
- 1. meta-learningのベンチマークデータセットを簡単にloadできるtorchmetaについて
- 2. 図鑑 データ構造 アルゴリズム Python
- 3. Django~settings.py編~
- 4. 危険なレバレッジETFは株より安全! 92年分のデータで統計的に検証してみた結果
- 5. tensorflow.python.framework.errors_impl.FailedPreconditionErrorの発生と解決
- 6. 【Pytorch】MaxPool2dのceil_mode
- 7. atom(仮想環境)のhydrogenを設定する手順
- 8. ゼロから始めるLeetCode Day72 「1498. Number of Subsequences That Satisfy the Given Sum Condition」
- 9. アナログメーターの読取りは、例題のMNISTで出来ます。
- 10. SPSS Modelerの再構成ノードをPythonで書き換える。購入商品カテゴリごとの集計
- 11. Pythonで実装するアヒル本「StanとRでベイズ統計モデリング」
- 12. PycharmでDjangoでアプリケーションを作成する手順~準備編~
- 13. [光-Hikari-のPython]09章-01 クラス(オブジェクトの基礎)
- 14. 数学記号がわからないならプログラムを書けばいいじゃない。
- 15. Oracle NoSQL Database Cloudシミュレータ を使い PythonでNoSQLをさわってみる
- 16. Pyhtonの基礎復習はこれだけ ~3~
- 17. C言語で16文字でセグフォらせる
- 18. Concatenateの理解
- 19. なろう小説APIを試してみた2
- 20. cx_Oracle が使える Docker イメージ
meta-learningのベンチマークデータセットを簡単にloadできるtorchmetaについて
# はじめに
MNISTやCIFAR10といった画像分類タスクのベンチマークデータセットはtorchvisionで簡単に読み込むことができました。meta-learningのベンチマークとして用いられるOmniglotやMiniImageNetなどのデータセットに対してもこのようなものはないのかと思い調べていたところtorchmetaというライブラリに出会ったのでご紹介することにしました。
meta-learningにおいては通常の学習に比べdataloaderの設計が少し面倒なのですが、それもtorchmetaではうまいことやってくれるので非常に便利です。
# meta-learningについて
ここではN-way K-shotのfew-shot learningにmeta-learningを用いるケースを考え簡単にmeta-learningについてご紹介します。
N-way K-shotのfew-shot learningとは、まず大規模な学習データセットでモデルを学習して、学習後に学習データに含まれていなかった新たなN-classの画像について各classについてK枚ずつ
図鑑 データ構造 アルゴリズム Python
https://www.amazon.co.jp/dp/B08BZFX31V
データ構造とアルゴリズムPythonの実践、トピック自体は複雑ですが、読みやすく理解しやすいように設計されています。アルゴリズムは、ソフトウェアプログラムがデータ構造を操作するために使用する手順です。明確で単純なサンプルプログラムに加えて、プログラムは、データ構造がどのように見え、どのように動作するかをグラフィック形式で示します。基本的なつのデータ構造をすべてイラストで解説,誌面がフルカラーなので、図の「動き」がわかりやすい,あなたはそれを簡単に、速く、うまく学びます。
Django~settings.py編~
#はじめに
この記事はDjangoでのsettings.pyの設定を忘れないようにメモするために書きました。#時間帯を合わせる
まずは時間帯を合わせましょう。
「settings.py」を開いて、ガーとしたの方までスクロールすると“`
LANGUAGE_CODE = ‘en-us’TIME_ZONE = ‘UTC’
“`
この部分が見つかるので、少し変更していきます。“`
LANGUAGE_CODE = ‘ja’TIME_ZONE = ‘Asia/Tokyo’
“`
このように変更することで、日本時間に合わせることができます。#アプリの登録
「settings.py」の一番上から少しスクロールし他ところに「INSTALLED_APPS」というところがあります。
ここにアプリケーションの構成情報を登録するために追加していきます。
ここではアプリ名を「app」としておきます。“`
INSTALLED_APPS = [
‘app.apps.AppConfig’,
]
“`
カッコ内の一番最初か一番最後にこのように追加します。
最後のカンマを忘れ
危険なレバレッジETFは株より安全! 92年分のデータで統計的に検証してみた結果
この記事はgithubにコードを含め上げてあります。
https://github.com/IntenF/leveraged_etf# 超短い結論
危険だと言われるレバレッジ・インデックスETFは用法用量を守ればオリジナルよりも安全かつ高収益資産!# 想定読者
– 株や投資に興味がある方
– 統計で株を語りたい方
– レバレッジETFが気になってる方# はじめに
僕が投資先を選定する上でレバレッジ・インデックスETF(以後レバレッジETF)に出会い。この記事はレバレッジETFが危険と言われるのはどうしても信じられなかったので自分で検証した記事です。僕は俗にあるレバレッジETFの特性は勘違いによって生まれていると思います。そこで、この記事を通してレバレッジETFの強みと弱みを”統計的”な側面から客観的に見ていただきたいという思いを込めて書いています。ぜひ、この機会にレバレッジETFの世界を一緒に眺めて見ませんか?きっと面白く思えるはずです。ただし、
*あくまで投資は自己判断で。*
申し訳ありませんが、僕は皆様のお金に責任は持てませんのでご注意ください。信じるも信じない
tensorflow.python.framework.errors_impl.FailedPreconditionErrorの発生と解決
# 概要
Kerasで単純なGANを実行するとき、tensorflowのエラーに躓いたので、その備忘録## やりたかったこと
– GANのサンプルコードを動かしみる
– 参考にさせていただいたのは
[こちら](https://qiita.com/triwave33/items/1890ccc71fab6cbca87e)##エラー内容
tensorflow.python.framework.errors_impl.FailedPreconditionError: Error while reading resource variable _AnonymousVar44 from Container: localhost. This could mean that the variable was uninitialized. Not found: Resource localhost/_AnonymousVar44/class tensorflow::Var does not exist.
