
- 1. Python で Covid-19 のコロプレス図を作成する
- 2. [Django / python3] ZoneInfoNotFoundErrorの対策
- 3. sklearn.feature_extraction.textのvectorizerで日本語の単語ngramを生成する
- 4. Python3: GraphQL サーバーにアクセスする方法
- 5. [LightGBM] Optuna 最適化
- 6. [Flask] ImportError: cannot import name ‘soft_unicode’ from ‘markupsafe’ への対処
- 7. 【Lightsail】Flaskアプリケーションをデプロイ
- 8. Django ランダムかつ有効期限のあるURLを生成し、上位者に承認してもらいアカウントを発行する
- 9. Python3: Cognito から Access Token を取得
- 10. kivyMDチュートリアル其の肆什玖 Behaviors – Touch篇
- 11. 【Flask】Hello World(uWSGI + Ubuntu)
- 12. テスト1
- 13. python websocketのパッケージ整理
- 14. Python time.sleepのsleepできるのは最小何秒?
- 15. Linux上にPython+Selenium+Chromeの動作環境を構築する
- 16. レコメンド指標でよく見るMAP@kとは
- 17. iptablesファイルに書いたドメインを、cronで定期的に解決しiptablesに反映する
- 18. サンプル用クラスタリング用のデータを作成しよう
- 19. Prophetを使ってみた(予測)
- 20. Prophetを使ってみた(事前準備)
Python で Covid-19 のコロプレス図を作成する
# はじめに
簡単なコロプレス図を作りたいと思ったときに、いろいろと調べたので備忘録代わりに記録しておく。コロプレス図のカラーバーをつけるのに少し工夫が必要だった。もしもっと簡単にできる方法をご存じの方が居ましたら是非コメント下さい。以下、参考サイト。– cartopy の使い方
– [cartopy official document](https://scitools.org.uk/cartopy/docs/latest/index.html)
– [Cartopyで地理データを可視化する1](https://metpost.hatenablog.com/entry/2015/11/05/180006)
– コロプレス図の作成方法について
– [14.6. Manipulating geospatial data with Cartopy](https://ipython-books.github.io/146-manipulating-geospatial-data-with-cartopy/)
– カラーバーの作成方法について
– [matplotlibでカラーバー
[Django / python3] ZoneInfoNotFoundErrorの対策
# 概要
Djangoの管理画面を開こうとしたら、以下のエラーが発生した。
“`bash
backports.zoneinfo._common.ZoneInfoNotFoundError: ‘No time zone found with key Asia/Tokyo’
“`むむむ、今までは発生してなかったんだが~( ˘·ω·˘ ).。oஇ
# 環境
||type / version|
|:-|-:|
|OS|wsl2 (Ubuntu)|
|Python|3.8.9|
|Django|4.0.2|
|backports.zoneinfo|0.2.1|# 対策
pip moduleの`tzdata`をインストールした上で、Djangoアプリケーションを再起動してあげれば大丈夫でした。
# 原因について
エラーの発生原因になっている[zoneinfoの公式ドキュメント](https://docs.python.org/3/library/zoneinfo.html#data-sources)によると、zoneinfoは、データベースかもしくは`tzdata`からt
sklearn.feature_extraction.textのvectorizerで日本語の単語ngramを生成する
# 概要
`sklearn.feature_extraction.text`のvectorizerで日本語の単語ngramを生成しようとして苦戦したのでメモ。結論としては、vectorizerの引数で、`tokenizer=lambda x: mecab.parse(x).strip().split()`(mecabはMeCabの分かち書きTaggerオブジェクト)としたうえで、`ngram_range=(3,3)`などと指定すればよい。分かち書き関数を`analyzer`ではなく`tokenizer`に指定するのがポイント。
“`Python
from sklearn.feature_extraction.text import TfidfVectorizer
import MeCab
mecab = MeCab.Tagger(“-Owakati”)vectorizer = TfidfVectorizer(
tokenizer=lambda x: mecab.parse(x).strip().split(),
ngram_range=(3,3)
)# 確認
d
Python3: GraphQL サーバーにアクセスする方法
こちらで作成した Graph QL サーバーにアクセスする方法です。
[Apollo Server の使い方](https://qiita.com/ekzemplaro/items/98aa688d329e526db516)“`py:graphql_client.py
#! /usr/bin/python
# -*- coding: utf-8 -*-
#
# graphql_client.py
#
# Feb/20/2022
#
# ——————————————————————
import sys
import requests
# ——————————————————————
def file_to_str_proc(file_in):
str_out = “”
try:
fp_in = open(file_in,encoding=’utf-8′)
str_out = f
[LightGBM] Optuna 最適化
# 概要
LightGBMをOptunaを使用して最適化する方法をまとめた記事です。
この記事はTunerやTunerCVなどの違いなどを一つのコードにまとめており、それぞれの結果を比較できます。
Optunaの使用方法の日本語の記事が少ないと感じたため、まとめてみました。
しかしながら、一度公式ドキュメントを一読することを強く推奨します。また、optunaで最適化した後に再度学習を回さなければいけないのか?
