
- 1. 投稿テスト
- 2. python上でのファイルやフォルダ情報を参照
- 3. Pandasユーザーガイド「テーブルの整形とピボットテーブル」(公式ドキュメント日本語訳)
- 4. COTOHAは人間を超えるのか?日本語検定に挑戦!
- 5. Python プログラミング ワークショップ – 超々入門編 Python実行環境編
- 6. Raspberry Piをリモートで動かして、PythonでLED付けられるようにした
- 7. VGG以降のネットワークは本当に進歩しているの?という話
- 8. 言語処理100本ノック-52:ステミング
- 9. 【Python】使い道があるようでなさそうなデコレータつくった。
- 10. 【Python + OpenCV】?エブリバーガーまちがいさがし攻略? ~ テンプレートマッチングで攻略 ~
- 11. 【Python】データ分析の際の覚え書き
- 12. Baiduが公開しているマスク検出を試してみた
- 13. 全22行のコードでGradCAM。tf_explainは、使い易いかも、お薦め!
- 14. Numpyの気持ち悪いぐらいの柔軟性は、Pythonが動的型付け言語だからできることなのか
- 15. GitHub Actionsを活用して擬似APIサーバーを用意する
- 16. [TensorFlow 2] TFRecordからの特徴量読み込みはバッチ単位でやるのがオススメ
- 17. Python、stftime、strptimeの違い
- 18. ベルヌーイ分布から様々な確率分布を生成し、確率分布間の関係を理解する
- 19. 言語別AWS SDKのパフォーマンスの一検証
- 20. Python、fromとimport、asについて
投稿テスト
投稿テスト
テスト1
“`Python:GM_world.py
print “Good morning world”
“`テスト2
“` main.c
#include
int main(void){
printf(“Hello, World!!¥n”);
return(0);
}
“`
python上でのファイルやフォルダ情報を参照
よく使うけど毎回調べてしまうpythonのファイル操作関連のまとめ
#フォルダ内のファイル一覧を取得
指定したフォルダ内のファイルの一覧をリストとして取得する“`python
import globfolder = “./tmp/”
img_path_list = glob.glob(folder)
“`ワイルドカードを使用すれば特定のファイルの一覧も取得可能
下記はpngファイルのみをリストとして獲得“`python
img_path_list = glob.glob(folder + “*.png”)
“`#ファイル名の取得
指定したパスからファイル名を文字列として取得する“`python
import osfilepath = ‘./tmp/hogehoge.ext’
filename = os.path.basename(filepath)
print(filename) # hogehoge.ext
“`拡張子なしで取得する場合
“`python
filename_only = os.path.splitext(os.pa
Pandasユーザーガイド「テーブルの整形とピボットテーブル」(公式ドキュメント日本語訳)
本記事は、Pandas の公式ドキュメントの[User Guide – Reshaping and pivot tables](https://pandas.pydata.org/pandas-docs/stable/user_guide/reshaping.html)を機械翻訳した後、一部の不自然な文章を手直ししたものである。
誤訳の指摘・代訳案・質問等があればコメント欄や編集リクエストでお願いします。
# テーブルの整形とピボットテーブル
## DataFrameオブジェクトをピボットすることによる整形
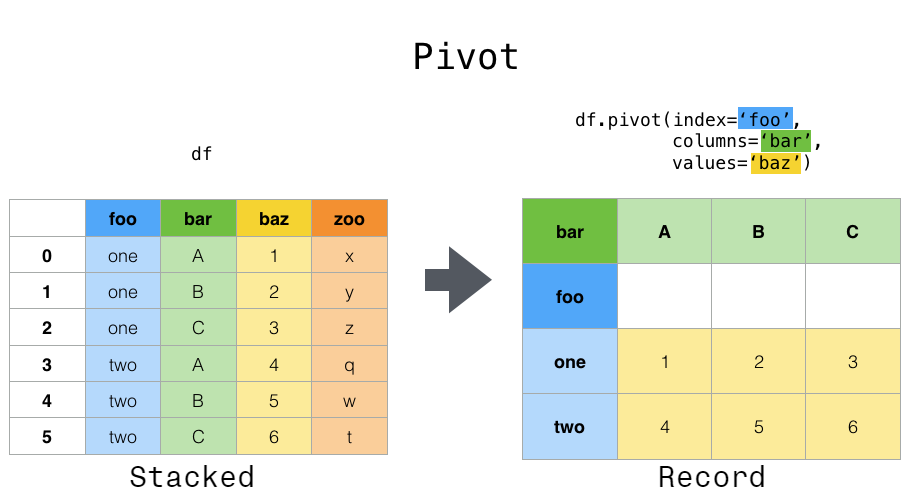
データは多くの場合、いわゆる「スタック」や「レコード」と呼ばれる形式で保存されます。
“`py
In [1]: df
Out[1]:
date variable value
0 2000-01-03 A 0.469112
1 200
COTOHAは人間を超えるのか?日本語検定に挑戦!
