
- 1. topic、projectID、サービスアカウントキーなどをexportせずに、GCP Pub/Subのtopicにメッセージをpublishする(python3)
- 2. (調整中)CentOS8とPython3とDjango3とMySQL8のセットアップメモ(pure python版)
- 3. pythonでLDAPにデータの追加取得をする
- 4. Kaggle Digit Recognizer
- 5. Kivy-iOS メモ
- 6. 【Python】Atomで競技プログラミング用の環境構築(input()使えます!)【Mac】
- 7. Python3 で 十字キーが入力された判定をとる方法
- 8. 【Python】AGC043A(問題読解力とDP)【AtCoder】
- 9. 5代血統表内に漢字の馬名が含まれるここ最近の競走馬を調べる【スクレイピング】
- 10. Kaggle Real or Not?
- 11. Python + Selenium(ChromeDriver)で「この接続ではプライバシーが保護されません」というエラーを無視する
- 12. Pycharmでpipがエラーになる(pipが古いってエラー)
- 13. Kaggle Predict Future Sales
- 14. colaboratoryデフォルトで入っているライブラリバージョン一覧 メモ
- 15. Python、正規表現について
- 16. AnacondaでPython3.8を使う
- 17. 楽にvscode+venvで仮想環境(Windows)メモ
- 18. SQLite3 で、たった2行追加して拡張ライブラリ(拡張SQL関数)を使おう!
- 19. chromeのcookieの内容をpythonで取得
- 20. ぜんぜんわからないから雰囲気でやったPython3での顔認識・モザイク処理。
topic、projectID、サービスアカウントキーなどをexportせずに、GCP Pub/Subのtopicにメッセージをpublishする(python3)
env.pyで環境変数など設定すれば、コマンドでのexportを実施せずに済みますので、楽です!
ポイント:
*サービスアカウントキーファイル(jsonファイル)はenv.py、publish.pyと同じディレクトリに置いておくと、便利です!
*リクエストを Pub/Sub サーバーに送信する際に、
“`publisher = pubsub_v1.PublisherClient()
“`
を使わず、“`publisher = pubsub_v1.publisher.Client.from_service_account_file(JSON_KEY)
“`
に変更すればokです!“`env.py
# GCPサービスのプロジェクトID
GOOGLE_CLOUD_PROJECT = ‘[PROJECT_ID]’
# Cloud Pub/Subのトピック名
TOPIC = ‘[TOPIC_NAME]’
# サービスアカウントキーファイル(jsonファイル)の保存パース
JSON_KEY = ‘[PATH_TO_JSO
(調整中)CentOS8とPython3とDjango3とMySQL8のセットアップメモ(pure python版)
※仕事場で確認するためにいったん投稿してます(ぉぃ
まだうまくいってないんだよね… encodingsのエラーが…# はじめに
CentOS8を入れてみたかった。それはCentOS7のシステム側のpythonが2で、プレーンなpython環境にしようとすると、ケンカするんだよね。CentOS側のpythonが3になってAnaconda縛りから解放されるってだけでやって見る価値あるでしょってことでさくらのVPSの2台めを検証用に借りてしまった!Wow!# 参考URL
サーバーワールド
https://www.server-world.info/query?os=CentOS_8&p=install
いままではここの内容ですら難しかったけど今なら大丈夫でしょ# CentOS8のインストール
## サーバーの契約
わくわくするね。休日つぶしにぴったり。
いったんCentOS7を入れる必要があるみたい。
次のページを参考にしました。
[kaggle Digit Recognizer をKerasで試してみる](https://trueman-dev`eloper.blogspot.com/2019/07/kaggle-digit-recognizer-keras.html)Kaggle の Notebook でコードを書き、コードをダウンロードして、
次のように、py に変換しました。“`bash
jupyter nbconvert –to script kernel23614dc019.ipynb
“`“`py:kernel23614dc019.py
#!/usr/bin/env python
# coding: utf-8# In[1]:
# This Python 3 environment comes with many helpful analytics libraries
Kivy-iOS メモ
#Kivyとは?
python3 でiOSアプリやandroidアプリなどのUIを記述可能なライブラリ#Kivy導入時に参考にした情報をまとめておく。
###導入
– https://qiita.com/sobassy/items/b06e76cf23046a78ba05
– https://github.com/kivy/kivy-ios
– https://qiita.com/tea63/items/c318ac7a1c09a78acab0###pathの繋げ方(エラー出た人だけ)
-https://qiita.com/yoshinbo/items/8eb71d8015291ac6a3bc
【Python】Atomで競技プログラミング用の環境構築(input()使えます!)【Mac】
Atomで競プロに必須のPythonの標準入力
`input()`
が使用できる環境構築の情報がググってもあんまりなかった…
ので記事にしてみます!
