
- 1. vscodeに導入したblackが機能しない
- 2. argparseのノート
- 3. 【トリビアのDelta Lake】#5 Pysparkで破産しないためにGoogle Colabにて無料で使う
- 4. 40代おっさんpythonでGoogleスプレッドシートを操作してみる
- 5. Python アプリをパッケージングしてあとで python コードを差し替えたいメモ
- 6. 典型90問 001 Yokan Party をPythonで解く!
- 7. これから更に流行るであろうフォトリアルな世界について勉強しよう
- 8. 初心者プログラマが1年でAIコンペで入賞し、IT大手に入社するまで。
- 9. Word2VecのCBOWをPyTorchで実装する
- 10. 【python】restAPI実行でconcurrent.futuresを使ってみた
- 11. ColaboratoryでBigQueryにアクセスする一番楽な方法
- 12. EfficientNetV2で転移学習・ファインチューニングする
- 13. 統計的推定と検定をPythonで解く「区間推定(正規母集団で母分散未知の場合)」
- 14. データを触ってみたいけどどこから手をつけよう??という趣味人の覚書
- 15. PycordでSlashcommandのファイル分割の仕方
- 16. LINE Messaging APIとPython FastAPIでメッセージ応答Botを作る
- 17. 広告でよく見る試験管パズルゲームをプログラムで解いてみた
- 18. kivyで作成したアプリをテストする際の”ModuleNotFoundError”の対処法
- 19. DjangoでLine Profilerを使う
- 20. DICOM画像を.jpg/.pngファイルとして書き出し、保存する
vscodeに導入したblackが機能しない
## はじめに
[これ](https://qiita.com/tsu_0514/items/2d52c7bf79cd62d4af4a)と[これ](https://qiita.com/sin9270/items/85e2dab4c0144c79987d)を参考にflake8とBlackを導入したものの、保存時にblackの自動整形が行われない## 状況
setting.jsonを以下の様に設定
“`json:settings.json
{
“python.linting.enabled”: true,
“python.linting.pylintEnabled”: false,
“python.linting.flake8Enabled”: true,
“python.linting.lintOnSave”: true,
“python.formatting.provider”: “black”,
“editor.formatOnSave”: true,
“editor.formatOnPaste”: false,
argparseのノート
# narg
`nargs=*`で引数が無い時の挙動が位置引数とオプション引数で違う.
“` python test.py
parser = argparse.ArgumentParser()
parser.add_argument(‘infile’, nargs=’*’)
parser.add_argument(‘-f’, ‘–foo’, nargs=’*’)
args = parser.parse_args()print(args.infile)
print(args.foo)
“`引数なしで実行
“` zsh
python3 test.py[]
None
“`
位置引数は空のリストになるが,オプション引数はNoneになる.`-f`だけつけて引数なしの場合
“` zsh
$ python3 test.py[]
[]
“`
この場合は空のリストになる.# helpをプリントする方法
“` python test.py
parser = argparse.ArgumentParser()
