
- 1. テスト1
- 2. python websocketのパッケージ整理
- 3. Python time.sleepのsleepできるのは最小何秒?
- 4. Linux上にPython+Selenium+Chromeの動作環境を構築する
- 5. レコメンド指標でよく見るMAP@kとは
- 6. iptablesファイルに書いたドメインを、cronで定期的に解決しiptablesに反映する
- 7. サンプル用クラスタリング用のデータを作成しよう
- 8. Prophetを使ってみた(予測)
- 9. Prophetを使ってみた(事前準備)
- 10. djangoアプリをAWSでデプロイする時にハマったこと
- 11. Pythonを使ってYoutubeのプレイリストを開く
- 12. python3 【標準入力】スペース区切りを読み込み
- 13. 【Atcoder】入緑したのでここまでの勉強をまとめてみた【Python】
- 14. 【Windows 10 /python3.8】Generate 100,000+ unique Kanji and sell them as NFTs Part-2
- 15. [FlyweightPatter]wikiのサンプルをpython3で実装
- 16. argparseの使い方備忘録
- 17. Python のあまり知られていない便利な言語構文3選
- 18. werkzeug.security(generated_pw_hash,checked_pw_hash)を読む
- 19. Python IOバウンドなスクレイピング処理をマルチスレッドやるときの初心者メモ
- 20. Python で Wordle ソルバー作ってみた
テスト1
“`
import openpyxl
from datetime import datetime as dt”’
エクセルのシート名にテーブル名を設定
ヘッダ列にカラム名を設定
ファイル名は任意
”’def calc(ex):
if isinstance(ex, int):
return str(ex)
elif (ex is None) or (ex == ”):
return “””
elif ex in func_str_list:
return str(ex)
else:
return “‘” + str(ex) + “‘”func_str_list = [‘CURRENT_TIMESTAMP’, ‘NULL’]
# TODO 適宜修正
file_path = ‘input_xlsx_path’
output_path = ‘output_sql_path’
wb = openpyxl.load_workbook(filename=file_path)
ta
python websocketのパッケージ整理
# 目的
似て非なるパッケージが複数あって混乱するので整理したい。
websocket系とthread# Pypi : Python Package Index
https://pypi.org/# windows10 ファイアウォール
外部への線を抜いてローカルでファイアウォールを切る。https://pc-karuma.net/windows-10-firewall-enable-disable/#Windows_%E3%83%95%E3%82%A1%E3%82%A4%E3%82%A2%E3%82%A6%E3%82%A9%E3%83%BC%E3%83%AB%E3%82%92%E7%84%A1%E5%8A%B9%E3%81%AB%E3%81%99%E3%82%8B
ファイアウォールを有効にするならば、ポートを開ける
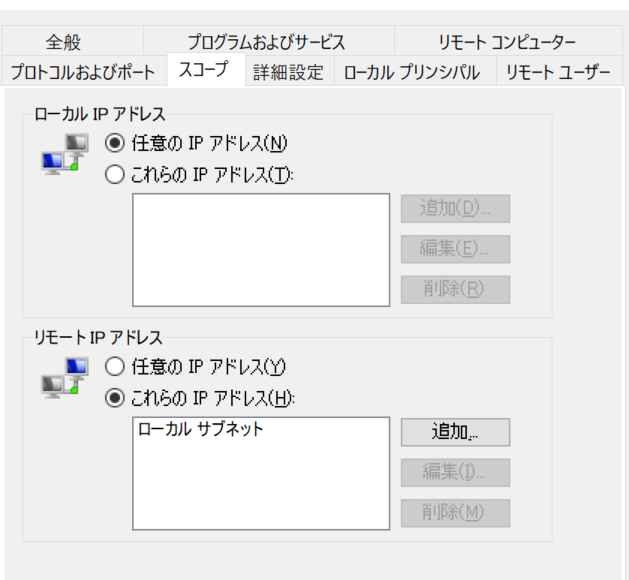# ラズパイ
Python time.sleepのsleepできるのは最小何秒?
