
- 1. Python3: psycopg2 のエラー対策
- 2. Treat of Ticks ~軸目盛りにいたずらするぞ~
- 3. 【Python】最大長が決まっているqueueが欲しい時は
- 4. kivyMDチュートリアル其の肆什 Components – Tabs篇
- 5. 【Python】2次元リストの行と列を入れ替える(転置する)
- 6. JupyterLab Desktop Appのインストールで困ったこと
- 7. Ubuntu18.04 + pyenv + pipenv + Django + Apache2 なデプロイ その0
- 8. Pythonで開発をするための準備
- 9. SharedMemoryを使ってnumpy配列を共有しmultiprocessing.Poolで並列処理する
- 10. AOJトライに関する知識知見の記録共有 (Volume0-0041)
- 11. 自然言語処理で日本語の学術要旨(日本アミノ酸学会)を分類分けする。その1
- 12. 仮想環境のJupyter上で異なる仮想環境のカーネルを使う
- 13. 【業務効率化】フォルダ内のファイルを自動的に合体させる方法~非エンジニアメモ
- 14. コマンドを打つとチャンネルを作ってくれるdiscordbotをPythonで作ろう #2
- 15. Python3.10でのマルチスレッド動作について
- 16. 【AWS】boto3を使ってS3でフォルダを作成する方法
- 17. Python初学者のまとめ
- 18. 資産のドローダウン率・ドローダウン期間を出す[Python]
- 19. C# Python インストール確認 ライブラリ確認
- 20. Photoshop 形式のファイルから RichText を取り出して HTML と CSS に変換する – 後編
Python3: psycopg2 のエラー対策
PostgreSQL に接続するライブラリーの psycopg2 を使っていてエラーが出た時の対策です。
Ubuntu 21.10 での対策です。エラーメッセージ
“`text
FATAL: Peer authentication failed for user
“`次のファイルを編集します。
変更前
“`text:/etc/postgresql/12/main/pg_hba.conf
(省略)
local all all peer
“`変更後
“`text:/etc/postgresql/12/main/pg_hba.conf
(省略)
local all all trust
“`PostgreSQL の再起動
“`bash
sudo systemctl restart postgresql
“`
Treat of Ticks ~軸目盛りにいたずらするぞ~
# 内容
`matplotlib`で`ax.imshow(img)`をするときに、軸目盛りを調節します。“`python
import matplotlib.pyplot as plt
import numpy as npimg = np.random.random((100,100))
fig, ax = plt.subplots()
ax.imshow(img)
plt.show()
“`
この状態だと、x軸目盛り、y軸目盛りはそれぞれ要素数になっています。
ここから、y軸目盛りをいじっていきます。
手順としては、* `ax.set_ytick()`を用いて目盛りをつける要素番号を指定
* `ax.set_xtick()`を用いて目盛りの各値を指定この際、それぞれのメソッドに与える配列の長さは揃えます。
“`pyt
【Python】最大長が決まっているqueueが欲しい時は
Pythonでqueue構造を使うにはqueue.Queue()があります。
しかし、これはqueueの長さを一定までにして、それを超える場合には古いものからdequeしたい場合には少々面倒です。
[リファレンス](https://docs.python.org/ja/3/library/queue.html)によると
queue.Queue()の引数で最大長が決められますが、queueがいっぱいの時は例外を送出し、
新規挿入はqueueが空くまでブロックするようです(待機させる)。
また、現在の要素数を得ようとしてもQueue.qsize()というメソッドはありますが、これは長さの近似値を返すのみです。
長さを一定にしたい場合はかなり処理が面倒になります。#ではどうするか
collections.deque()を使うと、すぐに今回ほしい形のqueueが得られます。“`python:dequeの例(最大サイズ3)
import collections
q = collections.deque([], 3)for i in range(5):
q.append(i
kivyMDチュートリアル其の肆什 Components – Tabs篇
ハロー、ワールド!みなさん開発してますか?(言い方としてはセコムのように)
はい、ということで今日も懲りもせずKivyMDのお時間が参りました。ちょっと使い方は
違うのですが、前に失敗して痛い目をして繰り返すという意味においては間違いではなか
ろうかと思います。https://www.weblio.jp/content/%E6%87%B2%E3%82%8A%E3%82%82%E3%81%9B%E3%81%9A
今週のニュースはというと、やっぱり選挙のことではないでしょうか。このページも投稿
するころにはもう結果も出ているのではと推測するばかりです。そんなことはないかな。
結果の方も注目したいところです。ITエンジニアに勤務助成金とか出すよと言っている
