
- 1. PythonでEthereumアカウントを作る
- 2. Python、stftime、strptimeの違い
- 3. Python、fromとimport、asについて
- 4. 【Matplotlib】軸ラベルは傾けない
- 5. 「電池つき言語」なpythonの10の関数
- 6. 【Python3】paizaで標準入力からの値の受け取り方
- 7. Python3のlistにおける重複した要素を削除する方法
- 8. Pythonを使ったBasic認証の設定
- 9. リストのソート
- 10. pythonでmd5を総当たりで解読するツールを作って見た
- 11. Pythonのいろんなfor文まとめ
- 12. Django2.xからDjango3.xでの変更点(かもしれない)の報告:静的ファイルのタグ書き換え・HttpResponseRedirectの指定方法
- 13. [Python]セミラグランジュ法のメソッド
- 14. 【Python】0で穴埋めするときに必要な桁数を計算する【メモ書き】
- 15. 【Python】MAEとRMSEの計算方法
- 16. 【Python】YouTubeの動画URLから動画IDを取り出す【メモ書き】
- 17. [Python] Travis CI と CodeClimate を使って unittest の coverage を算出
- 18. 最新物理ベースレンダラー Mitsuba2を触ってみる (2) Pythonから動かす編
- 19. 講義で書いたPythonのコードをまとめてみた その2
- 20. [PyTorch]modelとdatasetがcudaモードになっているか確認する
PythonでEthereumアカウントを作る
備忘録
“`
$ pip install eth-account
“`“`create.py
from eth_account import Accountacct = Account.create(‘RANDOM STRING’)
print(acct.address)
# 0x37B654931470E0319583ba097d4fbb79276b1067
print(acct.key)
# b’nq\x9b\x1a\x87\xc6/\xbf\x97\x91/\x1fj\xe2/]S\x87\x8d\x84\x9e\x1b\xb7\x18\xf8\xcfj\xc7A{h\x04′
“`# 参考
https://github.com/ethereum/eth-account
Python、stftime、strptimeの違い
#stftimeと、strptimの違いについてメモ
#(1)前提
datetiemクラスをインポートして、today()を変数tに代入“`
from datetime import datetime
t = datetime.today
t
“`
とすると、“`
datetime.datetime(2020, 3, 12, 23, 37, 45, 238787)
“`
となる#(2)datetime型 → str型
“`
str_t = t.strftime(‘%Y年%m月%d日/%H時%M分%S秒’)
str_t
“`
とすると、“`
‘2020年03月12日/23時37分45秒’
“`
となる
#(3)str型 → datetime型“`
time_t = t.strptime(str_t, ‘%Y年%m月%d日/%H時%M分%S秒’)
time_t
“`
とすると、“`
datetime.datetime(2020, 3, 12, 23, 37, 45)
“`
となる。
Python、fromとimport、asについて
#pythonで使用するfromとimportの違いをメモ(例としてtoday関数を使い、2通りの方法を記述)
##(1)datetimeモジュールをインポートするのみ
datetimeモジュールの、datetimeクラスのtoday関数を使う、という記述をする“`
import datetime
datetime.datetime.today()
“`
結果として“`
datetime.datetime(2020, 3, 12, 23, 21, 41, 756354)
“`
となる。##(2)datetimeモジュールとdatetiemクラスをインポートする
datetimeクラスのtoday関数を使う、という記述をする“`
from datetime import datetime
datetiem.today()
“`
結果は同様に“`
datetime.datetime(2020, 3, 12, 23, 21, 41, 756354)
“`
となる。##(3)おまけ
asを使うとライブラリ名(モジュール名)を好きな言葉で使うことができる
【Matplotlib】軸ラベルは傾けない
## はじめに
* 最近、時系列のグラフを多く見かけますが、一部の軸ラベルは傾いています。
* 恐らく見栄えを弄る時間が無かったか?もしくは対処法が見つからなかったかもしれません。
* 私自身も、軸ラベルを傾けるかあるいは横向けのグラフで妥協して作図していました。## 背景
* [「データ視覚化のデザイン#4」](https://note.com/goando/n/neb6ea35f1da3)で**軸ラベルは傾けない**という記事をTwitterで見かけました。
* その記事では、軸ラベルを傾ければ文字の認識に要する時間が伸びていくという研究の紹介がありました。
* ではどうすればと、軸ラベルを傾ない方法を調べました。## サンプルデータ
“`python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as ticker# サンプルデータ
data = pd.D
「電池つき言語」なpythonの10の関数
http://www.minekawada.com/python-useful-lib.html
目次
