
- 1. Python の Flask Web API に JWT による認証を組み込む
- 2. Ubuntu 20.04 で pyenv を使用して Python を導入する
- 3. PyMySQLでBulk Updateをする方法と注意点【Python】
- 4. 著書「python で作る対話システム」の天気予報ボットを参考に公式ラインに天気予報させてみた。
- 5. Python3 と venv と Ansible
- 6. kaggle の Courses を読む —Intermediate Machine Learning 5
- 7. Pythonを使って複数画像をPDFに変換する
- 8. 【Python】Excelの複数シートを1つにまとめる
- 9. AtCoder Recommendation 埋め
- 10. Pythonで仮想環境をつくる_Mac版
- 11. COVID-19のオープンデータを検証するというお話
- 12. djangoのモデルを特定の条件でソートする
- 13. 【ロジスティック回帰】statsmodelsでk分割交差検証を実装する
- 14. DBからデータを取得して返り値にするときに詰まったこと
- 15. バッチ設計とPython
- 16. Pixel4のカメラで学ぶDepth map-1(helper実装)
- 17. アラートメールを判別させたい。 – その x はワイルドカード? –
- 18. Redashでクエリを投げてみる
- 19. Splunkで見る新型コロナウィルスのファクトフルネス
- 20. apt-getを使用してnginx python postgresqlをinstallする
Python の Flask Web API に JWT による認証を組み込む
## はじめに
Python で作成した Flask Web API に対して、JWT (JSON Web Token) 認証を組み込んでみました。
参考:[Python + Flask + MongoDB を利用した Web API の作成と Azure VM + Nginx への配置(ホロライブの動画配信予定を収集 その3)](https://qiita.com/kerobot/items/bd504b0d787de63c364e)## JWT (JSON Web Token) とは
JWT は JSON Web Token の略で、要求情報(Claim)を JSON オブジェクトとしてやりとりするトークンの仕様です。
仕様は RFC7519 で定められており、二者間の通信時の認証(Authorization)に利用されます。今回は、Web API へのリクエストで指定されたユーザー名とパスワードを元に、JWT トークンを生成してレスポンスとして返し、その JWT トークンを用いて、Web API の機能を利用できるようにしてみました。
## 環境
* ローカル環境
Ubuntu 20.04 で pyenv を使用して Python を導入する
本記事では、Ubuntu 20.04 上に [pyenv](https://github.com/pyenv/pyenv) を使用して Python を導入する手順をまとめます。
# 注意
– そもそも pyenv が必要なのか確認しましょう。pyenv で期待通りに動作する Python を導入するのは簡単ではありません。(私は 1 時間くらいネットをさまよいました。)
– ただ Python が欲しいだけの方は、環境構築で苦労したくなければ OS 標準のパッケージ(Ubuntu なら `sudo apt install python3-pip`)や [Anaconda](https://www.anaconda.com/) などに頼ることをおススメします。
– 個人的に、pyenv は環境構築で困ったときにネットで対応策を探す面倒を受け入れられる人でないと使えないと思っています。正しく導入できれば便利なんですけどね…。
– 下記の手順の一部は、Ubuntu 20.04 に依存しています。Ubuntu 18.04 にすら対応していません。
– 一応、該当箇所には Ub
PyMySQLでBulk Updateをする方法と注意点【Python】
# 結論
* INSERT … ON DUPLICATE KEY UPDATE 構文の場合はexecutemanyを使う。
* ELT&FIELDでのUpdateをする場合はプリペアドステートメントでパラメータをセットする。# INSERT … ON DUPLICATE KEY UPDATE 構文
`VALUES`などの一度にデータを挿入するクエリでは`executemany`メソッドを使うことができます。
“`python
conn = pymysql.connect(
mysql_endpoint,
user=username,
passwd=password,
db=dbname
)def bulk_insert_and_update_users():
prepared_statement = [
[
1, # id
‘Qiita太郎’, # name
20 # age
],
[