parser.add_argument(‘infil
【トリビアのDelta Lake】#5 Pysparkで破産しないためにGoogle Colabにて無料で使う
# Pysparkで破産?
Databricksでは、Clusterという有償のコンピューティングリソースを用いてデータソースにアクセスしたり、プログラムを動かしたりします。Clusterは**従量課金制**であり、その単位はDBUというもので表されます。
契約形態やClusterの種類にもよりますが、およそ1DBUは0.15~0.65ドル。ドルです。Clusterはデータ量の大きさに応じれるようさまざまなマシンのサイズが用意されていますが、一番よく使うサイズであるi3 Xlargeインスタンスの3ノード(90GBくらい)で、だいたい1時間3DBU、つまり2ドルくらいです。
https://databricks.com/jp/product/aws-pricing
そしてClusterの裏側は自前で契約しているクラウドのコンピューティングリソース(AWSならEC2)なので、その料金もかかってきます。
だいたいDatabricks Cluster料金の等倍か、それ以下くらいだそうな。なのでDatabricksでは、Sparkのメリットを受けられるほど大きくないデータを扱う
40代おっさんpythonでGoogleスプレッドシートを操作してみる
## 本記事ついて
本記事は プログラミング初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。## GCPに登録してAPIの有効化して使えるようにする
・Googleアカウントが必要になる
Google Cloud Platformを開いて登録を行う
### My First Projectを選んで新しいプロジェクトを選ぶ
プロジェクトを記入
場所は組織なし
*会社に属している場合は必要かも右上に通知が出てきます
作成出来たらプロジェクトを選択
プロジェクトに飛ぶと思います。
上のタスクバーが自分のプロジェクト名に変わっていると思います### APIを有効化
左に「APIとサービス」という欄があると思いますのでそこをクリック
「APIとサービスの有効化」という項目が出てきたと思うのでそれをクリック
*最初はすべて無効になっていると思います必要な下2つのAPIを有効化
Google Drive API
Google Sheets APIAPI
Python アプリをパッケージングしてあとで python コードを差し替えたいメモ
## 背景
numpy とか torch とか入ったアプリを単体で配布したい.
pyinstaller で .exe とパッケージ作れるが, バグとか修正とかあって一部差し替えしたいが作り直しになってつらい.
(.exe だとアンチウイルスチェックかかったりして毎度配布がめんどい)py だけ差し替えしたい
## とりあえずの方法
exec でがんばります.
“`py
# mymodule.py
def bora():
print(“hello”)
“`“`py
# main.py
def main():import mymodule
exec(open(“custommod.py”).read())main()
“`“`py
# custommod.py
def myfunc():
import mymodule
mymodule.bora()myfunc()
“`main.py とかに自前アプリのカスタム module がある場合は import しておきましょう.
そうしないと pyins
典型90問 001 Yokan Party をPythonで解く!
# はじめに
AtCoder現在茶色(年内には緑が目標!)のあんこちゃん(@Chunky_RBP_chan)です。
典型問題は抑えとかねばということで、★2〜★5に取り組んでいます。
Pythonで取り組まれている方も多いと思うので自分の解答をシェアしたいと思います!
# 001 Yokan Party
https://atcoder.jp/contests/typical90/tasks/typical90_a## 解法
https://github.com/E869120/kyopro_educational_90/blob/main/editorial/001.jpg解法については出題者E869120(@e869120)の説明が非常にわかりやすかったので、この解法通り実装します。
簡単な説明としては、①最小の長さを決め、何個に分割できるか確かめる
②K+1個より多く分割できれば最小の長さを大きくする。K+1より少なければ最小の長さを小さくする。これを二分探索によって実装します。
K+1個に分割可能な数a,b,c(a <= b <= c)があった場合にcが選ばれる
これから更に流行るであろうフォトリアルな世界について勉強しよう

去年Googleが発表した「Total Relighting」
一枚の画像から、人物を切り出し、背景に合わせて人物のライティングを自動で調整する手法。・・・らしいのですが。すごいですよね。
