
- 1. 速いと噂のPythonのVaexについて詳しく調べてみた。
- 2. 【備忘録・随時更新】AzureFunctionsのあれこれ
- 3. 【Python】配列生成(初期化)時間まとめ!!!
- 4. taichiの使い方① ~mp4とgifで出力~
- 5. タコヤキオイシクナールをセグメントツリーへの乗せる際の考え方
- 6. 【強化学習】KerasでApe-Xの解説・実装(失敗)
- 7. [エラー]IOPub message rate exceeded. The notebook server will temporarily stop sending output to the client in order to avoid crashing it.
- 8. 【備忘録】初めてのAzureFunctionsのデプロイ
- 9. 【Python3】機械学習を使ってデータ分析をやってみよう!(回帰)
- 10. Githubトレンドリポジトリ①~面白そうなグラフィック系のリポジトリを発見したので試してみた~
- 11. 複数のバージョンのCUDAを同一環境で扱う方法
- 12. Pythonでtry/exceptと、ディクショナリの編集、取り出しの応用練習
- 13. Python の Flask Web API に JWT による認証を組み込む
- 14. Ubuntu 20.04 で pyenv を使用して Python を導入する
- 15. PyMySQLでBulk Updateをする方法と注意点【Python】
- 16. 「python で作る対話システム」の天気予報ボットを参考に公式ラインに天気予報させてみた。
- 17. Python3 と venv と Ansible
- 18. kaggle の Courses を読む —Intermediate Machine Learning 5
- 19. Pythonを使って複数画像をPDFに変換する
- 20. 【Python】Excelの複数シートを1つにまとめる
速いと噂のPythonのVaexについて詳しく調べてみた。
結構前にPandasやDaskなどよりも大分高速と話題になっていたPythonのVaexライブラリについて、仕事で利用していきそうな気配がしているので事前にしっかり把握しておくため、色々調べてみました。
# どんなライブラリなのか
– Pandasと同じように行列のデータフレームなどを扱うことのできるPythonライブラリです。
– Pandasと比較して膨大なデータの読み込みや計算などを高速に行えます(数十倍~数百倍といったレベルで)。
– 計算上のメモリ効率がとても良く、無駄の少ない実装になっています。
– Daskのように計算が遅延評価されたりと、通常はメモリに乗りきらないデータでも扱うことができます。
– Daskのように並列処理で計算を行ってくれます。
– Pandasと比較的似たインターフェイスで扱うことができます。# この記事で触れること
主に以下のVaexのトピックに関して本記事で触れます。
– インストール関係
– カラムへのアクセス
– スライス制御
– 各種要約統計量の計算
– データの選択(selectとselection)
– 各種データの読み込み
【備忘録・随時更新】AzureFunctionsのあれこれ
# 1. はじめに
この記事は、[前回の備忘録](https://qiita.com/gsy0911/items/61198607476ac686ce6f)にて書けなかった事柄について
書いていきます。項目は以下の通りです。
また、この記事は随時更新予定です。| 節 | タイトル | 内容 |
|:–:|:–|:–|
| 2 | API Manaegmentと統合 | AzureFunctionsをドメインを付与したURLで実行可能にする |
| 3 | Azure Identityの利用 | 他のリソースへのアクセスを許可する |# 2. API Managementと統合
この説では、API Managementを利用して、作成したAzureFunctionsのHttpTriggerの利便性を高くします。
## 2.1 Azure FunctionsのHttpTriggerの不十分な点
API Managementを作成する前に、AzureFunctionsのHttpTriggerでは不十分な点について説明します。
それは、AzureFunctionsで発
【Python】配列生成(初期化)時間まとめ!!!
#まとめ!!!
