
- 1. Djangoでモデル関係図を自動生成
- 2. 毎日定時に推し画像が送られてくるLINE Bot を作った
- 3. 停まれ標識検知 可視化部分の開発part2 物体を検知した時にソケット通信で別システムに知らせる
- 4. Anacondaで仮想環境を利用する コマンドライン集
- 5. 【Django】どうしても別アプリのテーブルを使いたい場合の逃げ道を丁寧に解説する
- 6. Docker で始める PySpark 生活
- 7. herokuで「ERROR: cannot execute ALTER TABLE in a read-only transaction」がでて困る
- 8. 【Python】スプラトゥーン2のリーグマッチデータを相関係数表を使って分析する
- 9. 【Python】自動フォルダ作成ツールを開発してみた!
- 10. Think Python 2E ハック
- 11. ‘pip’ は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。
- 12. 数値を線形探索/2分探索で探してみよう
- 13. Python3のExecutor.submitを大量に実行するとメモリを多く消費する場合がある
- 14. 異常検出の基本的な流れ
- 15. PythonでTwitterのツイートをしてみたいけどハマった話
- 16. Natural Language : GPT – Japanese Generative Pretraining Transformer
- 17. Pythonに疲れたのでnehanでデータ分析してみた(コロナ禍でもライブに行きたい – 後編)
- 18. Pythonの内包表記が好きなのでmapと比較検証してみた
- 19. Django シフト表 自分の所属している施設のみを表示する
- 20. [Python]アイシャドウのランキング上位10位をグラフにしてみた
Djangoでモデル関係図を自動生成
#概要
Django extensionsのgraph_modelsを使用し、モデルの関係図を自動生成する方法の自分用まとめ。
envではなく、dockerコンテナ内で実行する手順になっています。#準備
##インストールなど
必要なパッケージをインストールする。“`python
pip install pygraphviz
pip install pydotplus
pip install django-extensions
“`windows環境でpygraphvizをインストールしようとするとVCビルドツールをインストールしたりする必要があるので注意。
また、dockerコンテナで行う場合、次の作業も必要でした。
graphvizをインストール。“`python
apt-get install -y graphviz
“`日本語で出力したい場合、日本語フォントのインストール。ttcファイルはwindowsなどから適当に用意。
Dockerfileに記載してしまうのが楽です。“`python
$ cp meiryob.ttc /usr/share/
毎日定時に推し画像が送られてくるLINE Bot を作った
# はじめに
松岡茉優ファン(通称まゆらー)である僕が、
僕だけの僕だけによる僕だけのためのLINE Bot を作った。ファンになって5年くらいになると、
→ツイッターのタイムラインで松岡茉優さん関連のツイートを探す
→松岡茉優さんの画像や動画を保存するこの作業に昔ほどの楽しみを覚えなくなり、かつ私自身も社会人になったりして、毎日ツイッターサーフィンする時間も無くなってきます。
**全部自動化しちゃおう!!**
ってことでその第一弾として、ツイッターで最近人気の画像・動画付きのツイートを検索、画像URL取得、LINE Bot を使って毎日定時に送信する!!!!
よかったら友達追加してください。

with socket.socket(socket.AF_INET, socket
Anacondaで仮想環境を利用する コマンドライン集
#はじめに
SEIYA(@SeiyaSunapro7th)です.
Anacondaを用いた仮想環境(conda環境)を利用する際に役に立つコマンドラインをまとめてみました.###実行確認ができた環境
macOS Catalina ver.10.17.7
conda ver.4.8.5#1. Anacondaで仮想環境を構築する
###1-1. 仮想環境を構築
conda環境を構築するためのコマンド.
conda環境を構築する際に加えるパッケージを指定する.
versionの指定をしなければ最新versionがinstallされる.“`
$ conda create -n 環境名 加えるパッケージ
“`ex. conda環境にpython3.7とnumpyをinstallする場合
“`
$ conda create -n環境名 python=3.7 numpy
“`###1-2. ライブラリを追加
構築したconda環境にcondaが対応しているライブラリをinstallする.“`
$ conda install ライブラリ名
“`#2. c
【Django】どうしても別アプリのテーブルを使いたい場合の逃げ道を丁寧に解説する
#はじめに
別アプリのテーブルを使う方法について調べるのに少し時間がかかったので記事にしておきます。#解決方法
やり方は大きく二つあります。
###1.使用したいテーブルのmodelをimportして使用する
今回解説するのはこちらの方法。###2.アプリを統合してしまう
テーブルを共有したいアプリ同士を[一つのアプリとして統合してしまいます](http://coinbaby8.com/django-folder-structure-idea.html)。
Djangoの基本思想である「各アプリ同士は依存関係を持つべきではない」というルールに則ると**こちらが正攻法です**。簡単に説明すると、アプリA、Bがあった時、Aのアプリ上で定義されたテーブルをBが使用するということは、Bは
Docker で始める PySpark 生活
# はじめに
「Spark?雷属性でかっこいい!」という煩悩のもと,Docker + Spark + Jupyter Notebook で簡単な機械学習を回して見ました.
