
- 1. QGISとAmazon AuroraのPostgreSQL&PostGISを利用してジオデータを表示してみた
- 2. Amazon S3 Glacier のボールト とは
- 3. Glueに入門してみた(PySparkでk-means実行)
- 4. AWS CloudTech ハンズオン1に必要な費用の調べ方についてまとめました
- 5. Serverless Frameworkで運用しているAWSアプリケーションのデプロイをGithub Actionで管理する方法
- 6. インターネットゲートウェイと仮想プライベートゲートウェイの違い
- 7. 【AWS】RDSとEC2を紐づける方法
- 8. CloudWatch Synthetics について
- 9. SystemsManagerのChangeManager承認リクエストをロール指定にして承認する
- 10. AWS Workshops攻略記:AppSync Immersion Day(+VTLへの愚痴)
- 11. DatabricksにおけるAWS PrivateLinkの有効化
- 12. 【AWS】Django環境をEC2+ELB+RDSで構築してみた
- 13. localstackでredshiftとs3を立ててみる
- 14. 作成したEC2にWebサーバー(nginx)を立ち上げるまで。
- 15. Athenaで基礎からしっかり入門 分析SQL(Pythonコード付き) #4
- 16. AWS CloudFormationで開発環境を作ってみる
- 17. AWS Certified Cloud Practitionerを受けようと思った人へ
- 18. S3操作をするLambda関数(Python-image)をSAM CLIを使ってデプロイする手順をまとめてみる
- 19. terraformのworkspaceを利用してVPCをマルチリージョンに展開する
- 20. 認証に関して調べた事を書き連ねてみる。
QGISとAmazon AuroraのPostgreSQL&PostGISを利用してジオデータを表示してみた
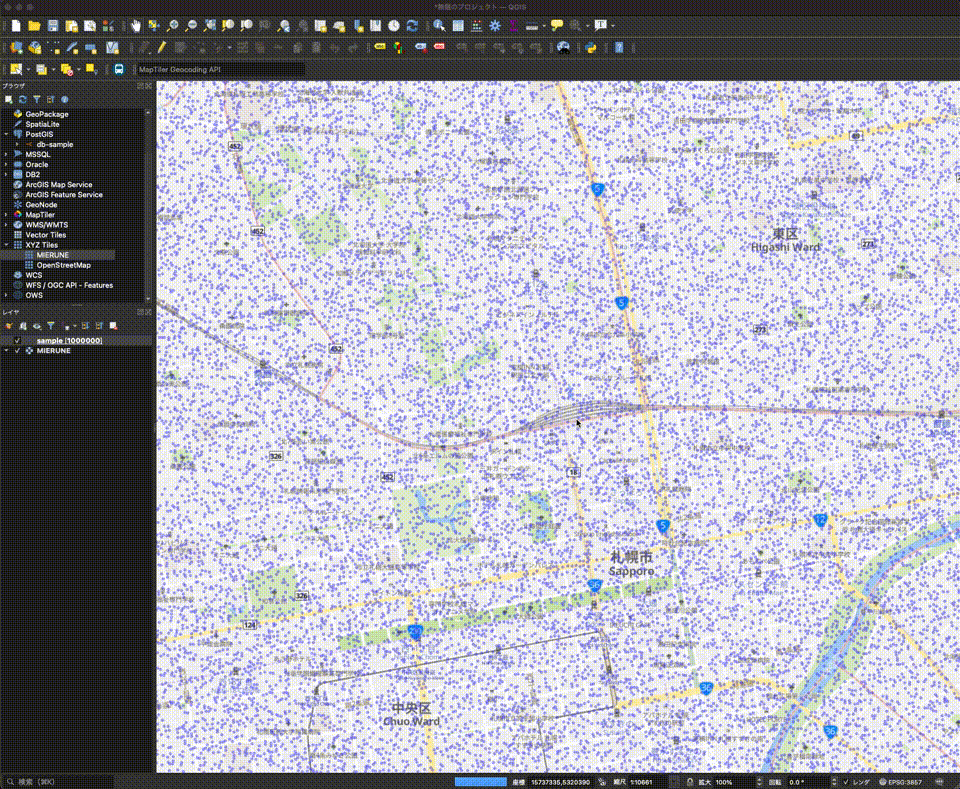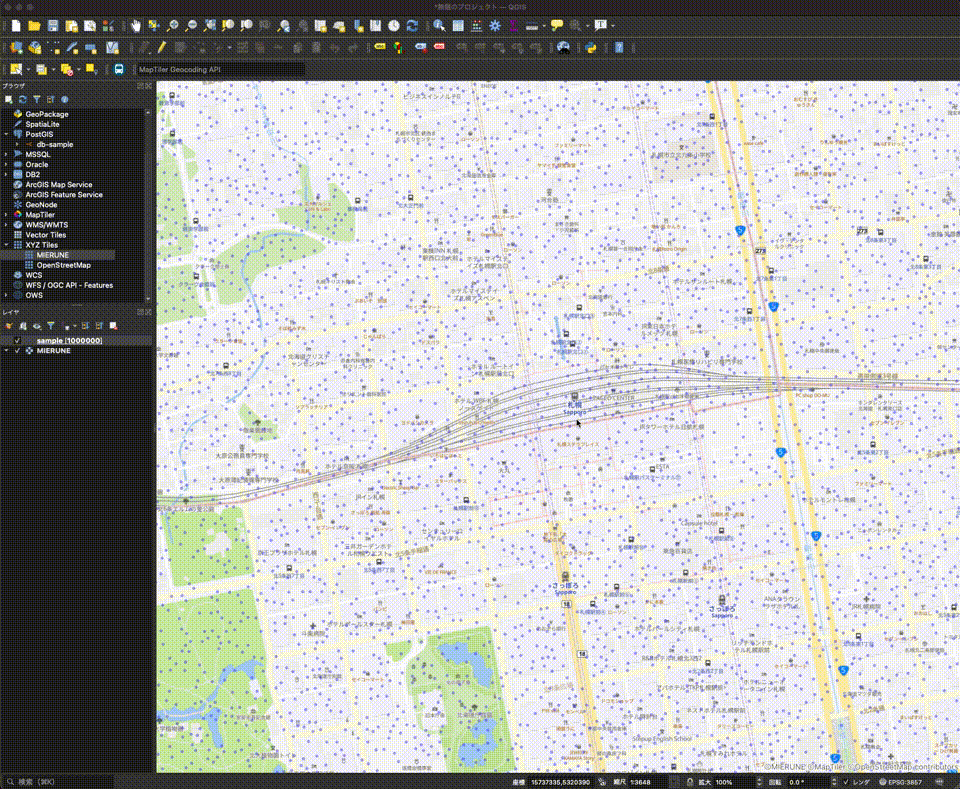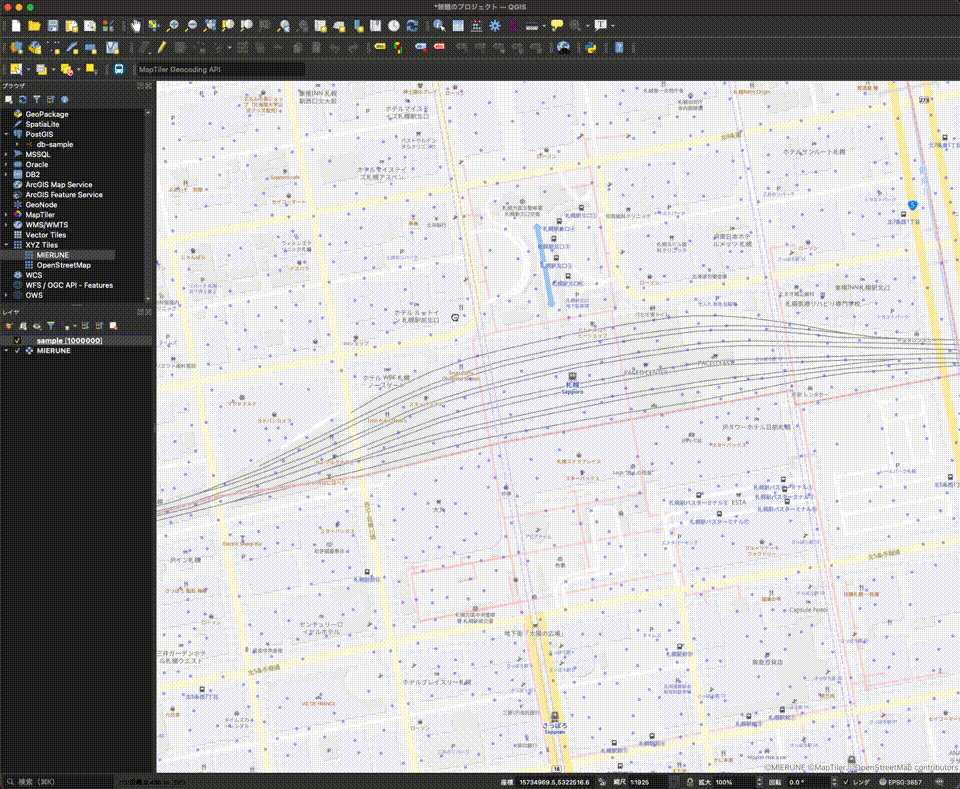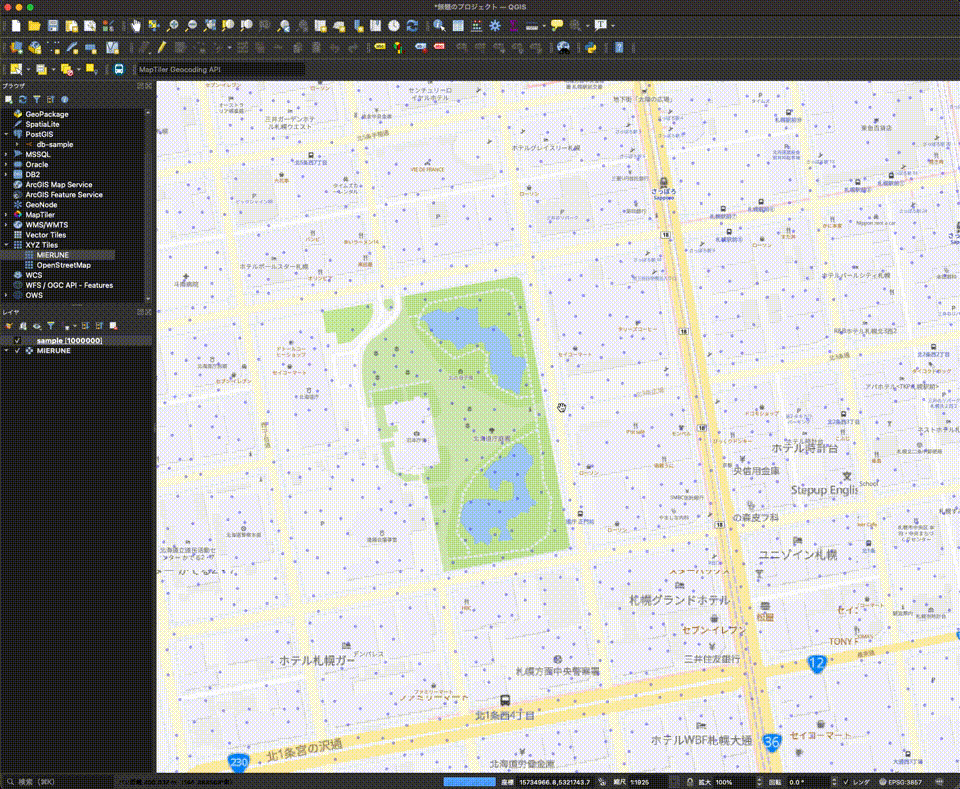

### QGISとAmazon AuroraのPostgreSQL&PostGISを利用してジオデータを表示してみました :tada:
2年くらい前に「[QGISとCloud SQLのPostgreSQL&PostGISを利用してジオデータを表示してみた](https://day-journal.com/memo/try-023)」という記事を書いたのを思い出して、今回は[Amazon Aurora](https://aws.amazon.com/jp/rds/aurora/?aurora-whats-new.sort-by=item.additionalFields.postDateTime&aurora-whats-new.sort-order=desc)でPostgreSQL&PostGISデータベースを構築し[QGIS](http://www.q
Amazon S3 Glacier のボールト とは
## 勉強前イメージ
Glacier を高く飛び越える・・・?