# COTOHA APIとは
NTTコミュニケーションズが提供する自然言語や音声を処理してくれるAPIで、主にできることは下記となります。– 構文解析
– 固有表現抽出
– 固有名詞(企業名)補正
– 照応解析
– キーワード抽出
– 類似度判定
– 文タイプ判定
– ユーザ属性推定
– 言い淀み除去
– 音声認識誤り検知
– 感情分析
– 音声認識
– 音声合成
– 要約詳しくは[こちら](https://api.ce-cotoha.com/contents/index.html)
今回はこの中から類似度判定を用いて日本語検定に挑戦してみました。#日本語検定とは
日本語検定委員会が運営する総合的な日本語能力を測る試験です。
漢字、表記、敬語、言葉の意味、語彙、文法、総合の7項目がありますが
今回は[こちら](https://www.nihongokentei.jp/check/)に公開されている例題から語彙の類義語問題に挑戦してみます。# いざ日本語検定にチャレンジ
使用するコードは下記のようになっています。
選択肢の数と問題を入力後、それぞれのスコアと最終的な解答を
Python プログラミング ワークショップ – 超々入門編 Python実行環境編
# 本題の前に
—
## 位置付け・前提本記事は、**社内ワークショップ** のために用意したものです。そのため、次の前提で進めることをご理解ください。
—
## 本ワークショップの目的
参加者が**必要に併せて自学できる入口に立つ** ことを目的とします。* 実用的なプログラミングを **ハンズオン形式** で実行して、理解を深めます。
* 本ワークショップだけで、あらゆるプログラムがすいすい組めるようになるわけではありません。
* 後日にプログラミングで何かを作ろうとしたときに、自分で調べて製作できるようになることを目指します。
* なんかこういうもんだ、という感じで軽く頭に残れば大丈夫と考えましょう。—
## ワークショップの進め方
ワークショップは、基本的にハンズオンを中心に進めます。(一部解説は入れます)* ご自分の業務用途のパソコンを利用してください。
* 基本的には**「写経」**を原則とします。
* 写経 = 自分でキー入力して写すこと ≠ コピペ
* 自分が書いたコードをコピペしてから改変するのはOK。
Raspberry Piをリモートで動かして、PythonでLED付けられるようにした
#はじめに
業務で適用できないかと考え、Raspberry Piを購入しました。今回、チュートリアルの位置付けとされるLED点灯を行いました。
私自身電子工作は初めての経験となります。ご意見、ご感想何なりとお申し付けください。当方、メインPCはWindowsを使用しております。
+ Raspberry Piをリモートで接続
+ LED回路を作製
+ Python経由でLED点灯プログラムを作成##Raspberry Piをリモート接続
Windowsでは他のPCを表示、操作するリモートデスクトップという機能があります。これは、Windows10であればWindowsアイコンの横の検索欄から検索することで出すことができます。

私の場合はWIFI経由でRaspberry Piへアクセスします。コンピュータ名としてはIPアド
VGG以降のネットワークは本当に進歩しているの?という話
# 1. はじめに
本記事では[AI competitions don’t produce useful models](https://lukeoakdenrayner.wordpress.com/2019/09/19/ai-competitions-dont-produce-useful-models/?utm_campaign=piqcy&utm_medium=email&utm_source=Revue%20newsletter)で問題定義されている最近のネットワークアーキテクチャはデータセットに過学習してるだけ&運ゲーで上振れしているだけじゃないの?という話を広角眼底データセット[^1]で調べてみることを目的とします。また、入門向けとして、`tf.keras`で実装済みのネットワークを用いてImageNet[^2]の学習済み重みからFine-turningする方法を解説します。[すべてのコード] (https://github.com/burokoron/StaDeep/tree/master/fine-turning)
# 2. 環境
– PCスペック
– CP
言語処理100本ノック-52:ステミング
[言語処理100本ノック 2015](http://www.cl.ecei.tohoku.ac.jp/nlp100/)[「第6章: 英語テキストの処理」](http://www.cl.ecei.tohoku.ac.jp/nlp100/#ch6)の[52本目「ステミング」](http://www.cl.ecei.tohoku.ac.jp/nlp100/#sec52)記録です。
**言語処理においてよく使うであろうステミング**です。実際に[後続ノック71本目](https://qiita.com/FukuharaYohei/items/60719ddaa47474a9d670)の機械学習系ノックでも利用しています。関数を呼び出すだけなので、技術的には非常に簡単です。# 参考リンク
|リンク|備考|
|:–|:–|
|[052.ステミング.ipynb](https://github.com/YoheiFukuhara/nlp100/blob/master/06.%E8%8B%B1%E8%AA%9E%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88%E3%81
【Python】使い道があるようでなさそうなデコレータつくった。
#はじめに
