
- 1. 統計初心者が時系列分析を学ぶための勉強法
- 2. mutagenでmp3とflacの埋め込み画像を表示
- 3. binary tree traverseのわかりにくさ
- 4. 【python】収穫できるリンゴとオレンジの数を求めるプログラム
- 5. 【AtCoder】ABC085C – OtoshidamaのPython回答
- 6. 【python】得点を丸め込むプログラム
- 7. Wiktionaryの効率的な処理方法を探る
- 8. 【EC2】seleniumでスマホの画面キャプチャを撮る方法
- 9. 【Python】変数前方のアスタリスクの役割。入力値を分割し変数に代入
- 10. 【python】listの各要素を一つづつ比較し勝敗を出すプログラム。zip()
- 11. 【python】2番めに小さな値を求める。
- 12. HackerRnakメモ
- 13. 【Python】シンプルな日⇒英翻訳ツールつくってみた
- 14. 【Pyto】スマホをPC用フリックキーボードにしてみた
- 15. TweepyとcronでTwitterボットを作ってみた話
- 16. AtCoder Grand Contest 過去問チャレンジ 2
- 17. Numpyで特定のindex以外を抽出する方法
- 18. pythonで特定のフォルダ内のExcel一覧を再帰的に取得してExcelに書き出す。
- 19. 機械学習の統計量を特徴量として加える際のスマートな書き方
- 20. 最小の例で理解する「ディープコピー」「シャローコピー」
統計初心者が時系列分析を学ぶための勉強法
私が個人的に開催しているエンジニア勉強会の2019年[Advent Calendar](https://qiita.com/advent-calendar/2019/study-co)で、[『統計初心者がベイズ統計学に入門するまでの勉強法』](https://qiita.com/ueniki/items/d02a81766ff65bde8a0c)という記事を書いたら、とても好評でした。
そこで今回は、統計初心者が時系列分析を学ぶための勉強について書いていければと思います。
# この記事の目的と対象者
この記事は、統計の基礎はある程度勉強したことがあるという人が、立派に「時系列分析」統計学の一大トピックについて語れるようになることを目指します。
時系列分析の全体像を語れるようになるぐらいまでがこの記事のゴールです。
時系列分析の中でも、**状態空間モデル**という分析モデルを理解できるようになるところまでをゴールとします。
ここで紹介する書籍は、プログラミンを手を動かして学べる系の書籍ですので、プログラミングの知識は必須とします。
# 時系列分析とは
## 時系列データ
mutagenでmp3とflacの埋め込み画像を表示
**Python 3.7.3** で動作確認
“`python
import mutagen
from io import BytesIO
from PIL import Image# ファイル名は適宜変更してください
file = r”example.mp3″
# ファイル読み込み
audio = mutagen.File(file)# 画像のリストを取得
if ‘audio/mp3’ in audio.mime:
images = for i in audio if “APIC” in i]
elif ‘audio/flac’ in audio.mime:
images = audio.picturesfor imgb in images:
# 画像を表示用に変換
img = Image.open(BytesIO(imgb.data))
img.show()
“`検索しても画像を新たに埋め込む記事ばかりで、埋め込み画像を表示する記事が見つけられなかったから書いてみました。
**”APIC” == i
binary tree traverseのわかりにくさ
binary tree
下記のwikiのリンクの図があったときに、
https://ja.wikipedia.org/wiki/%E4%BA%8C%E5%88%86%E6%9C%A8#:~:text=%E4%BA%8C%E5%88%86%E6%9C%A8%EF%BC%88binary%20tree%3B%20%E4%BA%8C,%E3%81%A7%E3%81%82%E3%82%8B%E3%82%82%E3%81%AE%E3%82%92%E3%81%84%E3%81%86%E3%80%82・root: 一番上の点=②
・node:点=②〜11の全ての点
・link:つないでいる線=②〜11を繋ぐ全ての線
を指している。#traverseについて
“`python
#下記のような関数について (Postorder)
#getLeftChild=左側の点に移動
#getRightChild=右側の点に移動
#getRootVal=一番上の点に移動
#つまり、下記の場合、右をとって、左をとってから、真ん中をとる。
#wikiでいうと、2-5-11-6-7-4-9-5-2
def tr
【python】収穫できるリンゴとオレンジの数を求めるプログラム
#【python】収穫できるリンゴとオレンジの数を求めるプログラム
個人メモです。
##設問
家の敷地内(座標s~t)に入ったリンゴの数をカウントする。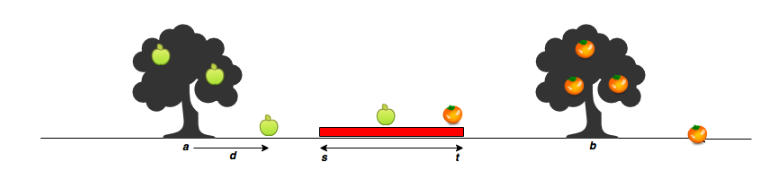
s:家の始点
t:家の終点
a:りんごの木の位置
b:オレンジの木の位置
apples:リンゴの落下地点(相対)
oranges:オレンジの落下地点(相対)[URL](https://www.hackerrank.com/challenges/apple-and-orange/problem)
▼sample input
“`python:
s=2
t=3
a=1
b=5
apples=[-2,2,1]
oranges=[5,8,-2,-1]
“`▼sample output
“`python:
2
1
“`▼my answer
“`python:
def
【AtCoder】ABC085C – OtoshidamaのPython回答
AtCoder Beginners Selectionから,ABC085C – Otoshidamaを解きました.
