
- 1. 【簡単】AI(YOLO V5)でじゃんけん検出
- 2. 初心者向け、kerasでよくあるエラーの対処法
- 3. GSI_DEMをUbuntuコマンドライン上だけでgeotiff変換->UTM変換->ascii変換
- 4. enumerate関数について(python)
- 5. Pythonのデフォルト引数の挙動
- 6. 犬ですが何か?Django–カスタムユーザーモデルを作成する2
- 7. ROSセットアップにてsudo rosdep initでコマンドが見つからない
- 8. SIGNATE 【第1回_Beginner限定コンペ】銀行の顧客ターゲティングに参加しました
- 9. python初心者メモ(9.1)
- 10. RaspberryPi内のPythonファイルをAtomのリモート機能で編集したら最高だった
- 11. 金を買うのはどの曜日?
- 12. 農家のITマーケティング試行錯誤日記1.楽天商品検索APIを使って商品情報をcsv出力[Python]
- 13. Python3における基礎的な正規表現のまとめ
- 14. 【Python3エンジニア認定基礎試験】受験・合格体験記
- 15. PythonAnywhereにてpip installしたい
- 16. 【Python】matplotlibを日本語対応させよう
- 17. Pythonで画像ファイルの仕分け
- 18. python3.7でdictが格納順を保持するようになったが、pprint出力は自動でソートされる
- 19. Tensorflow+matplotlibで推論&結果の表示
- 20. word2vecで実践するAKB48と乃木坂46における「自由」
【簡単】AI(YOLO V5)でじゃんけん検出
# 1. はじめに
**AIで手の形を検出**できたら、**手話の翻訳**などにも活用できそうですよね。いきなり手話翻訳は難しいので、まずは、**じゃんけん**の「**`グー・チョキ・パー`**」を**AIでリアルタイム検出**できるか試してみたいと思います。
# 2. 具体的にどんなことをやるか
ローカルPCのwebカメラを使って、じゃんけん(グー・チョキ・パー)をAIに検出させたいと思います。モデルを作成するのにローカルPCだとかなり時間がかかりそうなので、モデル作成はGoogle ColabのGPUパワーを利用し**サクッと**モデルを作って、作ったモデルをローカルPCへ移植したいと思います。
> モデル作成は、最先端リアルタイム物体検出システムである**`YOLO V5`**を使用します?### イメージ図
。
kerasを使う上でのエラー対処法についてまとめた記事がなかったので、teratailの解決済み質問をもとに、稚拙ですがまとめておきます。
#ImportError,AttributeError
・バージョンを下げる、上げるなどで解決(ImportError,AttributeError)
・再インストールで解決することもある(ImportError)
・importするファイルが間違っている(AttributeError)
・tensorflow.kerasとkerasは別物
・タイプミス(大文字、小文字の区別はしっかりと)kerasではいろんなライブラリのバージョンによる影響が大きい。古すぎたり新しすぎたりするとInportErrorを起こすことがある。
AttributeErrorについては、以下記事を参照。
[[python]「AttributeError: module(object) ‘xxx’ has no attribute ‘yyy’」が起きたときの対処法5選](https
GSI_DEMをUbuntuコマンドライン上だけでgeotiff変換->UTM変換->ascii変換
#国土地理院DEMをLinux (Ubuntu) のコマンドライン上のみでGISで使いやすい形式に変換したい
GISの業務をしている関係上,数値標高モデル (DEM) を利用することがあります.
日本の場合は国土地理院 (GSI) が国土基盤情報として5m,10mメッシュのDEMを公開しています.
ただGSIが提供しているJPGIS (GML) 形式という形で提供されています.
Metadataのようなものでテキストエディターで開くとぱっと調べるとWindows環境のみで動作するソフトなどがありますが,Linux使いとしてはやはりいちいちソフトを立ち上げてファイル形式を変換はやや面倒くさいです.
ここではbash環境の例です.
詳細の解説はスクリプトの下に記載します.“`shell:gsidem2geotiff.sh
#!/bin/bash#私の環境で足りなかったものを追加.
#足りないものがあれば各自追加.