皆さん`デコレータ`作ってますか? 恥ずかしながら、私は**今日**詳細を知りました。存在には気づいていても今日までは無視してきましたが、勉強しましたので何かアウトプットしようと思って書いています。#つくったもの
早速ですがこんなものをつくてみました。“`python:deco_test.py
def decof(Func,*_args,**_kwargs):
def _deco(func):
def wrapper(*args,**kwargs):
return Func(func(*args,**kwargs),*_args,**_kwargs)
return wrapper
return _decodef decob(Func,*_args,**_kwargs):
def _deco(func):
def wrapper(*args,**kwargs):
return Func(*_args,func(*args,**kwargs),*
【Python + OpenCV】?エブリバーガーまちがいさがし攻略? ~ テンプレートマッチングで攻略 ~
[[Python + OpenCV] ?エブリバーガーまちがいさがし攻略?](https://qiita.com/ari3/items/8fdca5f2a7c857f8f7ba) の続きです。
前回結果を踏まえたうえで、おそらく一番シンプルなやり方で改善を図りたいと思います。# 前回まで
難易度: 「むずかしい???」
まちがい: 4つ

https://www.bourbon.co.jp/burger.kikori/burger/導き出した答え(たぶん合ってる)
しかし、当該の問題画像にのみ特化して
【Python】データ分析の際の覚え書き
#この記事の目的
データ分析を行う際の完全な自分用のメモです.
コピペが捗るように作成しているので“`df.head()“`などの短いものは載せていません.## ライブラリ読み込み
“`python
import numpy as np
import pandas as pd
pd.set_option(‘display.max_columns’, 100)import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlibimport os
from tqdm import tqdm
import warnings
warnings.filterwarnings(‘ignore’)
“`## データ読み込み
#### パターン1“`python
filename = “hoge.csv”
df = pd.read_csv(filename, encoding=’utf-8′)
“`#### パターン2
“`python
dirname = “/foo/b
Baiduが公開しているマスク検出を試してみた
# はじめに
マスクを付けているかいないかを判別するプログラムが公開されたのでやってみました
コロナウイルスの影響でマスクを着用した顔のデータセットや検出モデルの公開がここ最近急増している?
■ Baiduが公開したオープンソースのマスク着用顔検出モデルhttps://t.co/NurgI3KB30■ 3500枚を超えるマスク検出するためのデータセットhttps://t.co/P3bVOaGawq pic.twitter.com/xtrVV86abF
— MAℝiNA?|Edge AI Biz (@m__sb04) 全22行のコードでGradCAM。tf_explainは、使い易いかも、お薦め!
#目的
**tf_explain**というのがあるらしい。
そこには、**GradCAM**がモジュールとして入っているようです。
それを使っているgithubをみると、
わずか、全22行(空行あり)で、**GradCAM**が実行できていた。
すばらしいと思うので、
動かしてみた。#全22行のコード
以下のgithubにこのコードがある。
https://github.com/sicara/tf-explain/blob/master/examples/core/grad_cam.py以下のコードがすべてなので、
“`
python grad_cam_py.py
“`だけで、動作します。
“`grad_cam.py
import tensorflow as tffrom tf_explain.core.grad_cam import GradCAM
IMAGE_PATH = “./cat.jpg”
if __name__ == “__main__”:
model = tf.keras.applications.vgg16.VGG16(weighNumpyの気持ち悪いぐらいの柔軟性は、Pythonが動的型付け言語だからできることなのか
rustあたりにnumpyのようなライブラリができたら比較できて面白いんだけどなぁ。
https://qiita.com/AKKYM/items/8cd2073432dbded95626
GitHub Actionsを活用して擬似APIサーバーを用意する
## はじめに
たぶん割と最近、GitHub Actionsという機能が追加されました。
これは、所定のイベントに対し所定のActions(シェルスクリプトの実行)を発火させる事が出来るというやつです。
例えばdevブランチへのPRがマージされたらビルドしてdev-pagesブランチにプッシュ、なんていういわゆるCI/CD向けの機能です。この度、現在大きな動きとなっているCOVID-19対策サイトの[北海道版](https://stopcovid19.hokkaido.dev/)に参加し、この機能を用いた開発を行いました。これを例に、タイトルのとおりGitHubを擬似APIサーバーに仕立てる事が可能では?という提案を本記事で行います。
## GitHub Actionsによるスケジューリング
#### Actionsに至った経緯
https://github.com/Kanahiro/covid19hokkaido_scraping
