
- 1. 【BeautifulSoup】ターミナル上で動くWeblio英和辞書をつくる
- 2. 【競プロ典型90問】008の解説(python)
- 3. Pythonのハッシュ衝突攻撃の考察
- 4. アンサンブル学習-ブースティング(Boosting)
- 5. AWS SSM Parameter StoreにあるNameのリストをフィルターして取得する
- 6. COVID-19のグラフ化とWEB公開
- 7. 【python】pandas学習記録~1回目~
- 8. 【競プロ典型90問】007の解説(python)
- 9. FC2ブログのエクスポートからCSVファイルを作る
- 10. Pythonで理解する確率分布
- 11. NGBoostに関する備忘録
- 12. Pythonではじめる機械学習 part4
- 13. DjangoでDynamoDBに移行する
- 14. NLTKでnltk.download(‘wordnet’)でResource not found.となってしまう
- 15. MT法で異常検知(python)
- 16. 測地系の変換が嫌になってきたのでメモ
- 17. FastAPIのリモートデバッグ設定(VSCode、debugpy)
- 18. Pythonで風配図を描く
- 19. 多数決アンサンブル分類器sklearn.ensemble.Votingclassifier()の変数やメソッドまとめ
- 20. Pythonを使って、PDFファイル中の任意の文字列を変換する
【BeautifulSoup】ターミナル上で動くWeblio英和辞書をつくる
英語が読めない!!
最近、英語の文章を読む機会が増えてきて苦しんでます。
「単語の意味がわからない、、、」っていうのが多くて、毎回weblio辞書を使って調べてたりしたんですけど、いちいちブラウザを操作するのが面倒、、、
ターミナル上でWeblio辞書が使えたらなと思ったのでつくってみました#Beautiful Soupのインストール
“`
$ pip install beautifulsoup4 requests
“`#つくったもの
“`python
import requests
from bs4 import BeautifulSoupwhile(1):
print(‘>> ‘, end=”)
en = input()
en.replace(‘ ‘,’+’) #半角スペースを+で置換res = requests.get(‘https://ejje.weblio.jp/content/{}’.format(en))
soup = BeautifulSoup(res.text, ‘html.par
【競プロ典型90問】008の解説(python)
## 概要
[競プロ典型90問](https://atcoder.jp/contests/typical90)の解説記事です。
解説の画像を見ても分からない(~~理解力が足りない~~)ことが多々あったので、後で解き直した際に確認できるようまとめました。※順次、全ての問題の解説記事を挙げていく予定です。
※★5以上の問題は難易度的に後回しにしているため、投稿時期が遅くなる可能性があります。(~~代わりに丁寧に解説してくれる方いたらぜひお願いします~~)## [問題008-AtCounter](https://atcoder.jp/contests/typical90/tasks/typical90_h)
### 問題概要
文字列Sから任意の文字を順番を変えずに取り出したときに、”atcoder”(以下、文字列Tとします。)となる個数を求める。### 解き方
まず初めに、単純にSから”atcoder”の文字をそれぞれ検索する方法が考えられますが、
この考えでは、文字列の長さNの検索を7回(Tの長さ分)行うため、$N^7$となりTLEになってしまいます。そこで今回は、DP(
Pythonのハッシュ衝突攻撃の考察
この記事は、Pythonにおける悪意を持ったdict, setに対するハッシュ衝突攻撃を考察します。一般的なハッシュ,辞書の実装を理解していることを前提とします。
C++の場合はmap, setの衝突を以下の記事のように簡単に引き起こせます。Pythonはどうでしょうか?
