
- 1. DS18B20温度センサーをラズパイで使ってみた
- 2. 新回生の方に向けて(その1)
- 3. ライブラリにある関数を拡張してみる試行 (pathlibの操作方法を拡張してみる)
- 4. ONNXに埋め込むopsetを設定する
- 5. 「全力回避フラグちゃん!」チャンネルの動画をグラフ化するとどうなるのか?【Python】【グラフ化】
- 6. Kaggle / MNIST をサポートベクターマシンで頑張る
- 7. 【Python】pipでエラーが出た場合の対処(pyinstaller、pyautoguiなど)
- 8. PythonのpeeweeのModel.get_or_create()の挙動について
- 9. 文字列操作でありますまいか
- 10. 【Python】GigaCode 2019 D – 家の建設(numpyで行列のまま操作!!!)【AtCoder】
- 11. TensorFlow 2.x での多変量LSTMとデータの前処理
- 12. Python パッケージ(ライブラリ)のpipコマンドを使ったインストール方法 Mac環境
- 13. LeetCodeに毎日挑戦してみた 160. Intersection of Two Linked Lists(Python、Go)
- 14. アニガサキキャラクター出番時間の統計的解釈
- 15. Pythonによる単回帰分析入門(数値計算/数式処理系の6ライブラリの比較)
- 16. Twitter、Google、メールでのログインを実装しよう。
- 17. AbstractBaseUser を継承したカスタムユーザーで E-mail ログインを実現する
- 18. ClearML入門〜機械学習の実験管理を楽にする〜
- 19. pipenv環境作成時に「ValueError: Not a valid python path」が出てハマった
- 20. Pythonで学ぶアルゴリズム 第11弾:木構造
DS18B20温度センサーをラズパイで使ってみた
#本記事のサマリー
Raspberry Pi3B+にDB18B20センサを接続し、Pythonスクリプトで温度を取得した後、crontabで定期的に温度を取得した。
#DB18B20センサとは
DB18B20センサは安価でアナログコンバータをセンサとラズパイの間に介さずに、温度を取得できるセンサー。情報量的に、価格的に空気中の温度(もしくは湿度も)図るのならdht11センサか、この上位互換のdht22センサのほうがオヌヌメといえる。
ただ、DB18B20の最大のメリットは防水タイプが販売されており、水温等図れることにある。ちなみに、筆者はHiLetgo社という中華製?、5つで1000円程度のものをAmazonで購入した。
#環境
devices: Raspberry Pi3B+
OS: Rasbian NOOBS_ver_3_5_1
言語:Python 3系
#回路
回路に関しては、下記のURLを参考にした。
http://aba.doorblog.jp/archives/55110922.html
回路を載せてくれてありがとうございます。
といっても、プルダウン抵抗を介するだけです。
新回生の方に向けて(その1)
# Python始めたての頃から今にかけて学んだこと
## 初めに(著者の現在)
私は今大学院1年の前期課程にて深層学習の研究を行っている者です。研究ではCT画像データやその加工データであるPLYデータなどを用いて特徴量を算出し、畳み込みニューラルネットワークで学習して最終的に骨表面においての骨折の自動診断を目指し、日々猪突猛進しております。ファースト著書の論文がありますのでご興味があれば読んでいただければと思います。(論文に関するコメントも何かあればお願いします(´;ω;`))
https://ieeexplore.ieee.org/abstract/document/9231453
## 書くに至った動機
なぜこの記事を書こうと思ったのかをここで述べておくと、Pythonを使い始め2年が経とうとする中新たな新入生が入ってきた時のためにこの記事を参考にPythonを使用するに当たって暗黙知的な部分を参考にしてもらおうかなと思い立っためです。(本当は現在実行中のプログラムの待ち時間がかなり長そうに感じたため)
## 筆者のおすすめPythonツール
まず、みなさんがPythonを
ライブラリにある関数を拡張してみる試行 (pathlibの操作方法を拡張してみる)
ライブラリにある関数を拡張します。拡張は、Pythonのクラスに、関数を登録するような形。(クラス下の変数に代入する形、毎回そのクラスから生成されるインスタンスは同じ関数を持つようになる)
以下、例として、pathlibの操作方法を拡張したコード。本来はないファイルコピー・フォルダツリーコピーの関数等を拡張追加します。
拡張試行項目:
* **拡張1** : 本来はないファイルサイズ取得のsize関数を拡張追加
* pathlib.Path(“…ファイル…”).**size()**
* **拡張2** : 本来はないフォルダコピーのcopy関数を拡張追加
* pathlib.Path(“…フォルダ…”).**copy(“./test2”)**
* **拡張3** : 本来はないフォルダ削除のunlink関数を拡張追加
* pathlib.Path(“…フォルダ…”).**unlink()**
* **拡張4** : 本来はないファイルコピーのcopy関数を拡張追加
* pathlib.Path(“…ファイル…”).**copy(“.