お馴染みのタイタニックデータを使い,線形回帰による予測を行いました.# そもそも Spark とは

Spark とは分散処理ライブラリの一つです.
分散処理といえば Hadoop という方も多いと思いますが,自分の理解だと Spark は Hadoop の欠点を補ったライブラリになります.Hadoop が登場したのが 2006 年,その後,2014 年に Hadoop が登場しました.### Hadoop VS Spark
上記,Spark は Hadoop の欠点を補ったとありますが,双方にメリット・デメリットがあるため簡単に表にまとめます.
||
herokuで「ERROR: cannot execute ALTER TABLE in a read-only transaction」がでて困る
# 問題
herokuの「Heroku Postgres – Add-ons」で行を追加しようと「ERROR: cannot execute ALTER TABLE in a read-only transaction」と怒られます.

# 解決策
こんなpythonからPostgresデータベースにアクセスするクラスを作成.
“`python
import os
import psycopg2
import json
import pprintclass PostgreSql:
def __init__(self):
self.conn = self.get_connection()
self.cur = self.conn.cursor()###########
【Python】スプラトゥーン2のリーグマッチデータを相関係数表を使って分析する
# 【Python】スプラトゥーン2のリーグマッチデータを相関係数表を使って分析する
## はじめに
スプラトゥーン2の戦績データは任天堂のサーバーに直近50試合分が保管され、公式アプリ「イカリング2」で確認することが出来る。