
- 1. DjangoでLine Profilerを使う
- 2. DICOM画像を.jpg/.pngファイルとして書き出し、保存する
- 3. [ Pythonanywhere ] Could not find your API token エラー解決方法
- 4. Azure Functions の Python + VSCode 環境不具合への対応
- 5. 【Selenium】IEモードでテスト自動化をしてみる
- 6. 【備忘録】PythonでMySQLに接続しよう
- 7. Pythonで使用する__name__ == ‘__main__’の意味
- 8. L2コンストラクトからL1コンストラクトにリファクタリングしたときにIDを保持する
- 9. AWS CDKでL2コンストラクトとL1コンストラクト間で依存関係を貼る
- 10. openpyxlでよく使う操作についてのまとめ
- 11. 【トリビアのDelta Lake】#4 Spark DataFrameの変換チートシートを作りました
- 12. PHPのexec()で正しくPythonを実行してるのに、なんかModuleNotFoundErrorになるんですけど!?
- 13. sort()の中身のkeyとlambdaが分からない
- 14. 【詳細編】【API × python × GitHub Actions】GithubのCommit数を自動集計するTwitterBotを作成してみよう!
- 15. Pythonで新規ファイル作成時にディレクトリが存在しなければ作成する方法
- 16. Python(pandas)を使って基本統計量から単回帰分析まで統計の復習
- 17. マクローリン展開をお勉強(おまけ)
- 18. 項目反応理論 項目母数の推定誤差
- 19. pillow(PIL)でメモリイメージを扱う
- 20. 整数数学A「2022年一橋大学前期第1問」2^a*3^b+2^c*3^d=2022を,エクセルvbaとsympyで
DjangoでLine Profilerを使う
## Line Profilerとは
プログラムを行単位でプロファイリングできるモジュールです。今回はDjangoアプリ内で行ごとの処理時間を計測し、コンソールに表示させてみます。## Line Profilerの使い方
### 1. Line Profilerをインストール
“`terminal
$ pip install line_profiler
“`
インストール後は $ pip freeze > requirements.txt しておくと良いでしょう。### 2. 処理時間を計測したいファイル(views.pyなど)に下記を追加
“`python:views.py
# Line Profiler
import line_profiler
import atexitprofile = line_profiler.LineProfiler()
atexit.register(profile.print_stats)# 測定したい関数にアノテーションを付ける
@profile
def foo():
…
“`### 3. runserverす
DICOM画像を.jpg/.pngファイルとして書き出し、保存する
## 1. Pillowをインストールする
“`terminal
$ pip install Pillow
“`
## 2. ファイルに書き出し、保存する
png形式で保存したい場合は、拡張子を .png にしてください。
“`python: sample.py
import pydicom
from PIL import Image# dicomファイルを読み込む
file = pydicom.dcmread(‘ファイルパス’)
# 画像処理
img = file.pixel_array
pil_img = Image.fromarray(img)
# 保存したい場所、ファイル名を引数に設定
pil_img.save(‘ファイルパス/original_dcm.jpg’)
“`## 3. 補足
### ■ TypeError: Cannot handle this data type
ndarrayのデータ型がdtypeやfloatの場合はエラーになることがあります。この場合、unit8に変換すると解決します。
“`python:sample.py
import n
[ Pythonanywhere ] Could not find your API token エラー解決方法
解決方法
API Token を発行する。
・手順
1 Pythonanywhere ログイン
2 Dashboard > Account > API Token に進み API Token を作成する。
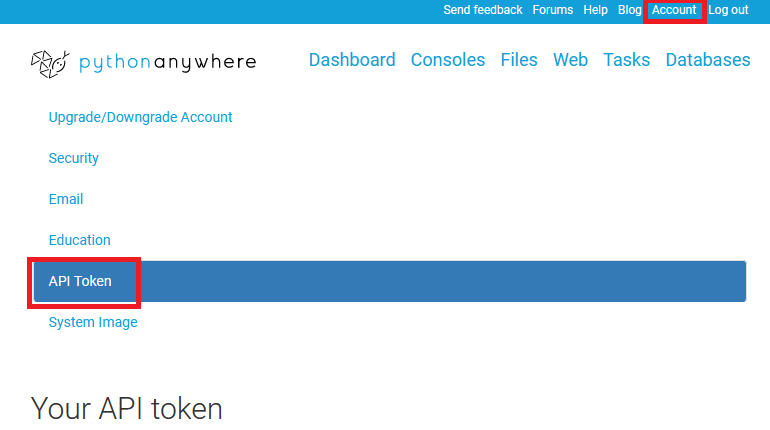3 exit コマンドでコンソールを終了しログアウトする。
4 再度ログインしコンソールにてコマンドを実行する。エラーメッセージ
pythonanywhere.exceptions.SanityException: Could not find your API token. You may need to create it on the Accounts page? You will also need to close this console and open a new one once you’ve done that.
