
- 1. 【Nuxt Vue】ファイルダウンロード(エクセル)する。
- 2. git cloneしたVueプロジェクトを仮想環境で起動できない!!
- 3. Puppeteerで繰り返し処理
- 4. node_modulesをインストールして死にかけた話
- 5. CentOS: Node.jsインストール
- 6. npm installについての質問です。
- 7. WindowsでReactの環境構築をしてみる
- 8. LINEで文字数をカウントしてくれるともだちをつくる
- 9. nodeとnpmとyarnをmacから削除したコマンド
- 10. Stripeで子アカウントへの入金タイミングをマニュアルにする | Node.js | 2020
- 11. Dockerを使った、サクッと作ってパッと捨てられるNode.js環境
- 12. Selenium IDEをcronで実行しようとした時に失敗した。 env: node: No such file or directory
- 13. 最速で画像を圧縮するAlfred Workflowを作った
- 14. Node.js: Lambda で MariaDB のデータを削除 (Delete)
- 15. Node.js: Lambda で MariaDB のデータを更新 (Update)
- 16. Node.js: Lambda で MariaDB のデータを読む (Read)
- 17. Node.js: Lambda で MariaDB のデータを作成 (Create)
- 18. [質問]jsで取得したデータをデータベースに保存する方法
- 19. [Express]DBのデータを利用しつつイベントハンドラの実行、関数の定義・実行をする
- 20. JavaScript SDK (SQL API)を見てみる (Part.3)
【Nuxt Vue】ファイルダウンロード(エクセル)する。
サーバー側の処理は問題ないことを確認したが、クラアント側でうまく受け取れずに少しハマってしまいました。
また似たようなことがありそうなのでメモ。#サーバー側の処理
expressを使用、詳細は省略。
“`Server.js
app.get(‘/download_excel_file’, async(req, res) => {
try {
const excelPath = ‘エクセルファイルのパス/ファイル名.xlsx’
return res.status(200).download(excelPath)
} catch (err) {
return res.status(500)
}
}
“`#クライアント側の処理
こちらも詳細は割愛しますが、要は { responseType : ‘blob’ } が必要で、抜けてしまっていた為にうまく受け取れませんでした。
responseTypeが何かわからない、という方はこちら参照願います。
https://developer.mozilla.org/ja/docs/XMLHttpRequ
git cloneしたVueプロジェクトを仮想環境で起動できない!!
#はじめに
タイトルにもある通り、リモートのVueプロジェクトをローカルの仮想環境で動かそうとした際に二転三転とエラーが重なって解決に時間がかかったので、解決方法及び内容理解のための内容です。
#環境
ローカル
Vagrant 2.2.7
Virtualbox 6.1.6
Vue 2.6.11仮想環境
centos 7.2共有フォルダの設定
“`file:vagrantfile
config.vm.synced_folder “..”, “/home/vagrant/vue_project”,
create: true, owner: “vagrant”, group: “vagrant”
“`#内容
まずはgit cloneでリモートリポジトリからソースをクローン“`
git clone [リポジトリURL]
“`
今回はソースコードの中にvagrantファイルを入れてあるので、vagrantfileのあるディレクトリまで移動。“`
cd vue_project/vagrant
“`
仮想環境立ち上げて、ssh接続“`
vagran
Puppeteerで繰り返し処理
# はじめに
[【初心者】Puppeteerでよく使うコードベスト3](https://qiita.com/Shin/items/aa5b82d1f0505ca9608f)
に処理追加。
繰り返し処理を追加しました。# 繰り返し処理するコード
以下のようにdo whileで処理を記載する。“`javascript
do {
// 処理
} while(true);
“`# 最終的なコード
“`javascript
const puppeteer = require(‘puppeteer’);
// ID・アカウント認証する時はここでID・アカウント情報を読み込む
const {USER, PWD} = require(‘./config.json’); // 認証が必要であれば別ファイルのconfigファイルから読み込む(async () => {
const browser = await puppeteer.launch({
headless: false, // ブラウザの動きを表示
slowMo: 50
node_modulesをインストールして死にかけた話
## node_modulesをインストールして死にかけた話
React学習のため
“`ruby:ターミナル
$ npm install
“`npmをインストールしてwebpackやreactをインストールしたいとコマンドを実行。
無事`node_modules`をインストール完了!これからパッケージのインストールしていくぞ!!
