
- 1. Macのデスクトップ通知をPythonから表示する
- 2. jupyterで仮想環境に入るならnb_conda_kernelsがおすすめ
- 3. ワンライナーズンドコチェック
- 4. 物体検出のDeepLearning読むべき論文7選とポイントまとめ【EfficientDetまでの道筋】
- 5. AtCoder Beginner Contest 177 復習
- 6. ズンドコチェック、キヨシが出るか?┗(^o^)┛が出るか?
- 7. DP100問バチャ復習 1~10(8/26,27)
- 8. Pythonを使い、iOSアプリのレビューを取得して、Lineで知る
- 9. 遺伝的アルゴリズムを使用したアルゴリズム生成自動化
- 10. Pythonのコードがそのままwebアプリになる『Streamlit』を試してみた
- 11. Windowsで環境を極力汚さずにPythonを動かす方法 (Scoop編)
- 12. Python(+ Flask)でMattermostのBot作った
- 13. Linuxでライブラリを使わず通信量を取得しよう
- 14. LambdaでPostgreSQLを使う(Python + psycopg2)
- 15. AutoGluonの画像分類(Image Classification)を試してみた
- 16. BeautifulSoupとSeleniumを組み合わせた自動テストの方法(Python)
- 17. Pythonから各種DBへ接続する方法(PEP 249)とSQLAlchemyについて
- 18. 【Python】データサイエンス100本ノック(構造化データ加工編) 033 解説
- 19. Pythonで解く【初中級者が解くべき過去問精選 100 問】(015 – 017 全探索:順列全探索)
- 20. pytubeの実行とエラー
Macのデスクトップ通知をPythonから表示する
Macの通知をPythonスクリプトから出したい局面があったので、
– AppleScriptをコマンドで実行する
– 上記のコマンドをPythonから実行するという流れで作成しました。
## AppleScriptでデスクトップ通知を表示する
AppleScriptでは、
“`AppleScript:notification.scpt
display notification “こんにちは世界”
“`でデスクトップ通知を表示できます。下図では、ScriptEditor.appから実行しています。
|  |
|——–|## コマンドからAppleScriptを実行する
`osascript`コマンドを使用します。
terminal.appにて、
“`sh
$ os
jupyterで仮想環境に入るならnb_conda_kernelsがおすすめ
# 概要
タイトル通り。日本語で検索すると[jupyter_environment_kernels](https://github.com/Cadair/jupyter_environment_kernels)を使った方法ばかりがヒットするが、Anaconda公式が開発している[nb_conda_kernels](https://github.com/Anaconda-Platform/nb_conda_kernels)を使った方が簡単かつ確実。# 導入
jupyterを起動する環境下で以下のコマンドを実行するだけ。`conda install -c conda-forge nb_conda_kernels`
jupyterを開いて”カーネル”→”カーネルの変更”から好きな環境を選択する。
# 詳細
jupyter notebookやjuypter labを実行する際の環境をanacondaの仮想環境に変更したいという需要は非常に高いと思います。
日本語で「jupyter 仮想環境」と検索すると、[jupyter_environment_kernels](https://g
ワンライナーズンドコチェック
**今朝、ズンドコチェックなるものと邂逅した。1行にした。**
セミコロンは甘え。“`python
print((lambda f, z:f(f, z))(lambda f, z:z + ‘キ・ヨ・シ!’ if z[-10:] == ‘ズンズンズンズンドコ’ else f(f, z + __import__(‘random’).choice([‘ズン’, ‘ドコ’])), “”))
“`“`
ズンズンドコズンズンドコズンドコドコズンドコドコドコズンドコズンド コドコドコズンズンドコズンズンズンズンズンズンズンドコキ・ヨ・シ!
“`
物体検出のDeepLearning読むべき論文7選とポイントまとめ【EfficientDetまでの道筋】
お久しぶりです。
2012年のHintonさんのAlexNetによるILSVRCでの圧勝を皮切りに、画像認識の世界でもDeepLearningが脚光を浴びることとなりました。物体検出の世界でも現在DeepLearningを用いたモデルが主流になっています。
https://paperswithcode.com/sota/object-detection-on-coco を見ると、
COCO test-devにおいて、state-of-the-art(SoTA)のモデルはEfficientDet-D7xのようです。
独断と偏見も少々ありますが、そのEfficientDetを理解するために読むべき論文を7つ集めてみました。DeepLearning以降の物体検出に焦点を当てて、出来るだけ簡潔
AtCoder Beginner Contest 177 復習
#今回の成績

#今回の感想
D問題まではスムーズに通せましたが、Eが簡単にもかかわらずD問題までで集中力が切れてしまいました。反省です。
F問題が思いつきうるタイプの問題ですが、嘘解法にハマってしまいました。#[A問題](https://atcoder.jp/contests/abc177/tasks/abc177_a)
$t \times s \geqq d$を満たすかを考えます。
“`python:A.py
n,x,t=map(int,input().split())
y=-((-n)//x)
print(y*t)
“`#[B問題](https://atcoder.jp/contests/abc177/tasks/abc177_b)
$len(s) \times l
ズンドコチェック、キヨシが出るか?┗(^o^)┛が出るか?