著書「python で作る対話システム」の天気予報ボットを参考に公式ラインに天気予報させてみた。
#pythonで作る対話システムに書かれた内容と変えた点
・XMLではなくSQLite3を使って状態遷移をさせた#ポイント
・本のコードをそのまま公式ラインに使用しようとすると遷移情報の保持が出来なかったため、SQLite3を使用した。#次に目指すもの
「大阪じゃなくて」のように入力を取り消すことが出来るようにする。
pythonで作る対話システムの非タスク編へ#プログラムの構造
#下記:天気予報公式ラインのコード
“`python:weather_system.py
import sys
from PySide2 import QtCore, QtScxml
import requests
import json
from dat
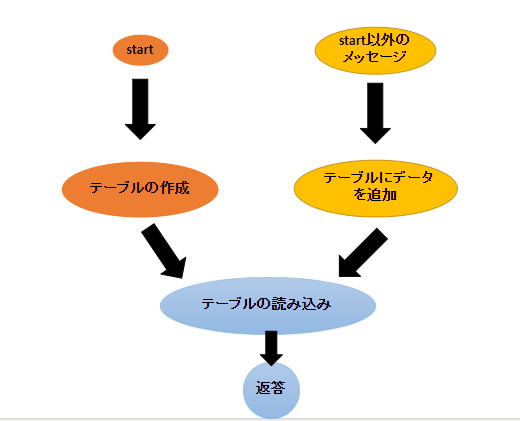
Python3 と venv と Ansible
# はじめに
Python2 系のサポートが終了してそろそろ1年ですね。
常日頃使っているサーバでは、まだ2系で問題なくスクリプトが動いているわけですが・・・
そろそろ3系も使えるようにならねばと、一念発起し今回調べた内容を簡単にまとめてみました。
タイトルの通り複数環境用に “`venv“` と 、インフラ環境構築用で使う “`Ansible“` を例にとって説明します。# 環境構成
VirtualBox 上に CentOS 7 を起動して試行します。**ホストマシン**
– Windows 10 Pro (20H2)
– VirtualBox:6.1.16
– Vagrant:2.2.14**ゲストマシン**
– CentOS:7.8.2003
# VM 起動
以下 “`Vagrantfile“` で起動します。
“`vagrant up“` !
※CPU や Memory の設定はお好みで“`ruby:Vagrantfile
# -*- mode: ruby -*-
# vi: set ft=ruby :Vagrant.configur
kaggle の Courses を読む —Intermediate Machine Learning 5
# twitter 始めました
こんにちは! まはらせないきと申します!
突然ですが、ついに [twitter](https://twitter.com/MaharaseNaiki) 始めました!
あまり有益なことは発信できませんが、先輩方の知見や経験を得られたらと思っています!それでは今回もよろしくお願いします!
___
__Intermediate Machine Learning__ では、機械学習をより深掘っていきます~Intermediate Machine Learning の流れ~
1. 導入
2. 欠損値
3. カテゴリー変数
4. パイプライン
5. 交差検証
6. XGBoost
7. データの漏洩今回は __6__ の内容です!
# eXtreme Gradient Boosting
Gradient Boosting は、__勾配ブースティング__ と翻訳されています。この勾配ブースティングにさらなる精度と速さを実装したものが、__XGBoost__ です。Scikit-learn には別の勾配ブースティングの手法もありますが、XGBoost の
Pythonを使って複数画像をPDFに変換する
この記事は、Pythonを使って複数の画像を一つのPDFにまとめたいと考えているユーザーに向けたものです。
以前の公開コードをPython3で試したら動作しなくなっていたので、Python3ユーザー向けに更新しています。
## 前提
macOS Catalina (10.15.6)
python 3.7.5## 事前準備
img2pdfをインストールします。
https://pypi.org/project/img2pdf/“`py
pip3 install img2pdf
“`
インストールに成功したことを確認“`
Installing collected packages: Pillow, img2pdf
Running setup.py install for img2pdf … done
Successfully installed Pillow-7.2.0 img2pdf-0.4.0
“`## 画像をPDFに変換する
以下のスクリプトを記述します。ここではファイル名を convert2pdf.py とします。
“`py:convert
【Python】Excelの複数シートを1つにまとめる
Excel for Macでは、ピボットテーブルを作成する際に複数テーブルを一括指定できないため結構不便です。(古いバージョンではできていたはず…)
まずは、pythonで複数シートのデータを1つシートにまとめてデータを扱いやすくしていきます。#使用ライブラリ
openpyxlを使用します。
Excelの読み書きなどの操作を行うためのライブラリです。
https://openpyxl.readthedocs.io/en/stable/#事前準備
openpyxlのインストール“`
pip install openpyxl
“`#ファイルの読み込み
“`python