後述する「ikaWidget2」では、この戦績データをダウンロード・保存し、キルやデスの平均値や、ステージ毎の勝率等の統計データが取得できる。「スプラデータクラブ」等のWebサイトでは、「ikaWidget2」に保存されたデータを用いることで、より詳細な統計データを得ることが出来る。しかし、こういった統計データの多くは各個人の戦績に基づいたものであり、**4人用モード「リーグマッチ」における自チーム内の相互作用に着目した解析ツールはほとんどない**。本記事では「リーグマッチ」における自チーム内スコアの相関係数表を計算するライブラリを作成し、それを利用して試合の分析を行う。
## スプラトゥーン2とは
### 概要

## はじめに
前回の記事で自動でフォルダを作成してくれるコードを書きましたが、GUI化して、操作しやすいようにした方が複数のフォルダを作成するときに、楽だと思ったので作成してみることにしました。
## 環境
実行は以下の環境で行いました。Windows 10 version 1903
Python 3.7.6
PyInstaller 3.6
## 完成品
完成したものはこちらになります:point_down:
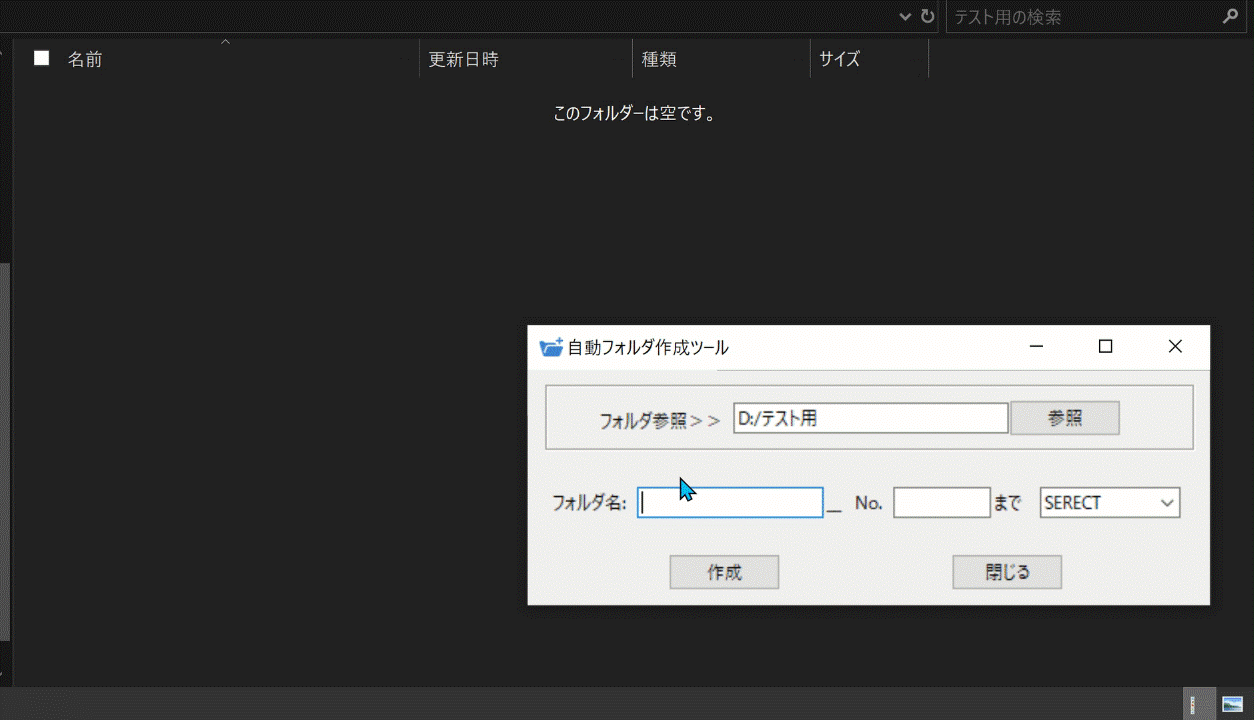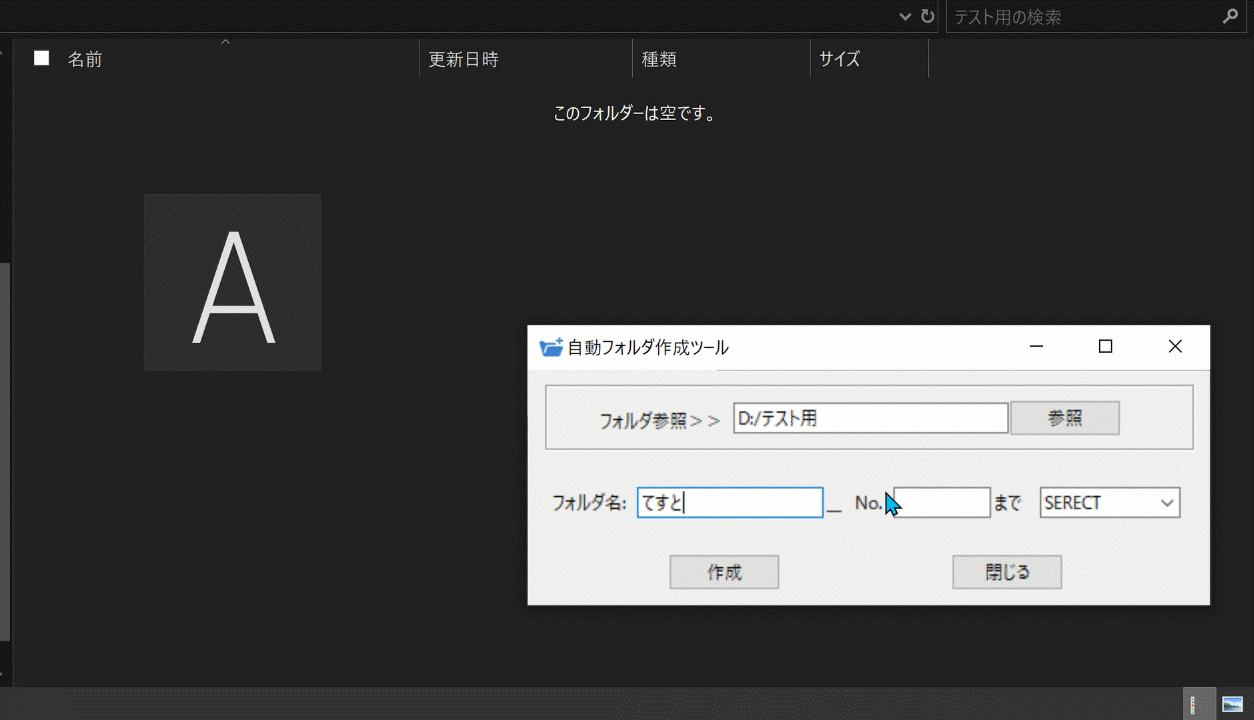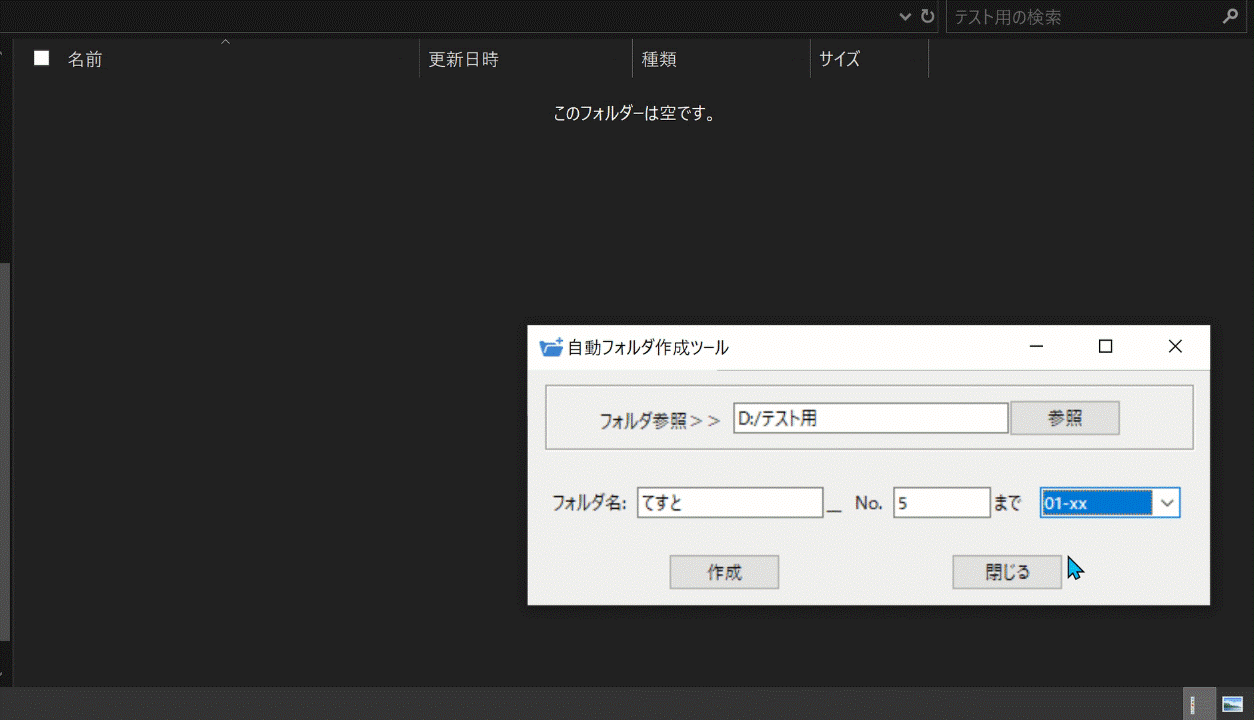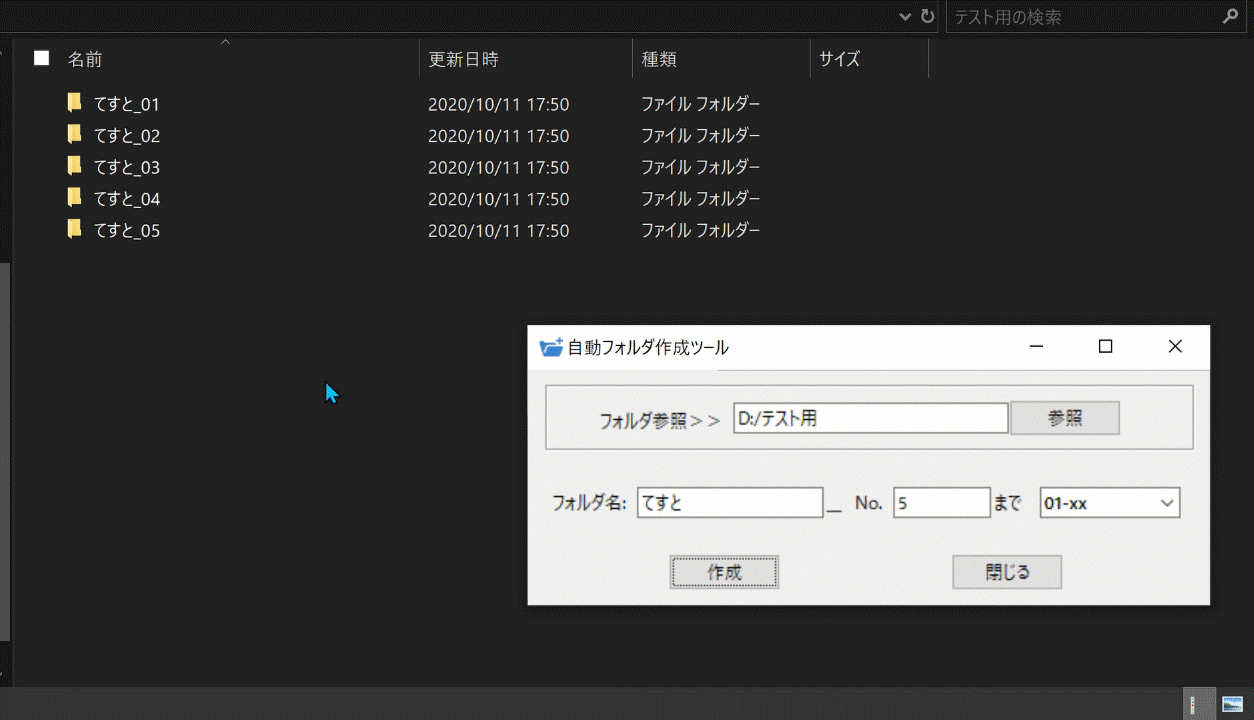パスを指定して、フォルダ名とフォルダを何個まで作成するかを入力し
Think Python 2E ハック
#Think Python 2E ハック
Think Python 2Eを学んでまともなプログラマーになるためのに#モチベーション
NEXT STEP NEXT STEP#概要
think Python 2e を
問題を含めてハックする。
http://facweb.cs.depaul.edu/sjost/it211/documents/think-python-2nd.pdf