問題は[こちら](https://atcoder.jp/contests/abs/tasks/abc085_c).## 解法
Pythonで書いてます.
“`python
n, y = list(map(int, input().split()))a = 0 # The num of 10000 yen
b = 0 # The num of 5000 yen
c = 0 # The num of 1000 yenyen_a = 10000
yen_b = 5000
yen_c = 1000target = y – yen_c * n
coef_a = yen_a – yen_c
coef_b = yen_b – yen_c
a = int(target / coef_a)
if a > n or target < 0: a = b = c = -1 else: while(a >= 0):
if(coef_a *
【python】得点を丸め込むプログラム
#【python】得点を丸め込むプログラム
個人用メモです。
##設問
– ①得点と②その得点の次の5の倍数との差が3未満(less than)の場合、①を丸め込んで②にする。
– 得点が38未満(less than)の場合は丸め込みしない。▼sample input
“`python:
73
67
38
33
“`▼sample output
“`python:
75
67
40
33
“`▼my answer
“`python:
def gradingStudents(grades):
finals=[]
for grade in grades:
if grade >= 38:
a = str(grade)[1]
if a == “3”:
grade += 2
elif a==”4″:
grade += 1
elif a==”8″:
Wiktionaryの効率的な処理方法を探る
Wikipedia の関連プロジェクトとして Wiktionary という多言語辞書があります。Python で全文を効率的に処理する方法を探ります。
この記事のスクリプトは以下のリポジトリに掲載しています。
*
# 概要
Wiktionary としては最大規模の英語版を対象とします。
* [Wiktionary, the free dictionary](https://en.wiktionary.org/wiki/Wiktionary:Main_Page)
Wikipedia と同様に、Wiktionary もダンプデータが提供されます。内容の収集にスクレイピングは禁止されており、ダンプデータの利用が推奨されます。
ダンプデータは bzip2 で圧縮されて提供されます。これを展開しないで圧縮されたまま利用します。(展開すると 6GB ほどになります)
*
【EC2】seleniumでスマホの画面キャプチャを撮る方法
#【EC2】seleniumでスマホの画面キャプチャを撮る方法
スマホ用のUAをoptionsの引数に追加すればOK。
**▼iphone safariの場合**
“`pyhthon:追加するオプション
options.add_argument(‘–user-agent=Mozilla/5.0 (iPhone; CPU iPhone OS 10_2 like Mac OS X) AppleWebKit/602.3.12 (KHTML, like Gecko) Version/10.0 Mobile/14C92 Safari/602.1’)
“`**▼コード全体例**
“`python:
#-*- coding: utf-8 -*-from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoptions = Options()
options.headless = True#キャプチャする画面サイズを指定
options.add_argument
【Python】変数前方のアスタリスクの役割。入力値を分割し変数に代入
#【Python】変数前方のアスタリスクの役割。入力値を分割
下記のような表記で実行されていることの確認。
`a,*b = [1,2,3,4,5]`
**▼処理内容**
一番最初の要素をaに代入。
それ以降をbに代入。“`python:
a,*b = [1,2,3,4,5]
print(a)
print(b)#出力
1
[2,3,4,5]
“`**▼基本の確認**
変数を要素分用意すると、一つ一つ格納できる。“`python
a,b,c=1,2,3
print(a)
print(b)
print(c)#出力
1
2
3
“`▼要素の数と変数の数が合わないとエラー
“`python
a,b=1,2,3
print(a)
print(b)#出力
too many values to unpack (expected 2)
“`**▼アスタリスクを使うことで変数と要素の数を合わせる必要がなくなる**
・最初や間にも使える。
“`python
a,*b,c,d=1,2,3,4,5,6,7,8,9
print(a)
pr
【python】listの各要素を一つづつ比較し勝敗を出すプログラム。zip()
#【python】listの各要素を一つづつ比較し勝敗を出すプログラム。zip()
2つの配列が与えられたときに、各々の1つ目の要素を比較し、勝った方に1点を与え、それぞれの点数を出力する。
Alice対Bob。勝った方に1点ずつ入る。引き分けの場合0点。
▼sample input
“`
17 28 30
99 16 8
“`▼sampel output
“`
2 1
“`▼my answer
“`python:
def compareTriplets(a, b):
#勝敗数カウント用の変数をセット。初期値0
alice=0
bob=0#与えられた配列の要素を一つづつ比較
for pair in zip(a,b):
if pair[0]>pair[1]:
alice+=1
