
- 1. FastAPI OAuth2パスワード認証
- 2. SPSS Modelerの可変長ファイルノードを、pythonに書き換える
- 3. ケリー基準を用いて最適なベッティングサイズを決める
- 4. pythonで双方向リスト
- 5. クラスター・サーバー上等でのmatplotlibに関するメモ
- 6. 重相関係数の意味あい
- 7. 【MLOps】docker/mlflowを使った競馬AI開発環境構築(2021年版)~python実行環境構築~
- 8. GPUを活用した機械学習ツールNVIDIA RAPIDSをArch Linux + CUDA11.5 でビルドした (Ver21.12版) (3) cuGRAPH
- 9. [Python][Pillow]画像ファイルのリサイズ(コマンドライン)<その1>
- 10. 湿度が高いとコロナの感染が弱まるって聞いた気がするけど本当か検証してみた
- 11. ECS Fargate環境のredashをv8からv10にした話
- 12. 多段にネストされたzipファイルの読み込み
- 13. 副反応疑い報告状況についてのPDFをCSVに変換
- 14. pythonでSQLite3を使う手順のメモ
- 15. Raspberry PiOSがbullseyeに更新された影響
- 16. python 関数をオブジェクトとしてとらえる。ーメモ
- 17. 読書:Pythonで始める機械学習
- 18. python 文字列を並び替えて列挙し、リストにする(競プロ用)
- 19. RedshiftにSSH接続してread_sql, to_sqlする方法
- 20. Poetryでrequirements.txtからパッケージをインストールする方法
FastAPI OAuth2パスワード認証
FastAPIで安全なログインなどを行うときは、OAuth2パスワード認証が使われることが多いようです。あまり難しいことは考えないでFastAPIの提供してくれる機能を使えば、他のフレームワークに比べれば比較的簡単に実現可能です。ドキュメントも充実していて、その丁寧な説明には感謝しかありません。
[【公式サイト】Dependencies – First Steps](https://fastapi.tiangolo.com/tutorial/dependencies/)
[【公式サイト】Security – First Steps](https://fastapi.tiangolo.com/tutorial/security/first-steps/)今回はドキュメントの内容をコンパクトにまとめる形で説明しました。
# 1. OAuth2パスワード認証の概略
## 1-1.OAuth2パスワード認証の登場人物
OAuth2パスワード認証の登場人物は3人でそれぞれ以下の役割を担っています。| |登場人物|役割 |
|–|—|—|
|1.|ユーザ|クライアン
SPSS Modelerの可変長ファイルノードを、pythonに書き換える
Modelerの可変長ファイルノードを、pythonに書き換えてみます。ここでは、以下の5つのオプションについてフォーカスします。
##①ファイルからフィールド名を取得
Modelerでチェックを入れた場合:
入力ファイルの1行目がヘッダーとみなされ、フィールド名として、取得されます。
について勉強した内容をまとめていきます。
### 1. The optimal size of a bet
ケリー基準では、無限に繰り返される賭けにおいて資本価値の成長率を最大化するようなベットサイズ(optimal $f$)を見つけることを目的としています。このケリー基準の考え方を数式に落とし込むと以下のようになります。
“`math
V_n = V_{0}(1+of)^m(1-f)^{n-m}\\
“`
“`math
G = lim_{n\ri
pythonで双方向リスト
## 目的
双方向リストとは何か,Pythonでの実装を通して理解を深めましょう.
この記事で実装した双方向リストは,以下のリポジトリから利用できます.
