
- 1. 【Python】Djangoで作ったアプリをHerokuにデプロイ
- 2. Python3.10でのマルチスレッド動作について
- 3. VSCodeでPythonのプロセスにattachしてdebugできないとき
- 4. Ubuntu20.04でpip install mysqlclientがエラーが出る場合の解決方法
- 5. LISの復元 (辞書順の最小となるLISを求める)
- 6. Equalumで多段のデータパイプラインを1時間以内でノーコード作成する!(その3)
- 7. Equalumで多段のデータパイプラインを1時間以内でノーコード作成する!(その2)
- 8. Equalumで多段のデータパイプラインを1時間以内でノーコード作成する!(その1)
- 9. Python + Beautiful Soupスクレイピング
- 10. 疑似親友、作りました。
- 11. 【Django】REST frameworkでプロジェクトにデータPOSTしてくるクライアントのIPアドレスをDBに格納する(続)
- 12. コンピュータとオセロ対戦21 ~データ分析~
- 13. 米国株のポートフォリオをMatplotlibで視覚化
- 14. Python multiprocessing
- 15. Python初学者のまとめ
- 16. 初心者がkerasを使った画像分類でメモリエラーに直面したときの対処法(サーベイ中心)
- 17. 【第一回】YOLOv3を一から実装 ~チュートリアル~
- 18. UTF-8じゃないの?Pythonの文字列処理で火傷を防ぐ
- 19. djangoのルーティングをざっくりとまとめてみた
- 20. CURP CUrrent Calculation of Protein の導入でつまずいて解決した点【Ubuntu(GNOME)編】
【Python】Djangoで作ったアプリをHerokuにデプロイ
#はじめに
Djangoで作ったアプリケーションをHerokuを使ってデプロイする方法。開発環境
・mac os
・Django==3.2.6
・python==3.9.1
・Heroku CLIインストール済#Heoku上にアプリケーションを作成・gitの紐づけ
Ⅰ. herkou上にアプリケーションを作成
“`
$ heroku create myherokuapp
“`
Ⅱ.Git URlの確認“`
$ heroku info –app myherokuapp
Git URL: https://git.heroku.com/myherokuapp.git
“`
Ⅲ. Gitの紐づけ“`
$ git remote add heroku https://git.heroku.com/myherokuapp.git$ git remote -v
heroku https://git.heroku.com/myherokuapp.git (fetch)
heroku https://git.heroku.com/myherokuapp.gi
Python3.10でのマルチスレッド動作について
Pyhtonのマルチスレッド周りで実験をしていたところ,
Python3.10より動作が変わった?点があったのでメモしておきます。**注意: 私の環境での結果をメモしただけです。**
**ソースレベルでの調査やリリースノートの確認はしていません。**
**詳しい情報があれば教えてください**
後日調査して内容をアップグレードする予定です.(時間があれば)### 大前提
PythonはGILがありマルチスレッドで実行しても,
GILにより実行されるスレッド数は常に1スレッドに限定されます.
ただし, 各動作がアトミックに行われるわけではないため, スレッドセーフではありません.