https://qiita.com/recuraki/items/652f97f5330fde231ddb
# サマリ
– Pythonでも実装として辞書の衝突は起こり、O(N)で各操作が発生しうる
– ただし、そのためには61ビットのハッシュの衝突をさせなければならないので現実的でない
– 数値入力で衝突を引き起こす入力をすることは現実的でない
– 文字列に関しても、ハッシュの衝突を発生させることは現実的でない
– このため、競技プログラミングの範囲ではhackケースにpythonの辞書を攻撃することは困難
– 定数倍をO(9)くらいにはできます。数値の辞書への追加は`mod (2**61-1)`した値を右から5bitずつ使
アンサンブル学習-ブースティング(Boosting)
## ブースティング(Boosting)とは
ブースティング(Boosting)とは、複数の弱学習器を組み合わせて強学習器を形成するアンサンブル手法です。
弱学習器は、ランダムな推測よりもわずかに良い結果を出すモデルのことです。例えば、最大深度が1の決定木は弱学習器です。ブースティングは、学習データもモデルも逐次的に生成・構築されていきます。
予測から外したサンプルが、次のモデル構築の段階で重視されるように新しい学習データが生成されます。イメージは以下です。
引用:”Hands on Machine Learning with scikit-learn and Tensorflow.” (2017) Géron, Aurélien.ブースティングは学習不足(underfitting)時に効果的な手法と言われています。
## Ada
AWS SSM Parameter StoreにあるNameのリストをフィルターして取得する
# この記事でできるようになること
どうも、IoTエンジニアのDangoと言います。AWSを用いたIoTシステムを構築していることが多いです。今回はPythonでAWS SSM Parameter StoreにあるNameをフィルターして取得し、List化します。
# 前提
AWS SSM Parameter Storeの詳しい仕様については割愛します。
Python3 + boto3で操作する前提です(AWS CLIなどでもやることは大体同じですが)。
IAMの設定も済んでいる前提です。## 基本操作
まずはboto3でssmを操作する方法を簡単に。
最初に、ssmのclientを作ります。“`python
import boto3
REGION = “ap-northeast-1”
ssm = boto3.client(“ssm”,region_name=REGION)
“`そして、次のように操作します。
“`python
戻り値 = ssm.メソッド(引数)
“`#やりたいこと
AWS SSM Parameter Storeから読み出すとき、
Na
COVID-19のグラフ化とWEB公開
####はじめに
新型コロナのcsvデータがNHKからダウンロードできるので、そのcsvデータを加工編集しx軸に年月日、y軸に各県毎の感染者数等のグラフを作成し、webで表示するまでのプログラムを作成したので公開します。– csvデータの編集には、pandasを使用しました。
– グラフ作成にはmatplotlibを使用しました。
– Web構築のフレームにはFlaskを使用しました。Jinja2も使用しています。
– Webサーバーにはpythonanywhereの無料版を利用しました。####環境
– 開発環境
– WIndows10
– Pycharm
– Python 3.8
– pythonanywhere
– 無料版####ディレクトリ構成とファイル
webサーバー pythonanywhere でのディレクトリ構成とファイルです。“`
mysite/
├── csv/
│ └── COVID-19_by_NHK.csv NHK提供のcsvファイル
├── covid19_graph.py
【python】pandas学習記録~1回目~
### はじめに
– バージョン
– Python: 3.6.8
– pandas: 1.1.5
– 概要
– 以下のようなyamlがある時に、pandasを使うと見やすくかつシンプルに表が作成出来るので紹介します。“`yaml:member.yml
—
member:
– name: “Aoki”
age: 23
– name: “Akiyama”
age: 38
– name: “Tom”
age: 31
“`今回紹介するのは以下のパターンです。
– 1. yamlから表を作成する
– 2. 表の列に対して関数を適用する
– ageが30以上であるかを判定し、True/Falseを返す
– 3. 関数の結果を新たな列として追加する### 1. サンプルコード
実際に作成したコードは以下です。
“`python:test_pandas.py
import pandas as pd
import yamldef read_yml(input_file):
with open
【競プロ典型90問】007の解説(python)
## 概要
[競プロ典型90問](https://atcoder.jp/contests/typical90)の解説記事です。
解説の画像を見ても分からない(~~理解力が足りない~~)ことが多々あったので、後で解き直した際に確認できるようまとめました。※順次、全ての問題の解説記事を挙げていく予定です。