[[node mul_28/ReadVariableOp (defi
【Pytorch】MaxPool2dのceil_mode
# ceil_modeとは
Pytorchの学習済モデル[torchvision.models.googlenet](https://pytorch.org/docs/stable/torchvision/models.html)をKerasに移植してみようと思ったら、気になることが。
MaxPool2dのceil_modeってなんでしょか。
ドキュメントをみると、「Trueの場合、出力シェイプの計算でfloor(切り捨て)ではなくceil(切り上げ)を使う」とある。
[torch.nn — PyTorch master documentation](https://pytorch.org/docs/stable/nn.html)
>ceil_mode – when True, will use ceil instead of floor to compute the output shape以下は、**torchvision.models.googlenet**で最初にでてくるMaxPool2D。
“`python
# 入力は (112, 112, 64)
Ma
atom(仮想環境)のhydrogenを設定する手順
#はじめに
atomで開発をしていく中で、途中までのコードを実行したいときありませんか?調べるとAtomをjupyterのように使用できるhydrogenというpackageがあったのでその設定方法を書いていこうと思います。私のような初心者ではエラーがなかなか解消できず、解決できた時は正直泣きました。笑
はじめての投稿かつ独学でやっているもので間違い等あれば指摘していただけると幸いです。#対象とする人
・atomのhydrogenを仮想環境下で設定したい方・atomでhydrogenを設定する際に以下のようなエラー文が出た方(atomでhydrogenを実行しようとしたきとにでるエラーです)
`Traceback (most recent call last): File “C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.7_3.7.2032.0_x64__qbz5n2kfra8p0\lib\runpy.py”, line 193, in _run_module_as_main “main”, mod
ゼロから始めるLeetCode Day72 「1498. Number of Subsequences That Satisfy the Given Sum Condition」
# 概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
[Leetcode](https://leetcode.com/)
Python3で解いています。
[ゼロから始めるLeetCode 目次](https://qiita.com/KueharX/items/6ee2502c3b620c795b70)
前回
[ゼロから始めるLeetC
アナログメーターの読取りは、例題のMNISTで出来ます。
人工知能を用いて アナログメーターの読取りを行うのに 教科書の例題にあるMNISTで出来ます。
まずは、カメラと照明を固定して撮影条件が一定となるように設置をします。一定の範囲内で撮影出来る事を保証できると、人工知能による予測精度が向上します。
次に、特定のアナログメーターを 事前に撮影して針の位置の状態をそれぞれ準備します。どの程度のデーターを準備するかは、要求する分解能に従いますが、20-30分解能もあれば、十分と思われます。
なぜなら、アナログメーター自体の精度(誤差)は、±2.5%や±1.6%程度あり、つまり、約5%や3%程度の誤差は、アナログメーターを使う時点で、許容されています。
有効桁数3桁、4桁の測定には、アナログメーターは向いていません。事前のデーターを多く用意するため、撮影条件や照明条件を振って、許容範囲内の状態を可能な限り撮影したり、画像処理でデーターを水増しましょう。
プログラム自体は、MNISTと同等のクラス分類です。データーが十分あれば、トレーニングとテストに分けたり、過剰適合の検証をしたり、パラメーターの調整をしたり、色々できます。
SPSS Modelerの再構成ノードをPythonで書き換える。購入商品カテゴリごとの集計
SPSS Modelerで縦持ちデータを横持ちに変換する再構成ノードをPythonのpandasで書き換えてみます。
#1.加工のイメージ
以下のID付POSデータから各顧客毎に①商品カテゴリごとの購入額合計と②商品カテゴリごとの購入割合を集計してみます。■加工前
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。
■加工後
顧客毎(CUSTID)に商品大分類(L_CLASS)の①商品カテゴリごとの購入額合計と②商品カテゴリごとの購入割合を集計します。

PycharmでDjangoでアプリケーションを作成する手順~準備編~
#はじめに