# 暇なんですよね
ズンドコチェック、今更ながらやってみました。
少しアレンジも加えてみました。
冗長なコードですみません…“`python:zundoko.py
import randomdef main():
zundoko = [‘ズン’, ‘ドコ’]
count_zun = 0
count_doko = 0
while True:
tmp = zundoko[random.randint(0, 1)]
print(tmp, end=””)
if tmp == ‘ズン’:
count_zun += 1
count_doko = 0
else:
if count_zun == 4:
print(‘キ・ヨ・シ!’)
break
elif count_doko == 3:
print(‘┗(^
DP100問バチャ復習 1~10(8/26,27)
[DP100問バチャ](https://kenkoooo.com/atcoder/#/contest/show/f1fd5759-0b54-4365-974e-6681a3837443)の復習用の記事です。
(100問解こうと思っていましたが、飽きたのでこの記事で更新は一旦停止すると思います。)
できるだけ体系的にDPの手法をまとめていこうと思います。
#1,[D – パスタ (Pasta)](https://atcoder.jp/contests/joi2012yo/tasks/joi2012yo_d)
###DPの判断
**連続的な制約がある場合はDPが有効**です。さらに、今回は**パスタが3種類で状態を制限**できそうなこともわかります。
###方針
**$i$日目にどのパスタを何日連続で食べていたか**の情報が必要なので、以下のようにDPをおきます(連続的に決まる場合は)。
$dp[i][j][k]:=$($i$日目までにパスタ$j$を$k$日(1-indexed)連続で食べている組み合わせの数)
**遷移**は以下のようになりす。また、ここでは**$i
Pythonを使い、iOSアプリのレビューを取得して、Lineで知る
自身の出したアプリのレビュー件数を取って毎日Lineで知りたい時ないですか?
自分にはありました。
そこで、作成。今回はiOS用に作成したものになります。
### 使用ライブラリ
– requests
– APIを叩くのに
– urllib3
– レスポンスをJSONに分解
– line-bot-sdk
– LineBOT### コマンド
“`
pip install line-bot-sdk
pip install requests
pip install urllib3
“`### 実際のコード
“`GetReview.py
from linebot import LineBotApi
from linebot.models import TextSendMessage
from linebot.exceptions import LineBotApiError
import requests
import json
import urllib.request
import urllib.parse#LINEでメッセージを送るため
遺伝的アルゴリズムを使用したアルゴリズム生成自動化
## 前置き
遺伝的アルゴリズムはパラメータの調整や組み合わせ最適化のような非常に単純な例で紹介されることが多いですが、少しの工夫でアルゴリズムやプログラムの自動生成が可能になります。## 前提知識
### 遺伝的アルゴリズム
変異、遺伝、淘汰などによる生物の進化の考えに基づいた探索アルゴリズムです。### 遺伝子型
突然変異や交叉のような遺伝的操作を行う対象となる型です。### 表現型
適応度の評価対象となる遺伝子型から発現した個体です。## 様々な遺伝的アルゴリズム
### 遺伝的プログラミング
遺伝子型が木構造[Wikipedia](https://ja.wikipedia.org/wiki/%E9%81%BA%E4%BC%9D%E7%9A%84%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0)
### 遺伝的ネットワークプログラミング
遺伝子型がネットワーク構造### Graph Structured Program Evolution (GRAPE)
遺伝子型が一次元配列
Pythonのコードがそのままwebアプリになる『Streamlit』を試してみた
公式サイト: https://www.streamlit.io/
データサイエンティストや機械学習エンジニアが、数時間で美しくて良いパフォーマンスのアプリを作成する一番簡単な方法だそうです。
単純に面白そうなのでやってみました。
### 参考にした記事
– [公式ドキュメント](https://docs.streamlit.io/en/stable/)
– [Pythonのスクリプトからウェブアプリを簡単に作れるStreamlitをさわってみた](https://dev.classmethod.jp/articles/streamlit-intro/)