#sudo apt-get install git osmium-tool gdal-bin python python-pip python-numpy pyt
enumerate関数について(python)
#1.はじめに
こんにちは!!今回はpythonのenumerate関数について記事を書きたいと思います。
enumerate関数を使用すると、forループの中でリストやタプルの要素と順番を取得できます。要するにリストやタプルの中身とその順番の番号を返してくれるという関数になっています。
enumerate関数を使用するとコードを簡略化でき、直感的に理解できるかと思います。
それでは、簡単な問題をenumerate関数を扱う場合と扱わない場合で解いてみようと思います。
#2.問題
研究室で定期発表会があります。発表の順番はこの用意されている名簿(配列)の順に行きたいと思います。ですがこの名簿には順番が書かれていないので直感的にわかりません。なので名前と発表の順番を出力してください。このような問題を解いてみましょう。
#3.enumerate関数を扱わない場合
enumerate関数を扱わない場合はこのようなコードになります。“`enumerate.py
publicator = [“haruto”,”sota”,”minato”,”yuto”,”riku”,”mei”]
nu
Pythonのデフォルト引数の挙動
Pythonのデフォルト引数はメソッド実行時ではなくプログラム起動時に評価される
これまで使っていたRubyやScalaでの挙動が普通だと思っていたので、何がおかしいのかわからずにかなりハマった### Ruby
“`ruby
def test(t=Time.now)
puts(t)
endtest
sleep(10)
test
“`実行結果
“`
2020-09-02 09:05:42 +0900
2020-09-02 09:05:52 +0900
“`### Scala
“`scala
object Test {
def test(t: DateTime = DateTime.now()): Unit = {
println(t)
}def run(): Unit = {
test()
Thread.sleep(10000)
test()
}
}
“`“`
2020-09-02T09:14:08.681+09:00
2020-09-02T09:14:18.732+09:
犬ですが何か?Django–カスタムユーザーモデルを作成する2
#追加情報の登録
こんにちは!柴犬のぽん太です。山でイノシシに追いかけられる夢を見ました。とても怖かったです。
さて、前回作成したカスタムユーザーモデルでは、dogname, introductionを追加したのですが、登録画面には下に示すように、その入力項目はありませんでした。

ここにdognameとintroductionの入力項目を追加しましょう。
# SignupFormのオーバーライド
入力フォームでdognameとintroductionが入力できるようにするために、SignupFormに追加します。“`python:accounts/forms.py
rom allauth.account.forms import SignupForm
from django impo
ROSセットアップにてsudo rosdep initでコマンドが見つからない
#rosdepエラー
ROSインストール直後にセットアップで
`sudo rosdep init`
を入力する場面があるが、現状
`sudo rosdep init`
をすると
`rosdep: コマンドが見つかりません`
と出る
#解決策
インストールが手動に変わった模様。
`apt install python-rosdep`
する必要あり
SIGNATE 【第1回_Beginner限定コンペ】銀行の顧客ターゲティングに参加しました
データサイエンス分析コンペサイトのSIGNATEの[【第1回_Beginner限定コンペ】銀行の顧客ターゲティング](https://signate.jp/competitions/292)に参加しました
無事Intermidiateに昇格きたので、気軽にコンペに参加できる人が増えることを願いつつ備忘と反省を踏まえて記事にしました
## SIGNATEとは(シグネイト)
日本の会社、[SIGNATE](https://signate.jp/)が運営しているデータサイエンスコンペです
経済産業省やマイナビ、NTTやSansanなども参加しておりkaggleの日本版だと思って差し支えないと思います
フォーラムが活発ではないため、あまり参加者同士で意見や情報を交換する風潮が”まだ”ないように見えます
今回のBegiinerコンペの終盤にはフォーラムが少し動いていたのでこれから変わっていくかもしれません(ちなみに[公式の動画](https://youtu.be/GTl8PmyefbA
)を見ると正しいイントネーションは「シグ(↑)ネイ(→)ト(↓)」みたいです
三角
python初心者メモ(9.1)
python初学者です。
自分用のメモです無限ループ
“`python
while True:
print(“無限ループ”)
“`
プロット(直線)“`python
plt.plot(data,”r–“) #(yデータ,色) r–で赤、点線
plt.plot(a,b,c) #(x,y,color)
plt.show()
“`
その他“`
plt.bar() #棒グラフ
plt.barh() #横棒グラフ
plt.scatter() #散布図
plt.pie(data,explode=ex,labels=labels ,autopct=%1.1f%%,counterclock=False) #円グラフ
#データ、目立たせる,ラベル,小数点の表示桁数、1.2で小数点以下第二位に,Falseで時計回りに配置
#colors=で色の指定もそれぞれ可能
plt.hist() #ヒストグラム
plt.boxplot() #箱ひげ図,引数にタプルを利用することで複数描画可能“`
複数のグラフの作成
“`
#一番目
a=fig.add_subplot(
RaspberryPi内のPythonファイルをAtomのリモート機能で編集したら最高だった
#きっかけ
VNCでPCからRaspberryPiのデスクトップ画面上でエディタを使っていたときのこと
私はある不満を抱えていた。
.
