
- 1. Python Enum ベストプラクティス
- 2. Pythonによる振幅スペクトルと位相スペクトル
- 3. JPEGファイルから文字を抽出する方法
- 4. Lambda で BigQuery のデータを ZIP 化し S3 へアップロードする【無料枠】
- 5. ffmpeg-pythonを使って動画をトリミングする
- 6. 「matplotlib 色 一覧」で検索するのはもう止めよう
- 7. Glue Jobでpandas has no attribute ‘json_normalize’に四苦八苦した
- 8. 1分でXserverにFlaskを導入する。(Linuxサーバーへ、python3環境を構築する。
- 9. 【備忘録】Pythonのインスタンス(オブジェクト?)の中身を確認したいとき
- 10. Python3 [::1]や[::2]を並べた アウトプット
- 11. Python3 YesかNoを返す (例:ある要素が含まれているかでYesかNoを返す)真偽判定
- 12. scikit-learn all_estimators関数を使って,様々な学習器を試す
- 13. 【Python3】よく使う分類モデルのグリッドサーチ手法まとめ
- 14. 【保存版】Python Dash パーフェクトガイド
- 15. 【Python3】メッセージボックスの表示
- 16. [atcoder] ABC226 涙の反省記事
- 17. ゼロから始めるデータベース操作SQL【学習まとめ】
- 18. ポートスキャンサンプル(python 3.8 on aws-λ )
- 19. kivyMDチュートリアル其の肆什乃弍 Components – Tabs篇
- 20. PythonでiCalendar形式のファイルを書き出す
Python Enum ベストプラクティス
PythonのEnumについての一番シンプルな方法を紹介します。
(他のどの記事よりも分かりやすいはず・・・)
これだけ理解すれば困ることはほとんどありません!## Enumとは
定数を列挙して、ステータス管理などに便利です。
C#などを経験している方はPythonでもEnumを使いたくなりますよね。## 公式ドキュメント
公式ドキュメントでは、
Enum, IntEnum, Flag, IntFlag, FlagBoundaryなどありますが、基本の「**Enum**」だけで十分だと思います。
(コードのシンプルさを考慮してもEnumだけが良いです)> [Enum 公式ドキュメント](https://docs.python.org/ja/3/library/enum.html)
## ソースコード
Enumは説明よりコードを見る方が手っ取り早いので、さっそく紹介します。
Enumの名前と値の一覧を取得したいときもたまにあるので、
Classmethodとして実装しています。### Case1 ソースコード
“`python
from enum impor
Pythonによる振幅スペクトルと位相スペクトル
# はじめに
Pythonで振幅スペクトルと位相スペクトルを求めたいと思います。出来る限り公式ドキュメントに従った実装を心掛けていますが、不慣れなところは見逃していただけると幸いです。本記事は「うえね(私)」が書いた[記事](https://uene.hatenablog.com/entry/2021/11/11/fft_amplitude_and_phase)を軽く再編集してQiitaに移植したものです。
# 概観
フーリエ変換は扱う信号とデータの長さによって四種類あります。1. 無限長のデータを扱う、連続系でのフーリエ変換
1. 有限長のデータを扱う、連続系でのフーリエ変換
1. 無限長のデータを扱う、離散系でのフーリエ変換
1. 有限長のデータを扱う、離散系でのフーリエ変換[scipy – Fourier Transforms](https://docs.scipy.org/doc/scipy/r
JPEGファイルから文字を抽出する方法
#1 はじめに
Pythonを使って、JPEGファイルから文字を抽出してみます。#2 環境
VMware Workstation 15 Playerで作成した仮想マシン(1台)を使用しました。
CentOSの版数は下記のとおりです。“`console:CentOS版数
[root@server ~]# cat /etc/redhat-release
CentOS Linux release 8.3.2011
“`
カーネル版数は以下のとおりです。“`console:カーネル版数
[root@server ~]# uname -r
4.18.0-240.el8.x86_64
“`#3 パッケージのインストール
まず、仮想マシンにAnacondaをインストールしました。
インストール方法は、[Anacondaのインストール方法](https://qiita.com/hana_shin/items/a65d686d0e611884cef4)を参照してください。次に、各種パッケージのアップデートを行いました。
“`console:アップデート
(base) [r
Lambda で BigQuery のデータを ZIP 化し S3 へアップロードする【無料枠】
Google Cloud Platform (GCP) BigQuery から Amazon S3 へ転送する記事が少ない印象を受けたので、備忘録として初投稿します。
どなたかのお役に立てば幸いです。## 1. やりたいこと
1. AWS Lambda で BigQuery のデータを DataFrame で取得する
– GCP との認証方法は以下を使用する