党にはすぐさま投票したいばかりです。ほんと出ないかなぁ。馬鹿なことを言っていますが、助成金を獲得できるためにも(無理)私たちはガリガリ
コードを書くしかありません。ということで今日も元気にやっていきましょう。今日は
タイトルにもある通り、Tabs篇となります。## Tabs
一旦気持ちを震わせてはいましたが、マテリアルデ
【Python】2次元リストの行と列を入れ替える(転置する)
#概要
競技プログラミング中に必要なり、調べてみました。
2次元リストの行と列を入れ替える(転置する)には、リストのアンパックと組み込み関数のzip()をうまく使います。
zipは組み込み関数なので何かをimportする必要はありません。
実際のコードは以下のようになります。“`python:zipの使用例
#元のリスト
list_org = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
print(list_org)#転置
list_transposed = [list(x) for x in zip(*list_org)]
print(list_transposed)
“`出典:
nkmk note様https://note.nkmk.me/python-list-transpose/
#解説
“`python
list_transposed = [list(x) for x in zip(*list_org)]
“`
の行が転置を行っています。
*list_orgのようにリストの前にアスタリスクをつけると「アンパック」という処理が行
JupyterLab Desktop Appのインストールで困ったこと
#1 はじめに
JupyterLab Desktop App([紹介ページ](https://www.publickey1.jp/blog/21/jupyterlabjupyterlab_apppython.html))をインストール後、アプリを実行すると以下のエラーメッセージが出た。この解決策(自分の場合)を備忘録として残す。**[エラーメッセージ]**
#2 現象の説明
* JupyterLab Desktop App を以下のサイトを参考にインストールした。
* このときのインストール環境は以下のとおり
| 項目 | 内容 |

Ubuntu18.04 + pyenv + pipenv + Django + Apache2 なデプロイ その0
ローカルではゴリゴリに動いているDjangoアプリケーションをデプロイするときに,何度も何度も失敗して悲しい思いをしたので自分用にまとめます.お察しの通りあんまりLinuxサーバに詳しいわけではないので,間違ってオジャンにしても責任取れません.悪しからず.
さくらVPSを利用して環境構築していきましょう.
タイトルにもある通り,Ubuntu18.04をインストールしてあり,Windows10からTeraTermで接続します.
さくらVPSのダッシュボードからサーバーにOSをインストールする時のナンチャラ=カンチャラはデフォルトのままでOKだと思います.結構長くなったので分けて書いていきます
[その1](https://qiita.com/drafts/633055f69503aec96156/)# いつもの
“`
ubuntu@:~$ sudo apt update
ubuntu@:~$ sudo apt upgrade
“`# rootユーザーにプレインパスワードで接続し続けるのは絶対ダメ!
玄関のドア全開で,家の鍵を玄関のど真ん中に置いたまんまにしとくぐらい危ない
Pythonで開発をするための準備
いざPythonで開発をしてみようと思った時に準備したまとめ。
# 環境– OS: macOS 12.0.1
– Shell: zsh#1. Pythonのバージョン確認
Macには標準でPython2とPython3がインストールされています。
過去の経緯などでPython2を使う必要がある人もいることを考慮してくれているのだろうか。
これから触り始めるのでここではPython3向けに進めます。“`:python3
$python3 –version
“`
これでバージョンが調べられます。“`:結果
Python 3.8.9
“`ちなみに、Python2のバージョンを調べたい時はpython3の部分をpythonに変えればOK。
#2.Pythonライブラリのアップデートとインストール
PyPI(Python Package Index)からライブラリをインストールするためにpipといるツールを使用します。ターミナルからpipコマンドを実行するのですが、使用している環境ではpipはcommand not foundになります。この環境ではpipで
SharedMemoryを使ってnumpy配列を共有しmultiprocessing.Poolで並列処理する
# はじめに
Python3.8から`multiprocessing.shared_memory.SharedMemory`をつかってプロセス間でのメモリ共有が可能になっている。メモリ共有したnumpy配列を`multiprocessing.Pool`を使って並列処理する方法を記載する。
以下記事を一部参考にした。そこでは`mulriprocessing.Process`を使う場合について記載しているが、ここでは`multiprocessing.Pool`を使う場合についてが主な話題となる。
https://atsuoishimoto.hatenablog.com/entry/2019/09/09/082554
# 準備
共有するnumpy配列は`np.uint8`型で1000行1000列の行列とする。