英語だけじゃよくわからん## 調査
### Amazon S3 Glacier のボールト とは
s3 Glacierのデータモデルの主要概念の内の一つで、
アーカイブを格納するコンテナのことを指します。
s3で言い換えるとバケットのことになります。s3 Glacierのデータモデルの主要概念には
他にも `アーカイブ` というものがあり、
ログファイルや動画、写真などのデータのことを指し、
s3で言い換えるとオブジェクトのことになります。### ボールトロック とは
ボールトロックとは、ボールトロックポリシーを用いて
s3 Glacierのコンプライアンス管理を簡単に適応することが出来ます。
ポリシーで、読み込みのみにしたり 登録から1年経過しないと削除できないなどの
ポリシーを適応することが出来ます。### ボールトロックの適応方法
ボールトロックポリシーは変更ができないので、セットを行うのに2段階プロセスを踏みます。
– ボールトロックポリシーをボールトに関連付け
– これによりテスト
Glueに入門してみた(PySparkでk-means実行)
# はじめに
* 大きめなデータでk-meansを実行したかったが、ローカルでscikit-learnで実行しようとするとリソースが足りなかったので、Glueを試してみた。# Glueとは
* **DataCatalog** と **ETL** という2つのコンポーネントから構成されるサービス。
* 「S3のデータファイルから、AWS Redshift Spectrum と AWS Athenaのテーブルを作成する」 ツール。
* GlueでDataCatalogと呼んでいるテーブル定義は、Apache Hiveのテーブルのこと。 = Glueは、S3のファイルからHive Tableを作るツール。
* Glueはクローリングによるテーブル定義作成・更新に加えて、Apache Sparkを使って、プログラミングにより、ユーザーがより細かくデータ加工することもできる。
* Sparkについては[こちら](https://qiita.com/noko_qii/items/a5d529c941cf00618bf9)を参照。
Lambdaのトリガーとして設定するAPI Gatewayには、開発用(dev)・本番用(prod)の2つのステージを用意し、Functi
インターネットゲートウェイと仮想プライベートゲートウェイの違い
## 勉強前イメージ
なんだっけ・・・ぱっと違いが出てこない
## 調査
### インターネットゲートウェイとは
インターネットゲートウェイはインターネットと接続するもので、
ネットワーク内はインターネットゲートウェイを通じてインターネットとやり取りを行います。
VPC内とインターネットを通信する際は以下を行います。– VPCにインターネットゲートウェイとアタッチする
– ルートテーブルでデフォルトルートにインターネットゲートウェイの設定を追加### 仮想プライベートゲートウェイとは
`Virtual Private Gateway` とも言い、
VPN接続の際にVPC側に配置するもの
複数のカスタマーゲートウェイ(ユーザ側に配置されるVPN装置)を受け付けることが出来る。### 違い
– インターネットゲートウェイ → VPC内とインターネットの接続の際に使用
– 仮想プライベートゲートウェイ → VPN接続の際にVPC側に接続するもの## 勉強後イメージ
全然違うやん!!!