– サービスアカウントキー + AWS SSM を使用する方法
– Workload Identity 連携する方法
2. データを CSV 化 & ZIP 圧縮し、 S3 へアップロードする## 2. 前提
– GCP のプロジェクト、AWS のアカウント等が作成済みであること
– Google Cloud SDK (gcloud) が使用できること
インストールは、こちらの[Google Cloud SDK(gcloud) を Homebrew 経由で Mac にインストールする方法](https://zenn.dev/phi/articles/gcloud-set
ffmpeg-pythonを使って動画をトリミングする
#はじめに
自分なりにffmpeg-pythonの使い方をまとめる
`ffmpeg.exe`を`subprocess`で操作するよりは目に優しそうだったので…#ffmpeg-pythonの取得
pipでインストール。“`
pip install ffmpeg-python
“`※ちなみに、似たようなラッパーがいくつかあるので注意。2ミス。
“`
○ pip install ffmpeg-python
——————————
× pip install ffmpeg
× pip install python-ffmpeg
“`#ffmpegの取得
ffmpeg-pythonはただのラッパーなので、ffmpeg.exe本体がないと使えない。FFmpeg.exeが見つからなくてもFileNotFoundになるので、事前に公式サイトから取得しておくこと。
※ちなみに、動画の編集だけならffmpeg.exeだけでいいが、動画ファイルから動画情報を取得するffmpeg.probe()という処理を実行するためには`ffprobe.ex
「matplotlib 色 一覧」で検索するのはもう止めよう
## Abstract
matplotlibで使える色は沢山あります。なので使いたい色を探す際には「matplotlib 色 一覧」と検索される方が多いでしょう。本記事ではコマンドラインに色の一覧を表示させることで、色の一覧確認のためにわざわざブラウザを開く手間を省く[mplcolors](https://github.com/AstroBarker/mplcolors)を紹介します。
## 環境
一応今回の記事の環境を。Pythonを動かせれば大きな違いはないかと思います。
– Windows 10
– Python 3.7.9もちろんですが、matplotlibが使えなければ意味がありません。念のため注意。
## mplcolors
[mplcolors](https://github.com/AstroBarker/mplcolors)紹介
>Tired of searching “matplotlib colors” every week/day/hour? This simple script displays them all conveniently r
Glue Jobでpandas has no attribute ‘json_normalize’に四苦八苦した
# 前提(長くて説明下手です)
ETL処理をGlue jobを用いて、自動化しようとしたときに“`python
import pandas
from pandas.io.json import json_normalize
df = pandas.json_normalize()
#~ 中略 ~
“`
というように処理をGlueスクリプトに書いていたが、jobを実行してみるとエラーログには何も書かれておらず、module ‘pandas’ has no attribute ‘json_normalize’というログのみ書かれていた。またjobのstatusは、「Succeeded」になっているが、肝心のcsvファイルはs3にアップロードされていない。
この時初めて知ったのだが、json_normalizeはpandasのversion >= ‘1.0.0’で実装されており、Glueでのpandasのversionを確認したところ、0.~であり、1.0.0より前のversionだった。Glue スクリプトでは、pipを叩くことはでき
1分でXserverにFlaskを導入する。(Linuxサーバーへ、python3環境を構築する。
Xserver に、Flaskを導入しよう。
そう考えたものの、かなり詰まりまっておりました。。。ですが、以下の方法により瞬殺でFlask環境を整えることができたので共有します。
https://kaedeee.com/xserver-flask-python/
今すぐやり方を知りたい!と言う方は、記事の半分あたりより確認してみてください。
#バージョン
Xserver X10
Miniconda3-py38_4.8.3-Linux-x86_64.sh
Python 3.8#解決前に試していたこと
前提として、このやり方では失敗しました。1. VScode によるSSH 環境を整える
1. Python3, pip3 インストールしたい←brewコマンド使いたい←Linuxbrew入れよう←git, curlインストール必要、、、と言うことで(xserver ではSudoコマンド使えないので、回りくどい方法に、、、)
1. Linuxbrew をxserver オリジナルのgitとcurlを使って入れてみる→失敗。バージョンが低いとのエラー。
1. git,curlの
【備忘録】Pythonのインスタンス(オブジェクト?)の中身を確認したいとき
# はじめに
機械学習のコードをいじっているとき,
出てきたバイナリファイルの中身を確認したいときがありますよね?