たぶん全作業30分かかりません!超簡単!
ちなみにMacです。Windowでもできるかは不明!#python3のインストール
[公式サイト](https://www.python.org/downloads/)からダウンロード
#Atomのインストール、初期設定
以下の記事が参考になりました!
[atom・pythonで競技プログラミングのテスト環境構築](https://qiita.com/crukky/items/73c1322f5929b1ca5834#%E5%8F%82%E8%80%83%E8%B3%87%E6%96%99)
#その他やる事
ホームディレクトリ(同階層にはダウンロードとかデスクトップとかあるよ)
に「python」というフォルダを作ってそのフォルダ内に– input.txt
– test.pyの2ファイルを作る。
これで準備完了。イメージはこんな感じ↓
Python3 で 十字キーが入力された判定をとる方法
## はじめに
この記事を書いた直後に、
https://docs.python.org/ja/3/library/curses.html#constants
このページを見つけました。以下の記事はほぼほぼ虚無です。## まえがき
自分用のメモです。愚直実装です。
やりたいことは十字キーなど特殊な文字が入力されたことを検知することです。前提としてUnicode制御文字の知識があることが望ましいです。
[wikipedia](https://ja.wikipedia.org/wiki/%E5%88%B6%E5%BE%A1%E6%96%87%E5%AD%97)## 詰まったところ
getchは入力を1文字ごとに取得します。しかし、矢印キーは3回文字分の入力がありました。 例えば上矢印は`27 91 65` とはいってきます。このままでは、矢印キーなどの特殊なキーを判定することができないばかりか、望まない入力を受け取ってしまいます。そこで、以下のように実装しました。## ソース
getch 1文字の入力を受け取る関数
ord は文字をUnicodeに変換する関数、
chr
【Python】AGC043A(問題読解力とDP)【AtCoder】
しっかり問題は読んで理解しよう!
難しい問題文に出会ってもすぐに諦めないで!#[AGC043A](https://atcoder.jp/contests/agc043/tasks/agc043_a)
Difficulty:803
強敵!
でも以下のポイント2つをクリアすればこの問題はとける!
①問題読解力
②DP(動的計画法)##①問題読解力
問題文の後半の「以下の操作」が頭に全く入ってこなかった!
ここでは「以下の操作」の解読をしていきます。
「以下の操作」の部分を問題より引用
>4つの整数r0,c0,r1,c1(1≤r0≤r1≤H,1≤c0≤c1≤W)を選ぶ。
r0≤r≤r1,c0≤c≤c1を満たす全てr,cについて、(r,c)の色を変更する。つまり、白色ならば黒色にし、黒色ならば白色にする。???
諦めないで!
とりあえず具体例を考えよう!
ノートとペンを用意!
※競プロにノートとペンは必須です!