特に仮想プライベートゲートウェイ忘れがち## 参考
– [4. インター
【AWS】RDSとEC2を紐づける方法
# はじめに
今回はRDSとEC2を紐づける方法について記述します。
本来であればEC2やRDSの作成の際に紐付けお行うのですが、
その工程を飛ばしてしまい、後から紐づける方法について記述いたします。
今回は自分自身のセキュリティの都合上、スクショはなく文字のみでご案内させていただきます。AWSやEC2、RDSについては下記の記事でまとめているので詳しく知りたい方は、
ぜひ参照してくださいhttps://qiita.com/kenta-nishimoto-1111/items/4760bc02a6dfa40db035
https://qiita.com/kenta-nishimoto-1111/items/4760bc02a6dfa40db035
https://qiita.com/kenta-nishimoto-1111/items/546990b12d4485a1b843
# EC2とRDSの紐付け方法
●EC2のセキュリティグループをコピーする
AWSのEC2を開き、紐付けたいインスタンスを選択します。
そしてメニューの中の「セキュリティ」を選択す
CloudWatch Synthetics について
# はじめに
CloudWatchにはSyntheticsという、アプリケーションの死活監視(外形監視)を行うサービスがあります。Canaryを作成し、APIのエンドポイントやWebページのリンクを設定することでそのエンドポイントをスクリプトで定期的に叩きに行き、落ちていた場合はSNSで通知や、CloudWatchAlarmを鳴らしたりできます。
以下公式説明です。
> Amazon CloudWatch Synthetics を使用して、スケジュールに沿って実行される設定可能なスクリプトである Canary を作成し、エンドポイントと API をモニタリングできます。Canary は顧客と同じルートをたどり、同じアクションを実行します。これにより、アプリケーションに顧客トラフィックがない場合でも、顧客エクスペリエンスを継続的に検証できます。Canary を使用すると、顧客が問題を検出する前に問題を検出できます。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/CloudWatch_Sy
SystemsManagerのChangeManager承認リクエストをロール指定にして承認する
# Systems Managerとは
SystemsManagerとは、ランブックの実行に承認プロセスを作成することでランブックの実行管理が行えるサービスです。
ランブックを指定して変更テンプレートを作成し、リクエストを作成することで「承認されたらランブックを実行する」というプロセスを作成することができます。
また、過去に承認したリクエストの履歴確認やリクエストの状態確認なども行えます。以下公式説明文
> AWS Systems Manager の機能である Change Manager は、アプリケーションの設定とインフラストラクチャに対する運用上の変更をリクエスト、承認、実装、および報告するためのエンタープライズ変更管理フレームワークです。単一の委任管理者アカウントから AWS Organizations を使用すると、複数の AWS アカウント と複数の AWS リージョン 全体で変更を管理することができます。または、ローカルアカウントを使用して、単一の AWS アカウント の変更を管理できます。AWS リソースとオンプレミスリソースの両方に対する変更を管理するには、Ch
AWS Workshops攻略記:AppSync Immersion Day(+VTLへの愚痴)
# はじめに
AWSのWorkshop(ハンズオン)がまとまったサイト「AWS Workshops」使ってますか?