pprint
__str__2番目のprint関数の内容は、意外と知らないかもしれませんよ〜
【Python3】paizaで標準入力からの値の受け取り方
# はじめに
pythonのお勉強がてらの自分メモです
動作環境は「paiza」でやってます。## 入力値が1行に1つの場合
“`python3:test.py
#文字列の場合
str = input()#数値(int)の場合
num = int(input())
“`## 入力値が1行に2つ以上の場合
※ここでは便宜上入力値は2つ、区切り文字は半角スペースとする“`python3:test.py
#文字列の場合
strA, strB = input().split(‘ ‘)#数値(int)の場合
num1, num2 = map(int, input().split(‘ ‘))
“`## 入力値が1行に複数ある場合 ⇒ listで取得
※ここでは便宜上区切り文字は半角スペースとする“`python3:test.py
#文字列の場合
list = input().split(‘ ‘)#数値(int)の場合1
list = list(map(int, input().split(‘ ‘)))#数値(int)の場合2
list = [i
Python3のlistにおける重複した要素を削除する方法
### リストの中から重複をしている要素の削除
このリストを書こうと思った理由としては、要素が重複していないリストを作成する際に自身はremove()を用いた要素の削除を行っていました。自分はremove()を用いれば指定した値はすべて削除してくれるものだと勘違いしていました。“`
l = [1, 2, 3, 4, 1]
l.remove(1)
print(l)
#[2, 3, 4, 1]
“`
このように一番最初に出てきた指定をした値の削除を行うことが出来ます。しかしこのコードだと、削除を行うことができるのは一つだけのため以下のような挙動が起きてしまいます。“`
l = [1, 2, 3, 4, 1, 1]
l.remove(1)
print(l)
#[2, 3, 4, 1, 1]
“`そのため、重複をしていないリストを作成するためには以下のようなコードにするべきです。
“`
l = [3, 4, 3, 2, 5, 4, 3]
l_u = []
for i in l:
if i not in l_u:
l_u.append(i)
#[3
Pythonを使ったBasic認証の設定
# はじめに
LambdaでBasic認証って検索すると、Node.jsのものしか見つからなかったので書いてみた。
自身の備忘録も兼ねて。
Node.js版は、ぐぐるとすぐに出てくるので、ここでは触れないです。# コード
と言っても大したものではなく、Node.js版の焼き直しな感じです。
ただ、マルチアカウントに対応できるようになっている点はちょっと違う。“` Python
import json
import base64accounts = [
{
“user”: “user1”,
“pass”: “pass1”
},
{
“user”: “user2”,
“pass”: “pass2”
}
]def lambda_handler(event, context):
request = event.get(“Records”)[0].get(“cf”).get(“request”)
headers = request.get(“headers”)
リストのソート
# リストのソート
“文字+数字”形式のリストを数字でソートしたい。
ネットで検索しても全然見つからなかったので、うまいやり方ではないかもしれませんが、
書いてみました。
回路図の部品表や、IC(特にBGA)のPIN番号などがこういった形式になっています。
文字列はFPGAのPIN番号リストを抜粋しました。## 1次元の場合
### 単純なソート“`python
list1 = [“A1″,”A2″,”A3″,”A10″,”A11″,”A12″,”A13″,”A20″,”A21″,”A22″,”A23″,”A30″,”A31″,”A32”]
list1.sort()
print(list1)
“`
結果:
桁がそろわない。“`python
[‘A1’, ‘A10’, ‘A11’, ‘A12’, ‘A13’, ‘A20’, ‘A2’, ‘A21’, ‘A22’, ‘A23’, ‘A3’, ‘A30’, ‘A31’, ‘A32’]
“`### 文字列の数字部分でソート
intでソートすれば番号順に並ぶので、いったん数値だけ取り出してソートした後、元のリストを取り出す
pythonでmd5を総当たりで解読するツールを作って見た
#はじめに
学校が休校になってしまいやる事が無かったので[ハッキングチャレンジサイト](http://www.hackerschool.jp/hack/)の問題に挑戦していたのですが、その中でmd5と言うハッシュ化の技術を知りました。そこでpythonでmd5を解読するコードを制作して見ました。総当たりでmd5を解いているので処理に時間がかかりますが温かい目で見てください(*- -)
#md5逆変換スクリプト
“`python
import hashlib
dat = input(“Enter md5:”)
word = [“1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”0″,”a”,”b”,”c”,”d”,”e”,”f”,”g”,”h”,”i”,”j”,”k”,”l”,”m”,”n”,”o”,”p”,”q”,”r”,”s”,”t”,”u”,”v”,”w”,”x”,”y”,”z”]
for a in range(36):
ps= hashlib.md5((word[a]).encode()).hexdigest()
if ps== dat:
Pythonのいろんなfor文まとめ
## ■基本形
### i=0始まりでn回回す“`input.py
n = 5
