
- 1. Pythonのstr.formatを存分に使う
- 2. Django の開発環境の Dockerfile を作成してみた
- 3. Django で Hello World(初心者)
- 4. Pythonのargparseで「’required’ is an invalid argument for positionals」が出たら、requiredを消せばいい
- 5. Pythonで処理にかかった時間を表示する簡単な方法とそれを改良したスマートな方法
- 6. Ubuntuでお手軽に機械学習(Python)の環境構築
- 7. Numpy行列をLatex用に出力
- 8. 木を標準出力する【Rust, Python3】
- 9. Pythonプログラミング:クラスタリング結果を3D散布図に描画してみた
- 10. Anaconda仮想環境を構築する
- 11. (たぶん)これだけで受かる、Python 3 エンジニア認定データ分析試験
- 12. PythonでGenderAPIとPykakasiを使って氏名から性別を予測する
- 13. PyPIデビューする際に参考になった書籍とリンク
- 14. 学習するDiscord Botを作る 1.
- 15. Python3 `\x24`について
- 16. atomのautocomplete-pythonが動かなかった時の対処法メモ
- 17. 通勤時間でまだそんなに消耗してるの?〜無料でWEBアプリ(時給計測シミュレーター)作った〜
- 18. kleeでパスワードを言い当てる
- 19. Pythonプログラミング:Qiita記事のタグからNetworkXを使ってグラフを描画してみた
- 20. Pythonでnetkeibaの一年分の全レース結果をスクレイピングするbotを作成した話
Pythonのstr.formatを存分に使う
# freeCodeCampでコツコツPythonを勉強しています。
[前回の記事](https://qiita.com/makky0620/items/73a566580b229c119675)では*Time Calculator*に挑戦しました、今回は*Budget App*に挑戦します。– Python for Everybody
– Scientific Computing with Python Projects
– Arithmetic Formatter
– Time Calculator
– *Budget App(今回はここ)*
– Polygon Area Calculator
– Probability Calculator# 3問目:[Budget App](https://www.freecodecamp.org/learn/scientific-computing-with-python/scientific-computing-with-python-projects/budget-app)
求められてる
Django の開発環境の Dockerfile を作成してみた
# はじめに
docker-compose を学習するにはまず Dockerfile を先に学ぶ必要があるということであったので、Python のフレームワークである Django のアプリケーションを用いて Dockerfile を作成してみたいと思います。# 事前準備
事前準備として Docker の image と container は空の状態からスタートします。
“`
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE$docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
“`# Django プロジェクトの作成
今回は[こちらの記事](https:/
Django で Hello World(初心者)
# はじめに
Python をちょっとだけ触ってみたく、最も人気である Django というフレームワークを用いてブラウザに `Hello World` と表示させるまでやってみたので、その備忘録を投稿いたします。今回こちらの記事を参考にさせていただきました。
Djangoで初めてのHello World
https://qiita.com/Yuji_6523/items/d601ad11ad49b9e7ab0e前提として python と pip はインストール済みとします。