今回はAppsyncが4時間ほどで学べる「Appsync Immersion Day」を試してみました。英語に抵抗感ある方向けに、布教がてらのレポを書きます。https://appsync-immersionday.workshop.aws/
## 概要(ネタバレ注意)
– 各章立てと、概要を。※準備、片付けは割愛。
– Lab 1. Hands-on with AppSync
– マネジメントコンソールでAppsyncを作成し、GUI上のエディタでスキーマ定義、クエリ実行。
– CDKでAppsyncを作成し、GUI上のエディタでスキーマ定義、クエリ実行。
– サンプルアプリを立ち上げ、データを投入する実践的な動きを試せます。
– Lab 2. Security
– スキーマ・リゾルバを編集して、APIキーでの認証 → Cognitoユーザープールでの認証に置き換え。
DatabricksにおけるAWS PrivateLinkの有効化
[Enable AWS PrivateLink \| Databricks on AWS](https://docs.databricks.com/administration-guide/cloud-configurations/aws/privatelink.html) [2021/8/30時点]の翻訳です。
> [Databricksクイックスタートガイド](https://qiita.com/taka_yayoi/items/125231c126a602693610)のコンテンツです。
> **プレビュー**
この機能は[パブリックプレビュー](https://docs.databricks.com/release-notes/release-types.html)です。この記事では、ユーザーとお使いのDatabricksワークスペース間、Databricksワークスペースのインフラストラクチャにおおけるデータプレーンのクラスターとコントロールプレーンのコアサービス間で、プライベート接続を有効化するために、どのようにAWS PrivateLinkを活用するのかを説明しま
【AWS】Django環境をEC2+ELB+RDSで構築してみた
#はじめに
Djangoの実行環境を構築する機会があったため、せっかくなので現在学習を進めているAWSに絡めて構築してみようと思います。
※AWSがメインの内容となるため、Django実行環境についてはさらっと記載します。
※Django実行環境については独学となるのでご容赦ください…#構成図
以下のような構成を目指します。
EC2インスタンス OS:Amazon Linux 2
Webサーバ(リバースプロキシ):Nginx
APサーバ(WSGIサーバ):Gunicorn
データベース(RDS):MySQL* Nginx+GunicornをEC2インスタンスにインストール
* データベースとしてマルチAZ構成のRDS(MySQL)を使用
* EC2起動時にユーザーデータによって、Django環境構築を実行
* EC2インス
localstackでredshiftとs3を立ててみる
## どういう記事か
とりあえずlocalstackの環境構築を行なってredshiftとs3を使ってみた記事です。
## 参考
## 前提
m1 mac
## docker-compose
“`docker-compose.yml
version: ‘3’services:
# LocalStack
localstack:
image: localstack/localstack:latest
environment:
– SERVICES=s3,redshift # 使いたいAWSサービスカンマ区切りで設定する
– DEFAULT_REGION=ap-northeast-1 # リージョンを設定
– DATA_DIR=/tmp/localstack/data # データ保存するディレクトリ
volumes:
– ./localstack:/tmp/local
作成したEC2にWebサーバー(nginx)を立ち上げるまで。
作成したEC2にWebサーバー(nginx)を立ち上げるまでの簡易的なメモです。
## 1.EC2にログイン
SSHでログイン。“`bash
# XX.XXX.XX.XXXはパブリックアドレスを入力。
ssh -i ~/.ssh/xxx.pem ec2-user@XX.XXX.XX.XXX
“`## 2.EC2にnginxをインストール
amazon-linux-extrasを使ってnginxをインストールします。“`bash
# マニュアルの確認
man amazon-linux-extras# 利用可能なリストを表示
amazon-linux-extras# 管理者権限でインストール
sudo amazon-linux-extras install nginx1# nginxを起動
sudo systemctl start nginx.status# nginxのステータスを確認(起動されていることを確認)
systemctl status nginx.status# ポート80番の状態を確認
sudo lsof -i:80
“`##
Athenaで基礎からしっかり入門 分析SQL(Pythonコード付き) #4
今まで複雑なデータ操作・分析などはPythonでやっており、SQLは普通のアプリ開発程度のライトなものしか触って来なかったのですが、やはり分析用の長いSQLなども書けた方がやりとり等で便利・・・という印象なので、復習も兼ねて記事にしておきます。
また、SQLに加えて検算も兼ねてPythonやPandasなどを使ったコードもSQLと併記していきます(Pythonで書くとどういった記述が該当するのかの比較用として使います)。
