
- 1. 【Python】Beautiful Soup 4+requestsでインデントされたHTMLを取得する(備忘録)
- 2. OpenCVによるコントラストと明るさの調整
- 3. conda環境にインストールしたパッケージのライセンスの種類を調べる方法
- 4. SDFを分割するスクリプトを作ってみた
- 5. Python+SeleniumでGet Wild退勤打刻する
- 6. yukicoder contest 287 参戦記
- 7. RGB / BGR classification はできるのか
- 8. nfcpyでFeliCa Lite-Sの内部認証を実装する
- 9. pandas と matplot で期間をレンジにしたグラフを描きたい。
- 10. 【Python】requestsでcookie情報を取得する(備忘録)
- 11. pyenvとvenvの必要最小限の利用方法
- 12. OpenCV+Pillowで動画上に秒単位で変化する日本語テキストを表示する
- 13. Pythonでコメント付きのJSONファイル(JSONC)を読み込む
- 14. snow加工を剥がしたかった with 機械学習
- 15. 二項分布で最尤推定/MAP推定/ベイズ推定をする
- 16. ディレクトリの中身を表示(Python)
- 17. VSCodeからAnaconda Powershell Promptを利用する
- 18. Metabase APIで変数付きのリクエストを投げる
- 19. Python:PythonでVlookup的な事をやってみた#3
- 20. IPython Notebookを簡単に共有する方法
【Python】Beautiful Soup 4+requestsでインデントされたHTMLを取得する(備忘録)
自分用メモ
# Beautiful Soup 4とrequestsのインストール
“`
pip install beautifulsoup4
pip install requests
“`# Beautiful Soup 4とrequestsのインポート
“`python
from bs4 import BeautifulSoup
import requests
“`# URLからrequestsのresponseを取得
変数「url」にリクエスト対象のURLを指定
※この段階ではインデントされていないHTML“`python
url = “https://qiita.com”
response = requests.get(url)
print(response.text)
“`# BeautifulSoupでHTMLをインデントして取得
prettify()がHTMLをインデントして取得する関数“`python
soup = BeautifulSoup(response.text, ‘html.parser’)
print(soup.pretti
OpenCVによるコントラストと明るさの調整
#はじめに
GIMPなどに明るさ・コントラストを調整する画面があります。
こんな機能を明るさ・コントラストをOpenCVとPythonで実装してみたいと思います。
GIMPは、明るさ・コントラストを0~127段階で調整できますが、この調整項の段階に
ついては同様にはいたしません。**GIMP操作風景**
#処理方法
今回の入力画像としては、今年鉄道が運休するほど大雪が降った日の写真です。
朝なので暗いです。この暗い感じを何とかしたいと思います。
まずはヒストグラムで現状確
conda環境にインストールしたパッケージのライセンスの種類を調べる方法
#はじめに
インストール済の conda パッケージのライセンスを調べる機会があり方法を調べてみたのでメモ。厳密にライセンス条文を表示する方法ではなく、どんなライセンスの種類かを調べる方法である。
#pip でインストールしたもの
pipでインストールしたものについては、以下のように“`pip show“`コマンドで調べることができる。“`sh
$ pip show torch
Name: torch
Version: 1.7.0
Summary: Tensors and Dynamic neural networks in Python with strong GPU acceleration
Home-page: https://pytorch.org/
Author: PyTorch Team
Author-email: packages@pytorch.org
License: BSD-3
Location: c:\users\kimisyo\.conda\envs\openchem\lib\site-packages
Requires: future, typ
SDFを分割するスクリプトを作ってみた
#はじめに
SDFの解析でエラーになった際に、どのデータがおかしいのか解析したいときがある。そういった場合、SDFを適当に切り出してみて、トライアンドエラーをすることが、ごくまれに(数年に1回)ある。今回、そのタイミングが来たのでツールを作って残すこととした。#仕様
– 何番目から何番目を取得するかをstartとendを指定すると、その間にあるデータを切り出し、別のsdfとして出力する。
– startを省略した場合は1, endを省略した場合は、sdfの一番最後を指定したものとする。
– デバッグ目的で使用することが多いため、RDKitなどインストールが面倒なツールは使わない。#できたソース
こんな感じ。使い方はソースを見れば一目瞭然なので省略。“`sdf_cutter.py
import argparsedef main():
parser = argparse.ArgumentParser()
parser.add_argument(“-input”, type=str, required=True)
parser.add_argume
Python+SeleniumでGet Wild退勤打刻する
PythonでSeleniumを覚えたので使ってみたかった。環境は以下。
– Microsoft Windows 10 Pro
– Python 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)]## 動機
Get Wild退勤。
[ネットで話題の「Get Wild退勤」とは? SNS大盛り上がり「あー分かります!」「今度してみますw」「出勤時はセルフコントロール」](https://www.iza.ne.jp/kiji/life/news/200911/lif20091116010028-n1.html) 元ネタは以下らしい。友達から退勤する時にドアを開けると同時にGet Wildを聴く「Get Wild退勤」を教えてもらって試したらマジでめちゃくちゃ良い仕事した気持ちになるし何なら後ろの建物(会社)が爆破してる脳内妄想が起こってオススメ。
&mda
yukicoder contest 287 参戦記
# yukicoder contest 287 参戦記
起きたら始まっていて、A問題を解いて、B問題をちょっと考えたら眠くなってまた寝てた. コンテスト後に起きてB問題を解いてみたらそこまでは難しくなかった.
