームでよくあるガチャについて考える。
このガチャは引くたびに1/nで当たりが出るものとする(nは与えられた自然数)。
k回引いた場合に、少なくとも1回は当たりが出る確率はいくらだろうか。
N君はこれを以下のように考えた。
「k回全てが外れである確率が
$$
(\frac{n-1}{n})^k
$$
だから、少なくとも1回は当たりがでる確率Pkは$$
P_k = 1 – (\frac{n – 1}{n})^k
$$
である。x = 1/nとおくと、$$
P_k = 1 – (1 – x)^k
$$となる。xは小さいのでテイラー展開を使って以下のように概算できる。
$$
P_k = 1 – (1-x)^k
\approx 1 – (1 – kx)
= kx
\approx \frac{k}{n}
$$ここでk = nとおくと、
$$
P_k \approx 1
$$
となる。これは「確率(1/n)のがちゃをn回引くと、1回くらいは当たりがでる
[PyTorch]modelとdatasetがcudaモードになっているか確認する
# はじめに
PyTorchはテンソルに対して“`hoge.to(device)“`などで簡単にcpuとgpuモードを切り替えられますが,よくこのデータセットやモデルがcpuかgpuなのかわからなくなったので,確認する方法を書き残しときます.## 確認方法
前提としてデータセットとモデルの準備は“`python
IMAGE_SIZE=224
BATCH_SIZE=20
TRAIN = ‘train’
DATA_DIR = ‘dataset/predata/’
DEVICE = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)data_transforms = {
TRAIN: transforms.Compose([
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor(),
])
}# データの前処理
image_datasets = {x: datasets.ImageFolder(os.p
RaspberryPi で NFC RFID-RC522 を Python3 で使う
NFCでやってみた実験一覧
– Felica でつくる簡単な入退室管理 (Rasbpberry Pi に複数台のカードリーダ)
– https://qiita.com/nanbuwks/items/e0988d8fec131baa579d
– RaspberryPi で NFC RFID-RC522
– https://qiita.com/items/c502ba880fbb93f522b3
– element14 の EXPLORE-NFC-WW で NFC 試してみる
– https://qiita.com/items/0c436941a0c5f0a257b1
– Arduino ESP32 と STM32 で NFC RFID-RC522
– https://qiita.com/nanbuwks/items/96c3c2d2af2cf97f3797# NFC RFID-RC522 格安モジュール
## 搭載チップ
NXP MFRC522
https://www.nxp.com/docs/en/data-sheet/MFRC522.pdfN
YouTubeコピペスパムを抽出する(モデレータなら自動ブロック?)
# 目的
最近、Vtuberの生配信を見ていると、下品なユーザ名がチャット欄に散見されることが多くなりました。注意深く見てみると、彼らには次の特徴があることがわかります。– 前述通り、ユーザ名がお下品
– 過去のコメントをコピペしているらしい
– そのため「コピペスパム」と呼ぶことにします
– コピペコメントには絵文字が追加される害があるかと言われると微妙なところです。コピペスパムがわきすぎるとグロテスクだとか、配信者のコメ拾いを阻害し得るとかでしょうか。
個人的にすごく邪魔に感じるので、本記事を書くに至りました。#概要
コピペスパムの特徴を利用して抽出したい。
そのためには、以下の手順を踏む必要があります。1. 本記事ではPython 3.6.2で実装
– 使用ライブラリはtime, requests, json, pickle
– pickleは取得したチャット欄の情報を保存するのに使用
– YouTube API利用のため、APIキーを取得する
– YouTube配信枠のURLからidを取得する
– id : YouT
Kaggle Titanic data set – Top 2% guide (Part 04)
*本記事は @qualitia_cdevの中の一人、@nuwanさんに作成して頂きました。
*This article is written by @nuwan a member of @qualitia_cdev.##Part 04
####Data analyzing and feature engineering : cont.######Deck
We got the Deck feature utilizing the Cabin feature. We removed the numbers from the Cabin feature and only kept the Alphabet letter.“`titanic_demo.py
data = combined_df[combined_df[“Survived”].notnull()]
fig, ax = plt.subplots(2 ,2, figsize=(16,10))sns.catplot(x=’Deck’, y=’Survived’, data=data, kind=’bar’, ci=
1.【準備編】NNの使い方を身につけよう!