#ファイルの読み込み
read_path = “./input.xlsx”
output_path = “./output.xlsx”
wb = load_workbook(read_path)“`
#全シートのデータを取得する
“`python
#全シートのデータを取得する
sheet_names = wb.get_sheet_names()
first_row = 1
l_2d_outpu
AtCoder Recommendation 埋め
###[C – Unification](https://atcoder.jp/contests/abc120/tasks/abc120_c)
最初は配列の最後尾から0と1を取り除くことを考えました。
しかし計算量が多いと思い組むだけにしました。“`C++:C++
#include#define rep(i,n) for(int i=0; i<(n); ++i) #define fixed_setprecision(n) fixed << setprecision((n)) #define execution_time(ti) printf("Execution Time: %.4lf sec\n", 1.0 * (clock() - ti) / CLOCKS_PER_SEC); #define pai 3.1415926535897932384 #define NUM_MAX 2e18 #define NUM_MIN -1e9 using namespace std; using ll =long long; using P = pair
Pythonで仮想環境をつくる_Mac版
# 目次
# 目次2
COVID-19のオープンデータを検証するというお話
この記事は[Civictech1年目 Advent Calendar 2020](https://qiita.com/advent-calendar/2020/civictech_rookies)の最終日(25日目)の記事です。(とは言ったものの、書き溜めしていた記事を消化したもので、あまり面白い記事ではないです…)
どうも、兵庫県版コロナウイルスまとめサイトコントリビュータ、y-chanです。本家東京都サイトにも積極的にコントリビュートしたり、SecHack365に受かっていろいろ開発したり、[CCC2020](https://ccc2020.code4japan.org)の運営をしていたりと大忙しな感じです。
今回は、COVID-19のオープンデータを検証するというような、おそらくどこもやってない(当社調べ)ことをやったのでそれについてちょっと書き残しておこうかなといった感じです。聞きかじった話が含まれてるので間違ってる部分もあるかと思いますが、編集リクエストなんかで優しく直してくれるとありがたいです。# 私たちはデータラングリングをしている
前置き的なお話をしたいと思い
djangoのモデルを特定の条件でソートする
# djangoのモデルを特定の条件でソートしたい
“`models.py
class Tag(models.Model):
# タグに振られるID
tag_id = models.AutoField(primary_key=True, verbose_name=’タグID’)
# タグの名前
tag_name = models.CharField(max_length=20, verbose_name=’タグ名’)def __str__(self):
return str(self.tag_name)class IdeaTagMap(models.Model):
ideatag_id = models.AutoField(primary_key=True, verbose_name=’アイデアタグのID’)
# 紐づけられる投稿
idea = models.ForeignKey(PostIdea, on_delete=models.CASCADE)
# 紐づけられるタグ
tag
【ロジスティック回帰】statsmodelsでk分割交差検証を実装する
#はじめに
pythonでは,ロジスティック回帰モデルを利用できるライブラリとして主にscikit-learnとstatsmodelsが用いられます.statsmodelsには係数の有意差検定を自動でしてくれるといったscikit-learnにはない利点がある一方で,代表的なモデルの評価方法であるホールドアウト法や交差検証法に対応していません.そこで今回は,statsmodelsでk分割交差検証法を実装するためのコードを作成してみます.statsmodelsを用いたホールドアウト法の実装については[こちら](https://qiita.com/takato0884/items/fd957fd431d41bcb3ada)をご覧ください.
# ライブラリのインストール
“`python:sample.ipynb
import numpy as np
import pandas as pd
import statsmodels.api as sm
“`
#データのインストールと前処理
データには,私が卒業研究のために独自に集めたクラウドファンディングに関するデータを用います.