# django コマンドのインストール
`pip install django` と実行して、 django コマンドをインストールします。
“`
$ python –version
Python 3.8.2$ pip install django
# (省略)$ python -m django –version
3.1
“`# Django プロジェクトの作成
今回は `helloWorldProject` という名前のプロジェクトを作成してみた例になります。
`d
Pythonのargparseで「’required’ is an invalid argument for positionals」が出たら、requiredを消せばいい
ドキュメントが少し分かりづらかったのでメモ。
# 起動時の引数を便利に扱えるargparseモジュール
Pythonには、起動時の引数を便利に扱える[argparseモジュール](https://docs.python.org/ja/3/library/argparse.html)があります。## 位置引数とオプション引数
argparseで扱う引数には以下の2種類があります。– 位置引数(infile1など)
– オプション引数(-fや–barなど)(=フラグ)
([公式ドキュメントのargparseの「name または flags」](https://docs.python.org/ja/3/library/argparse.html#name-or-flags)に書かれています)## add_argument()メソッド
どんな引数を指定できるかを`add_argument()`メソッドで指定できますが、位置引数が必須だからと“`
argument.add_argument(
‘infile1’,
required=True,
hel
Pythonで処理にかかった時間を表示する簡単な方法とそれを改良したスマートな方法
よく使うけどよく忘れるので覚えるためにアウトプット
初学者向けに易しく書いたつもりです## 忙しい方へ
[Github](https://github.com/RyukiFujita/mytools)に関数の処理時間を表示するデコレータを公開しています
**pipでインストールしてimportして処理時間を計測したい関数にデコレータを付けるだけ!**
ぜひ使ってください# 本題:簡単(だが残念?)な方法
Python標準装備の[time.time()](https://docs.python.org/ja/3/library/time.html#time.time “time.time()公式ドキュメント”)を使う
`time.time()`は現在のUNIXタイムを浮動小数点数で返すので処理前と処理後の時間の差分をとってやれば良い“`python:main.py
import time
start = time.time() # 開始時刻を記録
“””時間を計測したい処理を書く
“””
end = time.time() # 終了時刻を記録
proc_t
Ubuntuでお手軽に機械学習(Python)の環境構築
# はじめに
何番煎じかはわかりませんが、Ubuntuに新規で機械学習(Python)環境を構築した際のメモを残します。
システム(Ubuntu)にプリインストールされているPythonを用いて、**最小限のインストールでお手軽に環境構築したい方向け**です。
環境:Ubuntu 20.04 LTS# Python, pip, venvのインストール
Ubuntu 20.04 LTSの通常ディストリビューションであれば、Python3はプリインストールされているはずです。
念のため、ターミナルに以下を入力し、確認しておきます。“`shell:ターミナル
python3 -V
Python 3.8.2# インストールされていない場合
sudo apt install python3
“`
次に、各種ライブラリのインストールに必要となるpipをインストールします。“`shell:ターミナル
sudo apt install python3-pip# インストールの確認
pip3 –version
“`システムで使用しているPy
Numpy行列をLatex用に出力
#目標
普通にnumpyのndarrayをprintすると“`
[[ 9.999e+00 -1.000e-03 -1.000e-03]