ONNXに埋め込むopsetを設定する
## ONNXのopsetとは
ONNXファイルには、ファイル作成時のバージョンとしてopsetを指定する機能があります。opsetの値に応じて、使用できるオペレータやその機能(オペレータのプロパティ)が変わります。特に指定が無い場合は最新のopsetとして扱います。Deep Learning系のツールによってはONNXファイルのopsetの値を確認し、自分自身が処理できるかどうかを確認するルーチンが含まれています。そこの確認ルーチンではじかれた場合は、opsetを下げて再度ONNXファイルを作る必要があります。
https://github.com/onnx/onnx/blob/master/docs/Operators.md
ここを見るとそれぞれのオペレータが対応しているバージョンを確認出来ます。例えば、ABSではバージョンとして1,6,13が存在し、13ではABSで使える型としてbfloat16が追加されていることが分かります。
## Kerasでopsetを指定してONNXファイルを作る
opsetの指定方法はコンバーターによって違いますが、大抵は引数にopset
「全力回避フラグちゃん!」チャンネルの動画をグラフ化するとどうなるのか?【Python】【グラフ化】
# はじめに
YouTube が大好きで,その中でも日常的に良く視聴しているチャンネルのことをもっとよく知りたくなったため,今回のようなデータを自分で収集し,グラフ化することで状況を見やすくするということをしたくなったのが本記事作成のモチベーションです.
今回は”全力回避フラグちゃん!” という株式会社Plott 様が運営しているYouTube のあるチャンネルに公開されている動画から再生数や動画の公開日,登場キャラや話の終わり方の情報を収集してグラフ化することで全体像を見えるようにしました.
運営会社様やチャンネル及びキャラクターについて詳しく知りたい方は,本記事の末尾の関連リンクをご参照ください.それ以上のことは特にありません.フラグちゃんは,他のPlott 様のチャンネルとは異なり,話の内容によって出現する主要キャラがバラバラな感じ※がしたので,再生回数となんか関係あるのかなーと思いグラフ化してみたというだけのお話です.
※ フラグちゃんでさえでない回が少ないですが存在します.モブ男は皆勤賞です.## 注意事項
本記事で実施していることは動画から得られる
Kaggle / MNIST をサポートベクターマシンで頑張る
# Kaggle / MNIST をサポートベクターマシンで頑張る
## はじめに
[Kaggle / MNIST](https://www.kaggle.com/c/digit-recognizer) は, 28×28 の手書き数字の画像を学習するミッションである. 画像データの学習というと畳み込みニューラルネットワーク (Convolutional Neural Network, CNN) に手を出したくなるが, ここではあえてサポートベクターマシンでどこまで精度を上げられるかトライした.精度的には (私の機械学習の実力では) CNN に劣るが, ネットで調べても Kaggle / MNIST をサポートベクターマシンでトライした事例があまり無かったので, 「これくらいの精度が出るよ」という記録として残しておく. 結果的には, ***正答率は 0.98375*** となった.
精度を上げるためにやってみたことは, 以下の 3 つである. これらについて説明する.