最初に結果をまとめておこう.いわゆる「時間のない人のための」というやつである.かなり見やすくまとまっていると自負している.##1d配列
| Code | Mean | Stdev. | Runs | Loops |
|—————————-|———|———|——–|———|
| `np.empty(N) ` | 1.76 µs | 32 ns | 7 runs | 1000000 |
| `np.zeros(N) ` | 11.3 ms | 453 µs | 7 runs | 100 |
| np.ones(N) | 14.9 ms | 182 µs | 7 runs | 100 |
| np.zeros_like(np.empty(N)) | 19.9 ms | 320 µs | 7 runs | 100
taichiの使い方① ~mp4とgifで出力~
## 経緯
[taichi](https://github.com/taichi-dev/taichi)に昨日からハマっているので、色々使ってみつつ、適宜情報を共有していこうと思います。今回は、作成したグラフィックをmp4またはgifとして出力するやり方を紹介します。詳しくは公式の[ドキュメント](https://taichi.readthedocs.io/en/stable/export_results.html#export-images)をご覧ください。taichiについての初めての記事は[こちら](https://qiita.com/Hiroaki-K4/items/e8cdb8c4e79c0d1a6670)です。## ffmpegのインストール
動画を出力する際にtaichiはffmpegを使用するので、インストールしていない場合はインストールしてください。“`
$ sudo apt update
$ sudo apt -y upgrade
$ sudo apt install ffmpeg
“`## スクリプト
今回は試しにリポジトリのexamplesの中に
タコヤキオイシクナールをセグメントツリーへの乗せる際の考え方
タコヤキオイシクナールはセグメントツリーの応用の典型例として有名です。今回はこの問題を解いていきます。
対象読者は、セグメントツリーのMaxやSumの実装を理解しており、タコヤキオイシクナールをどのように乗せればよいのか?と悩んでいる人を対象とします。# 概要
まず、満点解法を考慮せずに考えます。– n 個の箱があり、それぞれの箱$a_i (0 \leq i < n)$にはa,b の変数が書かれている。すべての箱は1,0のパラメータを持つ。 - 各箱はxという値が入力されると $ ax + b $を出力する。 - 今、1という数字を$a_0$にいれる。$a_i$に入力された値の出力は$a_{i+1}$に渡され - すべての箱を通過した時の値は何か? # 例 2つの箱があり、それぞれパラメータが、$2,2$と$3,3$だったとします。 1つ目の箱の入力は1のため、$1 * 2 + 2$で5が出力されます。 2つ目の箱の入力は5のため、$5 * 2 + 3$で18が出力されます。 # 箱の合成 隣接する箱は合成することが可能です。今、1つ目の箱のパラメータをa,bとし、2つめの
【強化学習】KerasでApe-Xの解説・実装(失敗)
インターネットで調べて実装しているのでまだ理解し切れていない部分もあります。
虚偽・暴論等が記事内にありましたらご指摘願います。#はじめに
今回は、2018年の時点で2番目に優秀というApe-Xという強化学習アルゴリズムを実装してみました。#Ape-Xとは
Ape-Xは2018に発表された強化学習アルゴリズムで、R2D2に次いで2番目に優秀とされている強化学習アルゴリズムです
論文は[こちら](https://openreview.net/pdf?id=H1Dy—0Z)構造的には、
・Double Deep Q Network
・multi-step bootstrap target
・Dueling Network
・Prioritized Experience Replay
・分散学習
no
4つを組み合わせたアルゴリズムです。順番に説明していきます## Double Deep Q Network (DDQN)
DDQNについては[このサイト](https://qiita.com/sugulu_Ogawa_ISID/items/bc7c70e6658
[エラー]IOPub message rate exceeded. The notebook server will temporarily stop sending output to the client in order to avoid crashing it.
## エラー
IOPub message rate exceeded.
The notebook server will temporarily stop sending output
to the client in order to avoid crashing it.