フォトリアルというと、最近は3D分野の目覚ましい発展を連想しますが、
3Dはどうしても装置や機材に依存するイメージが付きまといます。
もしもiphoneなどの単眼カメラで実現できるようになれば、
表現の世界はさらに次のステージに進めそうです。ということで今回はそんな「フォトリアル」な世界について勉強します。
できるだけ数式と実際のソースに基づいて理解を深めていきます。(目標)このページはちまちまと更新していくと思うのでよろしくお願いします。
新規作成:2022/04/08参考:
https://google.github.io/filamen
初心者プログラマが1年でAIコンペで入賞し、IT大手に入社するまで。
# はじめに
この記事は私がプログラミング初心者からIT大手にエンジニアとして内定されるまでの流れを、使用していた学習ツールや参加したイベントなどを紹介しながら振り返ります。2019年10月にプログラミングを始めて2020年11月に内定をもらったので、約1年間の軌跡を時系列順に振り返ってみます。# きっかけ (2019年10月)
まず、なぜ未経験者の私がプログラミングを始めようと思ったのかを説明します。
私は大学時代、経営学部情報システム科に所属していました。といっても、「少しITに詳しい経営学部生」くらいのスキルセットでした。
就活生時代、BIG4の企業説明会を受けていると「経営学部で情報システム科なのはいいけど、結局君は何ができるの?」と問われた事があります。
その時私は経営学部でしたが長期インターンの経験もなく、情報システム科なのにプログラミンを触った事がありませんでした。そこで私は、他の就活生との差別化の意味も含め、プログラミングの学習を始めました。
(初めはプログラミングもできるビジネスマンを目指していたのですが、いつの間にか、プログラマの方がメインになっていました。)
Word2VecのCBOWをPyTorchで実装する
Word2Vecといっても、その実装には色んなバリエーションがあるそうですが、その中の CBOW (Continuous bag-of-words) ってのを PyTorch で実装してみました。あくまで勉強用であって、実用向きではありません。
# 学習済みモデルを Google Colaboratory に保存するための準備
次のようにして Google Colaboratory にマウントします。
“`python
from google.colab import drive
drive.mount(‘/content/drive’)
“`Mounted at /content/drive
学習済みモデルを保存するためのディレクトリを指定します。なければ作ります。
“`python
import osdirectory_path = ‘./drive/MyDrive/word2vec3/’
if not os.path.exists(directory_path):
os.makedirs(directory_path)
“`#
【python】restAPI実行でconcurrent.futuresを使ってみた
## はじめに
こんにちは。ジールの@________________-_です。ネットワークアクセス処理にはマルチスレッド処理が有効という記事や本をよく見かけますが、
restAPIを利用してデータ送信する機会がありましたので、実験としてどの位速度が変わるのか計測してみました。
以下3つのパターンで比較しました。– マルチプロセス処理:`concurrent.futures.ProcessPoolExecutor`を利用。
– マルチスレッド処理:`concurrent.futures.ThreadPoolExecutor`を利用。
– 単純なループ処理:`for`ループを利用。## 環境
– マシン:MacBook Pro 13inch 2020
– CPU:2GHz Quad-Core intel Corei5
– Mem:16GB## 処理時間の計測
以下のコードを実行して、100回と1000回のリクエストで比較してみました。“`py
import concurrent.futures
import timeimport requests
def
ColaboratoryでBigQueryにアクセスする一番楽な方法
## 公式のBigQueryのクライアントAPIを使う
ColaboratoryはGoogleアカウントがあれば使える
さらにこのアカウントはGCPアカウントとしてユーザーの認証を事前に通しておく必要がある## 実際にデータを取得してみる
ColaboratoryではGCP関連のライブラリはディフォルトでインストールされているので、`pip install`等は書く必要がない
Colaboratoryでは不要だが、Colaboratory以外で実行する場合には下記を実行する必要がある
`pip install –upgrade google-cloud-bigquery`今回はウマ娘というソーシャルゲームのデータベースからデータを取得する体でpythonコードを書いてみた
“`python:qiita.rb