1. 特徴量を増やす
2. 役に立たない (と思われる) 特徴量を減らす
2. ハイパーパラメタを調整する#
【Python】pipでエラーが出た場合の対処(pyinstaller、pyautoguiなど)
#概要
久々に仮想環境作ってpipコマンドでpyinstallerをインストールしようとしたらエラーが出た。
多分、過去にpyautoguiで発生したエラーと同原因のもの。
↑ [【Python】pyautogui(PyMsgBox)インストールエラーに対する暫定対策](https://qiita.com/hisakichi95/items/41002333efa8f6371d40)
**「wheel」をインストールしたら解決した**のでメモ。#エラー内容
pipでpyinstallerをインストールすると、下記のようなエラー内容を吐いてインストールに失敗する。“`
(pyautogui_pillow) PS C:\Users\aaa\Desktop\python\10_右クリックツール> pip install pyinstaller
Collecting pyinstaller
Using cached pyinstaller-4.1.tar.gz (3.5 MB)
Installing build dependencies … done
PythonのpeeweeのModel.get_or_create()の挙動について
# はじめに
Pythonの[peewee](http://docs.peewee-orm.com/en/latest/)というORMを使っていて、すでにレコードが存在する場合は無視、レコードが存在しない場合だけINSERTするために[Model.get_or_create()](http://docs.peewee-orm.com/en/latest/peewee/querying.html#create-or-get)というメソッドを使ったところ、少しつまづいたのでメモを残しておきます。
マニュアルをちゃんと読めば書いてあったんですけどね。
## 動作を確認した環境
* Pyton 3.7
* peewee 3.14.0# やろうとしたこと
device_idとpageの複合ユニークキーを持つテーブルを作って、
レコードが存在しない場合はINSERT、
レコードが存在する場合は無視するようにしたかった。そのためにget_or_create()というメソッドを使った。
`Table.get_or_create(device_id=1, page=1, data=”
文字列操作でありますまいか
調べていたら雑多なメモになってしまった。色々な文字列分割。
1. キャメルケースとかスネークケースとか
2. 日本の姓名分割
3. 日本の住所分割
4. 中国の etc..という雑文です。
## [キャメルケースとスネークケースの文字列変換](https://kagamihoge.hatenablog.com/entry/2017/01/03/225054)
使い方はURL参照。https://kagamihoge.hatenablog.com/entry/2017/01/03/225054
速度計測とか、コーディング内容比較してみようかと思ったのだが、[CamelCase と snake_case を相互変換する](https://qiita.com/toastkidjp/items/3c8f21da085ecaace7c3#%E8%BF%BD%E8%A8%98-jmh-%E3%81%A7%E3%81%AE%E3%83%91%E3%83%95%E3%82%A9%E3%83%BC%E3%83%9E%E3%83%B3%E3%82%B9%E3%83%81%E3%82%A7%E3%
【Python】GigaCode 2019 D – 家の建設(numpyで行列のまま操作!!!)【AtCoder】
2次元累積和の問題。
ただし2次元累積和については理解していても、**numpyで行列のまま操作できないとTLEになる。。。**
**何が起こっているのだろうか、じっくり眺めて理解すること**がこの記事の目的。
**この問題が完璧に理解できたら、numpyのハードルもずっと下がるはず・・・**>**※pypyは邪道!python(numpy)で解きたい!**
#[GigaCode 2019 D – 家の建設]( https://atcoder.jp/contests/gigacode-2019/tasks/gigacode_2019_d)
とりあえず、先にACコードから
“`python:AC.py
import numpy as np,sys
def LI(): return list(map(int,sys.stdin.readline().rstrip().split()))H,W,K,V = LI()
A = np.array([LI() for _ in range(H)])+K
map = np.zeros((H+1,W+1),np.int64)
map[
TensorFlow 2.x での多変量LSTMとデータの前処理
# はじめに
TensorFlow 2.x での時系列データに対する多変量LSTMを実装する際の解説記事があまり見つからなかったので書きます。
この記事は以下のような人にオススメです。* TensorFlowで時系列データに対する(多変量)LSTMを実装したい人
* LSTMに入力するデータの形式と前処理を知りたい人用いるコードとデータは[GitHubのレポジトリ](https://github.com/ishikawa08/tf_multi_LSTM)上に公開してあります。コードはJupyter Notebook形式で、Colab上でもすぐに動かせるようになっているため参考にして下さい(良かったらスターもお願いします)。
# 今回取り組むタスク
今回は、気温などの気象データから、東京の**「平均雲量の予測」**を行ってみようと思います。# データ
今回は予測に用いるデータとして[気象庁のHP](https://www.data.jma.go.jp/gmd/risk/obsdl/index.php#)から過去10年分の東京の7日間の**「平均気温、平均相対湿度、合計日照
Python パッケージ(ライブラリ)のpipコマンドを使ったインストール方法 Mac環境
こんにちは、かをるです。
今回は、GUIツールである【PyCharm】をつかってPythonの環境構築を行なっていきます。
PyCharmとは、Pythonの統合開発環境です。
コマンドラインによる環境開発よりもこういったツールを使いこなすことで、より効率的に開発を進めることができます。
有償と無償とありますが、今回は無償のインストール方法を紹介していきます。
ブログに投稿しました。
https://kaworublog.com/pycharm-python/
LeetCodeに毎日挑戦してみた 160. Intersection of Two Linked Lists(Python、Go)
#### Leetcodeとは
[leetcode.com](https://leetcode.com/)
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。
#### 36問目(問題160)
#### 160. Intersection of Two Linked Lists
#### 問題内容
> Write a program to find the node at which the intersection of two singly linked lists begins.