#目次
・エクササイズノート#エクササイズメモ
##CHAPTER 2
Exercise 2-1
省略
Exercise 2-2
>>> import math
>>> 4 / 3 * math.pi *(5*5*5)
523.5987755982989
>>> 24.95*(100-40) + 3 + 24.95*(100-40)* (60-59)+ 59 * 0.75
3041.25>>>7:30:06
‘pip’ は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。
#環境
数値を線形探索/2分探索で探してみよう
こんにちは。
いつも応援有難うございます m(_ _)m
9/23 から投稿を開始して、そろそろ 3 週間が経とうとしています。
楽しいことは あっ という間ですね(笑)。さて、今回は探索です。
最初は線形探索から行きましょう。
構えなくて大丈夫です。

こんな感じで左から順番に、探したい値と赤字が一致しているか確認するだけです。
※すいません、途中で図が切れてて。。
早速、書いてみましょう。“`linear_search.py
def search(x,key):for i in range(len(x)):
if x[i] == key:
print(f”value is placed at x[{i}]”)
break
#最終項 x[6] != key
Python3のExecutor.submitを大量に実行するとメモリを多く消費する場合がある
参考にしました: https://www.bettercodebytes.com/theadpoolexecutor-with-a-bounded-queue-in-python/
概要
———-Executorでmax_workersを指定すると並列度が調整できますが、並列数を上回るペースでsubmitした場合にどうなるかというとブロックは起きません。その代わりメモリにため込むようです。この動きのため、大量に実行するとメモリを多く消費してしまうことがあります。
“` py
with ThreadPoolExecutor(max_workers=10) as executor:
for i in range(0, 1024*1024): # たくさん
executor.submit(fn, i) # つくる
# forループはすぐ終わるが、消費メモリがすごいことになっている
“`実際、100万ループするようなコードを書くとメモリを2GBぐらい消費します。なので、対応を考えることにしました。
内部実装と原因
—
異常検出の基本的な流れ
##1. 前処理
KaggleのCredit Card Fraud Detectionを利用する。“`python
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
from sklearn import preprocessing as pp
from scipy.stats import pearsonr
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import log_loss
from sklearn.metrics import precision_recall_curve, average_precision_score
from sklearn.metrics
PythonでTwitterのツイートをしてみたいけどハマった話
自動でTwitterのツイートをしてみたいという話を聞いて、ちょっと作ってみたがハマった話
#CONSUMER_KEYがない
色々なサイトを見て検索するとpythonからツイートをするにあたって必要な項目が4項目あります。
CONSUMER_KEY, CONSUMER_SECRET,
ACCESS_TOKEN, ACCESS_SECRETが必要と出てくるのですがどう見てもCONSUMER_KEYとCONSUMER_SECRETがない!

