
- 1. # 使い終わった壁紙を自動で削除したい!
- 2. Pythonでエラーが出た時、まずやること
- 3. 【5】辞書型で自販機データを作ろう
- 4. 【4】リストの要素同士の計算
- 5. windows10へ2021年10月10日時点で最新のPython3.10.0で jupyter lab をpipでインストールしようとしたら遅延しまくってはまった件について
- 6. Python機械学習/pickleファイルを使ったオブジェクトの保存
- 7. Ubuntuに最新バージョンのPythonをインストールする
- 8. Python3.10 新機能!パターンマッチ構文解説
- 9. kivyMDチュートリアル其の参什漆 Components – NavigationRail篇
- 10. Python 基礎
- 11. Pipでuwsgiのインストールが失敗する場合の対処法
- 12. 【AtCoder】ABC207のA,B,C問題を解く
- 13. Pythonでランダム文字列を生成する
- 14. pip installをしたときにGitのsubmoduleがインストールされない問題
- 15. Pillow(PIL)で生成するgifの画質を上げる
- 16. AOJトライに関する知識知見の記録共有(Volume0-0036)
- 17. Pythonプログラミング:BeautifulSoup4を使ってlivedoor NEWSからキーワード検索結果のニュースを取得(スクレイピング)してみた
- 18. 【FastAPI】テストケース毎に独立したDBデータを使用する(GitHub Actions付き)
- 19. Error: Session cannot generate requests tensorflow の解決方法
- 20. Python3.7系をwindowsにインストール
# 使い終わった壁紙を自動で削除したい!
# 使い終わった壁紙を自動で削除したい!
「東京ディズニーリゾートの壁紙を毎月自動でダウンロード・設定するプログラムを作った!」と友人に話をしたところ、「昔の壁紙は消えないの??」と聞かれました。
私は何かと記念に残しがちですが、よくよく考えれば確かに要らない気がするので、ダウンロードするタイミングで削除しちゃおうと思います。前回の記事はこちら↓
https://qiita.com/ayk_f/items/40eca2f7376a2b04ce4c
# ざっくりフローチャート
前回の記事で、「今月の壁紙が指定フォルダに格納されていない場合、壁紙をダウンロードする。」という条件分岐を追加したので、壁紙をダウンロードする処理の前に、古い壁紙を削除する処理(オレンジ部分)を追加します。
# 削除対象ファイルのリストアップ
まずは削除対象の
Pythonでエラーが出た時、まずやること
## はじめに
プログラミングにおいて、エラーとの戦いは付き物です。特に最初のうちは、基本的な構文エラーで止まってしまうことが多くあります。このようなエラーを自分で解決できるようになるために、エラーが起きた時にすることをまとめてみました。### 想定読者
Pythonで初めてプログラミングに触れる方
すでに環境は整っているものとします。### 環境
– VisualStudioCode
– Python3.9
– JupyterNotebook(VSCode版)## 1. エラーメッセージを読む
ほとんどのプログラミング言語では、実行時に想定と異なる状況が起きた時エラーが出るようになっています。
(C言語などではその一段階前のコンパイル時にエラーが出る場合もあります)Pythonでは読みやすいエラーメッセージが出てくるので、読んでみましょう。
### よくあるエラー
#### IndexError
リストなどのインデックスがリストの長さを超えてしまった時に出るエラーです。
リストの長さが10のとき、インデックスは0~9の範囲でなければならないことに注意してくだ
【5】辞書型で自販機データを作ろう
# 演習問題
keyに商品名(str型),valueに値段(int型)を代入し
自販機の中身(キーバリューの組み合わせ)が表示され,
「[自分の好きな商品の値段]円を入れてください!」とアナウンスされるアプリを作りましょう.– 辞書型変数名は任意で構いません.※自販機=vendingmachine
– 要素は最低5個以上作りましょう.
HINT:print(str(vm[‘おでん’])+”円を入れてください!”)
print関数内で,数字の型を文字の型として表示させる作業が必須..pyファイルで提出してください!