[-1.000e-03 9.999e+00 -1.000e-03]
[-1.000e-03 -1.000e-03 9.999e+00]]
“`のようになる。
このndarrayをlatexでコンパイルできる形に出力させたい。
つまり、このndarrayを与えれば、“`latex
\begin{pmatrix}
\ 9.999 & -0.001 & -0.001 \\
-0.001 & \ 9.999 & -0.001 \\
-0.001 & -0.001 & \ 9.999 \\
\end{pmatrix}
“`
みたいな出力をする関数を作る。こればあれば
が
木を標準出力する【Rust, Python3】
皆さんは木:edit-request:を標準出力してますか?この木なんの木気になる木[^1]。木構造を扱うことは多くても出力するとなると適当にすませているのではないでしょうか?
[^1]: [この木NaNの木気にnull木](https://twitter.com/jp7wfp/status/1291707207227121664?s=20)というツイートをこの前見かけ笑いました。注釈に書くことじゃないですね。ごめんなさい。
木構造を書く機会が多かったので今回備忘録として投稿します!
最近はRustばかり書いていますが、他の言語でも同じ考え方で実装できるよう、Pythonでも書きました。色々な出力様式が考えられますが、bashで用いられている `tree` コマンド[^2]の出力形式が一番楽そうなので、このフォーマットでの出力を本記事では目指すことにします。
[^2]: `tree` コマンドはbash標準のコマンドではないのでパッケージマネージャで導入する必要があります。
`tree` コマンドの出力はこんな感じです。このディレクトリは表示用に適当に作ったものです。
“
Pythonプログラミング:クラスタリング結果を3D散布図に描画してみた
# はじめに
過去の記事([ウィキペディアのデータを使ってword2vecをしてみる{4. モデル応用編}](https://qiita.com/Blaster36/items/140f2b5c532c3be4b8fe))では、word2vecモデルの多次元ベクトルを用いて単語の非階層型クラスタリングをしました。
今回は、非階層型クラスタリングの結果を見せ方を変えて、3D散布図を描画します。最終的に、以下のようなモノを作ります。
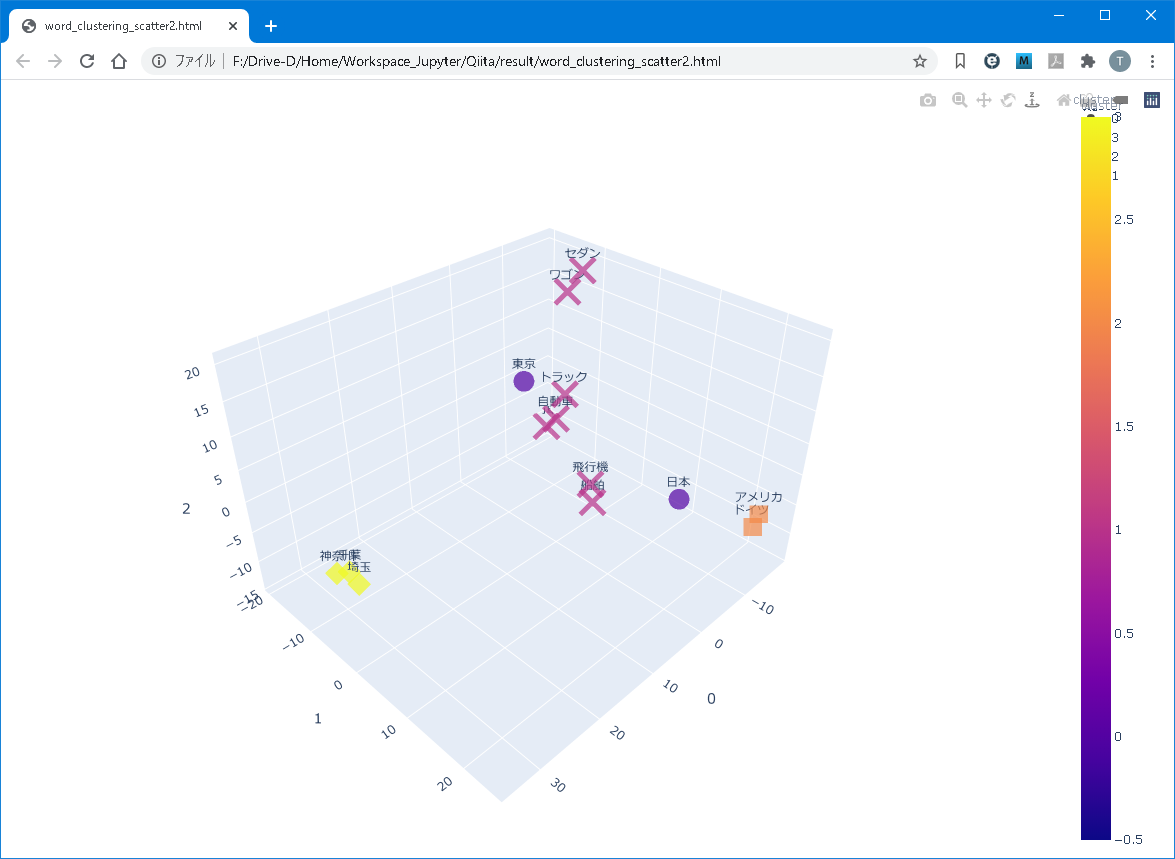## 本稿で紹介すること
– 3D散布図の描画
[Plotly Python Graphing Library | Python | Plotly](https://plotly.com/python/)
## 本稿で紹介しないこと
– Pythonライブラリの使い方
– scikit-learn
–
Anaconda仮想環境を構築する
# アンインストール & 再インストール
こちらの記事にしたがって、再インストール。
https://qiita.com/opankopan/items/5171116b1727c3907e86今回インストールしたのは、**python3.7**です。
(python-cdoはまだpython3.8に対応していないので。)
https://repo.anaconda.com/archive/Anaconda3-2020.02-Linux-x86_64.shPATHの設定をし直す。
“`bash:~/.bashrc
export PATH=/home/kanon/local/anaconda3/bin:${PATH}
“`# 仮想環境の構築
“`bash:
conda create -n [name] python=3.7.4
“`環境の切り替えは、
“`bash:
conda activate [name] # 起動
conda deactivate # 終了
“`# 導入したパッケージ
## condaで導入したパッケージ
`conda inst
(たぶん)これだけで受かる、Python 3 エンジニア認定データ分析試験
# はじめに
本記事は2020年6月8日から始まったPython3 エンジニア認定データ分析試験の知識を整理したものです。
プライム・ストラテジー様の模擬試験や様々なWebページからの情報を整理しています。
記事の中で「教科書」と記しているのは、主教材となっている以下の書籍のことを指します。主教材:
2018年9月19日発売(税込2,678円)
「Pythonによるあたらしいデータ分析の教科書」(翔泳社)
著者:寺田 学、辻 真吾、鈴木 たかのり、福島 真太朗(敬称略)※まだ整理途中であるため、フォーマットが汚い等のご指摘はスルーさせていただくこともございます。
※内容的な誤り、こんなことも載せたほうがよいのでは、といったご指摘は大歓迎です。# 出題範囲と出題配分
| | | 出題範囲 | 出題数 | 出題配分 |
| :—: | :—: | :—: | :—: | :—: |
| 1 | | データエンジニアの役割 | 2 | 5.00% |
| 2 | | Pythonと環境 | | |
| | 1 | 実行環境構築 | 1 |
PythonでGenderAPIとPykakasiを使って氏名から性別を予測する
##はじめに
氏名から性別を予測したい利用シーンがあるかと思います。
例えば、会員制のサービスで登録フォームで性別を聞くとCVRが下がってしまう、だったら予測で補おう!などと言ったシーンでしょうか。氏名から性別を予測する方法は、機械学習で分類器を生成し予測する方法や外部APIを用いて予測を行う方法などいくつかあります。
今回はPythonで名前からGenderAPIを用いて性別を予測するアプローチとなります。[GenderAPI](https://gender-api.com/)はアメリカの企業で、膨大な氏名データから性別予測をこれまで行ってきたようです。
類似するサービスはいくつかありますが、今回はこのGenderAPIを用いて性別予測を行います。##前準備
###Gender API
まずは、[GenderAPI](https://gender-api.com/)のアカウントを作成しましょう。
作成後、API_KEYを取得します。
無料で使用したい方は、500の氏名までなら無料で使用することができます###擬似個人情報取得
[PersonalGenerator](h
PyPIデビューする際に参考になった書籍とリンク
PyPIに初めてパッケージを配布しました。
基本的には[Python実践入門](https://gihyo.jp/book/2020/978-4-297-11111-3)を写経しました。
その際に細かな設定を調べたり、知識を補完するのに役立ったリンクを紹介していきます。# Python実践入門 に関して
11章にパッケージ管理に関して紹介されています。
パッケージ配布に必要な設定と配布方法が書いてあるので、そちらを写経してPyPIパッケージを配布までできました。# 参考になったリンク
– setup.py の記述に関して
– https://docs.python.org/ja/3/distutils/setupscript.html
– 設定するメタデータの内容を調べるのに役立ちました
– https://packaging.python.org/guides/making-a-pypi-friendly-readme/
– `long_description`を README.md から取ってくるコードをちょうだいしました
– h
学習するDiscord Botを作る 1.
#The introduction
会話を記録していくChatbotを作ります。個人的な使用ならば問題無いでしょうが会話内容がファイルに残るので一応プライバシー等に注意してください。
###今回やったこと
とりあえずdiscordのChatbotを何か作りたいと思い立って、会話の中で成長する比較的単純なbotを作りました。
###どうしてそれをするのか
https://medium.com/@kirkouimet/my-conversation-with-an-artificial-intelligence-about-coronavirus-covid-19-742c0dd9abbe
この記事に感銘を受けて、私も最終的にこれに似たものを作りたいと思いました。今回これを作ったのには二つの目的があります。一つにはChatbotのAIを作るための第一歩、チャットでランダムに振る舞うbotを作ること、もう一つには自動的に人間が作った文章を記録しデータセットとして残すこと。実際にAIの学習に使うデータセットを作るためにはこのbotで集
Python3 `\x24`について
pythonは`$` (つまり`\x24`)を予約して使ってるので注意が必要.