一旦Githubにコミットしておこう。
##### ところが。。
差分があまりにも大きすぎてGithubにコミットできないようになっていた。
エラー文を読解して理解した。
どうすればいいんだろう。初学者の私は必死で解決策を考えました。
##### あっ、そういえば`gitignore`なるものがあったな
“`ruby:gitignore
node_modules
“`こちらを追加してgit commit
制限文字数ちょうどで書いた文章を添削してもらうとき、先輩に直された文章が文字数を超過していたらいたたまれない気持ちになります。もうちょっと減らしてもらえますか?なんて言えたもんじゃないです。
また、文字数を数えること自体もそれはそれで面倒です。ESの形式によっては数えてくれるものもありますが、大抵私はWordに貼り付けて文字数を数えていました。面倒です。
そこで、カウント係の友達をもう一人トークに招待し、文章の文字数を数えてもらうことを思いつきました。が、そんな都合のいい友達はいません。よって、LineBOTを召喚します。
## 環境
せっかくなので、研究に必要で勉強している最中のNode.jsを使ってみることにしま
nodeとnpmとyarnをmacから削除したコマンド
“`
$ which node
→ /usr/local/bin/node
$ sudo rm -rf /usr/local/bin/node
“`“`
$ brew uninstall nodebrew
$ brew uninstall node
“`“`
brew: brew uninstall yarntarball: rm -rf “$HOME/.yarn”
npm: npm uninstall -g yarn
ubuntu: sudo apt-get remove yarn && sudo apt-get purge yarn
centos: yum remove yarn
windows: choco uninstall yarn
“`## 参考
[How Do I Uninstall Yarn](https://stackoverflow.com/questions/42334978/how-do-i-uninstall-yarn)
[ローカルからnode.jsを削除する](https://qiita.com/gaipoi/it
Stripeで子アカウントへの入金タイミングをマニュアルにする | Node.js | 2020
参考
[Stripe Connect 101](https://qiita.com/y_toku/items/7bfa42793801dfc5415d)
これ↓をnodeでやりたい
>入金タイミングをマニュアルにするには、payout_schedule[interval]を manual とします。Manual とすると、Payout 処理がされると入金に至る仕組みです。なお、決済が完了してから 90 日間以内に Payout をしてください。これは入金なので、子アカウントの残高から子アカウントの銀行口座へ入金するための処理となります。
こんな感じでできた
“`js
stripe.accounts.create(
{
type: ‘custom’,
country: ‘JP’,
email: email,
business_type: “individual”,
settings:{
payouts: {
schedule:{interval: “manual”}
Dockerを使った、サクッと作ってパッと捨てられるNode.js環境
待ちに待ったWindows 10 May 2020 Update(WSL2)もリリースされ、WindowsへのDockerの敷居も下がってきそうです。
そこで、Dockerで作る使い捨てやすいNode.jsの開発環境についてまとめておこうと思います。
## Why NodeJS with Docker :thinking:
※前置きです(読み飛ばし可)
### 現状のバージョン管理方法
– Mac (メイン)
– [anyenv](
Selenium IDEをcronで実行しようとした時に失敗した。 env: node: No such file or directory
# Selenium IDEを Command-line Runnerで動かしCronで動かしたが
エラー内容
“`bash
env: node: No such file or directory
“`
チーン# 解決策
パスを通す。# Selenium IDE使ってますか?
まぁまぁ自由度が高いし簡単に作れますし楽しいですね。# nodeがない
作成したSelenium IDEをコマンドライン[^Command-lineRunner]で実行しました。定期実行させる為にcronで実行すると以下のエラーが表示。
“`bash
env: node: No such file or directory
“`
nodeがないよーって言われました。コマンドラインで動かすには以下がインストールされていないとダメです。
– node version 8 or 10
– npm
– selenium-side-runner
– 使用したいブラウザのドライバ# いやインストールしてるわ
これらのものはnodebrew経由でインストールしていたので、“`
最速で画像を圧縮するAlfred Workflowを作った
# はじめに
PNGやGIFの圧縮は、ブログ記事やGitHubのPull Requestの実行画像貼り付けとかで割とあります。自分は[TinyPNG](https://tinypng.com/)や[iLoveIMG](https://www.iloveimg.com/ja) を利用していましたが、プラウザを開きファイルをアップロード・圧縮しダウンロードという手順が毎回面倒でした。
なので、[alfred-imagemin](https://github.com/kawamataryo/alfred-imagemin) という**PNG / JPEG / GIFを手軽に圧縮するAlfred Workflow**を作ってみました。
(GIFでも使えるというのが嬉しいポイントです)この記事ではalfred-imageminの概要と、仕組みを紹介します。

フォルダー構造
“`text
$ tree -a
.