# 結論
**0.001秒**
いちおう、スリープ時間は最小になったが、希望通りのスリープはしてくれない
# 検証
0.000~0.009のスリープ時間の計測
“`python
def minimam_sleep(milliseconds):
seconds = 0.001 * milliseconds
start_time = time.time()
time.sleep(seconds)
stop_time = time.time()
time_difference = stop_time – start_time
return time_differencefor milliseconds in range(10):
print(round(milliseconds*0.001,3), minimam_sleep(milliseconds))
“`“`
0.0 0.0
0.001 0.005999088287353516
0.002 0.016000986099243164
0.003 0
Linux上にPython+Selenium+Chromeの動作環境を構築する
#はじめに
SeleniumとはWebブラウザの操作を自動化できるフレームワークのことです。
本記事ではSeleniumを使う環境の一つとして、Linux上にPython+Selenium+Chromeの環境を構築する手順を紹介します。
#構成
今回使うLinux環境は、以下のようなインスタンスをAWSにて作成しました。|項目|設定値|
|—|—|
|プラットフォーム|Amazon Linux|
|インスタンスタイプ|t2.micro|#環境構築
以降のコマンドはデフォルトのユーザ(ec2-user)を使った場合のものとなってます。
###Python3のインストール
まず、yumのアップデートを実行します。“`
$ sudo yum update
“`
yumのアップデートが完了後、Python3のインストールを行います。
Python3をインストール時に合わせてpip3もインストールされます。“`
$ sudo yum install python3
“`
なお、Amazon Linuxではデフォルトで`python`コマンドにはPython2の方が
レコメンド指標でよく見るMAP@kとは
## 概要
– レコメンドでよく使われるメトリクスである**Mean Average Precision (MAP)**について解説する
– MAPについて説明する前にまず前提条件として**Precision@k (P@k)**、**Average Precision @k (AP@k)** についても説明する## 問題設定
– 正解を予測して並べた5個 (k=5)のデータのうち何個正解できたかを考える
– 例えば5個並べた商品のうち、実際にクリックされたのはどれだったか– 以下の例だと1番目と4番目を正解したことになる
– これを評価するメトリクスを考えたい
– 単純に5個中何個正解できたかを考えてみる (2/5)
– でも同

iptablesファイルに書いたドメインを、cronで定期的に解決しiptablesに反映する
# 本記事について
本記事は、`/etc/sysconfig/iptables`にドメイン名を直接書いたものを、iptablesに定期的に反映させる方法について私見を述べたものです。
### 環境
Amazon Linux 2
Python3# 背景
### iptablesの罠
以下のように、iptablesをドメイン名で記載している箇所がある。
変更する際は`sudo vi /etc/sysconfig/iptables`コマンドで直接編集し`sudo service iptables restart`で反映させる運用となっている。“`text:/etc/sysconfig/iptables
-A OUTPUT -p tcp -d dev.**.***.net -m owner –uid-owner userName -j ACCEPT
-A OUTPUT -p tcp -d prd.**.***.net -m owner –uid-owner userName -j ACCEPT
-A OUTPUT -p tcp -d ************.**.ne
サンプル用クラスタリング用のデータを作成しよう
# datasets.make_blobsでクラスタリング用のデータを作成
sklearn.datasetsのmake_blobs関数をインポート
from sklearn.datasets import make_blobsXには1つのプロットの(x,y)が、Yにはそのプロットの所属するクラスター番号が入る
X,Y = make_blobs(n_samples=150, # データ点の総数
n_features=2, # 特徴量(次元数)の指定 default:2
centers=3, # クラスター数
cluster_std=0.5, # クラスタ内の標準偏差
shuffle=True, # サンプルをシャッフル
random_state=0) # 乱数生成器の状態を指定
Prophetを使ってみた(予測)
前回はAnacondaのインストールからjupyter notebookが起動するところまで実施しました。今回はProphetを使った時系列データの予測をやってみたいと思います。
前回の記事はこちらから
https://qiita.com/nw-engineer/items/d167e9e193124bacfb96
## 1. データダウンロード
下記サイトより為替レート(日本円からドル)のグラフをダウンロードします。
https://fred.stlouisfed.org/series/DEXJPUS
ダウンロードしたデータは作成したDataディレクトリに保存しておきます。
## 2. 事前準備
ここからはJupyter notebook上での作業となります。必要となるライブラリをインポートしておきます。“`bash
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