To change this limit, set the config variable
`–NotebookApp.iopub_msg_rate_limit`.# 原因
iopun_data_rate_limit の値がとても小さく設定されているため。
# 解決策
設定されている値を変更する
jupyter notebook –NotebookApp.iopub_data_rate_limit=10000000000
# 追記
最新版では修正されている。
# 参考
https://github.com/jupyter/notebook/issues/2287
【備忘録】初めてのAzureFunctionsのデプロイ
# 1. はじめに
この記事では、AzureFunctionsでよく私が利用している`HttpTrigger`と`TimerTrigger`を
デプロイして動かすところまでを解説します。結構長くなったので、目次と簡単な内容を付与しておきます。
| 節 | 項 | タイトル | 内容 |
|:—:|:—:|:—|:—|
| 2 | – | 前準備 | – |
| | 1 | – ローカル環境 | AzureFunctionsをデプロイするのに必要なソフトのインストール |
| | 2 | – Azureのクラウド環境 | AzureFunctionsをデプロイするのに必要なサービスを事前に作成 |
| 3 | – | FunctionAppの作成 | コンソールからFunctionAppを作成 |
| 4 | – | AzureFunctionsの種類 | 利用可能なTriggerの種類 |
| 5 | – | AzureFunctionsの実装 | Pythonスクリプトの作成と修正 |
| | 1 | – requirements.txの修正 | –
【Python3】機械学習を使ってデータ分析をやってみよう!(回帰)
# 対象
– AIに興味がある人
– 興味があるけど何からすれば良いか分からない人
– AIで何ができるのか知りたい人# 前提
– Googleアカウントを持っている
– Google Driveの基本的な使い方を知っている
– Python3の基本的な使い方を知っている
– 機械学習の理論については扱わない機械学習の概要に関しては以下を参照
> [一から始める機械学習(機械学習概要) – Qiita](https://qiita.com/taki_tflare/items/42a40119d3d8e622edd2)# ゴール
– テーブルデータの目的の列の値をある程度の精度で予測できる
– データ分析に必要な専門用語が少し分かる
– データをグラフで表示できる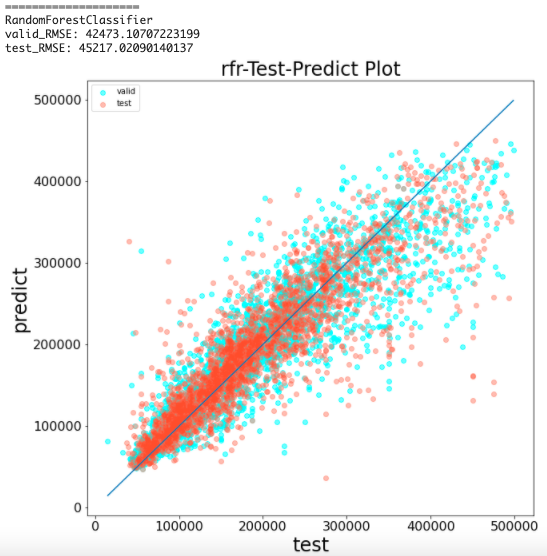
# 前知識
予測するデータの種類によって使うモデル
Githubトレンドリポジトリ①~面白そうなグラフィック系のリポジトリを発見したので試してみた~
## 経緯
前にgithubのトレンドリポジトリから情報を定期通知するという[記事](https://qiita.com/Hiroaki-K4/items/61b357fa69c90fd9bbfd)を書いたのですが、それを通じて、面白そうなリポジトリを発見したので共有します。今回は[taichi](https://github.com/taichi-dev/taichi)を紹介します。これシリーズ化しようかな(笑)。## taichiとは
**Taichi (太极) is a programming language designed for high-performance computer graphics.**
リポジトリの最初に上のように書かれているのですが、taichiがプログラミング言語なのかはわかりません。taichiはpythonで書かれたコンピュータグラフィックスのためのライブラリだと、勝手に解釈してます(笑)。違ったら教えてください。## 試してみた
導入はpipでtaichi入れるだけです。あと、gpu使うのでcudaもいります。“`bash
pi
複数のバージョンのCUDAを同一環境で扱う方法
大学の研究で機械学習をやっていて、同一環境で複数のバージョンのCUDAを扱うにはどうすればよいのか困ったことがあったのでそれについて書いていく。
# 前提
Windows10環境においてPyTorchをGPUで動かす。
PyTorchのバージョンによって必要なCUDAのバージョンが異なる。
これに伴って、複数のバージョンのCUDAをインストールした。# 対象者
PyTorchをGPUで動かしたことがあり、cuDNNやCUDAのインストール方法やパスの通し方は大体知っているが、複数のバージョンの扱い方がわからない方。# 方法
結論から言うと、ユーザーは何もしなくてよい。
パスさえ通っていれば、PyTorchのどのバージョンを動かすかによって必要なCUDAを自動で認識してくれる。`where nvcc`とコマンドプロンプトに入力した時に
“`
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin\nvcc.exe