Azure Functions の Python + VSCode 環境不具合への対応
解消にすごく苦しめられたので個人のメモとして置いておきます。
他にもこうやれば解消したよ、という情報があれば是非共有したいです。# デバッグ実行時にECONNREFUESED:127.0.0.1:9091
Python実行環境へアタッチできない、というエラーなのはぱっと見で想像できますが、その原因が多種多様すぎて解決が大変なエラーです。(以前に比べてこのエラーが出ることは減ったようです)
## 1. Python のバージョンを対象のものにする
2022/4現在では、ver.3.7, 3.8, 3.9 なら動きます。3.10は対象外です。気を付けましょう。64bit マシンでの開発の場合は(大抵はもう64bitだと思いますが)、64bit 版を選ばないとデバッグ実行ができないそうです。(32bit 版を使ったことがないので本当にデバッグ実行できないのかは不明です)
## 2. Azure Function Core Tools を ver.3.x にする
ver.3.x と ver.4.x の2種類がありますが、ver.4.x でうまくいかないときは ver.3.x にし
【Selenium】IEモードでテスト自動化をしてみる
2022年6月15日にIEのサポートが終了するということで、他のブラウザに移行する方も多いかと思われます。
その移行先の1つにEdgeのIEモードがあります。[Qiitaの記事](https://qiita.com/skwbr/items/456a341715a90c166093)によると、2029年までサポートしてくれるとの事です。自動テストツールでは、このIEモードに対応しているツールは少ないです。
その1つに[Selenium](https://www.selenium.dev/ja/documentation/)があります。
今回は、そのSeleniumを使って自動化してみたいと思います。## お伝えしたいこと
いくつか設定の変更や制約がいくつかあるが、SeleniumでEdgeのIEモードを動かすことは可能
## 今回実装した環境
| 項目 | バージョン |
|:———–|:————|
| OS | Windows 10 pro |
|ブラウザ | バージョン 100.0.1185.29 (公式ビルド
【備忘録】PythonでMySQLに接続しよう
# 経緯
Pythonを使用してMySQLからデータを取得したい。
DBの列構成が変わっても結果に変化がないよう、辞書型を採用した。# ライブラリインストール
~~~cmd:cmd
python -m pip install pymysql
~~~# ソース
~~~python:python
import pymysqlSQL=”SELECT * FROM userlist;”
mysql_kwargs = {
“host”: “127.0.0.1”,
“port”: 3306,
“user”: “testuser”,
“password”: “test”,
“database”: “testdb”,
}conn = pymysql.connect(**mysql_kwargs)
# カーソルを取得する(辞書型)
cur = conn.cursor(pymysql.cursors.DictCursor)# SQL実行
cur.execute(SQL)# 実行結果を取得する
rows = cur.