**意図せぬ競合を起こさないため, クリティカルセッションでは必ずWith構文を用いたロックをしましょう**### 本題
GILの確認のためマルチスレッド処理を実験してみたところ,
Python3.9.6とPython3.10.0で動作が異なったのでメモしておきます.#### 環境
– RaspberryOS 64bit
– Python3.10 (64bit)
– Python3.9.6
VSCodeでPythonのプロセスにattachしてdebugできないとき
VSCodeではすでに起動しているPythonのプロセスをデバッグすることができます。Jupyter Notebookで実行しながらデバッグする際によく用いられます。
https://qiita.com/k_maki/items/475f6be71279cffdd909
先日リモートのUbuntu 20.04のサーバー上のプロジェクトをこの方法でデバッグしようとしたところ、プロセスにattachできずにタイムアウトするという問題がありました。
Githubのissueに上げたところ
https://github.com/microsoft/debugpy/issues/771
Ubuntu 10.10以降からrootユーザー以外は子プロセス以外にはattachできなくなったそうなのでそのオプションを無効にすれば解決しました。
https://askubuntu.com/questions/41629/after-upgrade-gdb-wont-attach-to-process/41656#41656
Ubuntu20.04でpip install mysqlclientがエラーが出る場合の解決方法
# pip install mysqlclientが動かないとき
MySQLにアクセスするために使うmysqlclientですが、うまく動かないとき、“`
$ sudo apt-get install -y libmysqlclient-dev
“`そのあと、
“`
$ pip install mysqlclient
“`でうまく動きました。
LISの復元 (辞書順の最小となるLISを求める)
対象読者:DPで解くLISは分かる。けど、復元の方法がわからない。
今回の記事は、peroonさんの記事のソースコードを参考にしています。
https://perogram.hateblo.jp/entry/2019/07/27/051604# やりたいこと
長さ$N$の数列$A = a_{0}, a_{1}, \cdots, a_{N-1}$の最長増加部分列 (LIS: Longest Increasing Subsequence) のうち、辞書順最小であるものを出力してください。
数列Aの最長増加部分列は、$0 \leq i_0 < i_1 < \cdots < i_k < n$とするとき、、$a_{i_0} < a_{i_1} < \cdots < a_{i_k}$を満たすうち、$k$が最も大きいものです。 ※つまり、狭義単調増加(厳密に増加する)のLISを考えます # 間違った考察: DPテーブルだけで結果を求める `[7,8,9,4,5,6]`という入力を考えると、LISは`[4,5,6]`か`[7,8,9]`が考えられます。LISをDPで計算した直後のDP配列は
Equalumで多段のデータパイプラインを1時間以内でノーコード作成する!(その3)
###今回は、多段構成の後半部分をノーコードで作成し、全体を完成させた後に実際の動作検証を行います。
前回は、実際にストリーミング処理を行う部分のFLOW定義をGUIベースの専用環境で行い、そのノーコード作業の流れを簡単に紹介させて頂きました。
Equalumの処理的には、前回までの完成部分だけでも世間一般で言われている様な「サイロの壁問題」を、圧倒的にシンプルに解消出来る「誰でも作れる統合テーブル」を処理する事は可能です。
しかし、第1回目に掲げた多段構成を含めて「目標1時間以内」という事ですので、引き続き頑張って行きたいと思います。##今回の構成概要を少し現実的な状況にすると・・
1回目に今回のEqualum構成概要を説明させて頂きましたが、今回は最終回ということですので「少しリアルな感じ」に書き直してみました。

###今回は、前回のKafka部分をノーコードで処理した、データパイプライン接続設定を使って具体的なFLOWをノーコードで作成していきます。
前回は、KafkaとSPARKに関する作り込み部分を、簡単なGUIベースの設定画面処理だけで完了出来るEqualumのノーコード機能を検証しましたが、今回は前回設定したテーブルのCDC連携機構を使って、その先のFLOW処理を幾つか付け加えたリアルタイムストリーミング処理をノーコードで作成してみたいと思います。
##まずは、GUIベースのFLOWデザイナーを起動する。
Equalumのコンソールに戻って、左から2番目の**FLOWS**を選択します。
FLOWの編集画面になるので、マウスを使って必要な処理を設置・定義していきます。
」が面白かったので真似して作ってみました。
# 疑似親友とは
良いこと(ポジティブ発言)に対して一緒に共感してくれて、嫌なこと(ネガティブ発言)に対しては励ましてくれて、それ以外に対しては適当な相槌を打ってくれて、向こうからは全く何も言ってこないとても ~~都合のいい~~ 素晴らしい親友です。# 疑似親友の構成
作りとしてはLINE Messaging APIで受けたテキストをAWS API Gateway経由でAWS Lambdaに渡しAmazon ComprehendでテキストをPOSITIVE(ポジティブ)、NEGATIVE(ネガティブ)、Neutral(中立)、Mixed(混在)の4種類に分類、その結果を元に返信メッセージを作成するという構成になります。
感情分析に関しては以前自分で作成した[Pythonで感情極性辞書を用いたテキスト感情分析をつくってみた](https://qiita.com/miso_taku/item
【Django】REST frameworkでプロジェクトにデータPOSTしてくるクライアントのIPアドレスをDBに格納する(続)
#はじめに
タイトルの通り[【Django】REST frameworkでプロジェクトにデータPOSTしてくるクライアントのIPアドレスをDBに格納する](https://qiita.com/masaoguchi/items/a8e0b4bdb7085d3cb0a0)の続きです.