C:\Program Files\NVIDIA GPU Computing Toolkit\
Pythonでtry/exceptと、ディクショナリの編集、取り出しの応用練習
#はじめに
英語は””を付けるのめんどいから使ってるので文法とか許してください。
python初心者なので色々許してください。
有識者の方へ、もっとなんとかなるとかあったら優しく教えて許してください。
許してください。#概要
・ディクショナリからキーを検索する。
・指定したキーが見つかった場合は値を出力、見つからなかった場合は「鍵は見つからなかった」と出力する。
・上記処理が終了したときに、続行するか、ディクショナリを編集するか、終了するかを選択する。#完成例
“`python
name_age = {“tanaka”:33,”satou”:23,”suzuki”:29}
def dict_info (dict_tbl,key):try:
print(key,”‘s”,dict_tbl[key],” years old.”)except LookupError:
print(“[Key is not found.]”)op = 0
while op !=1:
if op == 0:
key
Python の Flask Web API に JWT による認証を組み込む
## はじめに
Python で作成した Flask Web API に対して、JWT (JSON Web Token) 認証を組み込んでみました。
参考:[Python + Flask + MongoDB を利用した Web API の作成と Azure VM + Nginx への配置(ホロライブの動画配信予定を収集 その3)](https://qiita.com/kerobot/items/bd504b0d787de63c364e)## JWT (JSON Web Token) とは
JWT は JSON Web Token の略で、要求情報(Claim)を JSON オブジェクトとしてやりとりするトークンの仕様です。
仕様は RFC7519 で定められており、二者間の通信時の認証(Authorization)に利用されます。今回は、Web API へのリクエストで指定されたユーザー名とパスワードを元に、JWT トークンを生成してレスポンスとして返し、その JWT トークンを用いて、Web API の機能を利用できるようにしてみました。
## 環境
* ローカル環境
Ubuntu 20.04 で pyenv を使用して Python を導入する
本記事では、Ubuntu 20.04 上に [pyenv](https://github.com/pyenv/pyenv) を使用して Python を導入する手順をまとめます。
# 注意
– そもそも pyenv が必要なのか確認しましょう。pyenv で期待通りに動作する Python を導入するのは簡単ではありません。(私は 1 時間くらいネットをさまよいました。)
– ただ Python が欲しいだけの方は、環境構築で苦労したくなければ OS 標準のパッケージ(Ubuntu なら `sudo apt install python3-pip`)や [Anaconda](https://www.anaconda.com/) などに頼ることをおススメします。
– 個人的に、pyenv は環境構築で困ったときにネットで対応策を探す面倒を受け入れられる人でないと使えないと思っています。正しく導入できれば便利なんですけどね…。
– 下記の手順の一部は、Ubuntu 20.04 に依存しています。Ubuntu 18.04 にすら対応していません。
– 一応、該当箇所には Ub
PyMySQLでBulk Updateをする方法と注意点【Python】
# 結論
* INSERT … ON DUPLICATE KEY UPDATE 構文の場合はexecutemanyを使う。
* ELT&FIELDでのUpdateをする場合はプリペアドステートメントでパラメータをセットする。# INSERT … ON DUPLICATE KEY UPDATE 構文
`VALUES`などの一度にデータを挿入するクエリでは`executemany`メソッドを使うことができます。
“`python
conn = pymysql.connect(
mysql_endpoint,
user=username,
passwd=password,
db=dbname
)def bulk_insert_and_update_users():
prepared_statement = [
[
1, # id
‘Qiita太郎’, # name
20 # age
],
[
「python で作る対話システム」の天気予報ボットを参考に公式ラインに天気予報させてみた。
#pythonで作る対話システムに書かれた内容と変えた点
・XMLではなくSQLite3を使って状態遷移をさせた#ポイント
・本のコードをそのまま公式ラインに使用しようとすると遷移情報の保持が出来なかったため、SQLite3を使用した。#次に目指すもの
「大阪じゃなくて」のように入力を取り消すことが出来るようにする。
pythonで作る対話システムの非タスク編へ#プログラムの構造