.**「使いづれぇ…」**
**「ちょー使いづれぇ…」**
コピペが上手くいかなかったり、動きがもっさりしてたりで
何とかならないかなーって思っていた。「あーあ、AtomとかVC codeみたいなエディタがあったらなー…」
.
.###あるやん!、Atomがあるやん!
###そうだ、Atomのパッケージ…あるやんっっ!と言うことで、AtomでRaspberryPi内のPythonファイルを編集、保存、実行する
方法をまとめました。#イメージ
VNC(Virtual Network Computing)仮想ネットワーク接続で
RaspberryPiのデスクトップ画面をPCからエディタを表示、操作する方法から、Atom上でRaspberryPiにリモートでアクセスし、ファイル編集をする方法をやっていきます。
を取り扱っており、銘柄コード1540は一つあたりおおよそ6000円と少しである。
こうした銘柄はいっぺんに買うのではなく、時間的分散を行い買う「ドルコスト平均法」と呼ばれるものがある。
人によっては毎日積み立てる人もいれば、週次や月次で積み立てていくといった人もいるだろう。
ここでは週次のデータに注目し、どの曜日がいいのだろうかを探っていく。ただし、判断は各自にに任せます。そしてこの記事は投資を進めるものといったものではなく、週次データの取り扱い方を書き手が知る範囲で記したものです。繰り返すが投資は自己責任ということをお忘れなく。
##前処理
データを用意しよう。私の場合、160日分のデータを取得し、置換などを用いて整えた。さらに曜日が欲しかったため一度Excelにとりこみ、関数を用いて曜日列を付与し、以下のようなcsvデータ「junkin.csv」を作成した。“`
曜日,日時,始値,高値,安値,終値,出来高,調整後終値*
2020-1-6,5220,5260,5200,5250,135951,5250
以
農家のITマーケティング試行錯誤日記1.楽天商品検索APIを使って商品情報をcsv出力[Python]
## はじめに
楽天市場のAPIを活用し、キーワードに当てはまる商品情報をcsvに出力してみました。活用したのはこちらの「楽天商品検索API」というものです。
[楽天ウェブサービス: 楽天商品検索API(version:2017-07-06) \| API一覧](https://webservice.rakuten.co.jp/api/ichibaitemsearch/)### 開発環境と使用するライブラリ
開発環境としてJupyter Notebookを利用しました。
大掛かりなツールや定期的に実行したいツール作成時にはまた別のテキストエディタで作っていく必要があるかもしれませんが、ちょっとした単発のツールを作る際には、Jupyter Notebookなら少しずつ試しながらスクリプトが書けるし、即座に実行できるのでとても便利です。使用するライブラリは`request`と`pandas`。
APIを叩くために`request`を使い、取得したデータ操作とcsv出力のために`pandas`を利用しました。## 目的
農産物を販売するための価格調査のために行いました。
取得
Python3における基礎的な正規表現のまとめ
Pythonでの正規表現(re)について使用頻度の高いものをまとめました。
**※投稿者がMac環境のため\(バックスラッシュ)で表記されている部分がありますが、Windows環境の方は¥(えん)マークに読み替えてください。**
# 位置関係に関する正規表現
| 記号 | 説明 |
| :-: | :-: |
| ^ | 文字列の先頭からパターンに一致するかを判定 |
| $ | 文字列の末尾からパターンに一致するかを判定 |# 繰り返しに関する正規表現
| 記号 | 説明 |
| :-: | :-: |
| ? | 0回または1回 |
| * | 0回以上 |
| + | 1回以上 |
| {m} | m回 |
| {m,} | m回以上 |
| {m,n} | m回以上、n回以下 |# 文字制限に関する正規表現
| 記号 | 説明 |
| :-: | :-: |
| [0-9] | すべての数字 |
| [a-zA-Z] | すべてのアルファベット |
| [a-zA-Z0-9] | すべてのアルファベットと数字 |
| [^a-zA-Z0-9] | すべてのアルファ
【Python3エンジニア認定基礎試験】受験・合格体験記
# はじめに
Python3エンジニア認定基礎試験を受験し、合格しました。
合格のための勉強法や受験して思ったことをまとめていきたいと思います。# そもそもPython3エンジニア認定基礎試験って?