前回の記事では,「DjangoのREST frameworkを使ってクライアントのIPアドレスも取れるようになりました.」的なことを書きました.でも,みなさんの手元で本当にできるのかを確認する方法を言ってなかったなと思って続きを書いております.#結論
**「Advanced REST client」**というGoogle Chromeの拡張機能を使って実際にPOSTして確認します.DjangoのDB内にlocalhostのIPアドレスが格納されていることを想定して説明していきます.#確認手順
###環境
macOS Catalina 10.15.7
Python 3.8.5
Django 3.2.8
djangorestframework 3.12.4###前提
※[前回の記事](https://
コンピュータとオセロ対戦21 ~データ分析~
https://qiita.com/tt_and_tk/items/068f2afde6db637e189f
[前回](https://qiita.com/tt_and_tk/items/e46cbbd0dc6f9f841003)
# 今回の目標
[前回](https://qiita.com/tt_and_tk/items/e46cbbd0dc6f9f841003)作成したプログラムの実行結果について分析します。
# ここから本編
pnadasとmatplotlibを使い、いろいろな条件でのデータを見てみます。
今回、ipynbでやってみたところpandasとの相性抜群に感じましたのでこれからはipynbでやっていきたいと思います。
まずこんなプログラムを書きました。拡張子が「.py」になっていますが実際は「.ipynb」で、二つのセルに分けて書かれています。“`data.py
import pandas as pd
import matplotlib.pyplot as pltdf = pd.read_csv(“data.csv”)
generation = df[“g
米国株のポートフォリオをMatplotlibで視覚化
##結論
###入力
辞書型
portfolio = {“TSLA”:[300],”AAPL”:[903],”GOOG”:[255],”MSFT”:[999],”AMZN”:[200]}###出力
円グラフと最新価格のデータ、そして現在の合計資産
円グラフの%は保有金額ベース