この記事はPycharmでDjangoを使ってアプリケーションを作成する準備の段階を書いていきます。
あくまで僕の手順なので、他の方の記事も見るとより理解が深まると思います。#新しいPycharmプロジェクトを作成する
1. Pycharmの左上のメニューバーから「ファイル」を選んでクリック。
2. その中の一番上の「新規プロジェクトを作成」をクリック。
3. ロケーションの部分にデフォルトで「untitled」とは言っているのでその部分を削除して、自分の好きなプロジェクト名を入れる。
4. 右下の作成を押すと新規のウィンドウに作成するか、今いるウィンドウで作成するか聞いてくるので、好きな方を選ぶ。
これでプロジェクトの作成は完了です。#仮想環境構築
今回はPipenvを用いて仮想環境の構築を行なっていきます。
Pycharmの左下のあるターミナルを開いてください。###インストールされているかの確認
まずインストールされているか確認します。“`
pipenv –version
“`
数字が出ればインストールされています。###インストールされてい
[光-Hikari-のPython]09章-01 クラス(オブジェクトの基礎)
#[Python]09章-01 オブジェクトの基礎
今まで、文字列や数値、データ構造の分野ではリストやタプルなどに触れました。データ構造の個所で触れましたが、これらは**オブジェクト**と言いました。さて、このオブジェクトとは何でしょう。まずはオブジェクトについて説明して少し掘り下げていきたいと思います。
##オブジェクトとは
まずは**Python Console**にて以下のコードを入力して確認してみましょう。“`.py
>>> S = ‘hello’
>>> type(S)
“`**S**という変数に’hello’という文字列を代入しています。さて、次に**type()**関数により、**\
**が出力されています。
これは、S変数がが現在**str型のオブジェクト**であることを意味しています。では、strオブジェクトの詳細を見てみましょう。以下のURLから閲覧できます。
[https://docs.python.org/ja/3/library/stdtypes.html#text-sequence
数学記号がわからないならプログラムを書けばいいじゃない。
#とある数学(というか数字)嫌いマンの伝説
* 数IIIと数Cをなんとなくのコレクション精神で履修してみるも、何もかも意味がわからない
* 原因をたどったらそもそも数Iあたりから既によくわかっていなかった
* 飲み会に行くと割り勘の計算ができない
* むしろ1000円上乗せぐらいならあげるからよしなにやっといてという気持ち
* なぜかプログラムは一般人レベルぐらいには書ける#で、なんで今更?
* なんか分析とかやってみたいの!かっこよさそうじゃん?
* 最終的には未来を予測してこの世界の神になるんじゃ!というわけで神を目指す数学嫌いマンは着々と数学の復習をしていったわけですが….。
数学記号あるじゃないですか。なんすか、あれ。知らんし。そこで思いついたのです。
数学記号がよくわからないならプログラムで実装してみたら良いのでは、と。#Σを実装してみる
とりあえず手始めにΣの意味を忘れてしまったので、自分で実装してみることにしました。
※本記事はわからない人がわからないなりに理解しようとした内容のため、用語等が正確でない場合があります##そもそもΣの目的とは
目的が
Oracle NoSQL Database Cloudシミュレータ を使い PythonでNoSQLをさわってみる
#本投稿の背景
Oracle Cloud にも NoSQL(Oracle NoSQL Database Cloud) があるのですが、
NoSQLの場合、Pythonで DDLや DMLはどうやって実行するのか?を調査したいと思ったのがきっかけです。Oracle NoSQL Database Cloudシミュレータというのがあり、
ローカルPCで試すことができますので、Oracle NoSQL Database Cloudシミュレータを使用する手順とPythonでDDLやDMLをどうやって実行するのかをまとめました。
本投稿では
Windows10環境で Pythonから Oracle NoSQL Database Cloud シミュレータを触ってみる内容となります。前提はWi

Pyhtonの基礎復習はこれだけ ~3~
#6.文字列操作
###シングルクォート、ダブルクォート
文字列にシングルクォートを含む場合、文字列をダブルクォートで囲むことでエラーを回避できる。“`python
spam = “That is Alice’s cat”
“`###エスケープ文字
しかし、シングルクォートとダブルクォートの両方を使いたいときはエスケープ文字を用いることで回避できる。| エスケープ文字|意味|
|:-:|:-:|
|\’|シングルクォート|
|\”|ダブルクォート|
|\t|タブ|
|\n|改行|
|\\\|バックスラッシュ|“`Python
print(“Hello there!\nHow are you?\nI\’m doing fine\t.”