elif pair[0]
【python】2番めに小さな値を求める。
#【python】2番めに小さな値を求める。
個人メモです。・与えられた数値と名前を入れ子の配列化(nested list)
・2番目に小さい数値を持つ人の名前をアルファベット順で抜き出す▼sample input
“`
5
Harry
37.21
Berry
37.21
Tina
37.2
Akriti
41
Harsh
39
“`▼my answer
“`python
if __name__ == ‘__main__’:#値を格納する配列を準備
nameScores=[]
scores=[]for _ in range(int(input())):
name = input()
score = float(input())scores.append(score)
nameScore=[name, score]
nameScores.append(nameScore)#名前のアルファベット順にソート
nam
HackerRnakメモ
#HackerRnakメモ
個人メモです###基本使用言語
python3・`raw_input()`
キーボード入力(python2)
python3の場合はinput()n = input()
n = int(input())・`.strip()`
空白文字(スペース、タブ、改行)の削除input().strip()
・`sprit()`
指定した文字で区切り配列にする。
()内に指定がない場合は、スペースやTABで区切るinput().split()
・`STDIN`
キーボード入力された値
標準入力・difference
差分
difference of the two numbers (first – second).・puroduct
掛け算
product of the two numbers.・`a//b`
割り算。商を整数で返す
小数点以下は切り捨て・`for文`
for 変数 in シーケンス“`
n = int(raw_input())for i in range(n):
print(i*i
【Python】シンプルな日⇒英翻訳ツールつくってみた
##やりたいこと
Python等でコードを書いている時、変数名に使用する英単語が思い浮かばないことが多々あります。
今まではブラウザを立ち上げてgoogle翻訳を行なっていたのですが、ちょいと煩わしいと感じる今日この頃。
そんな英語力ゼロの自分をサポートする、簡単な日⇒英オンリーの翻訳ツールを作ってみました。

↑ 出来上がりはこんな感じ。
なるべくスピーディな立ち上がりと、少ない操作数で実行できるツールを目指しました。
肝心の翻訳機能はgoogletransライブラリを活用しています。目新しい使い方はしていないので説明は割愛。
参考ページ ⇒ [Python – googletransを試してみました。](https://dev.classmethod.jp/articles/python-py-googletrans/)##環境
W
【Pyto】スマホをPC用フリックキーボードにしてみた

## はじめに
若者のPC離れと言われる中、タイピングができない人が多くなってきているそうです。しかし若者はPCが使えない代わりにスマホの扱いには慣れており、現在の女子高生のフリック入力はガラケーギャルもびっくりするほどの速さです。
それならPCの入力もフリックでやってしまえば良いのではないか、ということは以前から言われていたようですが、手軽に試せるソフトはありませんでした。
そこで、iOSでPythonプログラミングができる[Pyto](https://pyto.app/)というアプリを使って、フリックキーボードを作ってみました。
## 既存の製品
– [FlickTyper](http://flicktyper.com)
スマホとPCをこの装置で繋ぐとスマホがフリックキーボードになります。また、Bluetooth
TweepyとcronでTwitterボットを作ってみた話
# この記事に書いてあること
PythonでTwitterボット作ってみたのでそこでやったことをまとめました。
TwitterAPIの登録申請してLinuxサーバにPythonとTweepyをインストールしてPythonでプログラムを書いてcronで時間になったらプログラム起動してつぶやくという流れです。# TwitterAPIのアカウント作成
Pythonでやってみたかったので、いろいろ調べたらTweepyというTwitterのAPIをラップしたサービスを発見。使いやすそうだと思ったのでこれを使ってみる。
しかしいずれにしてもTwitterAPIのアカウントが必要です。私は[この記事](https://qiita.com/kngsym2018/items/2524d21455aac111cdee)を参考にアカウントを申請しました。
これで取得する以下4項目が後程重要になります。
– CONSUMER_KEY
– CONSUMER_SECRET
– ACCESS_TOKEN
– ACCESS_TOKEN_SECRET### 参考
– [Twitter API 登録 (アカウント
AtCoder Grand Contest 過去問チャレンジ 2
# AtCoder Grand Contest 過去問チャレンジ 2
## [AGC009A – Multiple Array](https://atcoder.jp/contests/agc009/tasks/agc009_a)
AN のボタンから A1 のボタンへと逆順に押していくのはすぐ分かる. Ai が Bi の倍数であるということは、Ai mod Bi = 0 ということだから、Ai mod Bi が0じゃないとき、Bi – Ai mod Bi 回押せばいい. ところで、それまでに押した回数分だけ Ai が増えていることに注意. 以上をもとに、以下のようなコードを書いて答えを求めた.