>
> For example, the following two linked lists:
>
> [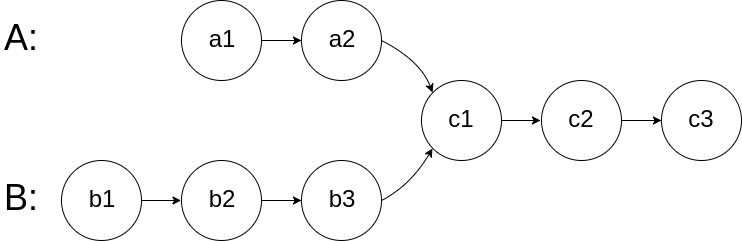](https:/
アニガサキキャラクター出番時間の統計的解釈
# 背景
先週虹ヶ咲学園スクールアイドル同好会TVアニメ**1期**が終了し,他のヲタクの感想や発見をTwitterやスレで拝見していたが,ラブライブ板のとあるスレで面白いレスを発見した.> 122名無しで叶える物語(たこやき)2020/12/28(月) 02:09:09.16ID:s1PSbHRM
\>>1のデータを参考に秒数変換してカンマ区切りcsvしてみた
ほかの人も分析にどうぞ[[1] 虹ヶ咲アニメの出番にどれくらい偏りがあるのか調べてみた](https://fate.5ch.net/test/read.cgi/lovelive/1609086530/122)
なんとアニメ作中において各キャラクターの会話時間を集計してCSV形式で投稿してくれている猛者があらわれた.情報科学工学界隈の人間はCSV形式で投稿されたデータ列を見ると解析したくなる病気なので,例によってデータをPythonで処理してみた.メモ書き程度に残すものなので,解説はほぼなされていない.(気が向いたらそれぞれの解析手法の原理や特徴をまとめるかもしれない)
# 解析内容
ソースを見れば自明.# 実装
Pythonによる単回帰分析入門(数値計算/数式処理系の6ライブラリの比較)
# 概要
Pythonで**単回帰分析をしたいとき**、つまり、**回帰直線を求めたいとき**、それを簡単に叶えてくれるライブラリが複数用意されています。ここでは「numpy」「scipy」「scikit-learn」「statsmodels」「sympy」「tensorflow」の6つライブラリを使って回帰直線($y=ax+b$ のパラメータ $a$ と $b$)を求めるための方法/コードについて比較・整理をしました。
また、おまけとしてデータ可視化ライブラリ「seaborn」で自動描画される回帰直線から強引に回帰式パラメータを求める方法についても記載しました。
コードの動作確認は、GoogleColab.(Python 3.6.9)により行なっています。
# 準備
各種ライブラリをインポートをします。そして、一次関数 $8x+10$ に対して、正規分布 $N(0,6^2)$ に従う乱数 $\varepsilon$ を加えた $y=8x+10+\varepsilon$ からサンプルデータ($8$個のセット)を生成します。
“`py:データの準備
import numpy
Twitter、Google、メールでのログインを実装しよう。
これらの技術を使えば、簡単に実装できます。
## 自前で実装(Twitter,Google)
PHPでTwitterログインを実装しよう
https://dotinstall.com/lessons/tw_connect_php_v3#!lessonsGoogleでログインするWebサービスを作ろう
https://dotinstall.com/lessons/google_connect_php_v2## BaaS/MBaaS環境を使う。
Firebase
https://firebase.google.com/?hl=ja## Ruby on Railsを使う
【Rails】ログイン機能を実装する
https://qiita.com/d0ne1s/items/7c4d2be3f53e34a9dec7## シンプルなPHPでのログイン実装
phpで作る簡素なログイン機能
https://qiita.com/qwertyuiopngsdfg/items/597da67387723a5aedadPHP5.6でログイン機能を実装しよう
https://doti
AbstractBaseUser を継承したカスタムユーザーで E-mail ログインを実現する
# 動作環境とこれまでの経緯
– ホスト環境
– macOS Catalina 10.15.7
– VirtualBox 6.1.14
– ゲスト環境
– Ubuntu Server 20.04.1 LTS