“Variable check okay.
TSLA’s current price : 1018.43
AAPL’s current price : 149.32
GOOG’s current price : 2793.44
MSFT’s current price : 310.11
AMZN’s current price : 3376.07
Your current total asset : 2137706 US Dollars.
“##ポ
Python multiprocessing
# Python multiprocessing で CPU 論理コア総動員で処理させる
## 環境
– Ubuntu 18.04.4 LTS / Python 3.6.8
– macOS Monterey 12.0.1 / Python 3.8.5multiprocessing は Python に最初から入っているパッケージなので、別途 install 不要。
### 論理コア数 確認
“`
import multiprocessing
multiprocessing.cpu_count()
“`### 時間のかかる処理を並列で実行するテンプレ
`論理コア数12の場合`“`
import multiprocessingdef run(process_count, process):
if process == 0:
print(‘completed’, process)
elif process == 1:
print(‘completed’, process)
elif process ==
Python初学者のまとめ
#本体のインストール
###■Windows10
1. [公式サイト](https://www.python.org/)よりダウンロード
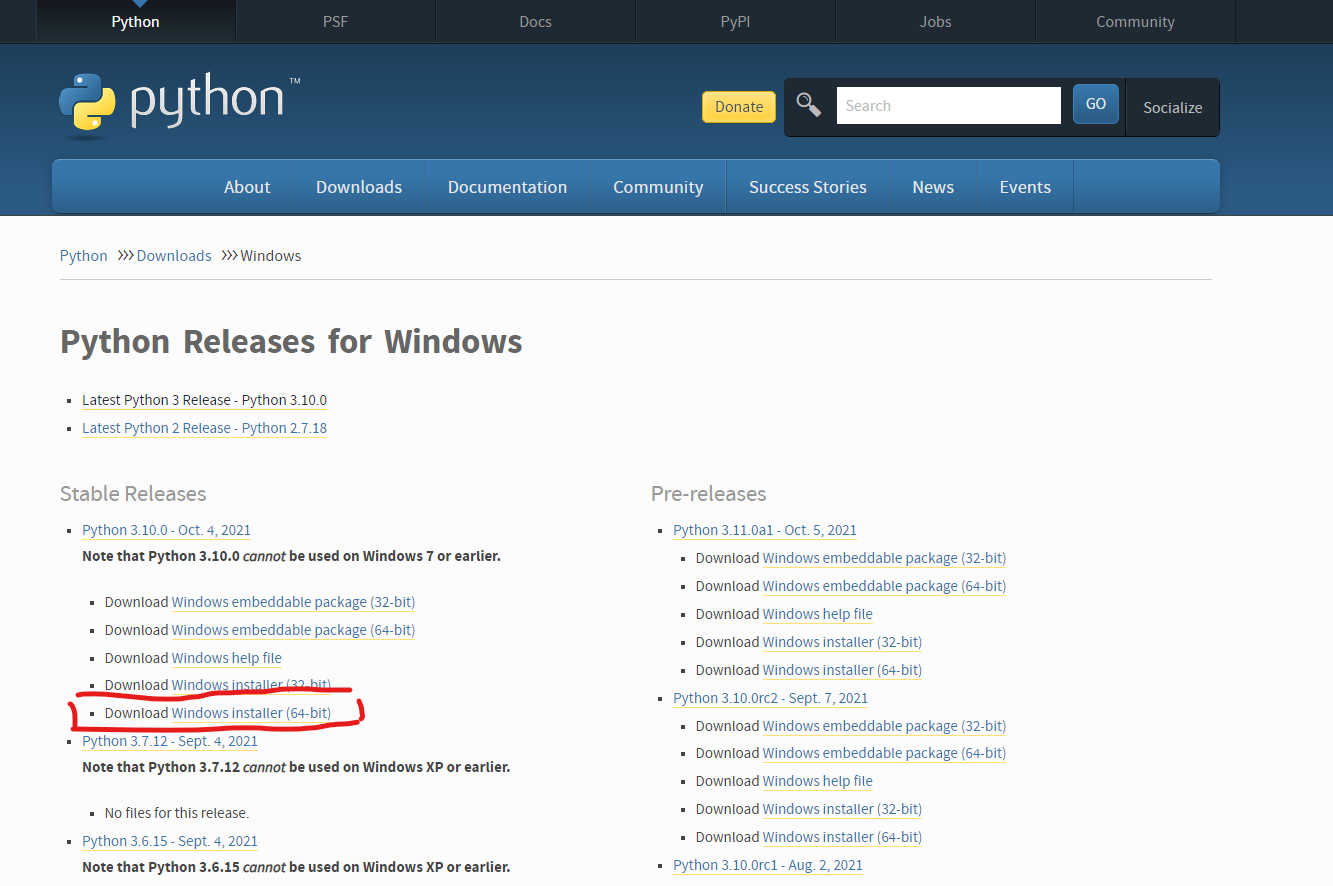2. Add Python 3.x to PATHにチェックを入れてInstall Now押す
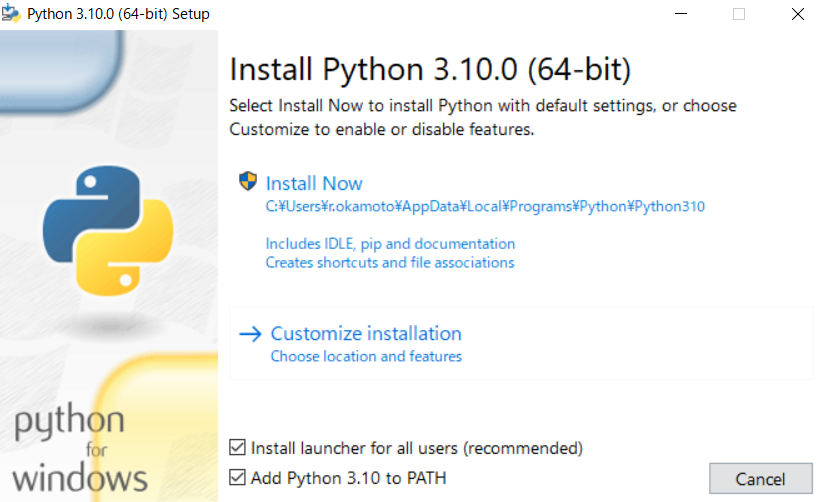
3. 確認デフォルトでは`C:\Users\{ユーザ名}\AppData\Local\Programs\Python`にインストールされる
“`plaintext:
C:\Use
初心者がkerasを使った画像分類でメモリエラーに直面したときの対処法(サーベイ中心)