[【Python】ABC159D(高校数学nCr)【AtCoder】](https://qiita.com/rudorufu1981/items/f9f1e679606d
5代血統表内に漢字の馬名が含まれるここ最近の競走馬を調べる【スクレイピング】
#はじめに
(以下、競馬用語を注釈無しで使用していきますのでご了承下さい。)なんとなく5代血統表に漢字の馬名が入っている馬がどれくらいいるのか気になったので競馬データベースサイト[「JBISサーチ」](https://www.jbis.or.jp/index.html)のページをスクレイピングして調べてみました。
近年活躍した競走馬で、5代血統表内に漢字の馬名がある馬といえば[ゴールドシップ](https://www.jbis.or.jp/horse/0001104811/pedigree/)が一番有名でしょう。
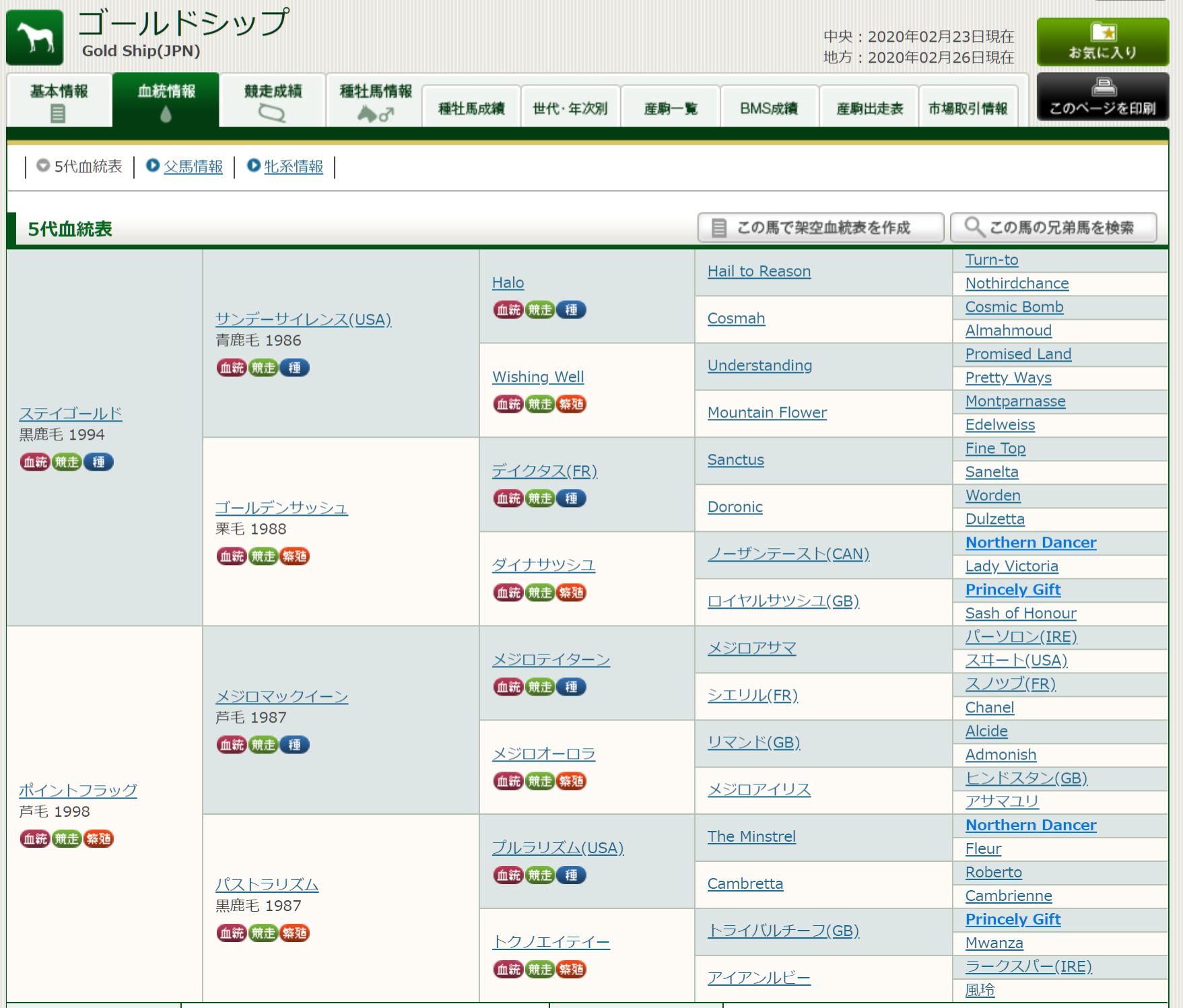
5代母が1959年生の「風玲」という馬です。昔は競走馬名にカタカナ使用の制限が
Kaggle Real or Not?