## [A 1432 Not Xor](https://yukicoder.me/problems/no/1432)
yukicoder では珍しい ABC-A レベルの問題. 使っている言語のビット演算子を知っていれば難なく解けるでしょう.
“`python
A, B = map(int, input().split())print((A | B) + (A & B))
“`## [B 1433 Two color sequence](https://yukicoder.me/problems/no/1433)
連続部分列の右端を固定して考えると、そこを右端とした部分列で最大のものは、先頭から始まる部分列で最小を引いたもの(プラスの値で絶対値の最大狙い)か、最大を引いたもの(マイナスの値で絶対値の最大狙い). なのでそこまでの最小値、最大値、合計の変数を更
RGB / BGR classification はできるのか
## これはなに
入力された画像がRGB-orderかBGR-orderかを判定するモデルを作った話です。ただの悪ノリです。
自然画像であれば見分けがつくでしょうが、例えばただの真っ赤な画像があったとき、元が赤か青かなんて50%でしか当たらないので解けません。でもAIは最強なのでなんとかしてくれると信じて学習させます。実行例↓
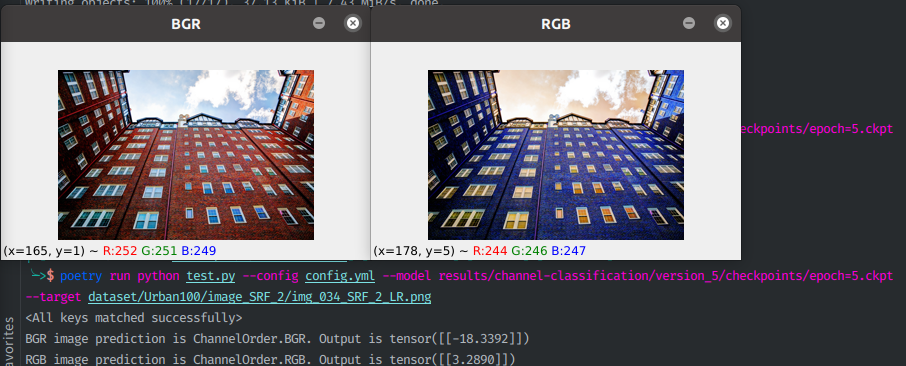## なぜつくったか
Pythonで画像処理をする際に、OpenCVやPillowを使用して画像を読み込むケースは多いかと思います。
特に何もせずOpenCVでRGB画像を読み込むと画像のチャンネルはBGR-orderになり、Pillowで読み込むとRGB-orderになります。そのため、OpenCVを使用して学習したモデルをPillowを使ったコードに適用すると思った性能を発揮しなかったり、前処理としてデータセットの
nfcpyでFeliCa Lite-Sの内部認証を実装する
FeliCaで電子錠、してますか?実装方法によってはそれ、危険かもしれません
# この記事を書こうと思ったきっかけ
FeliCaで家の鍵を解除するようなプログラムを書いている人の中でIDmを使って認証をしている人がいますが、それは非常に危険です。
IDmはPollingというコマンドで簡単に入手することができるし、IDmは簡単に偽造することができます。
(IDmが簡単に取得できるからこそIDmでこういうことをやっている人が多いとも言える)
IDmはユニークなIDなのでICカードの特定に使うことはできますが、認証に使うことはできません。
そこで使われるのが内部認証というものなのですが、Googleで調べてもIDm取得して終わり!!!というものばかりでほとんど情報が出てこなかったので今回自分で書きました。
この記事のわからないところがあればコメント欄か[私のTwitter](https://twitter.com/jun50_python)(かDiscord)で聞いてください。# 実装
## 必要なもの
FeliCa Lite-Sカード
NFCカードリーダー/ライター
Pytho
pandas と matplot で期間をレンジにしたグラフを描きたい。
COVID-19の厚生労働省の公開データ(厚生省のが2020/2/14からの集計)を使ってグラフを描こうとしたところ NHK 発表データ(NHKのが2020/1/16からの集計)と重ね合わせたいと思った。
この記事で必要になるものは、厚労省のオープンデータと、NHKの発表するオープンデータみたいなもの(ダウンロードしてから使用)です。厚労省のオープンデータのダウンロード先はこの記事の文中のコードブロックの中と、文中にあります。
###NHKのオープンデータみたいなもの
https://www3.nhk.or.jp/news/special/coronavirus/data-all/?fbclid=IwAR2UQ36PYoP2Kqwv88b-NERAN8PvG9uLUuWEY9VlspBqYZeKI4XJ3fjSpJw全くグラフの描き方は知らないが、できた。