【出力例】
“`
{‘ラーメン’: 600, ‘おしるこ’: 80, ‘ゼリー’: 100, ‘プロテイン’: 170, ‘おでん’: 200}
200円を入れてください!
“`解き終わり次第,[まなBOX](https://daltontokyo.mana-box.jp/epf-web/Servlet/)にて提出しましょう.演習の提出状況で成績判断をします.
→[次の演習]()へ
#### 演習問題一覧は[こちら]()#引用
[Am
【4】リストの要素同士の計算
# 演習問題
リスト型の変数名を「numbers」とし,1.numbersへ 250, 120, 800, 670, 210を順に代入し,print()を用いて出力しましょう.
2.要素0と要素3の和をnumbers_sum,差をnumbers_diff ,剰余をnumbers_remへ代入し,print()を用いて出力しましょう.
3.要素1の値を190へ書き換え,print()を用いて出力しましょう.
4.numbersの最後の要素へ480を追加し,print()を用いて出力しましょう.これからの演習は,特に指示がない限り .py ファイルで提出してください!
【コマンドでの出力例】
“`
[250, 120, 800, 670, 210]
670
800
250
[250, 190, 800, 670, 210, 480]
“`解き終わり次第,[まなBOX](https://daltontokyo.mana-box.jp/epf-web/Servlet/)にて提出しましょう.演習の提出状況で成績判断をします.
→[次の演習]()へ
#### 演習問題一覧
windows10へ2021年10月10日時点で最新のPython3.10.0で jupyter lab をpipでインストールしようとしたら遅延しまくってはまった件について
最近もっぱらMacbookで開発していて、自作PCのwindows10へはjupyterlabはおろか、pythonすらインストールされていないというとても稀有な環境下からjupyter labのインストールを試みた。
そうしたら、結果的に1日以上の時間を浪費したので備忘録。
ただし、結論から得られた教訓をまず言うと、大切なのは問題解決であって、最新が良いわけではないということ。
問題解決の目標大事。# 経緯
自動売買システム構築やら言語解析のためちまちまとコードを書くためのツールとして、所有する全デバイスにjupyter notebookをインストールしたいと思う。実行環境は自宅PC(windows)やリモート(CentOS)を想定しているので、マシンパワーのあるPCでDockerを動かしてローカルで検証してリモートに投げようかしら。
じゃあ、windowsでも開発できるようにjupyternotebookあったら便利じゃないですか。
よし、インストール!!! (所要時間10秒)
# 遅延にぶつかるまでの流れ
公式サイトから、最新のPythonのインストーラーをゲット
Python機械学習/pickleファイルを使ったオブジェクトの保存
# Summary
Pythonで機械学習をする際のデータやモデルの保存にはpickleファイルを使用するのが非常に便利なので,その使い方についてメモを残しておく.# データの準備
今回はScikit-learnのガンデータを使用.“`py
from sklearn.datasets import load_breast_cancer
import pandas as pdcancer = load_breast_cancer()
data_feature = pd.DataFrame(cancer.data, columns=cancer.feature_names)
data_target = pd.DataFrame(cancer.target)
“`# csvファイルでデータ管理
まずは一般的なCSVファイルでのデータ読み書きについて記す.csvファイルで保存
“`py
data_feature.to_csv(‘data_feature.csv’)
data_target.to_csv(‘data_target.csv’)
“`csvファイルの
Ubuntuに最新バージョンのPythonをインストールする
ubuntu20.04に最新のPython3.10.0をインストールする
###Ubuntuのバージョン確認。
cat /etc/lsb-releaseDISTRIB_ID=Ubuntu
DISTRIB_RELEASE=20.04
DISTRIB_CODENAME=focal
DISTRIB_DESCRIPTION=”Ubuntu 20.04.3 LTS”###アーキテクチャは64bit。
arch
x86_64###ビルド環境の準備
sudo apt update
sudo apt install build-essential libbz2-dev libdb-dev \
libreadline-dev libffi-dev libgdbm-dev liblzma-dev \
libncursesw5-dev libsqlite3-dev libssl-dev \
zlib1g-dev uuid-dev tk-dev###ソースコードのダウンロード
Python Japanのダウンロードページ
https://pythonlinks.python.j
Python3.10 新機能!パターンマッチ構文解説
# はじめに
Python3.10.0 が2021年10月4日にリリースされました。その中でもパターンマッチ構文は大きな機能追加の一つだったため、この記事で解説したいと思います。https://www.python.org/dev/peps/pep-0634/
私が運営しているYouTubeチャンネルの動画内でも解説しているのですが、動画をみるのが苦手、テキストで知りたい、という人向けにQiitaでも記事を投稿することにしました!