– [Streamlit: データサイエンティストのためのフロントエンド](https://note.com/navitime_tech/n/ned827292df6f)
– [Streamlitで確率分布のシミュレーションアプリを作ってみた](https://yolo-kiyoshi.com/2020/06/11/post-1903/)## できたもの
動い
Windowsで環境を極力汚さずにPythonを動かす方法 (Scoop編)
## 【はじめに】
なぜか着実にview数が伸びていく「Windowsで環境を極力汚さずにPythonを動かす方法」シリーズ[^1]。
意外に需要があるようなので、最近のお気に入りの方法を記述します。
本手順は過去に紹介したEmbeddable版と異なり `tkinter` や `venv` が利用可能だったり、WSL版のようにHW制限を受けないのが特徴です。
また手順が2stepしかなく、非常に簡単です。## 【内容】
Windows用のパッケージ管理ツール「Scoop」を利用し、Windows環境を極力汚さずにPythonをインストールして、開発や動作確認を行えるようにします。
**(※ ユーザ環境変数PATHが追加/変更されるので、それが気になる人はここで撤退してください)**## 【手順】
### 1. Scoopのインストール
まずはパッケージ管理ツール「Scoop」をインストールします。
Scoop自体は非常に軽量なツールであり、Scoopによってインストールされるモジュールはデフォルトではユーザフォルダ内にインストールされるため、Windowsのシステム環境をほ
Python(+ Flask)でMattermostのBot作った
# 注意
下書きに保存したまま、9か月ほど記事が眠っていたので、情報が古い箇所があるかもしれません。。。
せっかく書いたので供養のためにも投稿します。。# 背景
社内のコミュニケーションツールをMattermostに移行することになった。
既存のBotをMattermostに移行できたらいいなーと思ったので、
自分自身の勉強も兼ねてPythonでMattermost用にBotを再実装[^1]してみた。
Botを実装するに当たって色々と調べまわったので、自分のためにも情報をまとめておく。# 環境
– CentOS 7.7 (Mattermostサーバ)
– Ubuntu 18.04 LTS (Botサーバ)
– Mattermost 5.14.0
– Python 3.6.8なんとなくCentOSとUbuntuの両方が触りたい気分だったのと、
Ubuntu 18.04はデフォルトでPython3が入っているので使ってみた。
要するに特に意味はないです。# 環境構築
#### Mattermostの導入
MattermostはDockerで簡単に導入できるので、まずDock
Linuxでライブラリを使わず通信量を取得しよう
###はじめに
こんばんは、麻菜結です。最近ツイッターでつぶやいたいつかラズパイをwifiルーター兼アレクサ兼ファイルサーバー兼テレビ兼時計にしてそれらのアイテムを廃業にしたい
— 麻菜 結???? (@asana_yui) August 22, 2020
これを実現していくうえで得た様々な知見に関して書いていこうのやつです。
今回は置時計に表示する通信量データを、ライブラリを使わずゴリゴリ取得したやつです。###環境
Raspbian64bit“`
Linux as
LambdaでPostgreSQLを使う(Python + psycopg2)
# はじめに
LambdaでPythonを使うときに、psycopg2でPostgreSQLを簡単に使う方法です。
これまでは、psycopg2をimportするのは手間でしたね。# 方法
Mischa SpiegelmockさんのLambdaレイヤーを使わせてもらいます。https://github.com/jetbridge/psycopg2-lambda-layer
Lambda3.8 東京リージョンap-northeast-1の場合
“`
arn:aws:lambda:eu-central-1:898466741470:layer:psycopg2-py38:1
“`
レイヤーにarnを指定すればOK。これだけでimportできます!
# 終わりに
GithubのCod
AutoGluonの画像分類(Image Classification)を試してみた
# はじめに
Google Colaboratoryの環境でAutoMLのライブラリであるAutoGluon( https://autogluon.mxnet.io/index.html )の画像分類を試してみました。
基本的には公式のQuickStartの内容にプラスアルファした内容になります。# 環境
Google Colaboratoryで実施しています。
# 実行
## Google Colabの設定
画像分類の場合はDeepLearningのモデルを使用するため、GPUを使用するように設定します(下図参照)。
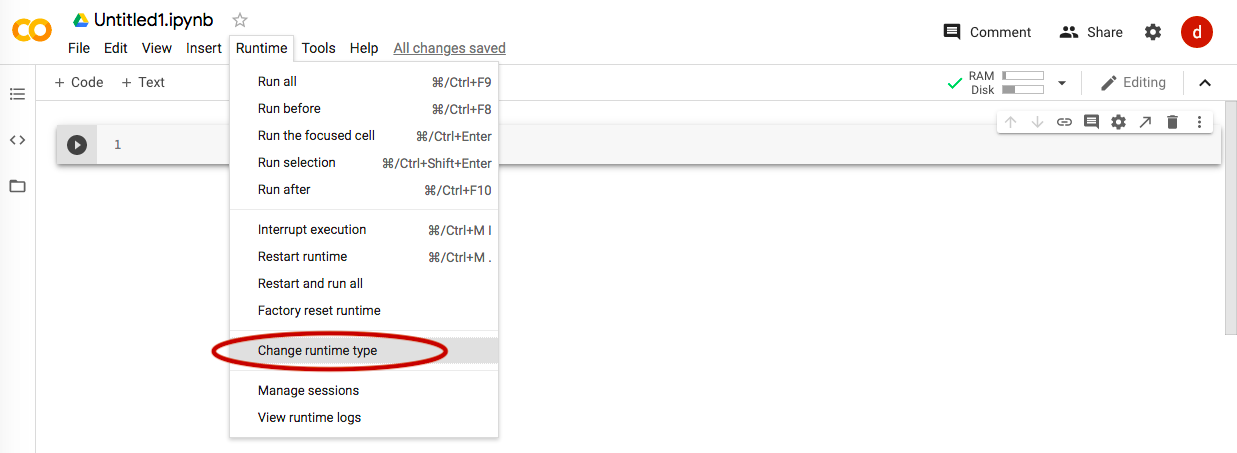