そんなとき用に備忘録として確認の仕方を残しておきます.# 結論
Open-NMTでpreprocessを行った際に,`-save_data`引数に指定したファイルに保存されたバイナリ化したデータを対象に説明していきます.pythonのインタラクティブモードでデータをloadすると以下のようになっていると思います.
(ここでは`training-data-en-de.vocab.pt`が対象データ)“`python
>>> import torch
>>> data = torch.load(‘training-data-en-de.vocab.pt’)
>>> data
{‘src’:, ‘tgt’:
Python3 [::1]や[::2]を並べた アウトプット
まんまです
学習していてこの辺りややこしいのでリストアップしてみました~~~python3
w=”aiueo”
print(w)
# aiueo# 0番目から0文字飛ばしで返す
print(w[::1])
# aiueo# 0番目から1文字飛ばしで返す
print(w[::2])
# auo# 0番目から2文字飛ばしで返す
print(w[::3])
# ae# 1番目から1文字飛ばしで返す
print(w[1::2])
# ie# 1番目から1文字飛ばしで返す
print(w[int(True)::2])
# ie# 0番目から1文字飛ばしで返す
print(w[int(False)::2])
# auo# 1番目から1文字飛ばしで返す
print(w[(True)::2])
# ie# 0番目から1文字飛ばしで返す
print(w[(False)::2])
# auo# 下記 おまけ
# 単体で使うと真偽
print(True)
# True# 単体で使うと真偽
print(False)
# False# intと組み合わせると
Python3 YesかNoを返す (例:ある要素が含まれているかでYesかNoを返す)真偽判定
学習のアウトプットです
まずYesかNoを返す式
~~~python3
print(“NYoe s”[1::2])
# Yes
print(“NYoe s”[::2])
# No
~~~
となるので
1を入れている箇所に真偽判定で1か0を返す値を入れてあげると
YesかNoを返すようになる
そこで下記~~~python3
print(False)
# False
print(False+0)
# 0
print(True)
# True
print(True+0)
# 1
~~~
TrueやFalseはintと混ぜると1や0を返してくれることを利用する
そしてまた下記~~~python3
print(“NYoe s”[judge::2])
~~~
judgeの部分に下記の要素を代入すると~~~python3
# 文字の配列を用意
sampleList=[‘a’, ‘i’, ‘u’, ‘e’, ‘o’]
# sampleListの配列は文字iを含んでいるか?
print(“i” in sampleList)
# True
print(“NYoe s”[“i” in sa
scikit-learn all_estimators関数を使って,様々な学習器を試す
#目的
機械学習において,学習器の選定は重要な事項であるが,自分でプログラムを書いて様々な学習器を試すには労力がかかる.
scikit-learnにはすべての学習器を読み出して,試すための関数all_estimatorsが用意されており,これを使用する方法をまとめる.#使い方
データには,テキストデータを使用しており,教師あり学習にて分類を行う.“`.py
import numpy as np
import pandas as pd
import glob
from sklearn.metrics import classification_report, make_scorer, accuracy_score
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import KFold, StratifiedKFold
import ngram
import random
import os
from transformers import B
【Python3】よく使う分類モデルのグリッドサーチ手法まとめ
# はじめに
分類タスクを行う際、毎回分類モデルについてとグリッドサーチを扱うためのパラメータなどを調べるのが面倒なのでまとめておくことにした。
今回はコードベースでまとめるので、モデルについての細かい説明は省きます。# パッケージのインポート
今回使用するライブラリをインポートします。“`py
import numpy as np
import pandas as pd
from sklearn import model_selection
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree
【保存版】Python Dash パーフェクトガイド
Dashの使い方完全保存版
基本的な使い方は他の方もたくさん投稿していると思うので、実務で使う便利なテクニックの紹介が多いです。
辞書的に使ってください。随時更新していくので是非ストック or LGTMしてください!