例えばre.search()で`\x24`はヒットしない(エスケープすればもちろんヒットする)“`python
import re
# Doesn’t match
target = b”\x00\x01\x24\x03\x04\x05″
kwyeord = b”\x01\x24″
r = re.search(keyword, target)
print(r) # -> None
“`
“`python
import re
# Does match
target = b”\x00\x01\x24\x03\x04\x05″
kwyeord = b”\x01\\x24″ # ESCAPING WITH `\`
r = re.search(keyword, target)
print(r) # -> <_sre.SRE_Match object; span=(1, 3), match=b'\x01$'>
“`参考: https://www.python.org/dev/peps/pep-0215/#
atomのautocomplete-pythonが動かなかった時の対処法メモ
atomを使ってpythonの環境構築をしていたときに、packegeのautocomplete-pythonがうまく動かず、
調べてもパッと出てこなかったのでとりあえず日本語で残しておこうと思います。内容はここに書いてあることと同じ。
https://stackoverflow.com/questions/44602603/atom-ide-autocomplete-python-not-working/52023811#52023811?newreg=45250004097448b89124410714d158d6# 前提
OS:macOS Catalina 10.15.5
pythonバージョン:3.8.5
atom:1.49.0×64
autocomplete-python:1.16.0# 起こったこと
### 期待していた状態
autocomplete-pythonが正しく動作していれば、
例えばpythonファイルを開いて「i」と打った時に下の画像のような感じでpythonのキーワードが候補として出てきます。
作った〜
# 前置き
タイトルは釣りです。リモートワーク関連に期待された方はすみませんorz
内容は一年前に作った動的っぽい挙動をする静的サイトをwebアプリにしたという内容です。ご了承ください。↓前回
【客先常駐SES向け時給シミュレーターを作る(やだ・・・あたしの年収低すぎ・・・?)+転職についての雑記】
https://qiita.com/lunalice/items/c788b82ba52ad940ac9c最近また転職について考える事があって、前回と違って今回はそれなりにエンジニア職っぽい事を経験してやれる事は増えてるはずなんですが、プロジェクト内のコミットは持ってこれないし、何かしら作れるという事をアッピルするために何かちょいちょいコミットしておきたいなぁと思って今回2回目の作成物です、1回目はまた別記事にする予定。
# 本題
先に作成物から。¥Time-Is-Money$
https://re-time-is-money.herokuapp.com/31
kleeでパスワードを言い当てる
# はじめに
kleeなるものがあると聞き,パスワードの特定をやってみたので備忘録を残す.具体的なところは全く理解できていないので,とりあえず動いたところまで.# 解いてみる問題
kleeチュートリアルの[Using symbolic environment](https://klee.github.io/tutorials/using-symbolic/)に紹介されている`check_password()`関数をターゲットにしてみた.
この関数はパスワード`hello`を入力すると1を,それ以外の場合は0を返す.“`c:password.c
#includeint check_password(char *buf) {
if (buf[0] == ‘h’ && buf[1] == ‘e’ &&
buf[2] == ‘l’ && buf[3] == ‘l’ &&
buf[4] == ‘o’)
return 1;
return 0;
}int main(int argc, char **argv) {
if
Pythonプログラミング:Qiita記事のタグからNetworkXを使ってグラフを描画してみた
# はじめに
前回の記事([Qiita記事のタグからTreemapを描画してみた](https://qiita.com/Blaster36/items/8fe99c2d861476ba52cc))では、Qiita記事に付与されたタグを取得し、Treemapを作りました。
今回はそれらタグ間の関係性に着目して、[グラフ](https://ja.wikipedia.org/wiki/%E3%82%B0%E3%83%A9%E3%83%95%E7%90%86%E8%AB%96)を描画します。最終的に、以下のようなモノを作ります。
## 本稿で紹介すること
– Qiita APIからの記事情報の取得
– グラフの描画以下のリンク、4つ目に掲載されたCodeを見本とし、Qiitaの記事を
Pythonでnetkeibaの一年分の全レース結果をスクレイピングするbotを作成した話
#はじめに
前回のエントリ
[競馬データの収集、分析、そして大金を失う迄 その2]
(https://qiita.com/kuri_tter/items/5650a36d88629a1afdde)
で書いた通り、今回は[netkeiba.com](https://www.netkeiba.com/)の一年分の全競馬場の全レースを取得するプログラムについての説明です。
前回は日本ダービーを題材に、レースデータをスクレイピングする方法について説明しました。
ここまでいけば、各レースのhtmlをを順繰りで巡回させることができれば全てのレースを自動でスクレイピングすることが可能となります。#netkeiba.comのraceidの法則
netkeiba.comではraceidに紐づける形で、urlを生成されています。
日本ダービーのurlをみてみましょう。
https://race.netkeiba.com/race/result.html?race_id=202005021211
末尾の’202005021211’という部分がraceidになります。
このraceidは下記の法則の元に振