“`CSVデータを読み込んで6行分表示してみます。
“`bas
Prophetを使ってみた(事前準備)
Prophetを利用した時系列データの予測などやってみたので、備忘録も兼ねて
## 1. 環境
– OS: CentOS 7.9
– kernel: 3.10.0-1160.53.1.el7.x86_64
– Anaconda: 3-5.3.1
– jupyter: 4.4.0## 2. OS最新化&ツールインストール
いつものようにOSは最新化します。また開発ツールパッケージも入れましょう。“`bash
yum update -y
rebootyum groupinstall ‘Development Tools’ -y
yum install wget -y
“`## 3. Anacondaインストール
下記サイトからAnaconda(Linuxインストール用スクリプト)をダウンロードしてインストールします。https://repo.anaconda.com/
wgetでダウンロードし、実行します。
“`bash
wget https://repo.anaconda.com/archive/Anaconda3-5.3.1-Linux-x86_64.s
djangoアプリをAWSでデプロイする時にハマったこと
djangoアプリをAWSでデプロイする時にハマったことを個人用にメモ。
【参考】
https://qiita.com/Bashi50/items/d5bc47eeb9668304aaa2
https://qiita.com/Bashi50/items/db0b6b3343d51e0fc598
https://zenn.dev/ryo_t/articles/71e4ee16d76274【メモ】
■gunicornを起動してもソケットファイルが作成されなかった。
原因⓵:ソケットファイルを作成するフォルダに書き込み権限を付与していなかった。
原因⓶:「gunicorn.service」に誤字があった。
原因③:wsgyファイルがあるアプリフォルダ名とプロジェクトフォルダ名を違う名称にしていたため、wsgyファイルパスが間違っていた。
原因④:「Procfile」ファイルを配置していた。■Postリクエストする時に403エラーが発生する。
原因:自分のブラウザ設定でcookieをブロックしていた。
Pythonを使ってYoutubeのプレイリストを開く
#はじめに
私は、普段から作業をするときに、Youtubeでプレイリストを流しているのだが、毎回その作業をする際に動画が気になったりなど、気が散る原因となっていました。
そこで、この作業を自動化し、自分が画面を見なくてもいいようにしたいなと考えました。##環境
* Windows 10 Pro (21H1)
* Python 3.9.1
* Google Chrome 98.0.4758.82 (Official Build)##ソースコード
“`python:main.py
#インポート
import webbrowser
import time#URLを開く
webbrowser.open(‘https://www.youtube.com/watch?v=2DoRuPI2OxM&list=PLH-ORs6msKSeO54zI7Rfcr0zC50HiKcLp&index=1&t=0’)
while True:
print(‘Program executed successfully. This window will automatically close.’)
#
python3 【標準入力】スペース区切りを読み込み
初めまして。初の記事ですが、いきなり自分用のメモに残します。
基本的なことはプロフィールに書いてます。(笑)
まだまだ初心者なので、備忘録として使うことが多々あると思います。ご容赦ください。最近自分で勉強していて
・標準入力で空白区切りの入力があった場合、どう受け取れば良かったっけ。
と根本的な部分で詰まってたので残します。
“`test.py
(変数1,変数2) = map(データ型,input().split())
“`
変数の部分は区切り数が分かっていれば追加可能。
データ型の部分で int,str 等 指定。VBやJavaを仕事で使うことが多く、pythonは実務では触らない…。
ので、忘れますね。
【Atcoder】入緑したのでここまでの勉強をまとめてみた【Python】
入緑しました〜!
最近のもので描かれてる記事もないのと、久々に文字として何か書かないとまずいなと思ってつらつら書いておきます。
# 筆者のスタート地点
アルゴリズムに関する知識は皆無。(二分探索や、累積和などすら知りませんでした)
それ以外仕事では主にフロントエンドの実装を行っておりSwiftが最近はメインです。学生時代はReactNativeを使ってインターンに参加したりをしていました。
そのため、Atcoderの計算量を意識することなく、愚直に計算するA,Bぐらいは書けるレベルのスタートになります。
C++が競プロではスタンダートですが、業務との兼ね合いもあるし、これ以上学ぶ言語も増やしたくなかったのと余程のことがない限り今はPythonで書いてPypyで出せば通るので少し馴染みがあったPyt
【Windows 10 /python3.8】Generate 100,000+ unique Kanji and sell them as NFTs Part-2
# Objectives
After generating some unique Kanji, the last step is to sell them on OpenSea. it is pain in the neck uploading thousand of images one by one. I found automation code that uploads my images to the OpenSea. I will use that code to upload my images on the OpenSea.