Pythonで使用する__name__ == ‘__main__’の意味
## 概要
Pythonを学習していると`__name__ == ‘__main__’`という謎の構文が出てきて、
それについて調べたのでアウトプットしたいと思います。## 使い方
`__name__ == ‘__main__’`は簡単に言うとファイルを読み込んだ際に
関数などの実行を制御してくれるものです。
例えば下記のようなファイルがあるとします。“`sample.py
def hello():
print(“Hello!”)hello()
“`
`hello()`を別ファイルで使用しようとしたときファイルをimportします。“`example.py
from sample import hellohello()
“`
このとき`example.py`ファイルを実行するとどうなるか“`
python example.py // pyファイルの実行コマンド
// => Hello!
Hello!
“`
`Hello!`が2度表示されてしまいます。
これはファイルをimportすると読み込み先のファイルに記載されている関数が実行され
L2コンストラクトからL1コンストラクトにリファクタリングしたときにIDを保持する
“`python
l2_resource.node.default_child.override_logical_id(id)
“`# 参考
* https://bobbyhadz.com/blog/override-logical-id-aws-cdk
* https://docs.aws.amazon.com/cdk/api/v1/python/aws_cdk.core/CfnResource.html#aws_cdk.core.CfnResource.override_logical_id
* https://docs.aws.amazon.com/cdk/api/v1/python/aws_cdk.core/ConstructNode.html#aws_cdk.core.ConstructNode.default_child# メモ
aws-glue.Jobの場合はdefault_childでCfnJobにアクセスすることができた。
が、default_childの説明を読んでもよくわからず。わかったら追記する。
AWS CDKでL2コンストラクトとL1コンストラクト間で依存関係を貼る
“`python
l1_resource.node.add_dependency(l2_resource)
“`
リソース.nodeに対して処理を行えばよい。# 参考
* https://docs.aws.amazon.com/cdk/api/v1/python/aws_cdk.core/ConstructNode.html#aws_cdk.core.ConstructNode.add_dependency
openpyxlでよく使う操作についてのまとめ
pythonでExcel操作をする際に使用する`openpyxl`でのよく使う操作について備忘録的にまとめました。
# インストール
“`shell
pip install openpyxl
“`# ファイル操作
Excelファイルの新規作成
“`python
wb = openpyxl.Workbook()
“`Excelファイルの読み込み
“`python
wb = openpyxl.load_workbook(‘input_file.xlsx’)
“`Excelファイルの読み込み(数式の計算結果を読み込む場合)
“`python
wb = openpyxl.load_workbook(“input_file.xlsx”, data_only=True)
“`Excelファイルの保存
“`python
wb.save(‘input_file.xlsx’)
“`# シートの操作
シートの新規作成
“`python
ws = wb.create_sheet(title=’hoge’)
“`sheetオブジェクトの取得
“`p
【トリビアのDelta Lake】#4 Spark DataFrameの変換チートシートを作りました
# Spark DataFrameはいろいろな形に化ける
DatabricksやPysparkを使っていると必ず扱うことになる、Spark DataFrame。これはいろいろな形に化けるし、その化けた先から再度Spark DataFrameに戻すこともできたりします。
このいいところは、同じデータに対して、汎用スクリプト言語であるPythonと、データベース言語であるSQLを自由に使い分けられるということ。
Pythonのいいところ、SQLのいいところを両方使えます。Pythonで無理そうな処理にぶち当たったなら変換してSQLを使い、SQLじゃ非効率だと思えばPythonに切り替える、などなど。ただ、その変換にあたって「これどのコマンド使えばいいんだっけ?」と迷い、そのたびに過去の自分が書いたスクリプトや公式ドキュメントを確認するのがちょっと無駄に感じたので、Spark DataFrameの変換チートシートを作成しました。
これで「Spark DataFrameエコノミー」(勝手に名付けた)を攻略していきましょう!
(もし内容にミスがあったら、ぜひコメントでご意見お願いしま
PHPのexec()で正しくPythonを実行してるのに、なんかModuleNotFoundErrorになるんですけど!?