このデ
DBからデータを取得して返り値にするときに詰まったこと
(備忘録なので簡単に。より詳しい情報は[ドキュメント](https://docs.sqlalchemy.org/en/13/)などを参照ください)
##execute()の返り値
・sqlalchemyでDBに接続して、excute()でクエリを発行したとき、
返ってくるのは’sqlalchemy.engine.result.ResultProxy’クラスの
オブジェクト・つまり、DBから取得した値をintやstrなどで返すためにはひと工夫が必要
↓↓↓例えばこんな感じ↓↓↓
~~~py
from sqlalchemy import create_engine
# 余談だけど型アノテーションはちゃんとしよう。この関数宣言をまねしちゃダメだぞ
def fetchUserIdFromDB(userName):
# DB接続
engine = create_engine(‘sqlite:///app.db’)userId = []
with engine.connect
バッチ設計とPython
# はじめに
Python Advent Calendar 2020 25日目:christmas_tree:です。時代はサーバレースですが、オンプレミスのサーバやクラウド(IaaS)などのインスタンスでバッチを運用しているシステムもまだたくさんあると思います。
本記事ではサーバ上で動かすバッチを前提とし、前半はアンチパターンなどを踏まえながらバッチ設計のポイントについてまとめています。後半はPythonでバッチ開発する際のTipsになります。
**※本記事の内容は、あくまで考え方の一例であり、必ずしも全ての考え方がシステムに適合したり、ここに書いている内容で満たされている訳ではありません。**
## バッチ設計
バッチ処理はひとまとまりのデータに対して、一連の処理を連続で実行する処理方式のことです。語源を辿ると、汎用コンピューターの時代まで遡ります。データを一括で処理することを目的とし、Unix系OSではcronを利用して指定した日時で運用することが多いです。また、バッチ自体のことをジョブと呼んだりもします。大規模システムではたくさんのジョブを管理するため、専用のジョブ
Pixel4のカメラで学ぶDepth map-1(helper実装)
#はじめに
この記事は[Note](https://note.com/sv_engineer/m/m98195ca0c6e1)で連載している記事で扱っているCode部分のみを切り出しています。技術背景等にご興味がある方はNoteの記事の方をご参照ください。#helperの実装
画像の入出力を多用するのでそれらをhelperとしてまとめて実装しておきます。そうすることでCodeが見やすくなりますし、メンテナンスが楽になります。使用するライブラリーは以下となります。事前にpip等でインストールしておいてください。
– glob
– OpenCV
– numpyそれでは実際の実装を記載します。
###指定したFolder内のファイル一覧作成
globを使用し、指定したFolder内で指定した拡張子を持つファイルの絶対パスリストを作成します。相対バスでも良いですが、後々絶対パスの方が扱いやすいので絶対パスで取得します。“`python:helper.py
def make_file_path_list(path: str, ext: str) -> [str]:
アラートメールを判別させたい。 – その x はワイルドカード? –
こんにちは。NETS1の田中(た)です。
[アラートメールを判別させたい。 – XXXXXはワイルドカードなんです! -](https://qiita.com/tatsumiya2015/items/515e40a721b23f3300f9) の続きです。
最終日が誰も登録されていないようなので書くことにしました。
# うまく判定してくれないメールの登場
ある時こんなアラートメールが届きました。
“`
Dec 14 12:59:12 app001 2020/12/14 12:59:12.449 app001 ERROR ERROR002 ecnxeci-1349 すごいことがおきました。 sugoi[10223] でエラー あぁ、なんという!
“`一覧表をみれば明らかに電話連絡とわかります。
|エラーコード|エラーメッセージ|対応|
|:———-|:————–|:————:|
|ERROR002|app00x ERROR ERROR002 xxxxx すごいことがおきました。 XXXXX[10223] でエラー|電話連絡
Redashでクエリを投げてみる
# はじめに
先日Redashをローカル環境にインストールしたので、今回はデータベースにデータを入れて、Redashでクエリを投げるところまでを実施します。
Redashのインストールについては[こちら](https://qiita.com/dyamaguc/items/a7a16f8ca9b562c33090)をご覧ください。# 環境
MacBookAirを使用しています。OSなどは次の通りです。
“`
$sw_vers
ProductName: Mac OS X
ProductVersion: 10.13.6
BuildVersion: 17G14033$python –version
Python 3.7.3$docker –version
Docker version 20.10.0, build 7287ab3
“`Redashを起動した状態を想定しています。
“`
$docker container ls
CONTAINER ID IMAGE COMMAND CREATE
Splunkで見る新型コロナウィルスのファクトフルネス
メリークリスマス!2020年もあと1週間。今日の夕方のクリスマスケーキとチキンの行列はいつもより長かった気がします。みなさん自宅でのクリスマスなんでしょうか。
2020年1月から発覚した、新型コロナウィルスと3月のパンデミック。毎日報道されています。だいたいは最高人数更新のニュースなのですが、最高で無い場合は過去の曜日の最高や、大阪が最高だの、煽っているようにしか見えません。
2017年の日本のがん死亡者数:373,584人、(https://ganjoho.jp/reg_stat/statistics/stat/summary.html)心筋梗塞などの心疾患死亡者数は204,837人(http://www.seikatsusyukanbyo.com/statistics/2019/009997.php#:~:text=%E5%8E%9A%E7%94%9F%E5%8A%B4%E5%83%8D%E7%9C%81%E7%99%BA%E8%A1%A8%E3%81%AE%E3%80%8C%E4%BA%BA%E5%8F%A3,%E3%81%AB%E5%A4%9A%E3%81%84%E6%9
apt-getを使用してnginx python postgresqlをinstallする
#前提
ubuntu (もしくは debian ?)#コマンド
“`
sudo apt-get updatesudo apt-get install nginx python3-pip python3-dev libpq-dev postgresql postgresql-contrib
“`以上