https://github.com/umihei/singlyLinkedListInPython## 双方向リストとは
### 双方向リストの仕様
– ランダムアクセス不可
– Nodeが連結してできており,各Nodeは,次のNodeを示すポインタと,**前のNodeを示すポインタ**を持つ
– Headは先頭の要素を示すポインタ,Tailは末尾の要素を示すポインタである
– リストの長さを表すLengthプロパティをもつ
### 双方向リストの各種メソッドの計算量
先頭,末尾の要素に対するInsertion,RemovalはO(1)となります.SinglyLinkedListは,末尾の要素の削除はO(N)でしたから,それにくらべる
クラスター・サーバー上等でのmatplotlibに関するメモ
– [サーバサイドにおけるmatplotlibによる作図Tips](https://qiita.com/TomokIshii/items/3a26ee4453f535a69e9e)
– matplotlib.use(‘TkAgg’) and matplotlib.use(‘Agg’)
重相関係数の意味あい
重回帰分析において,重相関係数の二乗(決定係数ともいうが)は独立変数どもが従属変数をどの程度説明するかを表す。
つまり,重相関係数が 0.5 ということは,独立変数どもが挙って従属変数を説明しようとしているが 0.5^2(Python なら 0.5**2であるが)つまり,0.25(つまり 25 %)しか説明できないということ。これは,ヤバいよね。なお,重回帰分析の最も単純な場合である回帰分析においては,重相関係数は相関係数の絶対値を取ったものであり,重相関係数の二乗は相関係数の二乗に他ならない。
つまり,独立変数と従属変数の間の相関係数が r の場合,重相関係数は abs(r) であり,重相関係数の二乗(決定係数)は r^2 である。相関係数の絶対値が 0.7 以上であれば,「強い相関がある」というように判断されるが,「独立変数は従属変数の 0.7^2 = 0.49 つまり,半分以下しか説明できていないのだよ」ということだ。
“`R
> x = c(3, 2, 4, 5, 1)
> y = c(1, 3, 4, 5, 6)
> ans = lm(y ~ x)
> summ
【MLOps】docker/mlflowを使った競馬AI開発環境構築(2021年版)~python実行環境構築~
今回は環境構築のうち、実際のコードを実行するPython実行環境を構築していきましょう。
下の図のうち赤い枠の部分をインストールしていきましょう。

### 大まかな流れ
今回のインストールは次の順番で進めていきます。1. ローカル環境にanacondaをインストールする
2. tensorflowをインストールする
3. optunaをインストールする
4. mlflowをインストールする#### 1.ローカル環境にanacondaをインストールする
まずは、python環境を構築するためにanacondaをインストールしましょう。
下記のリンクから自分の環境に合ったインストーラをダウンロードしてインストーラを実行してください。インストーラの指示に従って進めてください。特別な設定は不要です。https://www.anacond
GPUを活用した機械学習ツールNVIDIA RAPIDSをArch Linux + CUDA11.5 でビルドした (Ver21.12版) (3) cuGRAPH
# やったこと=RAPIDS のビルド
データ処理、機械学習のフレームワーク[RAPIDS](https://rapids.ai/)を [Arch Linux](https://www.archlinux.org/) でビルドした。ただし、ビルドまでにエライ手間がかかったので、皆さんへの共有も兼ねて