Hello there!
How are you?
I’m doing fine .
“`windowsでは、 \ は ¥ になる。
###raw文字列
クォート文字の前 __r__ に付けると文字列のエスケープ文字を無視する。“`Python
print(r’That is Carol\’s cat.’)
That
C言語で16文字でセグフォらせる
↓PythonをSegmentation Faultで落とすのが最近流行っているようなので。
[pythonを三行でセグフォらせる](https://qiita.com/autotaker1984/items/a8ba955acdc81c907b3d)
[pythonを2行でセグフォらせる](https://qiita.com/sh1ma/items/a6dd1bcca0d9725e7e67)
[pythonを1行でセグフォらせる](https://qiita.com/MysteriousMonkey/items/0e389ccdc12988dd4263)
[Pythonを33文字でセグフォらせる](https://qiita.com/kanimum/items/95a45d8be31ef75d4332)
[Pythonをctypesを使わずに1行でセグフォらせる](https://qiita.com/gyu-don/items/bd2d89f3abd7d0e1f072)
[Rustを5行でセグフォらせる](https://qiita.com/YoshiTheChinchilla/it
Concatenateの理解
#はじめに
KerasのF.Cholletの本を読むと、Concatenate Layerの説明がされている部分がある。下記の絵で表現されているが、この中でどんな演算が行われているかさっぱりしたまなであった。
ところで、U-NET, ResnetなどにConcatenate Layerが重要な役割をしていることから、これ以上にConcatenate Layerを理解せず放置することは良くない判断で、簡単なテンソルを利用し、Concatenate Layerの挙動を確認することにした。
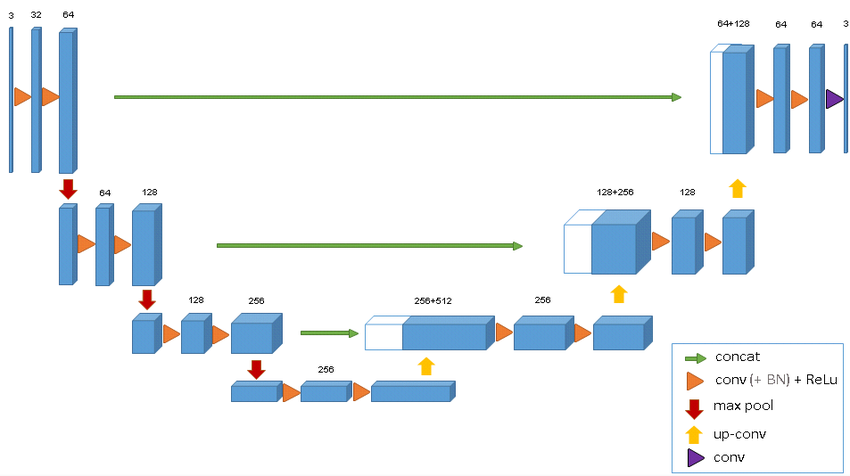
図 [U-Ne
なろう小説APIを試してみた2
[なろう小説API](https://dev.syosetu.com/man/api/)を読んでいたら面白いコマンドを見つけたので紹介と分析をしてみる
#会話率
>|パラメータ| 値| 説明|
|:–|:–|:–|
|kaiwaritu |int string |抽出する小説の会話率を%単位で指定できます。範囲指定する場合は、最低数と最大数をハイフン(-)記号で区切ってください。なるほど。会話率……
会話ばっかりとか地の分とかそういうのかなではでは早速
ロードの準備とライブラリの読み込みをし
“`before_load.py
import pandas as pd
import requests
import numpy as np
import seaborn as sns
from scipy import stats
import matplotlib.pyplot as plt
%matplotlib inlineurl = “http://api.syosetu.com/novelapi/api/”
“`“`narou_load.py
st
cx_Oracle が使える Docker イメージ
Python アプリから Oracle データベースに繋ぐ必要があり Python クライアントを入れる Dockerfile を書いたのだが、やたら苦労したので備忘録として書いておく。
“` Dockerfile:Dockerfile
FROM python:3.7RUN pip install cx_Oracle
# Install Oracle Client
ENV ORACLE_HOME=/opt/oracle
ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$ORACLE_HOME/lib
RUN apt-get update && apt-get install -y libaio1 && rm -rf /var/lib/apt/lists/* \
&& wget -q https://download.oracle.com/otn_software/linux/instantclient/19600/instantclient-basic-linux.x64-19.6.0.0.0dbru.zip \
&& unzip instant