– Docker 19.03.13
– Docker Compose 1.27.3
– Django
– Django 3.1.4
– uwsgi 2.0.18
– mysqlclient 1.4.6
– これまでの経緯
– [ローカルに Ubuntu Server を用意した](https://qiita.com/hajime-f/items/5d3373e98985776b4240)
– [そこに Docker Compose をインストールした](https://qiita.com/hajime-f/items/2bd1cad93d3ae4a62be8)
– [Django+MySQL+nginx の開発環境を Docker Compose で構築した](https://qiita.co
ClearML入門〜機械学習の実験管理を楽にする〜
# はじめに
機械学習では、モデルの学習に使用するコードだけでなくデータセット、前処理で生成された生成物、モデルなどもセットで管理する必要があり実験管理が難しいという問題があります。適切な実験管理は、実験段階で動いていたコードを本番環境に持っていき同様の予測結果を再現するのにも重要になります。
機械学習の実験管理では[MLflow](https://github.com/mlflow/mlflow)などが有名ですが、ClearML(前の名前: Allegro Trains)という実験管理ツールを見つけたので、この記事ではClearMLの簡単に使い方について説明させていただきます。
ClearML: https://github.com/allegroai/clearml (Apache-2.0 License)
公式ドキュメント: https://allegro.ai/clearml/docs/index.html#実験管理の考え方については、以下の記事も非常に参考になります。
[実験管理について考える Re:ゼロから始めるML生活](https://www.nogawano
pipenv環境作成時に「ValueError: Not a valid python path」が出てハマった
仮想環境にcondaを使っていたが、これからはpipenvにしようと
Anacondaを消して移行しようとしたときにハマった。対象のエラーメッセージ
“`
ValueError: Not a valid python path: ‘C:/Users/<ユーザー名>/Anaconda3/python.exe’
“`## 原因
Anacondaのレジストリ―キーを消し切れていなかったため、
`pipenv`が参照しようとして`ValueError`を返していた。## 前提条件
– Windows 10 Home
– Python 3.7
– pipenv 2020.11.15## 解決法
解決法がきれいな順に3つ載せます。### その1
https://github.com/pypa/pipenv/issues/4334 より、
Anacondaを参照しないようにレジストリ―キーを削除する。1. 「Win + R」に「regedit」と入力。
2. `コンピューター\HKEY_CURRENT_USER\Software\Python\Continuum
Pythonで学ぶアルゴリズム 第11弾:木構造
# #Pythonで学ぶアルゴリズム< 木構造 >
##はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第11弾として木構造を扱う.##木構造
#####幅優先探索
・階層ごとに見ていくような感じ
・何か1つだけ合致するものを見つける場合に**高速に処理**できる
・探索途中のノードをすべて保持 ⇒ メモリを大きく消費してしまう
#####深さ優先探索
・限界まで進んで,また戻ってくる方法(**バックトラック**ともいう)
・すべての(ある程度の深さまでの)答えを見つけるときによく使われる
・再帰処理を使うことが多い
・3種の異なるルートがある(行きがけ・帰りがけ・通りがけ)##木構造の処理ルート
####幅優先探索
おおまかなイメージ図を次に示す.

実際に処理順を各ノードに記したものを次に示す.