※★5以上の問題は難易度的に後回しにしているため、投稿時期が遅くなる可能性があります。(~~代わりに丁寧に解説してくれる方いたらぜひお願いします~~)## [問題007-CP Classes](https://atcoder.jp/contests/typical90/tasks/typical90_g)
### 問題概要
配列Aの中から、各Bに最も近い値を見つけ、その絶対値を出力する。### 解き方
まず初めに、全てのA、Bの組み合わせにおいて、順番に絶対値を求めていく方法が考えられるかと思います。
しかし、この考えでは、計算量がNQとなり、N, Qはそれぞれ$10^5$オーダーのため、TLEとなります。そこで今回は、事前にAをソートし、二分探索を行うことで、Bに最も
FC2ブログのエクスポートからCSVファイルを作る
簡単に組んだスクリプトのメモです。
FC2 ブログのエクスポートは、下記のような形で出力されます。
“`
AUTHOR: sou (08thse)
TITLE: とりあえず
STATUS: Publish
ALLOW COMMENTS: 1
CONVERT BREAKS: default
ALLOW PINGS: 1
PRIMARY CATEGORY: 日記
CATEGORY: 日記DATE: 07/27/2008 22:01:09
—–
BODY:
ほげほげ
—–
EXTENDED BODY:—–
EXCERPT:—–
KEYWORDS:—–
# 以下、記事ごとに繰り返し
“`ここから、「タイトル」「カテゴリ」「公開日」を CSV で出力したかったので、サクッと Python で組んでみました。
“`python
import pandas as pdcols = [‘title’, ‘category’, ‘publish_date’]
df = pd.DataFrame(index=[], columns=col
Pythonで理解する確率分布
##背景
最近教師あり学習を行おうとして、データが足りないというケースに遭遇することが増えてきたので、データがなくても学習してくれる強化学習に関心を持ちました。##環境
Google Colaboratoryで実行しました。##参考
「仕事で始める機械学習第2版」268頁~270頁
この書籍では6目のサイコロを2回振った値(2D6)が5以下になる確率を計算していました。この記事では12目のサイコロを2回振った場合に合計が10以下になる確率を計算していきたいと思います。
“`python:googlecolab
import numpy as np
import scipy.stats
import matplotlib.pyplot as plt
import japanize_matplotlibn = 1000000 #サイコロを振る回数の指定
dice_total = np.random.randint(1,13, size=n) #1個目のサイコロを振る
dice_total +=np.random.randint(1,13, size=n) #2個目のサ
NGBoostに関する備忘録
“`python
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from ngboost import NGBRegressor
import matplotlib.pyplot as plt
import numpy as npX, y = load_boston(return_X_y=True)
#print(X.shape, y.shape)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#print(X_train.shape, y_train.shape)
#print(X_test.shape, y_test.shape)ngb = NGBRegressor()
ngb.fit(X=X_train, Y=y_train)
#ngby_preds = ngb.predict(X_test)
y_dists = ngb.pr
Pythonではじめる機械学習 part4
# 前回の内容
[Pythonではじめる機械学習 part3](https://qiita.com/yuto_suzuki/items/00f58c32e2c87907b477)# k-最近傍法を使ったアイリスのクラス分類 概要
一番初めの分析モデルとして、k-最近傍法というアルゴリズムを使ったアイリスのクラス分類についてまとめていきます!
初心者の自分にも分かりやすいアルゴリズムだったので、ここを足がかりに学習を進めていきましょう。### k-最近傍法とは?
新しいデータポイントを予測する際に、単純に学習済みの特徴量に一番近い点を見つけてきて、それを分類結果とするアルゴリズムである。
k-最近傍法の「k」はいくつの近傍点を参考にするか?を表している(つまり、3個とか5個とかも取れる。)
このセクションでは一旦、1つの近傍点で見る。### k-最近傍法の実装
“`kNeighbors.py
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1
DjangoでDynamoDBに移行する
CodestarでDjangoを立ちあげ、データベースをsqliteからDynamoDBに移行します。
この記事は以下の方におすすめです!