# 基本構文
パターンマッチは、あるオブジェクトに対して、どのパターンにマッチしているかを評価して処理を分岐させる構文になります。`match`の後ろに、調べたい対象のオブジェクトを指定して、`case`の後ろにパターンを記載します。例えば、ひとつ目の`case`のパターン1に当てはまった場合は、`case`の中の処理が実施されます。パターンは色々な記載ができるため、いくつか解説していきます。
“`python3:base.py
match 対象オブジェクト:
case
kivyMDチュートリアル其の参什漆 Components – NavigationRail篇
ハロー、Qiita。清秋の候、すがすがしい秋晴れの
今日この頃、いかがお過ごしでしょうか。はいー、先週入れられてなかった時候の挨拶ですが、今週で使ってみました。
合ってますかね、使い方。先日は地震などがありましたが、みなさんはご無事でしたでしょうか。常日頃、
備蓄などはしないといけないなと感じたくらい、身の危険を感じましたね。と、
いってもいざ事が起きたときは何も動けなかったのですが汗というわけで、少し話は脱線しましたがKivyMDの時間は相変わらずオープン
します。今日は、NavigationRail編となります。## NavigationRail
いざ始まるといっても、いつものリンクは飛ばすというのはありますが、今日は
少し重要なこともあるので何点か触れてみます。2点ほどあるのですが、まずは他のナビゲーションと組み合わせてはいけないという
ことですね。他のナビゲーションとしては、先週やったNavigationDrawerともう
1つは以前やったBottomNavigationですね。これらと組み合わせると望ましくない
と書かれてあります。もう1点は、デバイ
Python 基礎
## 目次
1. [基礎文法](#1-基礎文法)
1. [演算子](#2-演算子)
1. [制御文](#3-制御文)
1. [関数](#4-関数)
1. [モジュールとクラス](#5-モジュールとクラス)## 1. 基礎文法
### 基本的なルール
* 文末のセミコロンは不要(つけることもできる)
* {}で処理をまとめるのではなく、インデントで処理をまとめる
* メンバアクセスはドットで行う
* 処理を複数行にまたぐ場合、改行にはバックスラッシュを使用する### 変数
* 「変数名 = 値」で宣言できる
* 「変数名:型名 = 値」で型を明示して変数宣言できる※ただし、実行時に指定型以外の値を入れても、実行時エラーとはならないので注意
型指定はあくまで制作側へのヒント。“`python
# 型指定なし
val = 10# 型指定あり
val:str = ‘あいうえお’
“`### コメント
* 単一行は「#」
* 複数行のコメント機能はないが、3重のシングルクォートorダブルクォートで囲むことで、複数行の文字列扱いにできる“`python
# 単
Pipでuwsgiのインストールが失敗する場合の対処法
# 事象
pipにてuwsgiをインストールしようとしたところ、下記のとおり失敗した。“`
$ sudo pip install -U uwsgi
Collecting uwsgi
Using cached uwsgi-2.0.20.tar.gz (804 kB)
Building wheels for collected packages: uwsgi
Building wheel for uwsgi (setup.py) … error
ERROR: Command errored out with exit status 1:
command: /usr/bin/python3 -u -c ‘import io, os, sys, setuptools, tokenize; sys.argv[0] = ‘”‘”‘/tmp/pip-install-97dwq_9q/uwsgi_24c3a89c34c847b9be2d2f525d846ef6/setup.py'”‘”‘; __file__='”‘”‘/tmp/pip-install-97dwq_9q/uw
【AtCoder】ABC207のA,B,C問題を解く
# PythonでABC207のA,B,C問題を解く
ABC222のA,B,C問題をPython3で解答しています。
簡単な解説はコードの中に記載しています。SNSでの発信も少しずつ始めました。フォローしていただけたらフォロー返してます。。!