前述の対策サイト開発の際、可視化の元となるJSON形式のデータをこさえるのに作ったスクリプトです。(当時のversionでは)実行すると道のウェブサ
[TensorFlow 2] TFRecordからの特徴量読み込みはバッチ単位でやるのがオススメ
# はじめに
TensorFlowで大量のデータを学習させるときには、Dataset APIを使ってTFRecordに保存した特徴量を読み込むようにすると便利です。
[\[TensorFlow 2.x対応版\] TensorFlow (Keras) で TFRecord & DataSetを使って大量のデータを学習させる方法 – Qiita](https://qiita.com/everylittle/items/11140a5706387e8e78ec)検索するとサンプルコードがたくさん見つかりますが、実は読み込み方を工夫することで、よく見る方法よりも格段に速く読み込めるようになる可能性があることが分かりました。
# 検証環境
– Ubuntu 18.04
– Python 3.6.9
– TensorFlow 2.1.0 (CPU使用)# よく紹介されている読み込み方法
上の記事の他、公式ドキュメントや他のサイトでよく紹介されている読み込み方として、“tf.io.parse_single_example()“ を使う方法があります。
[TFRecords と t
Python、stftime、strptimeの違い
#stftimeと、strptimの違いについてメモ
#(1)前提
datetiemクラスをインポートして、today()を変数tに代入“`
from datetime import datetime
t = datetime.today
t
“`
とすると、“`
datetime.datetime(2020, 3, 12, 23, 37, 45, 238787)
“`
となる#(2)datetime型 → str型
“`
str_t = t.strftime(‘%Y年%m月%d日/%H時%M分%S秒’)
str_t
“`
とすると、“`
‘2020年03月12日/23時37分45秒’
“`
となる
#(3)str型 → datetime型“`
time_t = t.strptime(str_t, ‘%Y年%m月%d日/%H時%M分%S秒’)
time_t
“`
とすると、“`
datetime.datetime(2020, 3, 12, 23, 37, 45)
“`
となる。
ベルヌーイ分布から様々な確率分布を生成し、確率分布間の関係を理解する
# はじめに
統計学の教科書に最初に出てくるベルヌーイ分布を出発として、様々な確率分布を生成する関数をPythonで実装しました。実装した関数は以下の通りです。`bernolli`、`binom`などが関数名です。
例えば、一様分布は次の順にたどることで生成できます。
`ベルヌーイ分布 -> 幾何分布 -> 指数分布 -> ガンマ分布 -> ベータ分布 -> 一様分布`
関数名や確率分布の定義は[scipy.stats](https://docs.scipy.org/doc/scipy/reference/stats.html)を踏襲しています。
それでは、これから各関数を順に説明していきます。# ベルヌーイ分布
まず、出発点のベルヌーイ分布に従うサンプルを生成します。
ベルヌーイ分布とは、「当たりが出る確率が$p$の
言語別AWS SDKのパフォーマンスの一検証
# 背景
## タグについて
AWSはリソースに[タグ](https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/Using_Tags.html)の付与が可能です。AWSにおけるタグはリソースの管理や[コスト配分](http://blog.serverworks.co.jp/tech/2019/07/29/cost-alloc-tags-basic/)の用途で用いられ、タグの付与設計はAWSの運用において非常に重要なポイントとなります。
特に大規模な環境や組織になるとリソースに付与するタグは非常に多くなる傾向があります。## AWS SDK for Rubyのパフォーマンス
[こちらの記事](https://qiita.com/kure/items/19b1c17a56d81e2bb955)でも言及したようにAWS SDK for Ruby では、リソースにタグが大量に付与されている場合、一度に大量のリソースを取得する場合に大幅に時間がかかることがあります。
以下はEBSを例に、タグ付与のあり・なしとで、リソースの取得(d
Python、fromとimport、asについて
#pythonで使用するfromとimportの違いをメモ(例としてtoday関数を使い、2通りの方法を記述)
##(1)datetimeモジュールをインポートするのみ
datetimeモジュールの、datetimeクラスのtoday関数を使う、という記述をする“`
import datetime
datetime.datetime.today()
“`
結果として“`
datetime.datetime(2020, 3, 12, 23, 21, 41, 756354)
“`
となる。##(2)datetimeモジュールとdatetiemクラスをインポートする
datetimeクラスのtoday関数を使う、という記述をする“`
from datetime import datetime
datetiem.today()
“`
結果は同様に“`
datetime.datetime(2020, 3, 12, 23, 21, 41, 756354)
“`
となる。##(3)おまけ
asを使うとライブラリ名(モジュール名)を好きな言葉で使うことができる