[一般社団法人Pythonエンジニア育成推進協会](https://www.pythonic-exam.com/pythonic)が実施している民間資格試験です。
「Pythonic」(Pythonらしい簡潔で読みやすいコードを書こう、という思想)の理解促進を目標の1つとしています。
[2019年7月時点で受験者数が5000人を超え](https://www.pythonic-exam.com/archives/news/python5000)、現在は受験者数は1万人に迫るそうです。受験方式はCBTで全国の試験センターでいつでも受験でき、受験料は1万円(税別)。
# 筆者のレベル
* プログラミング歴3ヶ月
* paiza、progate、Udemyで基礎を勉強した程度
* DjangoでWebアプリを1つ作成
* 実務未経験# 出題範囲
オライリー・ジャパン「Python
PythonAnywhereにてpip installしたい
## はじめに
私の記事では毎度お馴染みの自作競艇予想サイト、「[きょう、ていの良い
予想はあたるだろうか。](https://youhaveniceboat.pythonanywhere.com)」に自然言語処理的な機能を追加しました。
本記事では、PythonAnywhereにていざ実装!となった段階で起きたトラブルをまとめています。## Localでは動くが、PythonAnywhere上で動かない!!
Local環境での動作検証を終え、万を辞してPythonAnywhere上のファイルを差し替え、更新!!しかし、ここでエラーが起こりました..
errorlogを確認すると、どうやらjanomeがinstallされていないことが原因の様でした…
## 意外と簡単だったpip install
PythonAnywhere上の環境に
【Python】matplotlibを日本語対応させよう
# 概要
matplotlibは標準フォントでは日本語に対応していないので・・・
こんな感じで文字化けしてしまいます。
これを
こうなるようにしていきましょう。# 環境
“`
# OS version
ProductName: Mac OS X
ProductVersion: 10.15.6
BuildVersion: 19G2021# Python version
Python 3.8.5
# matplotlib version
matplotlib=


Pythonで画像ファイルの仕分け
## まえがき
自分は古い人なので基本「無いものは作る」派。
## お題
今回はタイトル通り画像の仕分けということで。
恐らく2000年前後からデジカメやスマホで撮った写真、ダウンロードしてきた壁紙、スクリーンショットなど何ファイルあるかわからない上にある時点のスナップショット的なバックアップが複数のHDDに入ってるので大変カオスな状態。まぁ分散&冗長性を持たせて保存するのはある意味リスクヘッジ的とも言えますが。– HDD1:~2000枚まで
– HDD2:~2500枚まで
– HDD3:~3000枚までといった感じで重複が激しいのと以前少しだけ仕分けをやりかけた残骸がfilename(1).jpgとかで残っているので重複を省いて新しいHDDに収めるのとAmazonPhotosへアップロードしておこうかなと。
1. 仕分け先フォルダはdst\yyyymmとする(取り敢えず年月で分類)
1. yyyymmはExifのDateTimeOriginalから決定する
1. ExifはあってもDateTimeOriginalが無い、またはExifが無い画像はファイルのタイムスタン
python3.7でdictが格納順を保持するようになったが、pprint出力は自動でソートされる
pythonのアップデートのきっかけになったので記念に投稿。
現在進行形でアップデートが進んでる言語なんですね。– 参考にしたサイト
– https://qiita.com/tonluqclml/items/db797d9ad03604ae489c
– https://note.nkmk.me/python-collections-ordereddict/
– https://note.nkmk.me/python-pprint-pretty-print/ちなみに、動作確認は Python3.7.3 -> Python3.8.5 です。
# python3.7以上は“`dict“`が格納順を保持する
めっちゃ便利!
しかし、“`pprint“`で出力をする場合、“`pprint“`が **出力前にソートをする** 仕様のせいでいまいち恩恵が薄い。“`python:test1.py
from pprint import pprintd = {1: 10, 9: 90, 3: 30, 7: 70, 5: 50}
print(d)
pprint(
Tensorflow+matplotlibで推論&結果の表示
# 1. はじめに
TensorflowやPyTorch、Chainerでモデルの評価はできたけど、Deep Learningをあまり知らない人にAccuracyやLossのグラフだけ見せても…って事ありませんか?