#下記:天気予報公式ラインのコード
“`python:weather_system.py
import sys
from PySide2 import QtCore, QtScxml
import requests
import json
from dat
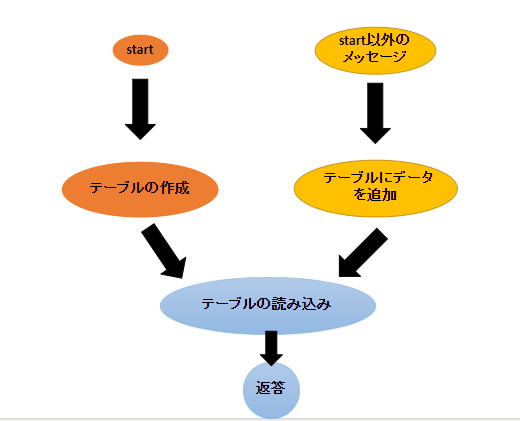
Python3 と venv と Ansible
# はじめに
Python2 系のサポートが終了してそろそろ1年ですね。
常日頃使っているサーバでは、まだ2系で問題なくスクリプトが動いているわけですが・・・
そろそろ3系も使えるようにならねばと、一念発起し今回調べた内容を簡単にまとめてみました。
タイトルの通り複数環境用に “`venv“` と 、インフラ環境構築用で使う “`Ansible“` を例にとって説明します。# 環境構成
VirtualBox 上に CentOS 7 を起動して試行します。**ホストマシン**
– Windows 10 Pro (20H2)
– VirtualBox:6.1.16
– Vagrant:2.2.14**ゲストマシン**
– CentOS:7.8.2003
# VM 起動
以下 “`Vagrantfile“` で起動します。
“`vagrant up“` !
※CPU や Memory の設定はお好みで“`ruby:Vagrantfile
# -*- mode: ruby -*-
# vi: set ft=ruby :Vagrant.configur
kaggle の Courses を読む —Intermediate Machine Learning 5
# twitter 始めました
こんにちは! まはらせないきと申します!
突然ですが、ついに [twitter](https://twitter.com/MaharaseNaiki) 始めました!
あまり有益なことは発信できませんが、先輩方の知見や経験を得られたらと思っています!それでは今回もよろしくお願いします!
___
__Intermediate Machine Learning__ では、機械学習をより深掘っていきます~Intermediate Machine Learning の流れ~
1. 導入
2. 欠損値
3. カテゴリー変数
4. パイプライン
5. 交差検証
6. XGBoost
7. データの漏洩今回は __6__ の内容です!
# eXtreme Gradient Boosting
Gradient Boosting は、__勾配ブースティング__ と翻訳されています。この勾配ブースティングにさらなる精度と速さを実装したものが、__XGBoost__ です。Scikit-learn には別の勾配ブースティングの手法もありますが、XGBoost の
Pythonを使って複数画像をPDFに変換する
この記事は、Pythonを使って複数の画像を一つのPDFにまとめたいと考えているユーザーに向けたものです。
以前の公開コードをPython3で試したら動作しなくなっていたので、Python3ユーザー向けに更新しています。
## 前提
macOS Catalina (10.15.6)
python 3.7.5## 事前準備
img2pdfをインストールします。
https://pypi.org/project/img2pdf/“`py
pip3 install img2pdf
“`
インストールに成功したことを確認“`
Installing collected packages: Pillow, img2pdf
Running setup.py install for img2pdf … done
Successfully installed Pillow-7.2.0 img2pdf-0.4.0
“`## 画像をPDFに変換する
以下のスクリプトを記述します。ここではファイル名を convert2pdf.py とします。
“`py:convert
【Python】Excelの複数シートを1つにまとめる
Excel for Macでは、ピボットテーブルを作成する際に複数テーブルを一括指定できないため結構不便です。(古いバージョンではできていたはず…)
まずは、pythonで複数シートのデータを1つシートにまとめてデータを扱いやすくしていきます。#使用ライブラリ
openpyxlを使用します。
Excelの読み書きなどの操作を行うためのライブラリです。
https://openpyxl.readthedocs.io/en/stable/#事前準備
openpyxlのインストール“`
pip install openpyxl
“`#ファイルの読み込み
“`python
#ファイルの読み込み
read_path = “./input.xlsx”
output_path = “./output.xlsx”
wb = load_workbook(read_path)“`
#全シートのデータを取得する
“`python
#全シートのデータを取得する
sheet_names = wb.get_sheet_names()
first_row = 1
l_2d_outpu