次の課題に submit するまでの流れです。
[Real or Not? NLP with Disaster Tweets](https://www.kaggle.com/c/nlp-getting-started)次のページを参考にしました。
[NLP Getting Started Tutorial](https://www.kaggle.com/philculliton/nlp-getting-started-tutorial)“`py:realornot01.py
#! /usr/bin/python
#
# realornot01.py
#
# Feb/24/2020
# ————————————————————————–
import sys
import numpy as np
import pandas as pd
from sklearn import feature_extraction, linear_model, model_selection,
Python + Selenium(ChromeDriver)で「この接続ではプライバシーが保護されません」というエラーを無視する
主に開発環境などに対してSeleniumでChromeの動作を確認したい時に、テキトウに作った不正なSSLサーバー証明書を使用していると「この接続ではプライバシーが保護されません」というChromeのエラーが出て止まってしまうことがある。
これを無視する方法を記す。## 解決方法
ChromeOptionsの「acceptInsecureCerts」を有効にする
これにより、不正なSSLサーバー証明書を利用していてもアクセスを許可するようになる。参考:
https://www.selenium.dev/selenium/docs/api/java/org/openqa/selenium/chrome/ChromeOptions.html## 前提条件
・Windows 10
・Python 3.7.4
・pytest
・Selenium
・ChromeDriver (C:\selenium\chromedriver.exe)## 実装例
“` python:test_webdriver.py
import pytest
import time
import j
Pycharmでpipがエラーになる(pipが古いってエラー)
#背景
Pycharmのvenv環境でyamlをインストールしようとしたらエラーになった。#状況
PycharmのTerminalにて“`
pip install yaml
Collecting yaml
Could not find a version that satisfies the requirement yaml (from versions: )
No matching distribution found for yaml
You are using pip version 10.0.1, however version 20.0.2 is available.
You should consider upgrading via the ‘python -m pip install –upgrade pip’ command.
“`#解決まで
言われたとおりに“`
python -m pip install –upgrade pip
Requirement already up-to-date: pip in c:\pycharmproje
Kaggle Predict Future Sales
次の課題に submit するまでの流れです。
[Predict Future Sales](https://www.kaggle.com/c/competitive-data-science-predict-future-sales/)次のページを参考にしました。
[来月の商品の売上数を予測する〜Kaggle Predict Future Salesに挑む(その2)](https://yolo-kiyoshi.com/2019/03/23/post-1090/)
“`py:futuresales01.py
#! /usr/bin/python
#
# futuresales01.py
#
# Feb/23/2020
# ————————————————————————–
import sys
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# import seaborn as
colaboratoryデフォルトで入っているライブラリバージョン一覧 メモ
pythonバージョン表示
“`python
import platform
print(“python ” + platform.python_version())
“`
ライブラリのバージョン表示“`python
import pkg_resources
for dist in pkg_resources.working_set:
print(dist)
“`
#一覧
“`
python 3.6.9zmq 0.0.0
zipp 3.1.0
zict 1.0.0
yellowbrick 0.9.1
xlwt 1.3.0
xlrd 1.1.0
xgboost 0.90
xarray 0.14.1
wrapt 1.11.2
wordcloud 1.5.0
widgetsnbextension 3.5.1
wheel 0.34.2
Werkzeug 1.0.0
webencodings 0.5.1
wcwidth 0.1.8
wasabi 0.6.0
vega-datasets 0.8.0
urllib3 1.24.3
uritemplate 3.0.1
umap
Python、正規表現について
#正規表現についてよく使いそうなものをメモ。
・Mac
・python<メモ内容>
① ”.”は 改行以外の任意の1文字(数字含む)
② matchは、先頭からマッチするかを判定する関数、マッチする場合はmatchオブジェクト(正規表現をまとめたもの)を返し、マッチしなければNONEを返す。
③ searchは、途中でマッチするかどうかを判定する関数。2箇所ある場合は最初の1箇所のみ返す。マッチする場合はmatchオブジェクトを返し、マッチしなければNONEを返す。
④ splitは指定した文字で分割する関数、返り値はリスト型
⑤ findallは、指定した文字を**全て**返す関数、返り値はリスト型#(1)例題
“`
import retext1 = ‘abcde’
text2 = ‘a’
text3 = ‘1234’
text4 = ‘a1234’
text5 = ‘a1234a567’
text6 = ‘住所は123-3456東京都中央区999-9999’
text7 = ‘〒123-1234東京都中央区999-9999’
text8 = ‘〒1231234東京都
AnacondaでPython3.8を使う
Anacondaのインストーラーで入るPythonのバージョンが3.7だったので3.8はまだ使えないのかと思っていたがどうも違うらしい。
「[Anaconda Individual Edition 2020.02: New Name, Exciting Features](https://www.anaconda.com/anaconda-individual-edition-2020-02/)」を読んでみると主要なOSSプロジェクトが3.8に未対応なためインストーラーは3.7にしていると書いてある。
上記リンクにある通り`conda create -n py38 anaconda=2020.02 python=3.8`を実行すると普通に3.8が使えた。ちなみに、python3.8だけの環境を作りたい場合は`conda create -n py38 python=3.8`でいい。
楽にvscode+venvで仮想環境(Windows)メモ
#環境を作成
C:\Users\USERNAME\envのディレクトリで仮想環境を管理
ENVNAME = 環境名
env = 環境管理用フォルダ名
USERNAME = 自身ののユーザーネーム“`
C:\Users\USERNAME> python -m venv env/ENVNAME
“`
#アクティベート
“`
C:\Users\USERNAME> env\ENVNAME\scripts\activate
“`
#VScodeと接続
“`
(ENVNAME) C:\Users\USERNAME> \code
“`?????