ただ、どうやっても見つからないので検索すると
CONSUMER_KEYはAPI KEYで
CONSUMER_SECRETはAPI_key_secretでいいそうです。検索すればよく見るコードですが下記のコードに変数を変更しました。
このほうが理解
Natural Language : GPT – Japanese Generative Pretraining Transformer
#目標
Microsoft Cognitive Toolkit (CNTK) を用いて GPT をやってみました。訓練に使用する日本語のコーパスを用意しておきます。
NVIDIA GPU CUDA がインストールされていることを前提としています。#導入
今回は日本語のコーパスを用意して日本語文生成モデルを訓練しました。単語の分割に関しては、sentencepiece [[1]](#参考) を用いたサブワードモデルを作成しておきます。##GPT
Generative Pretraining Transformer (GPT) [[2]](#参考) は Transformer [[3]](#参考) の Decoder 部分だけを使用します。Transformer については [Natural Language : Machine Translation Part2 – Neural Machine Translation Transformer](https://qiita.com/sho_watari/items/a23dddd60181d7f4f11e) で紹介しています。
Pythonに疲れたのでnehanでデータ分析してみた(コロナ禍でもライブに行きたい – 後編)
## ご挨拶
こんにちは、マンボウです。
**「Twtter×コロナ」**引き続き分析していきます。
[前編](https://qiita.com/nehan_io/items/a24efef4ad99e5739579)はtweetテキストを形態素解析し、頻出単語の日別出現数を出すところまでやりました。↓選ばれた頻出単語27

## Twitterのデータから、上昇・下降トレンドの単語を探してみる
コロナウイルスが社会問題になってから半年以上が経過しました。
人々の中で何が高まり、逆に何が忘れられているのか、つぶやきから追ってみます。
後編では、回帰分析を用いて上昇・下降トレンドの単語を見つけ出します。## データ
前編で作成した、日別・単語別出現数のデータを使います。
↓データ
![スクリー
Pythonの内包表記が好きなのでmapと比較検証してみた
##はじめに
こんにちは、麻菜結です。Pythonの内包表記が数多あるプログラミング言語の記法の中でも多機能かつ可読性が高く素晴らしい文法なのは間違いありませんが(個人の意見であり多大に偏見を含んでいる可能性があります)、よく競技プログラミングでは以下の記法が見られます。“`Python
l = list(map(int, input().split()))
“`内包表記の敵、`map`ですね(偏見を(略)。いちいち`list`かまさないといけないmapがなんぼのもんじゃい!ということで速度を比較してみました。
##環境
wsl1のUbuntuを使います。“`Bash
$ uname -a
Linux LAPTOP-H6KC5C7N 4.4.0-18362-Microsoft #1049-Microsoft Thu Aug 14 12:01:00 PST 2020 x86_64 x86_64 x86_64 GNU/Linux
$ py –version
Python 3.8.0
“`##概要
`1` 10000行5列の非負な整数値が並ぶテキストファイルを
Django シフト表 自分の所属している施設のみを表示する
スタッフ全員で20名を超えるのでシフト表が自分の関係ない施設分まで表示されていると見にくくなるので、修正しました。
この修正にかなりてこずり、Qiitaで質問させていただき実装できました:point_up:“`python:schedule/views.py
from django.shortcuts import render, redirect, HttpResponseRedirect
from shisetsu.models import *
from accounts.models import *
from .models import *
import calendar
import datetime
from datetime import timedelta
from datetime import datetime as dt
from django.db.models import Sum, Q
from django.contrib.auth.models import User
from django.views.generic import FormV
[Python]アイシャドウのランキング上位10位をグラフにしてみた
# 概要
化粧サイト[LIPS](https://lipscosme.com/)では化粧品のランキングが見れます。
今回はアイシャドウのランキングを取得し、
縦軸は商品の名前、横軸を星の評価にしてグラフにしたいと思います。
上から下への流れが順位となります。
# 完成
# コード
“`Python
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt# LIPSの