※長くなるのでいくつかの記事に分割します。本記事は4記事目となります。
# 特記事項
本記事では配列関係を良く扱っていきます。その都合、Pandasなどでapplyメソッドなどを絡めた形で触れている節もあればビルトインでの記述のみしている節もあります(本記事からPandas色が少し薄くなります)。
# 他のシリーズ記事
※過去の記事で既に触れたものは本記事では触れません。
`#1`:
用語の説明・SELECT、WHERE、ORDER BY、LIMIT、AS、DISTINCT、基本的な集計関係(COUNTやAVGなど)、Athenaのパーティション、型、
AWS CloudFormationで開発環境を作ってみる
# ■ CloudFormation
CloudFormation は AWSリソースのプロビジョニングを行えるサービスで、YAML(またはJSON)でテンプレートを記述することができます。
今回は勉強がてら自分の開発環境を作ってみたいと思います。
## ◎ テンプレート
“`dev.yml
# 組み込み関数: https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference.html
# 疑似パラメータ: https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/pseudo-param
AWS Certified Cloud Practitionerを受けようと思った人へ
# なぜ書くのか
– 自分がこの試験に興味を持った時に、「勉強法から受験方法までを流し読みできる記事」があればいいと思ったから
– 特に受験方法(オンライン試験の時間帯や当日のやり取り)はあまり情報がなくて不安だったから(→ 「受験してみての感想」を参照)# なぜ受けたのか
– 仕事でAWS使いそうだけど、知識がまったくなかったから
– AWSサービス名となんとなくの役割を理解して、会議やドキュメントを理解できるようになるため
– (Djangoの勉強してたらクラウドでサーバー立ててみたくなったから)# 筆者について
– 社会人3年目
– メーカーでソフトウェア開発担当
– クラウド開発経験ゼロ# 勉強方法
#### 作戦
初級の試験かつ選択式の問題ということで、とにかく過去問の数をこなす方針を立てました。#### 勉強時間
– 約2週間
– 平日1時間、休日3, 4時間ほど
実際にやってみて、多すぎず少なすぎずちょうどいい勉強時間だったと思います。サーバー管理やデプロイに関する知識・経験がもとからあれば、この半分くらいの勉強時間で合格できる印象です。###
S3操作をするLambda関数(Python-image)をSAM CLIを使ってデプロイする手順をまとめてみる
##はじめに
Lambda関数を作成するにあたり、必要な手順をざっくりまとめました。
以下も試しました。– 1つのアプリケーションで複数の関数の定義
– S3の操作周りをLambdaで行う
– SAM CLIのローカルテストを試す##開発者のIAMユーザ作成
開発とデプロイで使用します。


あとは、デフォルトのまま作成し、アクセスキー、シークレットアクセスキーを保存#####必要な場合アクセス権を追加
ユー
terraformのworkspaceを利用してVPCをマルチリージョンに展開する
workspaceを使って複数リージョンのインフラ環境をサクッと作って管理してみる。
マルチリージョン構成ので同じ構成のVPCを展開する時に便利。workspaceについてはこの記事を参考に
https://dev.classmethod.jp/articles/how-to-use-terraform-workspace/
今回のversion
“`
$ terraform –version
Terraform v1.0.3
on darwin_amd64
+ provider registry.terraform.io/hashicorp/aws v3.42.0Your version of Terraform is out of date! The latest version
is 1.0.6. You can update by downloading from https://www.terraform.io/downloads.html
“`やっていきましょう。
workspaceはawsのregion名で作成。“`
default
*
認証に関して調べた事を書き連ねてみる。
# このページに関して
今後重要になると思い、認証や認可やSSOとかの知見を得ようとしています。調べてると用語がたくさん出てきてどれがどう関係しているのかこんがらがってしまっています。その為、自分が整理する為のメモページです。とはいえ、同じ感覚を持つ人も多いと思うのでその方たちの参考になればと思います。初心者タグつけているのはその為です。
間違っている点など多々あるかと思います。その際には指摘など頂けると有り難いです。# 認証って何?
[IT用語辞典](https://e-words.jp/w/%E8%AA%8D%E8%A8%BC.html)によると、**認証とは、対象の正当性や真正性を確かめること。ITの分野では、相手が名乗った通りの本人であると何らかの手段により確かめる本人確認(相手認証)のことを単に認証ということが多い。**だそうです。
# 世の中ではどんな感じ?
大体のサービスでユーザーIDとログインパスワードを求められる形です。これは昔も今も同じかなと思います。
ただ、最近で世の中で流行っているのはシングルサインオンです。すなわちどこかのサービスでログインして