# はじめに
少し前から機械学習、特にディープラーニングの勉強をしています。理解を深めるには自分でコーディングしてみるのが良い、と考え慣れ親しんできたObjective-Cで色々とコーディングしてみました。ある程度理解できてCNNによる手書き数字認識ができ、次に何をしようか、というタイミングで自作のツールの拡充はやめてpython3とkerasを使用することにしました。ずっと早そうだったからです。
pythonもkerasも不慣れなので、忘備録として、いつもお世話になっているQiitaに投稿することにしました。
お気付きの点がありましたらご指摘いただけますと幸いです。
##課題
全4回のシリーズでは、以下の3つの課題をクリアしたいと思います。1. 平均と標準偏差を出力するNN
2. 正規分布に従う波形データから、その正規分布を描画するのに必要な3つのパラメータを出力するNN
3. 画像中にある円についての4つのパラメーター(x座標、y座標、半径、線の太さ)を出力する畳み込みNN(CNN)第1回の今回は準備編です。
##numpyのndarrayの使い方の復習
ker
Heroku、Flask、Python、にゃん子掲示板をデータベースで作る(その①)
#(1)まずはcsvを使って掲示板を作成する
###<ディレクトリ構成>“`
test
├app.py
├articles.csv
├Procfile
├requirements.txt
└templates
├index.html
├layout.html
└index_result.html
“`
###①コンテンツの作成
仮想環境をディレクトリtestの直下に設定、起動。“`
python3 -m venv .
source bin/activate
“`必要なフレームワークとwebサーバーをインストール。
“`
pip install flask
pip install gunicorn
“`articles.csvに、掲示板のデータをはじめに入れておく。
“`.csv:articles.csv
たま,眠いにゃー
しろ,腹減ったにゃー
クロ,なんだか暖かいにゃー
たま,ぽえーぽえーぽえー
ぽんたん,トイレットペーパーがない
なおちん,チーン
“`app.pyを作成。
“`.py:app.py
# -*- coding:
Python セイウチ演算子で複数行ラムダ
“`python
def very_long_name_func(x):
return x * 2def func(x, y, z):
return x + y + zf = lambda i: (
x := very_long_name_func(i),
func(x, x, x)
)[-1]for n in map(f, range(10)):
print(n)“`
AtCoder ABC43(ARC59) C,D問題
今回はABC43のC,D問題を解いてみた。
まず[C問題](https://atcoder.jp/contests/abc043/tasks/arc059_a)から。
“`python:abc43_c.py
n = int(input())
a = list(map(int,input().split()))
avg = 0
for i in a:
avg = avg + iavg1 = avg//n
avg2 = avg//n + 1
ans1 = 0
ans2 = 0for i in a:
ans1 = ans1 + pow((i-avg1),2)
ans2 = ans2 + pow((i-avg2),2)print(min(ans1,ans
Flask-Babelで多言語化をやってみる
# Flask-Babelとは?
[Flask-Babel](https://pythonhosted.org/Flask-Babel/)とは、PythonのFlaskで多言語対応(i18n, l10n)をするためのライブラリ。
多言語化対応にコンパイルが必要という、ちょっと使い勝手が特殊で理解に時間がかかったためメモを残す。## インストール
“`shell
$ pip install Flask-Babel
“`## HTTPリクエストのAccept Languagesヘッダで言語判別する設定
下記のコードの`request.accept_languages.best_match`には対応する言語を[ISO 631-1](https://ja.wikipedia.org/wiki/ISO_639-1%E3%82%B3%E3%83%BC%E3%83%89%E4%B8%80%E8%A6%A7)に従って指定する
※ 日本語対応にはjaのみで基本的には問題ないが、IEではja_JPが無ければ動かないという報告がある“`python
from flask import F
「コロナ」に関するツイートをpythonで収集して、「コロナ」の影響で話題になった単語を自動検出する
Twitterデータのpythonでの収集方法と、時系列のテキストデータに対するバースト検出方法の説明です。
技術的には、以下の過去記事と同様です。
過去記事:
「クッパ姫」に関するツイートをpythonで収集して、バースト検出してみた
https://qiita.com/pocket_kyoto/items/de4b512b8212e53bbba3この時に採用した方法の汎用性を確認するために、2020年3月10日時点で話題の「コロナ」をキーワードとして、Twitterデータの収集と、「コロナ」と共起する語のバースト検出を実践してみました。
# 「コロナ」に関するツイートを収集する
収集方法は、基本的に過去記事とほぼ同じです。
まずは、ライブラリの読み込みなど、ツイート収集の準備を行います。
“`python
# Twitterデータ収集用のログインキーの情報
KEYS = { # 自分のアカウントで入手したキーを記載
‘consumer_key’:’*********************’,
‘consumer_secret’:’
PythonのプロジェクトをTeamcityで自動テストする
## 目的
Pythonの自動テスト環境を構築する。
## 環境
* TeamCity Professional 2019.2.2 (build 71923)
* dockerコンテナubuntuバージョン
* Python 3.7.6
* Poetry 1.0.5## 概要
以下の条件であればTeamcityでなくても問題はない。
TeamcityのビルドエージェントはDockerコンテナで環境がわけられていい。* Pythonの実行環境がある
* 単体テストの全実行ができる
* フォーマッタを全ソースに自動適用できる
* 静的コード解析を全ソースに自動適用できる## Pythonの実行環境
### Python用ビルドエージェントコンテナ
MinimalのエージェントコンテナをベースにPythonの環境を構築していく。
pyenvを使うとコードが短くなるしanacondaなど実装系とも共通化できるので利用した。“`dockerfile:Dockerfile
FROM jetbrains/teamcity-minimal-agent:latest