VScodeでファイル > 基本設定 > 設定 > python.venvPath を~/envに変更??#環境を適用
VScodeの一番下のバーのPython x.x.x 64-bitをクリックし環境を選択して変更
#参考
[Pythonでvenv仮想環境を使う](https://jade.alt-area.jp/archives/510#VS_Code(https://jade.alt-area.jp/archives/5
SQLite3 で、たった2行追加して拡張ライブラリ(拡張SQL関数)を使おう!
# はじめに
SQLite3 では、PostgreSQL の EXTENSION (拡張)と同じように、共有ライブラリを拡張ライブラリとして導入することが可能です。実際、**enable_load_extension と load_extension の2行だけを追加することで拡張ライブラリを使うことができます!**
例として、[SQLite Contributed Files](https://www.sqlite.org/contrib/download/)で公開されている拡張SQL関数(extension-functions.c)を導入して使ってみましょう。
SQLite3 は他のRDBMSと比べて、SQL関数が少ないのですが、拡張SQL関数を導入することで補うことができます。CentOS7で、SQLite3 CLI(Command Line Intferface)、python3、C言語で導入してみましょう。# 拡張SQL関数の入手、構築
[SQLite Contributed Files](https://www.sqlite.org/contrib/download
chromeのcookieの内容をpythonで取得
#備忘録
chromeのcookieの内容を取得するpythonコード(ほぼ丸パクリ)
その後sys.exit(main())で結果を標準エラー出力
cookieFileとhostKeyは各自必要な内容を入力
それぞれファイルパスとcookieのhostkey
cookieのhostkeyは事前にわかっていないといけないのでchromeのデベロッパーから見つけるか
コード中のc.executeのwhereとformatを削除して、printで出力してあげて探す“`cookie.py
# Used information from:
# https://stackoverflow.com/questions/463832/using-dpapi-with-python
# http://www.linkedin.com/groups/Google-Chrome-encrypt-Stored-Cookies-36874.S.5826955428000456708import sqlite3
import sys
from ctypes import *
from ctypes.
ぜんぜんわからないから雰囲気でやったPython3での顔認識・モザイク処理。
これはお勉強の雑なメモです。頭のいい人助けて。
「PythonによるAI・機械学習・深層学習アプリの作り方」より、顔認識・モザイクの処理のやつをやる。この本はすごい。
下のこれをやって画像にモザイクをかけた。
“`py
import matplotlib.pyplot as plt
import cv2
def mosaic(img, rect, size):
# モザイクをかける領域を取得
(x1, y1, x2, y2) = rect
w = x2 – x1
h = y2 – y1
i_rect = img[y1:y2, x1:x2]
# 一度縮小して拡大する
i_small = cv2.resize(i_rect, ( size, size))
i_mos = cv2.resize(i_small, (w, h), interpolation=cv2.INTER_AREA)
# 画像にモザイク画像を重ねる
img2 = img.copy()
img2[y1:y2, x1:x2] = i