[Twitter](https://twitter.com/Edu_ner)[A – Four Digits](https://atcoder.jp/contests/abc222/tasks/abc222_a)
##
“`python:python
# 文字列として受け取り、足りない桁文を足す。
n = input()
length = len(n)
if length == 4:
print(n)
elif length == 3:
print(‘0’+n)
elif length == 2:
print(’00’ + n)
elif length == 1:
print(‘000’+n)
“`
[B – Failing Grade](https://atcoder.jp/conte
Pythonでランダム文字列を生成する
## 結論
こうするとできます。コメントアウトに出力を書いてます。“`python
import random
s = ”.join(random.choices(‘PA’, k=4))
print(s)
# PPAP
“`## 解説
`random.choices(‘PA’, k=4)` で `P`,`A` からランダムにどちらかを4回選んでリストに入れたものを作ります
“`python
import random
print(random.choices(‘PA’, k=4))
# [‘P’, ‘P’, ‘A’, ‘P’]
“``”.join` で文字列のリスト `[‘P’, ‘P’, ‘A’, ‘P’]` を空文字で連結します
“`python
print(”.join([‘P’, ‘P’, ‘A’, ‘P’]))
# PPAP
“`以上
## ちなみに
`string.*` が便利です。`’PA’` の代わりに使うと良いかもしれません。
“`python
import string
print(string.ascii_lowe
pip installをしたときにGitのsubmoduleがインストールされない問題
# はじめに
Github上で開発をしている際に開発しているmoduleとは別のRepositoryのmoduleを利用したい場合があります.
そのようなときに`submodule`を利用します.一方で,単純にsubmoduleを加えるだけだと`pip install`をした際にsubmoduleが追加されないという問題が発生します.その対処法について簡単に説明します.参考:[How to write setup.py to include a Git repository as a dependency](https://stackoverflow.com/questions/32688688/how-to-write-setup-py-to-include-a-git-repository-as-a-dependency/)
# 問題設定
Sphere関数という関数を作成し,それをsubmoduleとして利用したいケースを想定します.
例として[submodule_practice_parent](https://github.com/nabenabe0928/submod
Pillow(PIL)で生成するgifの画質を上げる
## 単刀直入
`im.quantize()` するだけ## はじめに
Pythonの画像処理ライブラリのPillowを使えば、簡単にgifアニメーションを作ることができます。
詳しいことはみんな大好き[note.nkmk.me](https://note.nkmk.me/python-pillow-basic/)に譲りますが、適当に画像を数枚開いてオプションを決めるだけです。“`python:makegif.py
from PIL import Imageim1 = Image.open(“hoge.png”)
im2 = Image.open(“huga.png”)
images = [im1, im2]
images[0].save(‘test.gif’, save_all=True,
append_images=images[1:], optimize=False, duration=500, loop=0)
“`
# 概要
A Figure on Surfacehttps://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=0036
# コード
itertoolsを使用“`
import itertoolsdef matched(area, ptn):
#print(area)
ret = False
if ptn == 0:
if len(area) >= 2 and len(area[0]) >= 2 and area[0][0] == “1” and area[0][1] == “1” and area[1][0] == “1” and area[1][1] == “1”:
ret = True
elif ptn == 1:
if len(area) >= 4 and len(area[0]) >= 1 and area[0][0] == “1” and area[1][0] == “1” and area[2][0] == “1”
Pythonプログラミング:BeautifulSoup4を使ってlivedoor NEWSからキーワード検索結果のニュースを取得(スクレイピング)してみた
# はじめに
前回記事に続き、データ収集に関する投稿です。
1. [ニュースアクセスランキング編](https://qiita.com/Blaster36/items/163333b81398b5bd4af0)
2. [今日のニュース編](https://qiita.com/Blaster36/items/3d02a050f61218679ae0)
3. [話題のニュース編](https://qiita.com/Blaster36/items/f631727cd270abc57993)
4. キーワード検索結果のニュース編 ★本稿今回は、たくさんのニュースに対して、キーワード検索した結果の取得を目指します。
WebブラウザでTop画面を表示した際の、左肩にあるテキストエリアにキーワードを入力して、検索した画面の画面です。
↓↓↓キーワード「**緊急事態宣言 解除**」での検索結果の例↓↓↓

ORMと連携した機能のテストを行う際、テストケース(= テスト関数)毎にクリーンなデータベースが欲しい(**テストケース間の依存関係が生まれてほしくない**)。
この点についていい感じの方法が実現できたためご紹介する。
– 参考(一部重複内容あり)
– [FastAPIでテスト用のクリーンなDBを作成してpytestでAPIのUnittestを行う](https://qiita.com/bee2/items/ff9c86d8d345dbcab497)本記事のソースコード:[skokado/fastapi-tutorial](https://github.com/skokado/fastapi-tutorial)
# 環境
– Python: 3.8
– fastapi==0.68.2
– SQLAlchemy==1.4.25
– SQLAlchemy-Utils==0.37.8
– pytest==6.2.5
– factory-boy==3.2.0# アプリケーション準備
ユーザ認証とブログ管理を行う簡単なアプリケーションを用意する。
※アプ
Error: Session cannot generate requests tensorflow の解決方法
表題のエラーに数時間苦労しました...
もし同様のエラーでお悩みの方の参考となれば幸いです.# ハマりポイント
VScode上で,GPUとTensorFlowを用いて学習させたところ,モデルのトレーニングを行うセルで,突然以下のエラーが発生するようになりました.“`
Error: Session cannot generate requests tensorflow
“`
また,一度このエラーが発生すると,以降はどのセルにおいても同様のエラーが発生するようになります.# 環境
“`
Ubuntu 18.04
VScode 1.61
Python 3.8
Tensorflow 2.5
“`# 解決方法
結論から言うと,無駄なプロセスにGPUメモリが割かれていて,十分なメモリが確保できないことが原因の一つであると考えられます.
そのため,まずは,現在のGPUプロセスを確認してみます.以下のコマンドから,GPUの状況を確認してください.
“`terminal
~$ nvidia-smi -l 1+—————————–
Python3.7系をwindowsにインストール
# 「このインストールはシステムポリシーで許可されていません」とエラーが出る
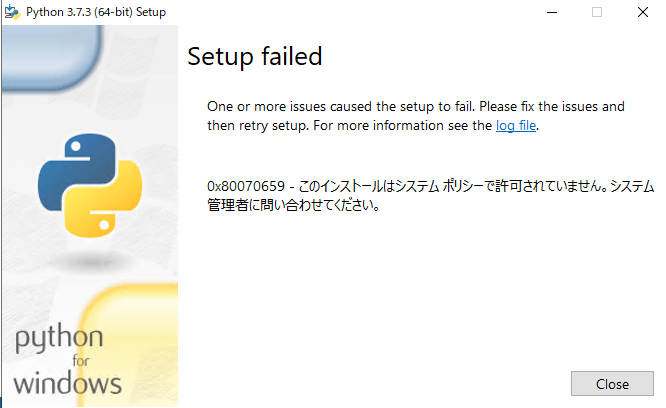# 対処方法
以下サイトにある通り、MAX_PARHの除去が必要らしい
https://docs.python.org/ja/3.7/using/windows.html#removing-the-max-path-limitation## 1.MAX_PATHをレジストリエディターから除去
https://knowledge.autodesk.com/ja/support/autocad/troubleshooting/caas/sfdcarticles/sfdcarticles/JPN/The-Windows-10-default-path-length-limitation-MAX-PATH-is-256-characters.html
以下のように