という疑問があったので、それについても検証しています。
(実際には検証データを学習データに追加してスコアを上げることが多いので、基本的に再度学習させますが、、、)この記事はPython APIを使用しています。
# 動作環境
* MacBook Pro (M1)
* optuna: 2.9.1
* lightgbm: 3.3.2
* scikit-learn: 1.0.2# ソースコード
“`
“””
公式githubから一部引用しています。
ソースコード引用元: https://github.com/optuna/optuna-examples/tree/
[Flask] ImportError: cannot import name ‘soft_unicode’ from ‘markupsafe’ への対処
FlaskをCloud Runにデプロイしたら、「 **ImportError: cannot import name ‘soft_unicode’ from ‘markupsafe’** 」 が発生したときの対処。
原因特定までできていないのですが、
フロントを色々直して、デプロイしたら、発生して、
ブラウザから接続すると、 service unavailable に……“`requirements.txt
-Flask==1.1.4
+Flask==2.0.1
“`Flaskのバージョンを上げたら、解決した。
【Lightsail】Flaskアプリケーションをデプロイ
# 1. はじめに
Lightsailのコンテナサービスを利用します。
Flaskアプリケーションの作成に関しては、前回の記事で記述しました(https://qiita.com/shiv76e2/items/cbb8e553ecd6c6846672)
ディレクトリ構成
“`
Containers/
├ nginx/
│ ├ Dockerfile
│ └ nginx.conf
└ uwsgi/
├ app.py
├ Dockerfile
├ requirements.txt
└ uwsgi.ini
“`
# 1. LightsailにContainerService作成
AWSの公式チュートリアルをご参照ください(https://youtu.be/eOqlLa6paCI)# 2. Nginxイメージの作成
ReverseProxyとして、ユーザーからのリクエストを受け取って、uWSGIサーバーへ返す役割をします。“`Dockerfile:Dockerfile
FROM nginx
Django ランダムかつ有効期限のあるURLを生成し、上位者に承認してもらいアカウントを発行する
## 環境
Windows 11 Home
Python 3.10.2
Django 4.0.2
venv利用あり
(PyPI)
APScheduler==3.8.1 (第2回、第3回で使用。今回は使用しない)## 関連記事
Django 第1回:[Django Custom User Model の作成](https://qiita.com/startours777/items/706d38e712b0c737a16a)
Django 第2回:[Django 初回ログイン時にパスワード変更を強制する](https://qiita.com/startours777/items/28db625a9bb81a36d4ad)
Django 第3回:[Django 一定期間パスワードを変更していないユーザにパスワード変更を強制する](https://qiita.com/startours777/items/d550ca9b67cea4408a44)
Django 第4回:[Django ランダムかつ有効期限のあるURLを生成し、上位者に承認してもらいアカウントを発行する](https://
Python3: Cognito から Access Token を取得
AWS の Cognito から JWT Access Token を取得する方法です。
AuthFlow は ADMIN_USER_PASSWORD_AUTH です。
次のページを参考にしました。
[PythonでAWS Cognito認証](https://qiita.com/jp_ibis/items/4fffb3c924504f0ce6fb)“`py:get_token.py
#! /usr/bin/python
# -*- coding: utf-8 -*-
#
# get_token.py
#
# Feb/19/2022
#
# ——————————————————————
import sys
import os
import boto3
from dotenv import load_dotenv
# ——————————————————————
def cognito_auth(p
kivyMDチュートリアル其の肆什玖 Behaviors – Touch篇
ハロー、Qiita!いかがお過ごしでしょうか。
今週は特に技術的なニュースはあまりなかった気がしていますが、オリンピックが
世間を賑わせていますね。そうなのか?ということ仰られる方もいるかと思いますが、
否定はしなく、どちらかというと私もそのような思いが近いです(どっちだ)。冬のスポーツはあまり馴染みがないので、ニュースだけを見ていますが、みなさん
の推しのスポーツはありますでしょうか。話はKivyMDに戻り、とうとう今週でエピソード1は終わりにしたいと思います。(なんそれ)
一旦はエピソード1はBehaviors章を区切りにしたいと思います。ver.1.0ももう
そろそろ出るじゃないかと思いますが、エピソード2は1.0が出たときに始動したい
と思います。どんなことやるかはまとめに書こうかなと。今日については先週からの続きで、Touch篇となります。
ではさっそくですが、今日も元気にレッツラゴ。
## Touch
なにやら冒頭に以下のような記載がありますね。
> Provides easy access to events.