:::note info
CodestarでDjangoを立ち上る方法を軽く知りたい
Djangoでデータベースがどのように使われているのかを知りたい
DjangoでDynamoDBに移行したい
:::#概要
この記事ではAWSのサービスの一つである`CodeStar`を使用し、`Django`で環境を構築します。そこからDjangoのデフォルトのデータベースであるsqliteからAWSのDynamoDBに移行します。
DjangoはDynamoDBに対応していないので、ある程度自分で対応させる必要があります。何か不備があった場合はコメントの方でご指摘いただけると幸いです。
#環境
“`
git
Windows
Django==2.1.15
Python==3.6.12
“`#CodeStarでDjangoを立ち上げる
:::note info
CodeStarはAWSのサービスの一つです。
AWSの様々なサービスが
NLTKでnltk.download(‘wordnet’)でResource not found.となってしまう
# はじめに
ゼロから作るDeepLearning2を使って勉強会を開こうと思い、復習をしていたました。
せっかくなので付録で説明されている`wordnet`を実装していたのですが、Colabで書籍通りに動かなかったのでまとめたいと思います。古めのライブラリで利用する人は少ないかなと思いましたが、有名な書籍かつ初心者向けということで同じく詰まる人の助けになればと思います。
# 環境
– Google Colabratory# 問題
まず、nltkをインストールします。
“`
!pip install nltk
“`その後、以下のコードを実行します。
“`
import nltk
from nltk.corpus import wordnet# carの類義語を調べる
wordnet.synsets(‘car’)
“`すると、以下のエラーが発生します。
“`
LookupError Traceback (most recent call last)
/usr/local/lib/pytho
MT法で異常検知(python)
# はじめに
世の中には時系列データがたくさんあって、例えばサイトの日々のアクセス数だとか、工場の温度センサーだったりとか、いろいろな現場で目に付く機会が多いと思う。
そんな時系列データを使った課題解決の中でもニーズが高いのが異常検知だと思われる。
異常検知へのアプローチはたくさんあるが、その中の一つMT(マハラノビス・タグチ)法を遊びで試してみたので書く。# MT法
MT法の基本的な概念やRでの実装方法は井手剛さんの書籍[「入門 機械学習による異常検知 Rによる実践ガイド」](https://www.amazon.co.jp/dp/4339024910)に書いてある。
マハラノビス距離に基づく外れ値検出手法に、異常変数の選択手法を組み合わせることで、多変数のホテリング理論の課題に対応した手法である。
イメージ的に、相関のある複数のデータ同士をお互いに比較しておかしくないのか見ている感じ。
(AとBとCは同じような動きをするはずなのに、Aだけ異なる動きをしていた ⇒ 異常と判断 ⇒ MT法は異常を起こしているデータの判別も可能)
※ユークリッド距離とは違い、マハラノビス距離はデータ
測地系の変換が嫌になってきたのでメモ
様々な測地系のデータを1つの地図にプロットする必要があるのですが、泣きそうなので頭の整理のためにまとめます。
(あくまで自分用で情報の網羅性はありませんのであしからず)# 用語の整理
### 座標系
まずこれがバラバラなのが諸悪の根源。##### 地理座標系(度数、dgree)
いわゆる緯度経度でイメージするやつ。
`lat=35.658584 lon=139.7454316`地球の中心からの角度で考えてる。
が、地球は楕円形なので、円として考えてる場合と楕円として補正してる場合とがある。latが緯度、lonが経度。
latlonで覚えてるけど、関数の引数とかはlon,latになってることが多いので罠。##### 地理座標系(度分秒、DMS)
上と同じく角度なんだけど、単位を分けたやつ。
1.5時間と書くか、1時間30分と書くかみたいな違い。
`lat=35度39分30.9秒 lon=139度44分43.55秒`
時間と同じで、60で割ると1つ上の単位になる。やたら表記に幅がある。
`lat=35.3.30.9 lon=139.44.43.55`
`lat=3
FastAPIのリモートデバッグ設定(VSCode、debugpy)
# 記載内容
FastAPIについて、VSCodeとdebugpyを使ったリモートデバッグ方法を記載します。FastAPIは下記のように起動します。これでどうやって、main.pyにリモートデバッガーを接続できるのか迷ったので、記録を残します。
https://fastapi.tiangolo.com/ja/
“`
uvicorn main:app –reload
“`# FastAPIの起動方法
単純にuvicornをモジュールとして実行する形で、main.pyをリモートデバッグできました。
“`
python -m debugpy –listen 0.0.0.0:5678 –wait-for-client -m uvicorn cont_mgmt:app –reload
“`# VSCodeのlaunch.jsonの設定
通常通り設定すればOKです。
“`json
{
“version”: “0.1.0”,
“configurations”: [
{
“name”: “FastAP
Pythonで風配図を描く
# やりたいこと
PythonのMatplotlibで風配図を描きます.Pythonでの風配図の描き方をまとめている記事があんまりなかったので書きました.ぜひ参考にしてみてください.# 風配図とは
サクッと風配図についての説明をします.風配図(Wind rose)はある期間における各方位(大体8,16方位)の風向,風速の頻度を円形にプロットした図です.これを見ればその地点の卓越風や風環境の特徴がよくわかるので,建築分野や気象シミュレーションの精度評価などに使われます.今回は簡単のため,風向のみをプロットした風配図を描画してみようと思います.