## 基本
### Dashとは
超簡単におしゃれなWEBアプリが開発できるライブラリ(Flaskベースのライブラリ)
グラフはPlotlyというライブラリを使用しています。
(PlotlyはPython以外にもR、Javascriptなどにも対応しています)Webアプリのプロトタイプを開発する際や、社内利用のアプリならこれで十分だと思います。
> [Dash Hello World](https://dash.plotly.com/layout)
### 不便な点
* 大規模アプリには向かないかも(DjangoやFlaskの利用を検討)
* Flask render_template が使用できない(Flaskとレンダリングの仕組みが異なるため)
* コードが少し冗長となり、メンテナンス性はあまり良くない(templateが使えないから)
* ドキ
【Python3】メッセージボックスの表示
#はじめに
VBAなどでよくあるメッセージボックスを表示するコードです。・「tkkinter.messagebox」をインポート
(Tool Kit Interfaceのこと)“`Python3:messagebox
from tkinter import#引数に(‘タイトル’, ‘内容’)を記載
ret = messagebox.askyesno(‘確認’, ‘処理を開始しますか?’) #「はい」、「いいえ」を選択
if ret: #「はい」を選択した場合はTrue
messagebox.showinfo(‘メッセージ’, ‘はいを選択しました’) #「情報」のメッセージボックスを表示
else: #「いいえ」を選択した場合はFalse
messagebox.showwarning(‘メッセージ’, ‘いいえを選択しました’) #「警告」のメッセージボックス
“`
#####その他のメッセージボックス| 表示内容、確認内容 | メソッド、引数 | 戻り値 |
| :— | :— | :— |
| エラー |
[atcoder] ABC226 涙の反省記事
こんばんは。たゅと申します。
ABC226にpython3で参戦。
https://atcoder.jp/contests/abc226/tasks
三完で入茶させてクレメンスと息巻いていたところ、なんと__ABを通すのに40分+5ペナ__という最悪の事態に。
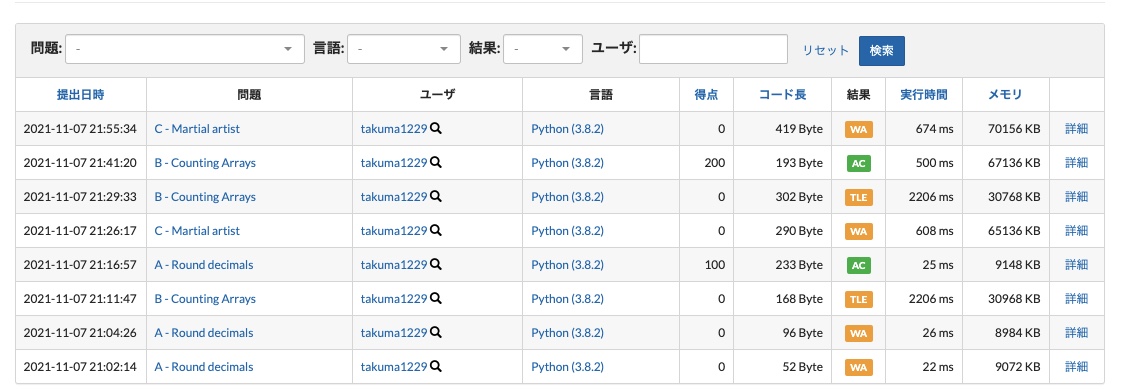
Cは推定茶色中盤diffだったので、むしろよく粘ったと自分では納得しています。しかし、ABでここまで詰まることは完全に想定外だったので、コンテスト中は狂いそうでした。
この悔しさをなんとかポジティブな方向に昇華するために、記事を書いております。
概要としては、
__ABC226のA,B問題について、python3で解説します。__
Cも後で解答を見て余裕があれば復習として追記したいと思います。## A問題
https://atcod
ゼロから始めるデータベース操作SQL【学習まとめ】
#データベース学習を始めるきっかけ#
DBの概念や基本的な操作ができないと業務を実施することが出来ない内容の為、
SQL事前学習をすることで、スタートダッシュを切れる目的で学習を始めました!#学習内容#
SQLの事前準備~基本的な操作で必要な3つの文「CREATE文、INSERT文、DELETE文、UPDATE文」の使い方を纏めます。#事前準備#
#1.PostgreSQLのインストールと接続設定
1.インストーラーのダウンロード
PostgreSQLの[ダウンロードサイト](https://www.enterprisedb.com/products-services-training/pgdownload#windows)からインストーラをダウンロードします。
※使っているPCの環境に応じて適切なものをダウンロードしてください。