“`python
N = int(input())A = [None] * N
B = [None] * N
for i
Numpyで特定のindex以外を抽出する方法
あるarrayから特定のインデックス以外を抽出する方法です。
“`Python
# 0~99の数字からランダムに10個取ってくる
arr = np.random.randint(0, 100, 10)
# > array([74, 29, 6, 79, 76, 13, 3, 56, 25, 50])# 奇数番目の数値をarrから除外したい
odd = [1,3,5,7,9]# 方法① リスト内包表記
index = [i for i in np.arange(len(arr)) if i not in odd]
arr_even = arr[index]# 方法② True/Falseでマスキングする
index = np.ones(len(arr), dtype=bool)
index[odd] = False
arr_even = arr[index]# 方法③ np.delete
arr_even = np.delete(arr, odd)“`
方法③が一番スッキリしていますが、どれも時間的にはあまり変わらないのでお好きな方法でどうぞ。
pythonで特定のフォルダ内のExcel一覧を再帰的に取得してExcelに書き出す。
“`python
# import libraries
import os
import pandas as pd
from glob import glob# Configure Folder path
mybooks = glob(r”FOLDERPATH\**\*.xls*”,recursive=True)df = []
for mybook in mybooks:
df.append([mybook,os.path.basename(mybook)])# Exchange ListObject to Dataframe
df = pd.DataFrame(df)# Dump to ExcelFile
outputFilename = “filename.xlsx”
outputFolder = r”filepath”
outputFileFullpath = outputFolder + “\\” + outputFilename
df.to_excel(outputFileFullpath,’List’)print(
“ファイル
機械学習の統計量を特徴量として加える際のスマートな書き方
数値データの行方向の統計量を特徴量として生成するコードの書き方です。
## ありがちな特徴量生成
まずは良く見る書き方
“`Python
# 一個一個付け加えていくやり方
df[“sum”] = df.sum(axis=1)
df[“max”] = df.max(axis=1)
df[“min”] = df.min(axis=1)
df[“mean”] = df.mean(axis=1)
df[“median”] = df.median(axis=1)
df[“mad”] = df.mad(axis=1)
df[“var”] = df.var(axis=1)
df[“std”] = df.std(axis=1)
df[“skew”] = df.skew(axis=1)
df[“kurt”] = df.kurt(axis=1)df.head()
“`これでも良いが、拡張性やメンテナンスを考えるとちょっと気持ち悪い。
## スマートな特徴量生成
“`Python
func_list =[“sum”, “max”, “min”, “mean”, “median”,
最小の例で理解する「ディープコピー」「シャローコピー」
ディープコピー・シャローコピー…
しばしば混乱の原因になる言葉です。
ここでは、各コピー方法の違いが端的に現れる最小の例を使って、各コピー方法でプログラムの動きがどう違ってくるかを見ていきたいと思います。
# 断り書き
断り書きです。別に気にならないという方は「なにやるの?」の章まで読み飛ばしてください。
## 「共有渡し」という言葉を使います
「pass-by-sharing」「call-by-sharing」「共有渡し」「参照の値渡し」などと呼ばれているやり方の呼び方を、この記事内では「共有渡し」で統一します。
なお、筆者がこの用語を推奨しているわけではありません。複数言語の仕様を比較する便宜上、この記事内で用いる名前をつけているだけです。
## 代入の場合にも「○○渡し」という言葉を使うことにします
この記事内では、「参照渡し」「共有渡し」という言葉を「変数代入の際の方式」を表す際にも使います。
通常は関数に引数を渡す時に用いる言葉ですが、ほぼ同様の概念が代入の場合も成立するので、言葉もそのまま用いることにします。
(これは私見ですが、「○○渡し」という言