# 使用データ
今回は気象庁の過去の気象データから風配図を作ります.データは以下のURLから地点,期間等を指定してダウンロードできます.この記事では高知市地方気象台の2020年7月1ヶ月ぶんの
多数決アンサンブル分類器sklearn.ensemble.Votingclassifier()の変数やメソッドまとめ
#作業環境
Jupyter Notebook(6.1.4)を用いて作業を進めました。
各versionは`pandas`(1.1.3), `scikit-learn`(0.23.2)です。#多数決アンサンブル分類器`Votingclassifier()`とは
いくつかの分類器を使って1つのメタ分類器を作る方法を**アンサンブル**法といいます。
学習方法や予測値の出し方に工夫を与えたブースティングやスタッキング、バギングなどが有名ですが、ここでは単純に、個々の分類器がそれぞれ全データに対して学習をして、その結果を多数決で決める単純なアンサンブル分類器を考えていきます。
下は単純多数決アンサンブルのイメージ図です。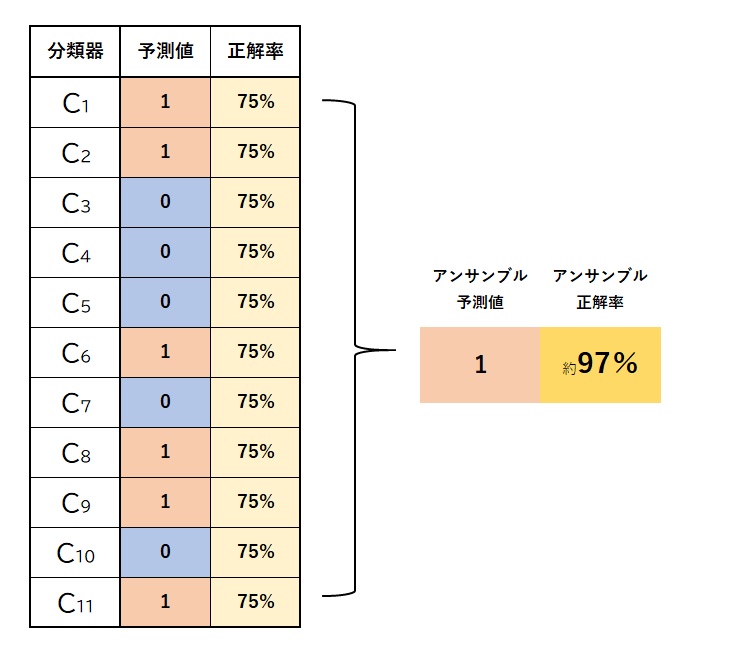
このような単純多数決は`sklearn.ensemble`ライブラリの中の`VotingClassifier`クラスで実装
Pythonを使って、PDFファイル中の任意の文字列を変換する
pdf-redactor を使って可能でした。
https://github.com/JoshData/pdf-redactor#Install
https://github.com/JoshData/pdf-redactor からZIPファイルをダウンロード
ライブラリをインストールする。
pip3 install -r requirements.txt# 構文ファイルを書く
この例ではPDF ファイル中の 123456 を、ABCDEFに置換している。
$ vi hoge.py
import re
from datetime import datetimeimport pdf_redactor
options = pdf_redactor.RedactorOptions()
options.content_filters = [
(
re.compile(u”123456″),
lambda m : “ABCDEF”
),
]
pdf_redactor.redactor(opti