**If you haven’t checked Part 1 yet, Go to 【Part1】**# Version
– python 3.8
– Pillow 8.4.0# Create OpenSea Account and Connected to Your Wa
[FlyweightPatter]wikiのサンプルをpython3で実装
“`python:flyweight_pattern_wiki.py
“””Flyweight Pattern
https://ja.wikipedia.org/wiki/Flyweight_%E3%83%91%E3%82%BF%E3%83%BC%E3%83%B3Desc:
等価なインスタンスを[別々の箇所]で使用する際に、
一つのインスタンスを再利用することによって、
プログラムを省リソース化することを目的とする。(UML
FlyweightFactory <>————– Flyweight
– pool:Flyweight[]
+ getFlyweight()(Ex
StampFactory <>————– Stamp
– pool: Stamp[]
+ get()
“””# Flyweight
class Stamp:def __init__(self, type: str):
self.__type = typedef print(self):
argparseの使い方備忘録
業務でPyTorchで実装されたモデルを度々学習させています。ただ、必要なファイルが都度少しずつ異なるという場面が多々有ります。職場の方からargparseを使うと便利だとご教示頂いたので、使ってみるととても使いやすいと感じました。しかし、いつも使い方を忘れてしまうので備忘録メモとして残しておこうと思います。
“`python:使用例
class SampleClassdef __init__(self, required_arg, optional_arg):
self.required_arg = required_arg
self.optional_arg = optional_argdef sample_func(self):
passif __name__ == ‘__main__’:
import argparse
arg_parser = argparse.ArgumentParser()
arg_parser.add_argument(‘required_arg’)
Python のあまり知られていない便利な言語構文3選
あまり知られていないけれど、便利なPythonの構文3つを紹介。どれもちょっとしたことだが、汎用的で使える場面が多い言語構文。他の言語には同等の機能がないことが多いから知られていないのだと思う。
ちなみにPython3のお話、Python2にあるのかは知らん。# for-else、while-else 文
`for`の後ろに`else`句をつけると、ループの中で`break`しなかった場合のみ実行してくれる。`while`も同様。“`python
def for_else(id):
…
for item in items:
if item.id == id:
break
else:
item = create_item()
item.id = idsomething_to_work_with(item)
…
“`例えば上記は条件に合うアイテムをループで探して、見つかれば`break`でループを離脱、見つからなければ新しく作るというコード。他の言語だとこれをやるために別にフラグ変数を用意したりすることもあ
werkzeug.security(generated_pw_hash,checked_pw_hash)を読む
##はじめに
前々からwerkzeug.securityに興味があったので、
今回、表題の機能を調べてみることにしました。### generated_pw_hashを見る
先ずは公式のドキュメントを見る。
[公式ドキュメントのリンク](https://werkzeug.palletsprojects.com/en/2.0.x/utils/#general-helpers)
>Security Helpers
Changelog
***werkzeug.security.generate_password_hash(password, method=’pbkdf2:sha256′, salt_length=16)***
Hash a password with the given method and salt with a string of the given length. The format of the string returned includes the method that was used so that check_password_hash() c
Python IOバウンドなスクレイピング処理をマルチスレッドやるときの初心者メモ
# 参考
[PythonによるWebスクレイピング](https://amzn.to/3e9ePL2)
[Pythonクローリング&スクレイピング-データ収集・解析のための実践開発ガイド](https://amzn.to/2XkSVO5)
[実践 Selenium WebDriver](https://amzn.to/3ge97cE)https://qiita.com/osorezugoing/items/cb5c27ddcd5432c9af5b
https://qiita.com/saba/items/107c4237206e31acdbef#%E7%B5%90%E8%AB%96
# はじめに
ぼくちんスクレイピング初心者
もっと良い書き方があったら教えていただきたい
30分ほどで書いたので誤字脱字ご容赦願う# やろうとしていること
以下の処理を別スレッドでやろうとおもう
・URLのリクエスト処理
・パース処理
・DBへのインサート処理# 意識したこと
・マルチタスク処理で最も注意しなきゃなのがデータの取り扱いなんだなあ
・複数スレッドで1つのデータにアク
Python で Wordle ソルバー作ってみた
# はじめに
みなさん。 [Wordle](https://www.nytimes.com/games/wordle/index.html) やっていますでしょうか。
知らない人のために一応説明しておくと、Wordleとは
“`text
Guess the WORDLE in six tries.
Each guess must be a valid five-letter word. Hit the enter button to submit.
After each guess, the color of the tiles will change to show how close your guess was to the word.
“`というゲームです。(公式引用)
要は、単語当てゲームで、いかに効率的にお題を特定するかが肝となっています。
とりあえず一度やってみればルールは理解できると思うので、やってみましょう。そして先日、[こんな動画](https://www.youtube.com/watch?v=v68zYyaEmEA)を知り合いから教わり見てみた