from google.cloud import bigquery
project_id = ‘uma_musume-2021’
client = bigquery.Client(project=project_id)# 実行するクエリ
query = “””
EfficientNetV2で転移学習・ファインチューニングする
# はじめに
tensorflow2.8を利用できる環境構築が完了したので、勉強がてらEfficientNetV2の学習済みモデルで転移学習・ファインチューニングを試してみました。
– 環境
OS: Ubuntu18.04LTS
CPU: Intel® Core™ i7-8700 CPU @ 3.20GHz × 12
GPU: GeForce RTX2080
Python: Python3.7.9(Anacondaで作成した仮想環境)
tensorflow:2.8.0
matplotlib:3.5.1– 参考記事
① [TensorFlow, Kerasで転移学習・ファインチューニング(画像分類の例)](https://note.nkmk.me/python-tensorflow-keras-transfer-learning-fine-tuning)
② [tensorflow2.0 + kerasでGPUメモリの使用量を抑える方法](https://qiita.com/studio_haneya/items/4dfaf2fb2ac44818e7e0)
③ [転移学習でCIF
統計的推定と検定をPythonで解く「区間推定(正規母集団で母分散未知の場合)」
先日は、Pythonで「区間推定(正規母集団で母分散既知の場合)」を行いました。コード的には、stats.norm.interval 関数を用い母平均の信頼区間を求めるだけです。その引数として「信頼度:alpha」「標本平均:loc」「標準誤差:scale」を必要としました。基本は標準化得点$Z$について、
$P(−1.96≤Z≤1.96)=0.95$
が成り立つため、母分散の信頼区間を求めるために上手い具合に式を変形して求められるのでした。前回の記事
[統計的推定と検定をPythonで解く「区間推定(正規母集団で母分散既知の場合)」](https://qiita.com/tan0ry0shiny/items/e4b04a508873e83c7fc6)今回は、「区間推定(正規母集団で母分散未知の場合)」について解いていこうと思います。今回も「[とけたろうさんのチートシート](https://toketarou.com/cheatsheet/#toc16)」を使わせて頂きます。今回の問題も前回に引き続き電球の寿命を調べる問題になっています。全く同じ題材を少し変えて出し
データを触ってみたいけどどこから手をつけよう??という趣味人の覚書
## この記事は何
世の中でデータサイエンスが持て囃され幾星霜、皆さんいかがお過ごしでしょうか。
「私もキラキラしたデータサイエンティストになりたい :star2: 」なんて思うことはあっても、そこから一歩も踏み出せない。そんなことも多々あるでしょう。**この記事はそんな方の背中を押すほど大層なものではございません** :laughing:
私のような「ちょっと遊びでデータを触ってみたいんだけど :rabbit: 」ぐらいの方に向けて、少し情報をまとめたものです。気が向いたら適宜追記・編集をしていきたいと思ってはいますが、過度な期待は後禁物 :no_entry_sign:
## お品書き
– データの集め方
– データ処理基盤
– データの前処理
– データの可視化
– データの活用## データの集め方
私も含め、趣味データ分析erにとってはここが最初の鬼門ではないでしょうか?何をしたいかにもよりますが、まずデータ分析を試みてみたいのであれば例えば次のような選択肢があるかと思います。– まとめられたデータを使う
– オープンデータのデータセットを活用
PycordでSlashcommandのファイル分割の仕方
## やりたいこと
DiscordのBotを作っていると思い付きでコマンドを追加したくなってくることが多々あります。(N=1的な感想)
そうなってくると1つのpythonファイルの中にコマンドを追加していくと死ぬほど読みづらくなってしまいます。なので、コマンドごとにファイル分割をしようって感じのはなしです。
#### 前提環境
– Python 3.10.4
– py-cord 2.0.0b5## Cogを利用したファイルコマンド読み込み
**Bot commands framework**の**Cogs**を利用することができます。
https://docs.pycord.dev/en/master/ext/commands/cogs.html
従来のprefixを定義して利用するBOTだと以下の記事のような方法です。
https://qiita.com/sizumita/items/c58170b72790df8ba417
このままだとSlashcommandでは利用できないので、以下の動画を参考にして変更をしました。
https://www.