また、手っ取り早く、この画像は正解!これは不正解!ってのが見られると嬉しい場面もあるでしょう。
そんな願いを叶えるため、複数並んだ画像に判定結果を載せていく、というのをMatplotlibで実現してみたいと思います。
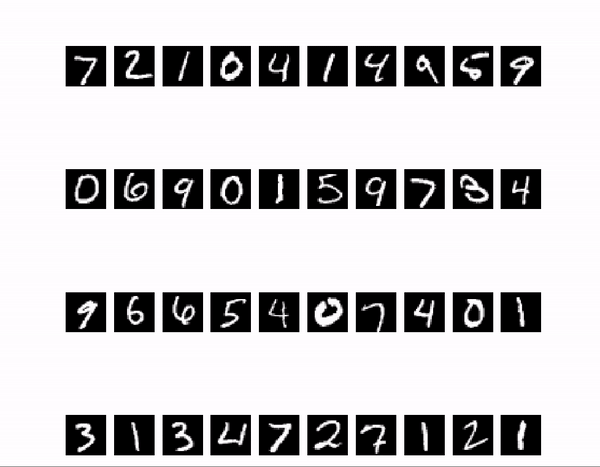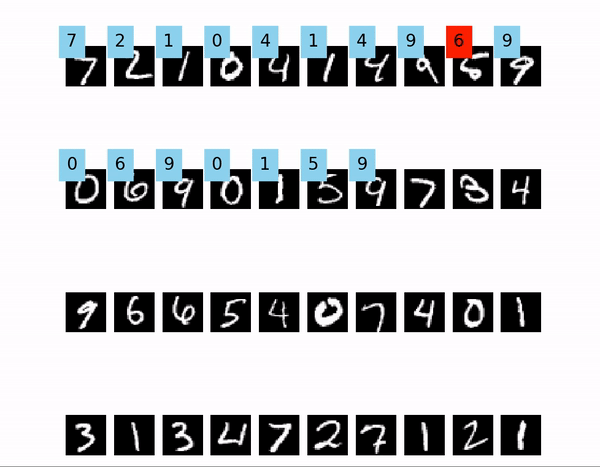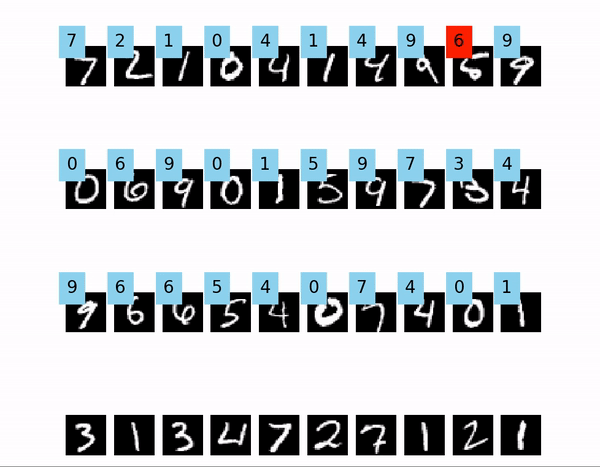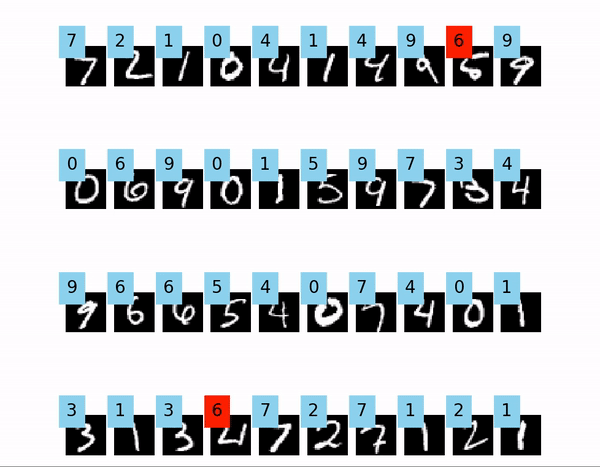また、今回は例としてTensorflowを用いますが、画像の表示部分はフレームワークが何であっても大丈夫です。
# 2. 実装 & 解説
例として、Tensorflowを使ってMNISTの学習をしたモデルを用意しました。
今回、画像は40枚使用します。“`python:valid
word2vecで実践するAKB48と乃木坂46における「自由」
#はじめに
Pythonのライブラリのword2vecを使って、AKB48と乃木坂46の歌詞をそれぞれ学習することで、AKB48と乃木坂46それぞれの歌詞における「自由」と類似する言葉を調べてみました。ここでは主に6つのプログラムによって処理を行っています。最初に歌ネット( https://www.uta-net.com/ )からAKB48と乃木坂46のそれぞれの歌詞を取得するために楽曲のタイトルとIDを取得しています。次にそのIDを使って、楽曲ごとの歌詞を取得しています。その後、MeCabを使って形態素解析を行い、ストップワード処理をしています。その次にどのような言葉が多く使われているかを確認するために形態素解析したデータを集計しています。そして、形態素解析したデータをword2vecを使って学習モデルを作成しています。最後に、学習モデルから「自由」に類似する言葉を抽出してみました。#このプログラムを実行するために必要な環境
BeautifulSoup、gensimなどのライブラリがインストールされている。(anacondaなどのパッケージを推奨、gensimのみ別途インストール