0. **基本構成その0** ・・・ Cupyのビルド方法については[こちらの記事](https://qiita.com/daisuzu_/items/971ff080bb8e16d7c815)で紹介してます。
1. **基本構成その1** ・・・ [こちら](https://qiita.com/daisuzu_/items/ffd7fc82b8410b9e14b4)。RMM, cuDFというRAPIDS の基本コンポーネントの一部のビルド手順。
2. **基本構成その2** ・・・ (作成中)。CUMLというRAPIDS の基本コンポーネントの一部のビルド手順。ついでに、cuSignal という信号制御ライブラリやcuxfilter という描画データ変換ライブラリも
3. **基本
[Python][Pillow]画像ファイルのリサイズ(コマンドライン)<その1>
pillow の resize をコマンドラインから操作できるよう、一般化した。
オプションは、ImageMagick の resize っぽく。
今後、機能追加予定。“`resize.py
import os
import sys
import argparse
import glob
import re
from PIL import Image
from decimal import Decimal, getcontext, FloatOperation, ROUND_HALF_UPgetcontext().traps[FloatOperation] = True
def create_parser():
parser = argparse.ArgumentParser()
parser.add_argument(
“source”,
type=str,
help=”This is source. (Specify a file or directory. Wildcards cannot be use
湿度が高いとコロナの感染が弱まるって聞いた気がするけど本当か検証してみた
## 定義
2020年1月から12月までの東京の月の平均湿度と、
同じ期間の東京のコロナの新規感染者数の月の平均数で相関係数を出し、0.5以上あったら関係していることとする## 利用したデータ
### 湿度データは気象庁から
https://www.data.jma.go.jp/gmd/risk/obsdl/index.php
[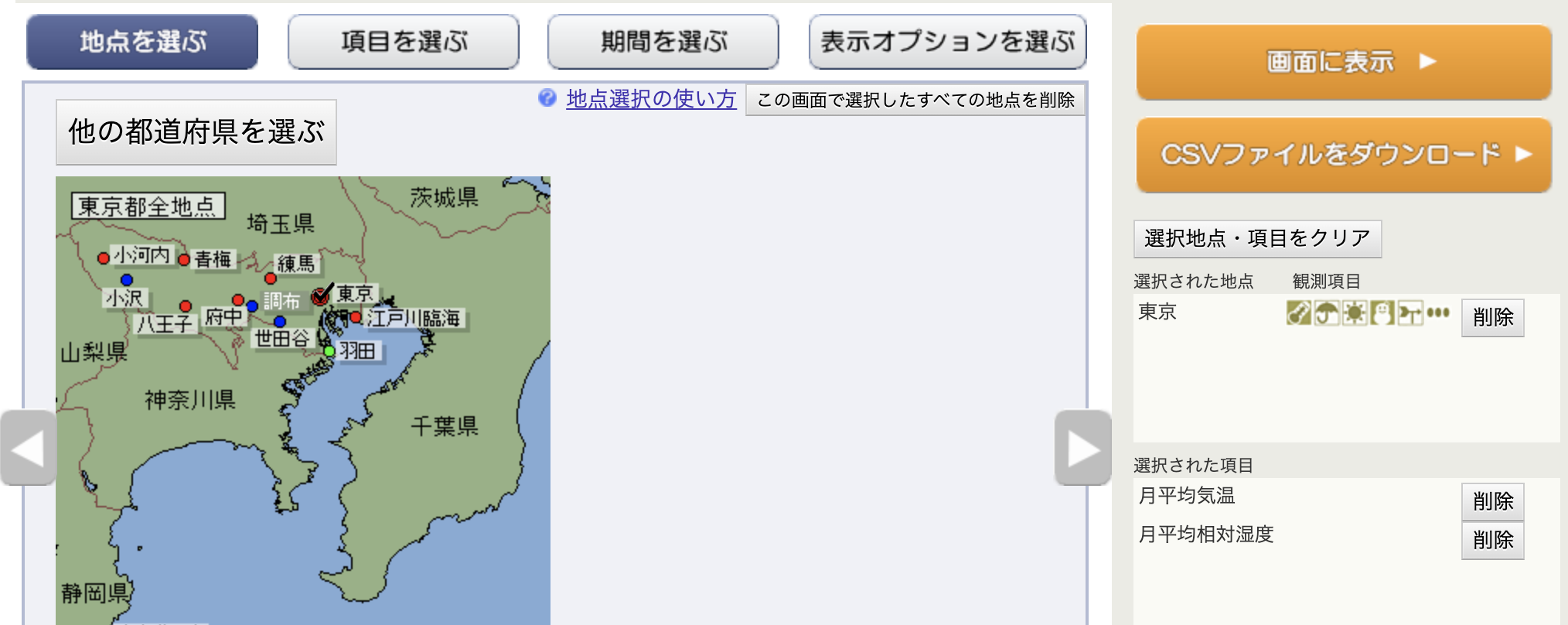](https://gyazo.com/275a099c90cfe12c0bcab95c79f2d40f)
地域は東京
[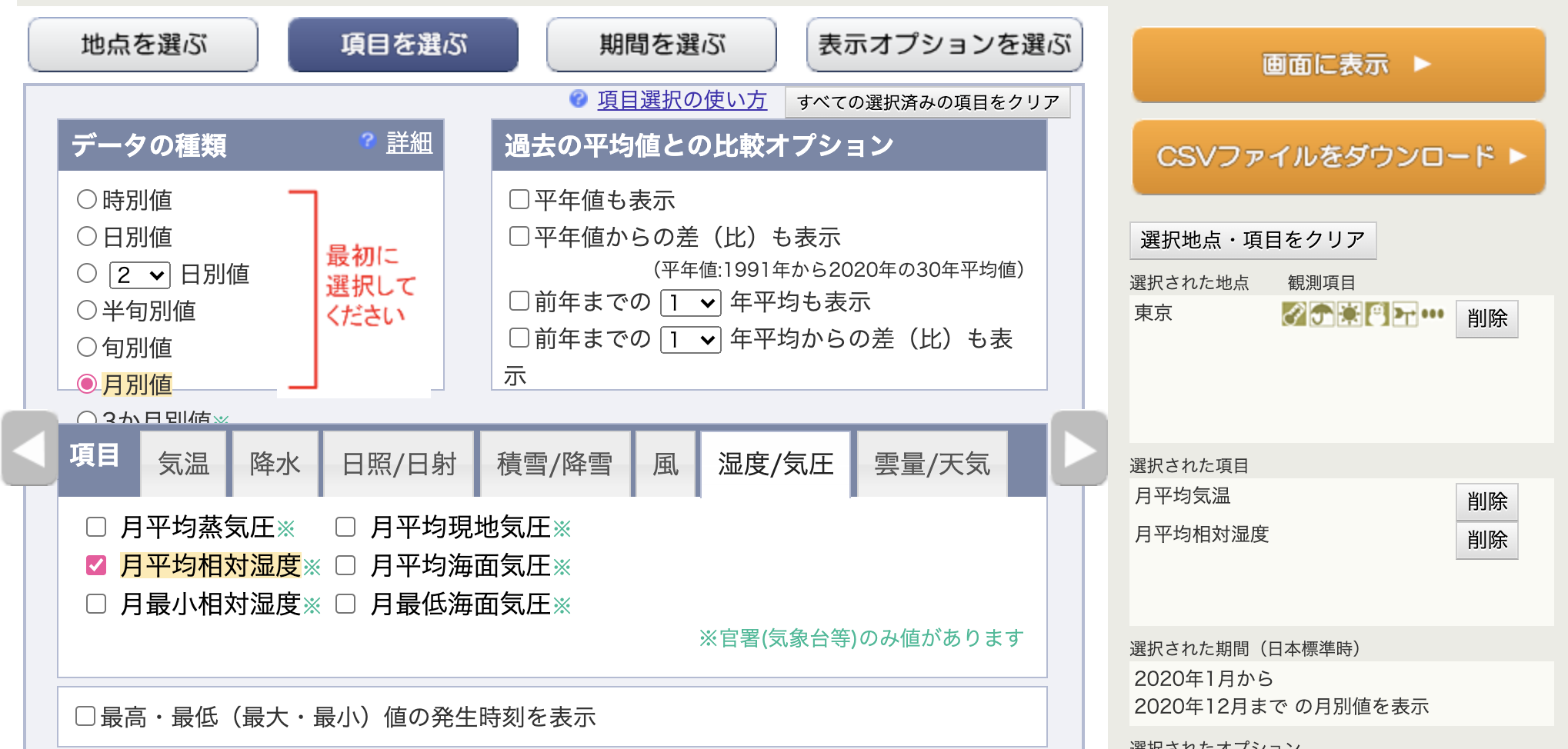](https://gyazo.com/a8967bce64edc54344f41baee9c20d00)
データは湿度のみで、月別に
[を読みアップデートを行うも、**発行したクエリが返ってこない**という症状が発生、原因不明・解決不能のまま泣く泣く切り戻しを行いました。
*クエリが返ってこず、Queuedだけがどんどん増えていく。その後調査を続ける中で[**Redash SaaSサービスから自前ホス
多段にネストされたzipファイルの読み込み
# やりたいこと
zipファイルの中のzipファイルを読みたい場合は、 [How to read from a zip file within zip file in Python?](https://stackoverflow.com/questions/12025469/how-to-read-from-a-zip-file-within-zip-file-in-python) で紹介されている。