なにやらおぉ、と言ってしまいそうな英
【Flask】Hello World(uWSGI + Ubuntu)
# はじめに
勉強でflaskを触ったときの、hello worldまでの手順をまとめました。
* WSL2環境を汚したくなかった&勉強のためvenvを利用
* この記事のfile/folderはすべて同じディレクトリvenv: 同じシステム上で、独立した複数のpython実行環境を生成するためのツール
uWSGI: Pythonを実行するためのアプリケーションサーバー。Flaskにも組み込みのアプリケーションサーバーがあるが、そちらはSingleThreadなので一度に一つのrequestしか捌けないため、ローカルで開発する際もuWSGIを使ったほうが好ましい。参考にしたサイト
https://riptutorial.com/flask/example/16286/using-uwsgi-to-run-a-flask-application# 1. venvで仮想Python環境構築
“`
$sudo apt update
$sudo apt upgrade
“`必要なpackageのinstall
“`
$sudo apt install python3-
テスト1
“`
import openpyxl
from datetime import datetime as dt”’
エクセルのシート名にテーブル名を設定
ヘッダ列にカラム名を設定
ファイル名は任意
”’def calc(ex):
if isinstance(ex, int):
return str(ex)
elif (ex is None) or (ex == ”):
return “””
elif ex in func_str_list:
return str(ex)
else:
return “‘” + str(ex) + “‘”func_str_list = [‘CURRENT_TIMESTAMP’, ‘NULL’]
# TODO 適宜修正
file_path = ‘input_xlsx_path’
output_path = ‘output_sql_path’
wb = openpyxl.load_workbook(filename=file_path)
ta
python websocketのパッケージ整理
# 目的
似て非なるパッケージが複数あって混乱するので整理したい。
websocket系とthread# Pypi : Python Package Index
https://pypi.org/# windows10 ファイアウォール
外部への線を抜いてローカルでファイアウォールを切る。https://pc-karuma.net/windows-10-firewall-enable-disable/#Windows_%E3%83%95%E3%82%A1%E3%82%A4%E3%82%A2%E3%82%A6%E3%82%A9%E3%83%BC%E3%83%AB%E3%82%92%E7%84%A1%E5%8A%B9%E3%81%AB%E3%81%99%E3%82%8B
ファイアウォールを有効にするならば、ポートを開ける
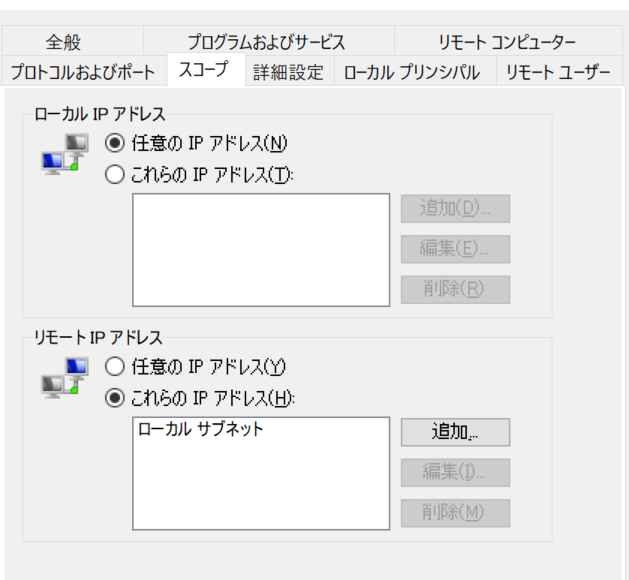# ラズパイ
Python time.sleepのsleepできるのは最小何秒?