このとき確保する共有メモリの大きさは、1000 x 1000 x np.uint8型の大きさであり次の`sz`値となる。“`python
import numpy as npsz = np.prod ( 1000, 1000, np.dtype ( ‘uint8’
AOJトライに関する知識知見の記録共有 (Volume0-0041)
# 概要
Expressionhttps://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=0041
# コード
TIPS:再帰処理により可変長引数に対応“`
import itertoolsdef apply_op(op, args):
a, b = args[:2]
if op == “+”:
return a + b
elif op == “-“:
return a – b
elif op == “*”:
return a * bdef gen_list_histresult(hist, args):
if len(args) == 1:
return [[hist, args]]
else:
ret = []
for v in itertools.permutations(args):
for op in [“+”, “-“, “*”]:
自然言語処理で日本語の学術要旨(日本アミノ酸学会)を分類分けする。その1
#背景
[日本アミノ酸学会第15回学術大会](https://15th-jass2021.com/program/)にて自然言語処理を応用した発表をおこないました。内容は日本「アミノ酸学会の要旨(約30年の要旨約900報)をPython使って分類してみたら、学会の発表内容の変遷が分かってきたよ」というものです。これほど多量かつ専門用語が盛りだくさんのコーパスで自然言語処理することはとっても稀有な体験なので私も勉強になりました。学会に参加した方がコードを見たいということなので紹介させていただきます。詳細データをお示しすることができないため、**学会に参加していない方は意味不明な記事になってしまうことをご了承ください。**#作業環境
windows10のpython3.7.1です。#全体の流れ
以下のような順序で作業を実施したのですが、今回は一番の肝になる後半の「研究要旨の高次元ベクトル化、次元削減とクラスタリング」の部分をご紹介します。大部分はQiitaの[SCDV法に関する記事](https://qiita.com/fufufukakaka/items/a7316273908a
仮想環境のJupyter上で異なる仮想環境のカーネルを使う
#概要
* Jupyter labを立ててる仮想環境上で、違う仮想環境のカーネルを使う作業環境
>* python3.8
>* venv
>* Windows PowerShell(基本的なコマンドは環境で変わりません)#はじめに
カーネルを追加する際に、ちょっと戸惑ったので備忘録として残しておきます。
どのサイトも割と`pip`で`ipykernel`を追加する記載しかなかったので、初めての人向けに紹介したいと思います。参考サイト
>* [Jupyter Notebookでカーネルを増やそう](https://qiita.com/SaitoTsutomu/items/a3d27a2de1ff3e762771)#メイン
まずは、新たにカーネルを追加した仮想環境上で`jupyter`をインストールします。
`jupyter`をインストールすると`ipykernel`も入ってるので、個別にインストールする必要がなくなります。
また`ipykernel`だけインストールしても、もちろんエラーを吐くので、個人的には`jupyter`のインストールだけのほうが楽ですね。“
【業務効率化】フォルダ内のファイルを自動的に合体させる方法~非エンジニアメモ
# モジュールのインポート
“`
import glob
import os
“`# 空のDataFrameを定義
“`
df = pd.DataFrame(columns= [])
“`
# .csvを含むファイル全てをpd.read_csv()で読み込む
“`
for i in glob.glob(“*.csv”):
tmp_df = pd.read_csv(i,encoding=”cp932″,low_memory=False)
df = pd.concat([df,tmp_df]) # DataFrameを連結する
“`
コマンドを打つとチャンネルを作ってくれるdiscordbotをPythonで作ろう #2
[前回](https://qiita.com/confrict/items/101a0fb273d3f275af53)の続きです。
# メッセージを受けた上でのアクション
次は、Message内での特定のメッセージに反応するプログラムを書いてみましょう。`!` や `;;` などではじめるbot機能は皆さん使ったことがあると思います。
この文字を Prefix といいます。これについてのコードを書くと長くなるので使わないやり方を説明します。(それを使ったサイトもいつか作ろうと思います。)“`python
@client.event
async def on_message(message:discord.Message):
if message.content.startswith(‘.txt’):
:
:
“``on_message(message:discord.Message)` は
### 大前提
PythonはGILがありマルチスレッドで実行しても,
GILにより実行されるスレッド数は常に1スレッドに限定されます.
ただし, 各動作がアトミックに行われるわけではないため, スレッドセーフではありません.