今回、Windowsのインストーラ(Win x86-64)2.psql.exeの実行
ダウンロードが完了しpsql.exe実行すると、コマンドプロンプトでパスワードが求められたら、任意のパスワードを入力する。
入力後、「postgres=
ポートスキャンサンプル(python 3.8 on aws-λ )
メモリは1GB推奨。がっつりスキャンするので、要チューニングして利用のこと。
“`python
import json
import socket
import random
from multiprocessing import Process, Pipe
import urllib.request#向き先
TARGET_HOST=’hogehoge.com’#通知先WEBHOOK
webhook = “https://discord.com/api/webhooks/9999999999999999/hogehoge”#生成するスレッド数:CONNECTION多重度と同義。400辺りでファイルディスクリプタ関連エラー
THREAD_MAX=300
#検査レート:何%のポートを検査対象とするか。0.3の場合、検査ポートの30%をScan対象とする
#TODO:アホほど回るのでチューニングすること
SCAN_RATE=0.3
#タイムアウト:socketのタイムアウト時間(秒)。0.3くらいで検査できそう
SOCK_TIMEOUT=0.3def portscan(
kivyMDチュートリアル其の肆什乃弍 Components – Tabs篇
晩秋の候、ますますご繁栄のこととお慶び申し上げます(急な畏まり)。
11月も突入するようになりました。またちょっと温かい気温になる日もあって、なんだか
よく分からない季節ですね。はい、今週も始まりました。KivyMDのお時間です。
少し今週は毛色が異なり、先週のTabs篇の続きとなっています。コードの置き場所などは
先週と同じなのでご留意ください。先週からの差分を主に触れ込んでいきたいと思っており
ます。今週のニュースはというと、先週からの続きですが衆議院選挙のことではないでしょうか。
大小問わず変化があった!ということやいつも通りでしょということなど色々思われるとは
推測していますが、いかかだったでしょうか。ちなみにですが、どの党に投票したかやこう
予想していた(後出しだし…)などは少しセンシティブに近いかもなのでここでは記しません。。というわけで今週も元気にやっていきましょう!しつこいようですが、今日は先週のTabsの
続きとなっています。## Tabs
さて、今日はどこから始まるかというと、先週は「Example with tab icon」までで
止まって
PythonでiCalendar形式のファイルを書き出す
iCalendarはカレンダーアプリなどで使われるスケジュールデータの標準フォーマット。
iCalendarファイルを使ってGoogleカレンダーやOutlookなどのアプリにスケジュールをインポートすることもできる。iCalendarファイルは単純なテキストファイルなので、その気になれば一行一行書き出す処理を書いて作ることもできそう。
https://developers.worksmobile.com/jp/document/1007011?lang=ja
PythonでiCalendarファイルを読み書きできるライブラリがあるのでこれを使ってみる。
https://pypi.org/project/ics/
[クイックスタート](https://icspy.readthedocs.io/en/stable/)を見ながら試してみる。
まずはファイルの書き出しから。
“`python:ics_write.py
from ics import Calendar, Event
import arrow# カレンダーの生成
cal = Calendar()
cal.c