しかし、もっと階層が深くなったり、そもそも深さが不定だったりする、意地悪なファイルを扱わなければならなかったので、上記のリンク先も参考にしながら、任意の深さのzipファイルを読み込めるコードを書いた。# コード
:::note info
yield from を使用しているため、python 3.3 以降で動く。
:::
:::note info
ZipInfo.is_dir() を使用しているため、python 3.6 以降で動く。この判定は必須でなく、ディレクトリが含まれることを許容するなら、削除してもよい。あるいは、name_filter で代替してもよい。
:::“`
副反応疑い報告状況についてのPDFをCSVに変換
予防接種法に基づく医療機関からの副反応疑い報告状況について(コミナティ筋注・報告症例一覧) (PDF:5,092KB)
https://www.mhlw.go.jp/content/10601000/000853766.pdfpdfplumberでテーブルを抽出しようとすると表の最後に線がないため最終行が取得できない
縦線の下の位置を取得して最終の横線を追加
縦線を追加
すると指定したPATHにあるSQLite3 DBファイルに接続しますが、ファイルがない場合は自動で作ってくれます。
“`python
import sqlite3
conn = sqlite3.connect(‘./TEST.db’)
conn.close()
“`PATHを’:memory:’にするとメモリ上にDBを作ってclose()した時点で消えるように出来ます。操作方法の確認をやりたいときに便利です。
“`python
conn = sqlite3.connect(‘:memory:’)
conn.close()
“`# 3. table
## 3-1. tableを追加する
カーソルを作ってex
Raspberry PiOSがbullseyeに更新された影響
10/30にRaspberry PiOSがアップデートされ、これまでDebianがbusterだったのがbullseyeに変更されていた。
知らずにダウンロードし、機械学習の環境構築などをしていたら色々インストールできず困ったので備忘録として以下に記す。
# 旧Raspberry PiOSのダウンロード
まずは旧Raspberry PiOSのダウンロード方法について以下に記しておく。
基本的にRaspberry PiOSの[公式HP](https://www.raspberrypi.com/software/operating-systems/)には最新バージョンのimgファイルしか公開されていないが、
HTTPなどで常に全バージョンにアクセスすることができる。以下からダウンロードすることができる。
ちなみにbusterの最終更新は2021年の5月のイメージファイルである。
https://downloads.raspberrypi.org/raspios_armhf/images/# インストールできなかったもの
今回インストールできなかったものは以下であるが、他にもイ
python 関数をオブジェクトとしてとらえる。ーメモ
“`
def greeting():
print(‘hello’)
print(‘nice to meet you’)greeting()
“`
こちらは、ふつうの関数?pythonでは、関数をオブジェクトとして扱える。
:relaxed:“`
def double(func):
func()
func()double(greeting)
“`
同じ関数を二度呼び出しました。:fist:“`
実行結果hello
nice to meet you
hello
nice to meet you
“`
読書:Pythonで始める機械学習