**意図せぬ競合を起こさないため, クリティカルセッションでは必ずWith構文を用いたロックをしましょう**### 本題
GILの確認のためマルチスレッド処理を実験してみたところ,
Python3.9.6とPython3.10.0で動作が異なったのでメモしておきます.#### 環境
– Ubuntu 64Bit(x86-64), RaspberryPiOS 64bit(Aarch64),
【AWS】boto3を使ってS3でフォルダを作成する方法
boto3を使ってS3でフォルダを作成する方法です。(備忘録として)
“`python
import boto3 #boto3インポートdir = ‘hoge/fuga/’ #ディレクトリパス
bucket_name=’your_buket_name’ #S3のバケット名
s3 = boto3.client(‘s3’)
result = s3.list_objects(Bucket=bucket_name, Prefix=dir) #ディレクトリを変数にif not “Contents” in result: # ディレクトリがない場合はContents というキーが存在しない。これを使えば存在判定ができる。
s3.put_object(Bucket=bucket_name, Key=dir) #ディレクトリ作成
“`# 参考にした記事
https://intellipaat.com/community/41744/using-boto3-how-can-i-create-a-folder-inside-s3
https://qiita.com/ra
Python初学者のまとめ
#本体のインストール
###■Windows10
1. [公式サイト](https://www.python.org/)よりダウンロード
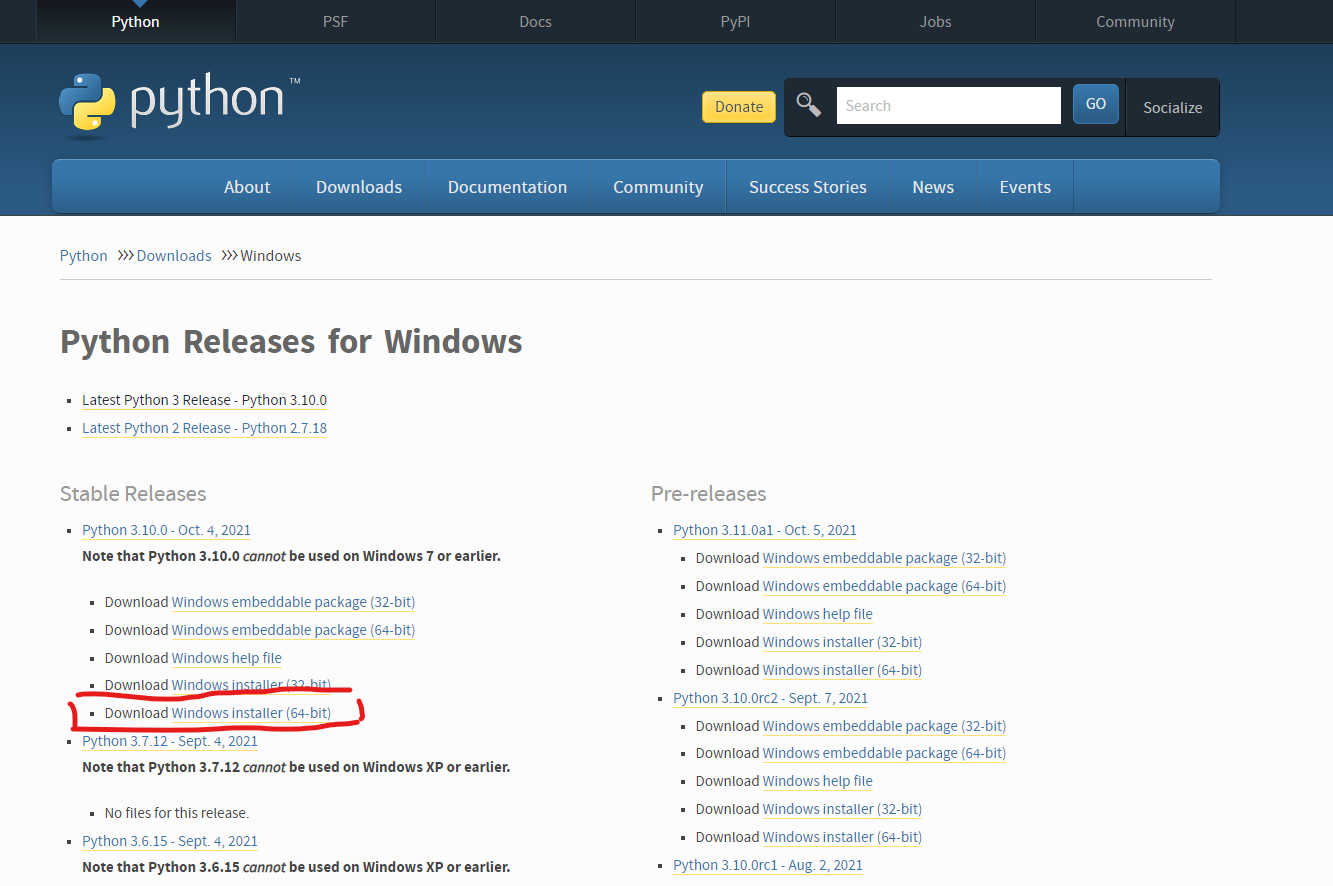2. Add Python 3.x to PATHにチェックを入れてInstall Now押す
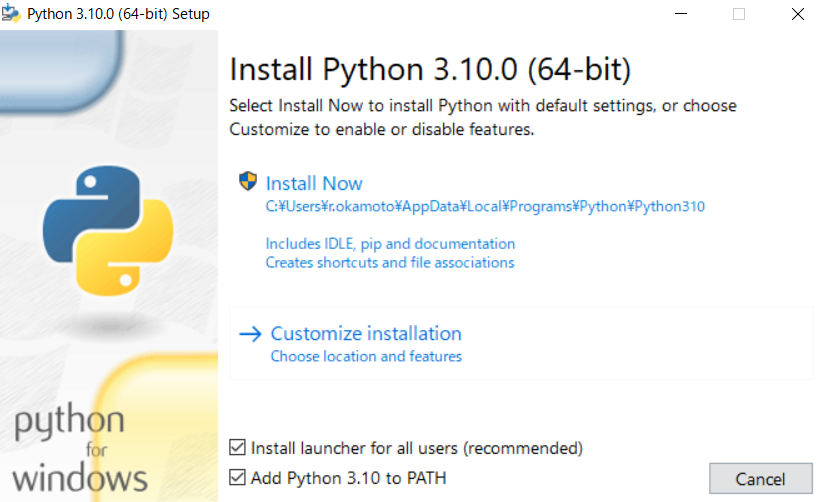
3. 確認デフォルトでは`C:\Users\{ユーザ名}\AppData\Local\Programs\Python`にインストールされる
“`plaintext:
C:\Use
資産のドローダウン率・ドローダウン期間を出す[Python]
# はじめに
トレーディングシステムのバックテストで、資産のドローダウン期間の平均を求めたくなりました。いろいろ調べてみたところ、最大ドローダウン率を出すプログラムはあるけれど、個々のドローダウン期間を出すプログラムって案外見つからないんですよね。
そこで自分で実装してみました。
# 環境
* Python 3.9.5# コード
“`Python:sum_model.py
def calc_drawdown(input):