#1.概要
WebページのHTMLに特定のデータを収集するためのタグを埋め込むことがあり、その埋め込んだタグが正しいのか、自動テストを用いてテストを行っていました。
[BeautifulSoupを用いたHTMLデータの検索方法](https://qiita.com/momotar47279337/items/bb123c98dc8c1c840409)
ただ、静的なページであればBeautifulsoupを用いてテストできたのですが、SSL化された画面などのセキュリティが強い画面は、HTMLデータを取得できませんでした。
そのため、BeautifulsoupでHTMLデータを取得できない場合は、Seleniumを用いて対象画面に遷移し、HTMLページを取得することにいたしました。
#2.プログラム
以下BeautifulsoupとSeleniumを用いてHTMLデータを取得するプログラムになります
“`python:test.py
import time
from selenium import webdriver
from bs4 import Beautiful
Pythonから各種DBへ接続する方法(PEP 249)とSQLAlchemyについて
# 1.はじめに
pythonからDBへのアクセスは、[PEP 249 — Python Database API Specification v2.0](https://www.python.org/dev/peps/pep-0249/)という仕様が定められており、各DBがこの仕様に合わせて実装を行っています。(各DBが用意しているこの実装をDBAPIと呼ぶことにします。)その思想は、
~~~
接続先のDBを意識することなく、同一のコードでDBへの接続とSQLの実行、その結果の取得を実現できる
~~~
ということだと思います。では、実際どうなのか。確認していきたいと思います。# 2.各DBごとに用意されているDBAPIについて
各DBの代表的なDBAPIは以下の一覧の通りとなります。| No | DB | モジュール名 | 備考 |
| — | — | — | — |
| 1 | MySQL | mysql、pymysqlなど | |
| 2 | MariaDB | mariadb | mysql用のパッケージも代用可能 |
| 3 | Postgr
【Python】データサイエンス100本ノック(構造化データ加工編) 033 解説
– データサイエンス100本ノックをやりきる会を作りました?
– こちらの[Slack招待URL](https://join.slack.com/t/data-science-100nocks/shared_invite/zt-gfncg9vm-8W8b3UrDg8R~TKaqUkQpgw)からご参加ください!!
– ぜひ一緒に励まし合いながら、データサイエンス100本ノックをやり切りたいと思っています!##Youtube
[動画解説](https://youtu.be/pCm70lEQgZ4)もしています。##問題
P-033: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、330以上のものを抽出せよ。##解答
“`:コード
df_receipt.groupby(‘store_cd’).amount.mean().reset_index().query(‘amount >= 330’)
“`##出力
| | store_cd | amount |
|:———–|
Pythonで解く【初中級者が解くべき過去問精選 100 問】(015 – 017 全探索:順列全探索)
# 1. 目的
[初中級者が解くべき過去問精選 100 問](https://qiita.com/e869120/items/eb50fdaece12be418faa)をPythonで解きます。
すべて解き終わるころに水色になっていることが目標です。本記事は「015 – 017 全探索:順列全探索」です。
# 2. 総括
順列系の問題では“`itertools“`をうまく使うと解ける場合が多いです。
“`permutaions“`と“`combination“`と“`product“`はよく使うので、この辺はいろいろサンプルデータで試しながら学びました。# 3. 本編
## 015 – 017 全探索:順列全探索
### 015. [AtCoder Beginner Contest 145 C – Average Length](https://atcoder.jp/contests/abc145/tasks/abc145_c)
“`
pip install pytube
“`とコマンドラインに入力し、pytubeをダウンロードしました。
しかし、実際に実行してみると、
上の画像のように
**ImportError: cannot import name ‘quote’ from ‘pytube.compat’**
というエラーが発生してしまいました。調べてみると、
>https://github.com/nficano/pytube