[Pythonで始める機械学習](https://www.amazon.co.jp/Python%E3%81%A7%E3%81%AF%E3%81%98%E3%82%81%E3%82%8B%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92-%E2%80%95scikit-learn%E3%81%A7%E5%AD%A6%E3%81%B6%E7%89%B9%E5%BE%B4%E9%87%8F%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E5%9F%BA%E7%A4%8E-Andreas-C-Muller/dp/4873117984)を読んだのでざっくりとまとめます。
著者:Sarah Guido
翻訳:中田 秀基
出版社:オライリージャパン
発売日:2017/5/25# 所間
[courseraのMachine Learning](https://ja.cou
python 文字列を並び替えて列挙し、リストにする(競プロ用)
## 入力された文字列を並び替えてリストにする(昇順)
“`
import itertoolss = input()
words = [“”.join(i) for i in itertools.permutations(list(s))]
words.sort()
print(words)
“`## 出力 (‘abcd’を入力した場合)
“`
[‘abcd’, ‘abdc’, ‘acbd’, ‘acdb’, ‘adbc’, ‘adcb’, ‘bacd’, ‘badc’, ‘bcad’, ‘bcda’, ‘bdac’, ‘bdca’, ‘cabd’, ‘cadb’, ‘cbad’, ‘cbda’, ‘cdab’, ‘cdba’, ‘dabc’, ‘dacb’, ‘dbac’, ‘dbca’, ‘dcab’, ‘dcba’]
“`## 入力された文字列を並び替えてリストにする(降順)
“`
import itertoolss = input()
words = [“”.join(i) for i in itertools.permutations(li
RedshiftにSSH接続してread_sql, to_sqlする方法
セキュリティの観点から、AWS Redshiftへは踏み台経由でSSH接続する場合が多いと思います。
そこで、今回はデータサイエンティスト・アナリストが良く使うであろう`pandas.read_sql()`や、ORMのSQLAlchemyを利用したpandas.DataFrameの`to_sql()`を、踏み台経由でSSH接続したRedshiftで使用する方法を紹介します。
## ライブラリ
“`
psycopg2-binary==2.9.1
sqlalchemy==1.4.25
sshtunnel==0.4.0
“`## メソッド定義
新たにread_sql, to_sqlメソッドを定義する。“`python
import psycopg2from sqlalchemy import create_engine
from sshtunnel import SSHTunnelForwarder
def read_sql(ssh_host, ssh_port, ssh_username, ssh_pkey, dbhost, dbport, dbuser, dbpa
Poetryでrequirements.txtからパッケージをインストールする方法
忘れないようにメモしておきます
“`
poetry init
poetry shell
“`してから、
“`
poetry add `cat requirements.txt`
“`fishならこう
“`
poetry add (cat requirements.txt)
“`おしまい
誰かの役に立ちますように・・