自分用メモ
# requestsのインストール
“`
pip install requests
“`# requestsのインポート
“`python
import requests
“`# requestsのオブジェクト作成
変数「url」にリクエスト対象のURLを指定“`python
url = “https://qiita.com”
session = requests.session()
response = session.get(url)
“`# cookieを取得
cookie情報すべてを取得
※Webスクレイピングする場合は大抵これが必要“`python
cookie = response.cookies
“`# cookieの任意項目を取得
cookie内の任意項目を指定して取得
※Webスクレイピングでcookie内にトークンがある場合などで必要“`python
item = response.cookies.get(‘_qiita_login_session’)
“`# requestsでcookie情報を取得
pyenvとvenvの必要最小限の利用方法
# はじめに
Python+Djangoで開発をしているのですが、複数案件を担当していると案件によってPythonやDjangoやその他のライブラリのバージョンが異なります。
場合によっては、同じPythonのバージョンでも異なるライブラリのバージョンが異なるため、pyenvとvenvによるバージョン管理は非常に役に立ちっています。今回は必要最小限の機能に絞って利用方法を記載してみます。# 実行環境
OS:macOS Big Sur(version 11.2.2)
シェル:zsh
or
OS:CentOS7
シェル:bash# pyenv
pyenvを利用することで様々なバージョンのPythonを利用することが可能になります。
本記事の記載時点だと2.1.3~3.9.1までインストール可能です。# pyenvのインストール
macの場合はHomebrewを利用してインストールできるようです。“`
$ brew install pyenv
“`
Linuxの方などはgitで持ってくることができます。“`
$ git clone git://github.com
OpenCV+Pillowで動画上に秒単位で変化する日本語テキストを表示する
## はじめに
業務で秒単位のセンサ情報テキストデータを動画に直接紐付けるために、動画に秒単位で日本語テキストを表示する作業を行った。
その際に少し手間取ったので、テキスト表示用のPython実行コードサンプルを備忘録も兼ねて紹介します。## やったこと (プログラム入出力内容)
入力動画より、下の出力動画のように秒単位で変化する日本語テキストを表示できるようにした。・入力動画 (※ https://www.home-movie.biz/free_movie.html より取得)
・出力動画
を読み込む
##はじめに
JSONの詳細は[ウィキペディアの記事](https://ja.wikipedia.org/wiki/JavaScript_Object_Notation)をご参照ください。
このJSON形式ですが、本来の仕様にはコメントを記述するための仕様がありません。読み込みも書き出しもソフトウェアで行う場合はコメントは要らないと思います。
一方で、設定ファイルにJSONを採用し、ユーザーがメモ帳等で変更するようなスタイルのソフトにおいては、**設定値の仕様が分かり易いのが望ましい**かつ**ファイルは読み込みさえできればOK**という場面が多く、コメントの需要が出てきます。本記事では、全く大したコードではないですが ~~たまに欲しくなる自分のために~~
「コメントが掛かれたJSON」を読み込むためのPythonコードを載せておきます。##JSONCとは?