## はじめに
みなさま、PHP使っていますか。PHPからPythonを呼び出す用事があり、やむなくPHPで外部プログラムを実行できるexec()を使いました。
自称PHPerとしては断腸の思いの決断です。cronやシェルスクリプトなど、こういう系では**フルパス**を使うのが定石と存じ上げています。
なので
“`php
$path=”/usr/bin/python3 /…フルパス/.py”;
“`
として、exec()に渡しました。
“`php
exec($path,$output);
“`
## パスは正しいのに、動かないときがある?
ちゃんとPythonのコードは実行されていて、print文だけみたいな**簡単なコード**なら動くんです。
ちゃんと$outputにprint()などで入れた標準出力が帰ってきています。でも本来動かしたい、少し規模の大きいコードを動かすと$outputがすっからかんに……
これはどこかでエラーが出ている可能性大なので、エラーを出させてみます。
このような形で
“`php
$path=”/usr/bin/python3 /
sort()の中身のkeyとlambdaが分からない
## sort()のlamdaって何者?
python3エンジニア認定基礎試験問題集に以下のようなコードの記載があります。
“`
toshi_code = [(42, ‘naga’), (41, ‘saga’), (40, ‘fuku’), (43, ‘kuma’)]
pref = toshi_code
pref.sort (key = lambda pref: pref[0])
print( pref)>>>[(40, ‘fuku’), (41, ‘saga’), (42, ‘naga’), (43, ‘kuma’)]
“`
outputがなぜこうなるのかわからなかったので、公式ドキュメントを漁ってみました。### pref.sort(key=lambda pref: pref[0])の解説
まずは[sort()の公式ドキュメント](https://docs.python.org/ja/3/howto/sorting.html)を確認します。
すると、このような記述が。
「list.sort() と sorted() には key パラメータがあります
【詳細編】【API × python × GitHub Actions】GithubのCommit数を自動集計するTwitterBotを作成してみよう!
# はじめに
[Nara](https://twitter.com/besumero628)と申します。DMMWEBCAMPで勉強後、2022年1月より都内の受託会社で勤務を始めました。この記事では、
pythonをベースに、APIでgithubのcommit数の算出と、twitterの自動投稿を行い、github Actionsでそれらを自動化する方法をお伝えします。
(ただし、pythonの知識が少ないことに加え、勢いで書いているので煩雑なコードになっていることをお許しください。)日々githubでcommitを重ねて頑張っているあなた。
Twitterにcommit数を記録していきませんか?
また、その努力をフォロワーに共有して成果をアピールしませんか?# この記事の対象
こちらの記事は詳細編ということで、以前投稿した簡易編を掘り下げてコードの解説を行います。
1からBotを作成してみたい。APIをどのようにして使用しているのか知りたいといった方が対象です。# 1からの作成は嫌ですという方へ
https://github.com/besumero628/git
Pythonで新規ファイル作成時にディレクトリが存在しなければ作成する方法
よく使用する便利な書き方なので備忘録として。
`os.makedirs`は`exist_ok=True`とすると、既に存在するディレクトリに対しては何もしない。
引数がディレクトリなので、pathが出力ファイルの場合は以下のように指定する。“`python
path = ‘piyo/hoge/hoge.txt’
os.makedirs(os.path.dirname(path), exist_ok=True)
“`## 参考
https://note.nkmk.me/python-os-mkdir-makedirs/
Python(pandas)を使って基本統計量から単回帰分析まで統計の復習
# はじめに
機械学習やDeeplearningなどを勉強していると実装モデルに目がいきがちですが、データを扱う以上、基本的な統計を知っておく必要があります。また、わざわざ難しいモデルを持ち出さなくても集計レベルでもわかることがたくさんあります。
と言いつつ、大学で勉強したことを忘れているので、手元にあった参考書を片手にPythonとそのライブラリであるpandasを使って統計の初歩を復習しようと思います。
たまたま、データ共有プラットフォーム「delika」のデータに関する記事を書こう!キャンペーンがあったので、それに乗っかることにしました。# ゴール