“””calc drawdown listArgs:
input [list]: 資産推移Returns:
[list]: [(ドローダウン率, ドローダウン期間, ドローダウンが始まった箇所のインデックス), …]
“””hist = input + [float(“inf”)]
dd = [] # 結果
down_start_price = 0 # ドローダウン開始時の資産&ドローダウン突入のフラグ
down_strat_d
C# Python インストール確認 ライブラリ確認
C#からPythonのインストールとライブラリの導入確認をします。
これによってC#からPythonのアプリケーションを適切に起動したりできます。
今後これらを使いC#からPython機械学習アプリケーションを呼び出して、
連携をしていこうと考えているところです。## 動作環境
Windows 10
Python 3.6.4 Anaconda, Inc.
(環境変数にpythonは追加済み)## フォルダ構成
“`
AppDir
|_ python
|_ import_check.py (import確認したいライブラリを記載)
|_ app.exe (PythonチェックをするC#アプリケーション)
“`## ソースコード
### Python (import確認用)
importできるか確認したいライブラリをまとめて記載“`python:import_check.py
import pandas
import numpy
import opencv
# 他に適宜追加
“`### C# (Pythonチェックアプリケーション)
Photoshop 形式のファイルから RichText を取り出して HTML と CSS に変換する – 後編
[前編](https://qiita.com/Kazuya_Murakami/items/ce7a9cc123510798cefd)からの続きです。
psd-tools を利用したスクリプトを実行し、
リッチテキストとして取り出したい PSD (PSB) ファイルを指定すると、HTML+CSS のソースコードと CSV ファイルが作成されるという内容です。ちなみに、PSD (PSB) ファイルに変更を加えることはありません。
## 動作環境
+ Python 3.5 以上
+ psd-tools-1.9.18(インストール手順は[前編](https://qiita.com/Kazuya_Murakami/items/ce7a9cc123510798cefd)を参照)## スクリプトの全文
https://github.com/km7902/TextExtractFromPSD“`Python:TextExtructFromPSD.py
import csv
import osfrom decimal import Decimal, ROUND_HALF_UP
fr