LINE Messaging APIとPython FastAPIでメッセージ応答Botを作る
LINE Messaging API からPytohn FastAPIを介して
メッセージをやり取りするLINE Botを作成します。
メッセージの応答はFlexMessage形式で表示するようにします。
Web APIは西暦か和暦で年を送信すると西暦・和暦・干支の情報を返すようにします。# 開発環境
VS Code
Heroku CLI
Python 3.x
FastAPI
LINE Developers# 前提
VS Code、Pythonのインストールは事前に行い、Pythonプログラムを実装する環境を用意しておいてください。
(参考: Windows環境)
https://www.python.jp/python_vscode/windows/index.html# 完成イメージ
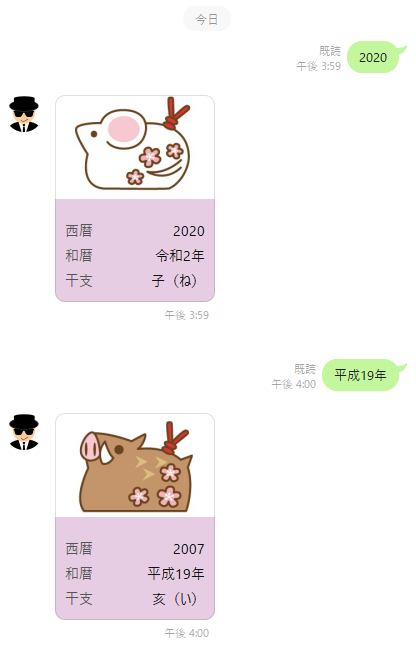# LINE Deve
広告でよく見る試験管パズルゲームをプログラムで解いてみた
# はじめに
上の画像のような試験管に入ったバラバラの色を揃えるパズルゲーム。water sort puzzleという名前で、世界的にもそこそこ名の知れているフリーゲームだそうです。
最近、暇つぶしにと思ってアプリを入れてプレイしたのですが思いのほか面白くてハマりました。そこで、完全に趣味なのですが、このパズルを解くソルバーを作ってみました。
ソルバーのアルゴリズムとしてはグラフ探索のA*アルゴリズムを使用します。# 実装
## 方針
試験管クラス(Tube)と、試験管クラスを変数に持つボードクラス(Board)を実装します。
シャッフル済みboardを受け取り、最終状態までの手順を探索するsolv関数を実装します。
A*アルゴリズムなので、各時点における盤面の終点までの推定コストが必要で、それはevaluate_boardという関数に
kivyで作成したアプリをテストする際の”ModuleNotFoundError”の対処法
# 環境
– kivy-ios:12.5
– Xcode:13.3# ModuleNotFoundErrorについて
kivy-iosによって作成したプログラムをXcodeからエミュレーターや実機に転送し,アプリを起動しようとすると`ModuleNotFoundError: No module named ‘{モジュール名}’`
というエラーが発生し,アプリが起動しないということがあります.
ex:`ModuleNotFoundError: No module named ‘requests’`
# 解決方法
`toolchain create`を行ったディレクトリで,“`sh:bash
$ toolchain pip install <モジュール名>
“`
を行う.例えば,
“`sh:bash
$ toolchain pip install requests
“`# 参考
– [YouTube: iOS App in Python with Kivy – Part 14: Run It On Your iPhone!](https://www.you
DjangoでLine Profilerを使う
## Line Profilerとは
プログラムを行単位でプロファイリングできるモジュールです。今回はDjangoアプリ内で行ごとの処理時間を計測し、コンソールに表示させてみます。## Line Profilerの使い方
### 1. Line Profilerをインストール
“`terminal
$ pip install line_profiler
“`
インストール後は $ pip freeze > requirements.txt しておくと良いでしょう。### 2. 処理時間を計測したいファイル(views.pyなど)に下記を追加
“`python:views.py
# Line Profiler
import line_profiler
import atexitprofile = line_profiler.LineProfiler()
atexit.register(profile.print_stats)# 測定したい関数にアノテーションを付ける
@profile
def foo():
…
“`### 3. runserverす
DICOM画像を.jpg/.pngファイルとして書き出し、保存する
## 1. Pillowをインストールする
“`terminal
$ pip install Pillow
“`
## 2. ファイルに書き出し、保存する
png形式で保存したい場合は、拡張子を .png にしてください。
“`python: sample.py
import pydicom
from PIL import Image# dicomファイルを読み込む
file = pydicom.dcmread(‘ファイルパス’)
# 画像処理
img = file.pixel_array
pil_img = Image.fromarray(img)
# 保存したい場所、ファイル名を引数に設定
pil_img.save(‘ファイルパス/original_dcm.jpg’)
“`## 3. 補足
### ■ TypeError: Cannot handle this data type
ndarrayのデータ型がdtypeやfloatの場合はエラーになることがあります。この場合、unit8に変換すると解決します。
“`python:sample.py
import n