CSV形式の数値データに対して、基本統計量の出力、集計、散布図、単回帰分析まで行い、統計的手法の基本をおさらいします。
※個別の詳細は公式ドキュメントへのリンクを貼ります。delikaを使う
https://delika.io/qiita_delika_article_campaign/QiitadelikaDummy/articles.csv# 実行環境
・Windows10
・Python 3.8.5
・panda
マクローリン展開をお勉強(おまけ)
### [前回「マクローリン展開をお勉強(Python)」](https://qiita.com/yellow_detteiu/items/d0c10d7158a620a08144)の続きです。
“`Python:McLaughlin2.py
import numpy as np
import matplotlib.pyplot as pltdef kaijyo(n):
result = 1
for i in range(1, n+1):
result *= i
return resultdef sin(x, n):
result = 0
for i in range(1, n+1):
result += (-1)**(i+1) * (1 / kaijyo(2*i-1)) * x**(2*i-1)
return resultdef cos(x, n):
result = 1
for i in range(1, n+1):
result += (-1)**(i
項目反応理論 項目母数の推定誤差
## 目的
以前、2PLの母数の推定するためのEMアルゴリズムは実装していたのですが
Rとの比較はしていなかったので、備忘録として記録しておきます。## 使用するデータ
使用するデータは豊田先生の書籍である[項目反応理論[入門編]](https://www.asakura.co.jp/detail.php?book_code=12795)から、学力テスト1を使用しています。
また項目のいくつかは、書籍の手順に則り、削除しています。
その上で残った30個の項目を自作の関数(Python)とRのltmパッケージにより、識別力と困難度を推定し値を比較します。## Pythonの実行結果
[pythonで推定する際に作成した関数](https://github.com/ttksaito/test/blob/master/IRT_EMstep.ipynb)
[Rで推定する際に使用した関数](https://cran.r-project.org/web/packages/ltm/ltm.pdf)| 項目 | python_推定値a | R_推定値a | python_推定値b |
pillow(PIL)でメモリイメージを扱う
# メモリ上で画像を弄りたくなる時もたまにある。
そう、たまにあるんです。
大体は速くなるからね、やりたくなるよね。なので簡単に使えるように作ってみた。
“`python:arrayimage.py
from PIL import Image, ImageTkclass ArrayImage:
def __init__(self, size=(10, 10)):
self.sizeW = int(size[0])
self.sizeH = int(size[1])
self.size = (self.sizeW, self.sizeH)
self.byteData = bytearray(self.sizeW * self.sizeH * 3)def image(self):
return ImageTk.PhotoImage(Image.frombytes(“RGB”, self.size, bytes(self.byteData)))def in
整数数学A「2022年一橋大学前期第1問」2^a*3^b+2^c*3^d=2022を,エクセルvbaとsympyで
# 問題
https://nyushi.sankei.com/honshi/22/ht1-21p.pdf
# 解答
一橋の問題は素直であるが、誘導も少なく、難易度は高い。 < 河合塾分析より
難易度標準で解答2頁でした。https://kaisoku.kawai-juku.ac.jp/nyushi/honshi/22/ht1-21a.pdf
整数問題の基本事項…地道な作業が必要なところもあります。 < わか様より
https://waka-blog.com/?p=4285
# エクセルvbaで
あっという間に結果がでました。エクセルすごいですね。
“`vb
‘nMax = 2022
‘実行時エラー ‘6’:
‘オーバーフローしました。
Sub aaa_main()
nMax = Int(Log(2022) / Log(2)) + 1
ActiveSheet.Cells.Clear
MsgBox “実行を開始します”
iR = 0
For i = 0 To nMax
For j = 0 To nMax
For k = 0 To nMax
For l = 0 T