for i in range(n):
print(i)
“`
“`output.py
0
1
2
3
4
“`
### i=xから(y-1)まで
“`input.py
x = 1
y = 4
for i in range(x,y):
print(i)
“`“`output.py
1
2
3
“`## ■文字列
### 一文字ずつ取り出す“`input.py
for char in ‘string’:
print(char)
“`“`output.py
s
t
r
i
n
g
“`## ■リスト型
### 要素1つずつ取り出す“`input.py
list = [‘a’,’b’,’c’]
for a in list:
print(a)
“`“`output.py
a
b
c
“`## ■辞書型
### 要素1つずつ取り出す
“`input.py
dict = {‘key1′:’val1’, ‘key2
Django2.xからDjango3.xでの変更点(かもしれない)の報告:静的ファイルのタグ書き換え・HttpResponseRedirectの指定方法
# 経緯
半年ぶりくらいにDjangoを触ったらバージョンが3になってました。更新速いっ!
で、昔作ったプロジェクトをカスタムしてたらエラーが何個か出たので、変更点っぽいのでDjango扱うかたに有益かもしれないので、共有します。# 環境など
Django==2.0.4
で作ったプロジェクトをカスタムして、
Django==3.0.4
で構築した時の気づきPython==3.6.1 (3.7だとエラーが出てしまう。今後要解析。)
# 1 静的ファイル取り扱いタグが昔の奴が使えなくなっていた
“`
TemplateSyntaxError at /
‘staticfiles’ is not a registered tag library. Must be one of:
“`というエラーが出ました。タグを直すだけで直ります!
“`
このタグを
{% load staticfiles %}↓のように直します
{% load static %}
“`# 2 HttpResponseRedirectの飛ぶ先の指定が変わったかもしれない。
NoRever
[Python]セミラグランジュ法のメソッド
移流方程式解くプログラムがネット上に少なかったのと、メソッド化されているものは日英で探した時に無かった(もしくはバグってるやつ)ので作りました。
“`python
#https://github.com/christian512/SemiLagPy/blob/master/advection1D.ipynb
#これを参考にした。import numpy as np
import matplotlib.pyplot as pltclass SemiLagrangian1D:
“””
SemiLagrangian scheme for periodic 1D problems.
“””
def __init__(self,x,y,u,dt):
“””
Initizalizes the SemiLagrangian object given initial configuration
x : x positions (must be equidistant)
y : variable
【Python】0で穴埋めするときに必要な桁数を計算する【メモ書き】
`log`を高校で習ったときに`log`っていつ使うねん!って思ってたら使いどきあったのでメモメモ。
“`python
import mathlist = [1,2,3,4,5,6,7,8,9,10,11]
number_of_val = len(list)
number_of_padding_zero = math.ceil(math.log10(number_of_val))
format_pattern = ‘{:0’+ str(number_of_padding_zero) +’d}’for i,val in enumerate(list):
serial_number = format_pattern.format(i)
print(serial_number)
“`実行結果:
“`
00
01
02
03
04
05
06
07
08
09
10
“`連番でファイル出力するときに0で穴埋め(ゼロパディング)するということを想定。
テスト用なのでコード中の`list`には数字入ってますが、ファイルパスとかが入ってると思ってください。
出力
【Python】MAEとRMSEの計算方法
###目的
Pythonを使って平均絶対誤差(Mean Absolute Error:MAE)と二乗平均平方根誤差(Root Mean Squared Error:RMSE)を計算する。記事は[こちら](https://www.aiprogrammers.net/entry/2020/03/09/021517)にまとめました。
【Python】YouTubeの動画URLから動画IDを取り出す【メモ書き】
# まえがき
YouTubeの動画URLを取り出す手法についてはいくつもの記事が上がっているが、「共有」ボタンを押したときに生成される`https://youtu.be/`で始まる短縮URLへの対応や、URLクエリパラメータ(例えば時間を指定する`t=15`や短縮URLからの転送を示す`feature=youtu.be`など)を含む場合は考慮されてないものばかりな気がしたのでここにメモとして書いてみる。
ちなみに、再生開始位置を示すYouTubeのURLクエリパラメータ`t`は、
`https://youtu.be/r4Mkv-q4NmQ?t=5437`や
`https://youtu.be/r4Mkv-q4NmQ?t=5437s`のように
全て秒数で指定するのはもちろん、
`https://youtu.be/r4Mkv-q4NmQ?t=1h30m37s`のように
`◯h△m□s`とすると「◯時間△分□秒」から再生開始するURLになるぞ!