├── .env
├── function_update.sh
├── index.js
└── test_local.js
“`“`js:maria_delete/index.js
// —————————————————————
// maria_delete/index.js
//
// Jun/07/2020
//
// —————————————————————
var mysql = require(‘mysql2/promise’)// —————————————————————
async function main(id_in)
{
console.error(“id_in = ” + id_in)
const host = `${proc
Node.js: Lambda で MariaDB のデータを更新 (Update)
フォルダー構造
“`text
$ tree -a
.
├── .env
├── function_update.sh
├── index.js
└── test_local.js
“`“`js:maria_update/index.js
#! /usr/bin/node
// —————————————————————
// maria_update/index.js
//
// Jun/07/2020
//
// —————————————————————
var mysql = require(‘mysql2/promise’)// —————————————————————
function get_current_date_proc ()
{
const today = new Date ()
var
Node.js: Lambda で MariaDB のデータを読む (Read)
フォルダー構造
“`text
$ tree -a
.
├── .env
├── function_update.sh
├── index.js
└── test_local.js
“`“`js:maria_read/index.js
// —————————————————————
// maria_read/index.js
//
// Jun/08/2020
//
// —————————————————————
‘use strict’// —————————————————————
async function read01 (mysql,host,user,password,data_base)
{
try {
console.error (“*** read01 *** start ***”)
Node.js: Lambda で MariaDB のデータを作成 (Create)
フォルダー構造
“`text
$ tree -a
.
├── .env
├── function_update.sh
├── index.js
└── test_local.js
“`“`js:maria_create/index.js
// —————————————————————
// maria_create/index.js
//
// Jun/07/2020
//
// —————————————————————
var mysql = require(‘mysql2/promise’)
// —————————————————————
function dict_append_proc (dict_aa,id_in,name_in,population_in,date_mod_in)
{
var uni
[質問]jsで取得したデータをデータベースに保存する方法
###前提・実現したいこと
・自身プログラミング経験が浅いため、お伝えする内容に不備や、漏れがあれば
ご指摘いただいても大丈夫です###[実現したいこと]
・amazonの商品をスクレイピングで、家電の商品の価格を抽出した情報を
データベースを使用して保存したい####発生している問題
####[現状]
・ターミナルにて、npm i puppeteer
puppeteerをインストール
・プロジェクトのディレクトリ内に、test.jsamazonのサイトまでは、いきデータは抽出できているかと
思うのですが、その先が、
どう対応すればいいのかわからず、進めることができません。データベースは、MySQLを予定しております。
該当のソースコード
・test.js
const puppeteer = require(“puppeteer”);
(async () => {
const browser = await puppeteer.launch({
headless: false, // 動作確認するためh
[Express]DBのデータを利用しつつイベントハンドラの実行、関数の定義・実行をする
# はじめに
所有する技術書を登録(追加)、内容の更新、削除するWebアプリケーションを実装した。
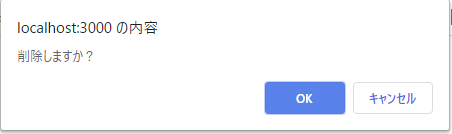
そこから、削除機能について「本当に削除していいですか?」という確認を行うプロセスを追加したかった。
# 作ったのはどんなアプリなの
まだまだ拡張の余地はあるが、現時点での完成形を紹介する。
DBに登録されているデータを表示しているが、それを削除する様子。
を見てみる (Part.3)

# この記事について
本記事は、2020年3月6日 (米国時間) にて、Azure Cosmos DB に新しく Free Tier (無償利用枠) が登場したことに伴い、改めて Azure Cosmos DB を色々と触っていく試みの 5 回目です。
今回も、[前回記事][PrevLink2] 同様、 Microsoft Azure Cosmos JavaScript SDK について見ていきたいと思います。– [2020年から始めるAzure Cosmos DB – JavaScript SDK (SQL API)を見てみる (Part.1)][PrevLink1]
– [2020年から始めるAzure Cosmos DB – JavaScript SDK (SQL API)を見てみる (Part.2)][PrevLink2]# 対象読者
– Azure Cosmos DB について学習したい方
– N