# なぜこんな問題に直面したのか?
現在、会社の自己啓発プロジェクトの一環として、機械学習初心者数人で、kaggleの[cassava classification](https://www.kaggle.com/c/cassava-leaf-disease-classification)のプロジェクトにトライしております。
pythonはここ一年でようやく慣れてきましたが、画像データを取り扱うのは初めてでなかなか不慣れなことが多いです。
同プロジェクトでCNNについての輪講を実施したので、使ってみようと思っていたのですが、“`
MemoryError
“`(‘Д’)
大量の画像データなんて扱ったことないし、所詮数値データなんだからnumpyに直してしまえば全部読み込めるだろうと思っていたのですが、2万枚というレベルになるとなかなか厳しそうですよね。ということで、自分なりに考えたり調べたりした結果を共有しようと思います。# 実際にはどのくらいのサイズになるのか?
ざっくり全部展開するとどのくらいになるのか計算してみます。
| 項目|値 |
|:-:|:-:|
|
【第一回】YOLOv3を一から実装 ~チュートリアル~
# YOLOとは
YOLOとは物体検出(画像内の物体の位置と種類を検出)の機械学習モデルで、2015年にJoseph Redmon氏が論文を発表しました。Joseph Redmon氏がv3で制作を引きましたが、現在でも積極的に開発が進められており、2021年10月現在v5まで出ております。ただしYOLOv4はYOLOv3にSPP(Spatial pyramid pooling)やPAN(Path Aggregation Network)といった技術が追加されたもので、YOLOv5に関しては論文が出ていないため、今さら感も否めませんが今回はYOLOv3を実装を解説していきたいと思います。# YOLOv3の構成
YOLOv3のモデル構造について説明していきます。ちなみに元の論文の条件から入力画像は416×416pxのRGB画像、検出対象のクラス数(b種類)は80として説明を進めていきます。YOLOv3のめちゃくちゃざっくりとした構成は以下のような図になります。
](https://github.com/Soliton-Analytics-Team/BytePos/) [](https://colab.research.google.com/github/Soliton-Analytics-Team/BytePos/blob/main/BytePos.ipynb)
ご覧いただきありがとうございます。[ソリトンシステムズのセキュリティ分析チーム](https://www.soliton-cyber.com/)です。
Google Colaboratoryにアカウントをお持ちの方は、上の「Open in Colab」という青いボタンを押せば直接notebookをC
djangoのルーティングをざっくりとまとめてみた
今回のお題
–
今回は、djangoのルーティングについてまとめます。
ルーティングファイルが2層構造になっていたり参考にした書籍と現在のトレンドが違ったり(書籍ではurlを用いていたが現在はpathが主流)と所々混乱する要素があったので、記事にすることで自分の頭を整理したいと思います。目次
–– djangonにおけるルーティングの概要
– プロジェクトフォルダのurls.pyの記述
– アプリケーションフォルダにおけるurls.pyの記述
– 終わりにdjangoにおけるルーティングの概要
–
djangoでは、ルーティングの定義に以下の2つのファイルが関わります。– プロジェクトフォルダのurls.py
– アプリケーションフォルダのurls.py名前が同じなのがややこしいですね。
役割分担としては、まずプロジェクトフォルダのurls.pyがリクエストのurlに応じて適切なアプリケーションのurls.pyを呼び出します。
その後、呼び出されたアプリケーションのurl.pyがリクエストに対応した関数をviews.pyから呼び出すという流れになります。
では
CURP CUrrent Calculation of Protein の導入でつまずいて解決した点【Ubuntu(GNOME)編】
#はじめに
Molecular Dynamicsを用いてアミノ酸配列からタンパク質の計算をする CURP CUrrent Calculation of Protein というプロジェクトがある。>CURP CUrrent Calculation of Protein
http://www.comp-biophys.com/yamato-lab/curp.html>[Github] CURP CUrrent Calculation of Protein
https://github.com/yamatolab/current-calculations-for-proteinsお試しで使っていみようと思い導入したが、かなりのエラーに出くわしたので備忘録にもと思い過程を記す。以下、環境はUbuntu(GNOME)を想定しています。
#導入環境
筆者は以下の環境で導入した。
– OS: Ubuntu 20.4LTS
– パッケージ管理: dpkg (いやこれは明記せんでええんよっ)
– Python: 2.7.18
– 仮想環境: virtualenv 20.9.0ドキ