※もちろん、`◯h`を省略して`△m□s`とするのも可。尚、この記事内のYouTubeのURLは基本的に私の投稿動画やチャン
[Python] Travis CI と CodeClimate を使って unittest の coverage を算出
# 概要
[CodeClimate](https://codeclimate.com/) のサービスの1つである test coverage 機能を使おうとしたのですが、予想以上に設定に手こずったので、記事にしておこうと思いました。
ネット上で掲載されている記事と環境が一部違ったりして辛かった…
# 対象者
* Travis CI は既に使えている
* CodeClimateについては、コード品質チェックまではできる
* CodeClimateのtest coverage機能がなぜか動かない…設定がおかしいのかな?という方!(ものすごく限定的です)
## イメージ画像
CodeClimateへの通信経路のイメージを書いてみました。
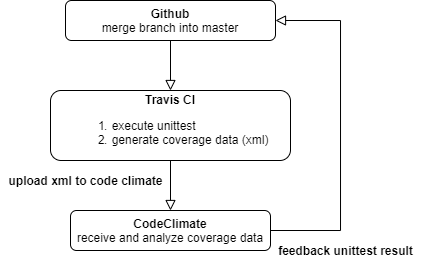
## environment
|項目||
|:–|:–|
最新物理ベースレンダラー Mitsuba2を触ってみる (2) Pythonから動かす編
# Mitsuba2とは
アカデミック向けのフリーの物理ベースレンダラー。微分可能レンダリングや偏光レンダリングなどの新機能がある。
この記事は[最新物理ベースレンダラー Mitsuba2を触ってみる(1) 導入編](https://qiita.com/kurilab/items/34089636fa570d9a7939)の続きになります。
Mitsuba2のインストールまで終わっているという前提です。
# PythonからMitsuba2を動かす
[公式でも書かれているように](https://mitsuba2.readthedocs.io/en/latest/src/python_interface/intro/)Mitsuba2は非常に強力なPythonバインディングを提供していて、ほぼすべての機能をPythonから

講義で書いたPythonのコードをまとめてみた その2
# はじめに
今回もPythonで解いていきます。
書くことないので早速ゴー。## 問題とコード
ゲームでよくあるガチャについて考える。
このガチャは引くたびに1/nで当たりが出るものとする(nは与えられた自然数)。
k回引いた場合に、少なくとも1回は当たりが出る確率はいくらだろうか。
N君はこれを以下のように考えた。
「k回全てが外れである確率が
$$
(\frac{n-1}{n})^k
$$
だから、少なくとも1回は当たりがでる確率Pkは$$
P_k = 1 – (\frac{n – 1}{n})^k
$$
である。x = 1/nとおくと、$$
P_k = 1 – (1 – x)^k
$$となる。xは小さいのでテイラー展開を使って以下のように概算できる。
$$
P_k = 1 – (1-x)^k
\approx 1 – (1 – kx)
= kx
\approx \frac{k}{n}
$$ここでk = nとおくと、
$$
P_k \approx 1
$$
となる。これは「確率(1/n)のがちゃをn回引くと、1回くらいは当たりがでる
[PyTorch]modelとdatasetがcudaモードになっているか確認する
# はじめに
PyTorchはテンソルに対して“`hoge.to(device)“`などで簡単にcpuとgpuモードを切り替えられますが,よくこのデータセットやモデルがcpuかgpuなのかわからなくなったので,確認する方法を書き残しときます.## 確認方法
前提としてデータセットとモデルの準備は“`python
IMAGE_SIZE=224
BATCH_SIZE=20
TRAIN = ‘train’
DATA_DIR = ‘dataset/predata/’
DEVICE = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)data_transforms = {
TRAIN: transforms.Compose([
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor(),
])
}# データの前処理
image_datasets = {x: datasets.ImageFolder(os.p