# 結論
**0.001秒**
いちおう、スリープ時間は最小になったが、希望通りのスリープはしてくれない
# 検証
0.000~0.009のスリープ時間の計測
“`python
def minimam_sleep(milliseconds):
seconds = 0.001 * milliseconds
start_time = time.time()
time.sleep(seconds)
stop_time = time.time()
time_difference = stop_time – start_time
return time_differencefor milliseconds in range(10):
print(round(milliseconds*0.001,3), minimam_sleep(milliseconds))
“`“`
0.0 0.0
0.001 0.005999088287353516
0.002 0.016000986099243164
0.003 0
Linux上にPython+Selenium+Chromeの動作環境を構築する
#はじめに
SeleniumとはWebブラウザの操作を自動化できるフレームワークのことです。
本記事ではSeleniumを使う環境の一つとして、Linux上にPython+Selenium+Chromeの環境を構築する手順を紹介します。
#構成
今回使うLinux環境は、以下のようなインスタンスをAWSにて作成しました。|項目|設定値|
|—|—|
|プラットフォーム|Amazon Linux|
|インスタンスタイプ|t2.micro|#環境構築
以降のコマンドはデフォルトのユーザ(ec2-user)を使った場合のものとなってます。
###Python3のインストール
まず、yumのアップデートを実行します。“`
$ sudo yum update
“`
yumのアップデートが完了後、Python3のインストールを行います。
Python3をインストール時に合わせてpip3もインストールされます。“`
$ sudo yum install python3
“`
なお、Amazon Linuxではデフォルトで`python`コマンドにはPython2の方が
レコメンド指標でよく見るMAP@kとは
## 概要
– レコメンドでよく使われるメトリクスである**Mean Average Precision (MAP)**について解説する
– MAPについて説明する前にまず前提条件として**Precision@k (P@k)**、**Average Precision @k (AP@k)** についても説明する## 問題設定
– 正解を予測して並べた5個 (k=5)のデータのうち何個正解できたかを考える
– 例えば5個並べた商品のうち、実際にクリックされたのはどれだったか– 以下の例だと1番目と4番目を正解したことになる
– これを評価するメトリクスを考えたい
– 単純に5個中何個正解できたかを考えてみる (2/5)
– でも同

iptablesファイルに書いたドメインを、cronで定期的に解決しiptablesに反映する
# 本記事について
本記事は、`/etc/sysconfig/iptables`にドメイン名を直接書いたものを、iptablesに定期的に反映させる方法について私見を述べたものです。
### 環境
Amazon Linux 2
Python3# 背景
### iptablesの罠
以下のように、iptablesをドメイン名で記載している箇所がある。
変更する際は`sudo vi /etc/sysconfig/iptables`コマンドで直接編集し`sudo service iptables restart`で反映させる運用となっている。“`text:/etc/sysconfig/iptables
-A OUTPUT -p tcp -d dev.**.***.net -m owner –uid-owner userName -j ACCEPT
-A OUTPUT -p tcp -d prd.**.***.net -m owner –uid-owner userName -j ACCEPT
-A OUTPUT -p tcp -d ************.**.ne
サンプル用クラスタリング用のデータを作成しよう
# datasets.make_blobsでクラスタリング用のデータを作成
sklearn.datasetsのmake_blobs関数をインポート
from sklearn.datasets import make_blobsXには1つのプロットの(x,y)が、Yにはそのプロットの所属するクラスター番号が入る
X,Y = make_blobs(n_samples=150, # データ点の総数
n_features=2, # 特徴量(次元数)の指定 default:2
centers=3, # クラスター数
cluster_std=0.5, # クラスタ内の標準偏差
shuffle=True, # サンプルをシャッフル
random_state=0) # 乱数生成器の状態を指定
Prophetを使ってみた(予測)
前回はAnacondaのインストールからjupyter notebookが起動するところまで実施しました。今回はProphetを使った時系列データの予測をやってみたいと思います。
前回の記事はこちらから
https://qiita.com/nw-engineer/items/d167e9e193124bacfb96
## 1. データダウンロード
下記サイトより為替レート(日本円からドル)のグラフをダウンロードします。
https://fred.stlouisfed.org/series/DEXJPUS
ダウンロードしたデータは作成したDataディレクトリに保存しておきます。
## 2. 事前準備
ここからはJupyter notebook上での作業となります。必要となるライブラリをインポートしておきます。“`bash
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
“`CSVデータを読み込んで6行分表示してみます。
“`bas
Prophetを使ってみた(事前準備)
Prophetを利用した時系列データの予測などやってみたので、備忘録も兼ねて
## 1. 環境
– OS: CentOS 7.9
– kernel: 3.10.0-1160.53.1.el7.x86_64
– Anaconda: 3-5.3.1
– jupyter: 4.4.0## 2. OS最新化&ツールインストール
いつものようにOSは最新化します。また開発ツールパッケージも入れましょう。“`bash
yum update -y
rebootyum groupinstall ‘Development Tools’ -y
yum install wget -y
“`## 3. Anacondaインストール
下記サイトからAnaconda(Linuxインストール用スクリプト)をダウンロードしてインストールします。https://repo.anaconda.com/
wgetでダウンロードし、実行します。
“`bash
wget https://repo.anaconda.com/archive/Anaconda3-5.3.1-Linux-x86_64.s