JSONにコメントを記述するための仕様が追加されたもの・・・という私の認識です。[こちらのQiita記事( JSON にもコメントを書きたい )](https://qiita.com/yokra9/items/
snow加工を剥がしたかった with 機械学習
# 0. 目次
[1. 概要](#1-概要)
[2. 環境](#2-環境)
[3. snow加工](#3-snow加工)
[4. 学習 – pix2pix](#4-学習)
[5. テスト](#5-テスト)
[6. 結果](#6-結果)
[7. epochを増やす](#7-epochを増やす)
[8. いらない訓練データを削除](#8-いらない訓練データを削除)
[9. 最終結果](#9-最終結果)# 1. 概要
snowなどで加工された人間の顔写真から、pix2pixという技術によって
加工されていない顔写真を予測を**したかった**!# 2. 環境
– Python 3.6.8
– Tensorflow 1.14.0
– OpenCV 4.5.1.48# 3. snow加工
https://qiita.com/cheeseokonomiyaki/items/983e4a234a863cb741f8こちらを使わさせていただきました。
Open CVをインストールします。“`
$ pip install opencv-python
“`カスケード分類機をダウ
二項分布で最尤推定/MAP推定/ベイズ推定をする
# これはなに
– 二項分布で最尤推定/MAP推定/ベイズ推定をやります。
– 「[イカサマコインの例で最尤推定とベイズ推定の違いを理解してみる](https://qiita.com/MoriKen/items/09da26466c00500bcd68)」という記事にコメントしたものを多少編集したものです。
– 間違っている所があったらコメントください。# 問題設定
– コインの表が出る確率を知りたい(0.7以上ならイカサマと判定する)
– コインを5回投げたら表3回・裏2回だった
– 表になる確率は0.75という事前知識がある# 最尤推定/MAP推定/ベイズ推定の違い
|手法|方法|事前確率の仮定|パラメータ|
|—|—|—|—|
|最尤推定|尤度関数を最大化するパラメータの値を決める|仮定しない|点推定|
|MAP推定|尤度関数×事前分布を最大化するパラメータの値を決める|仮定する|点推定|
|ベイズ推定|パラメータの確率分布(事後分布)を決める|仮定する|事後分布|### 最尤推定について
1回のコイン投げをベルヌーイ分布で定式化します。
確率θで1
ディレクトリの中身を表示(Python)
pythonでディレクトリの中身を表示させる方法を紹介します
(環境はLinux)
また、ファイル構成はこのようにします“`python:/test
test1 #ディレクトリ
test2.txt #ファイル
test3.txt #ファイル
“`“`python:/test/test1
test4.mp3 #ファイル
test5.mp3 #ファイル
“`#ディレクトリの中身を表示させるには
“`python:ソースコード
import os
print(os.listdir(“/test”))
“`“`python:実行結果
[‘test1′,’test2.txt’,’test3.txt’]
“`pythonでディレクトリの中身を取得するにはos.listdir()を使います
os.listdir()では、中身をリスト化してくれるので、for文を使うと表示させるのが楽です“`python:ソースコード
import os
a = os.listdir(“/test”)
for p in a:
print(p)
“`“`:実行結果
te
VSCodeからAnaconda Powershell Promptを利用する
# 経緯
Windows環境でAnaconda Power ShellをVSCodeのターミナルとして設定する記事がないのでメモとして書いておきます.[Anaconda Promptを設定する記事](https://qiita.com/_meki/items/5b4f06318f1a0986c55c)はたくさんあったのですが,Unixコマンドが使えないのがストレスだったので慣れているPower Shellを利用したいと思ったのがきっかけです.
# settings.jsonの編集
下記手順に従う
1. Anaconda Powershell Promptを検索
2. 右クリックして「ファイルの場所を開く」
3. Anaconda Powershell Promptのプロパティからリンク先の文字列をコピー
4. コピーした文字列のPowershellのパスを指定するコマンド部分をVSCodeのsettings.jsonでterminal.integrated.shell.windowsに指定する
5. 引数部分をterminal.integrated.shellArgs.windo
Metabase APIで変数付きのリクエストを投げる
# はじめに
下図のように、Metabaseで変数を設定したSQLクエリに対して、PythonからAPIを叩いて、クエリ結果を取得します。

# 環境
“`bash
$sw_vers
ProductName: Mac OS X
ProductVersion: 10.13.6
BuildVersion: 17G14042
“`Metabase への接続については[metabase_api](https://github.com/vvaezian/metabase_api_python)を使用しました。
“`pip install metabase-api“`でインストール済みです。Metabaseの構築については[こちら](https://qiita.com/dyamaguc/items/1cba8cd11a
Python:PythonでVlookup的な事をやってみた#3
# どんだけVlookUPが好きなのか問い詰めたい
もー3回目のネタ、でもこれが一番シンプル
PandasのSeries.replaceで置き換えしてます。
ただ、Series.replaceは重いので大量のデータの置き換えは時間がかかるかも# 目的
在庫情報など日々変わる数値をデータベースから読み込んで指定のデータに流し込んで
指定フォーマットで書き出しする。使用インタープリタ:Python3.8
—投稿者の作業環境—
Windows10Pro 64Bit
# 参照元データ
以下のようなデータベースがあった場合に、
商品マスタに対して、販売実績を当て込みたいケースを想定●商品マスタ

●販売実績
を報告書に添付するなど、環境がインストールされていない方にシェアする場合の備忘録です。
JupyterLabからpdf生成もありますが、拡張機能のインストールが必要だそうで、HTML出力を選びました。
https://teratail.com/questions/196951# 参考
こちらを参考にさせていただきました。一気に変換する場合はこの参照先に書かれているコマンドの方が便利です。
https://qiita.com/supersaiakujin/items/1429b7529d858ee4177b# 準備
報告書に添付する場合、警告を表示したくなかったので、こちらを参考に警告を非表示にしました。
https://note.nkmk.me/python-warnings-ignore-warning/# 手順
File > Export Notebook As > Export Notebook to HTML
を選び、ファイル名を指定して保存。# おわりに
これだけ渡せば、結果を見




