
- 1. condaでライブラリインストールする手順
- 2. 線形漸化式の値を行列を使って求める
- 3. 統計的推定と検定をPythonで解く「母平均の検定(正規母集団で母分散未知の場合)」(2020.4.21)
- 4. Python学習記録_1日目.Pythonの基本構文について
- 5. Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記
- 6. pythonで「統計学入門」5 正規分布からの標本
- 7. pythonで「統計学入門」4 標本分布
- 8. DataFrame を Validation する pandera 入門
- 9. FlaskのBlueprintを使ったひな形
- 10. FastAPIでホットリロードを有効にする方法(2パターン)
- 11. Python: Selenium: Dockerで、Chromeブラウザ最新版が動く仮想環境を立てて、24時間自動WEBサーフィンさせる環境の基礎を作る
- 12. TensorFlowでALICesを判別(顔判定モデル作成)
- 13. OpenCVに加わった深層学習ベースの顔検出・顔照合のデモ用のサンプル
- 14. Python: Selenium: 自分のMacのChromeブラウザ設定を使って自動WEBサーフィンするプログラミング
- 15. pythonでの設定ファイルの作り方
- 16. venv 環境での OpenCVのインストール上の注意点
- 17. 【Python】Excel、Word、PowerPointの図形処理をしたら嵌った話
- 18. pythonのosモジュールを初めて調べた備忘録
- 19. delikaを使って日本の名山情報を見てみた
- 20. 3D空間で紙飛行機を回転(オイラー角)
condaでライブラリインストールする手順
command prompt (anaconda)を管理者権限で起動して以下実行
“`conda-init.cmd
conda activate base
conda init
conda install [library-name]
“`
線形漸化式の値を行列を使って求める
**【例題】数列$t_n$が以下の漸化式で表されるとき$t_{10^{12}}$ mod $10^4$を求めよ**
“`math
t_0=0, t_1=t_2=1, t_3=4 \\
\large t_n = 2t_{n-1}+2t_{n-2}-2t_{n-3}+t_{n-4}
“`
この問題は$n$の値が$10^{12}$と非常に大きいのとmod計算がキーとなります。### 再帰プログラム
まずは安易に再帰プログラム。lru_cacheを付けても$10^3$で撃沈。“`python
from functools import lru_cache
@lru_cache(maxsize=None)
def t(n):
if n < 4: return [0,1,1,4][n] return (2*t(n-1)+2*t(n-2)-2*t(n-3)+t(n-4)) % 10**4 print(t(10**2)) # 8344 ``` ### ループ実装 次にサイクルバッファでループ実装。 なんとか$10^8$までが精いっぱい。 ```python T = [0
統計的推定と検定をPythonで解く「母平均の検定(正規母集団で母分散未知の場合)」(2020.4.21)
# 概要
先日は、Pythonで「母分散の推定(母平均未知)の場合」を行いました。コード的には、stats.chi2.interval 関数を用い母分散の信頼区間を求めるだけです。その引数として「信頼度:alpha」「自由度:df」を必要としました。基本は$\chi^2$値について、
$P(0.831≤χ2≤12.833)=0.95P(0.831≤χ2≤12.833)=0.95$
が成り立つため(と言いながらこういう表現は見たことがありません)、母分散の信比率頼区間を求めるために上手い具合に式を変形して求められるのでした。前回の記事
[統計的推定と検定をPythonで解く「母分散の推定(母平均未知)の場合」(2020.4.19)](https://qiita.com/tan0ry0shiny/items/4dbec818f9243d8afd99)今回は、「母平均の検定(正規母集団で母分散未知の場合)」について解いていこうと思います。今回も「[とけたろうさんのチートシート](https://toketarou.com/cheatsheet/#toc16)」を使わせて
Python学習記録_1日目.Pythonの基本構文について
# 元記事
[Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記](https://qiita.com/noway6064/items/14ab494dc65d3040f733)
こちらの1日目の学習内容まとめ。### プログラミングとは 10m …
>プログラミングとは、コンピューターにさせたい仕事をプログラムすることです。
つまり、コンピュータへ指示するプログラムを作ることがプログラミングになります。>Pythonは1991年にオランダ人のグイド・ヴァンロッサムが開発し2000年にPythonバージョン2が公開されました。
Pythonは、大きく次の2つの特徴を持っています。
1.プログラムを読みやすい可読性の高さ
2.幅広い用途で利用可能
Pythonは人工知能技術領域で大変活用されており、ここ近年人気な言語にもなっています。
他にも、Webアプリケーション開発や、データ分析などでも利用が可能で、身につけておくことで、様々な事をPythonで実現が可能になります。>プログラミングは実際に手を動かしながら学んでいくことをオススメします。
なん
Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記
# 1.はじめに
この記事はプログラミングに触れたことすらないガチの初心者がPythonを使えるようになって
Kaggle参加できるようになることを目標に雑に学んだこと等をまとめていくものです。
筆者は業務でAccesee、SQLを使うくらいでプログラミングにはほとんど触れたことのないマジ者の初心者なので
あたたかい目で見守ってください。# 2.きっかけ
先日異動が決まり、もともといた部署では施策の立案・実行などをやっていましたが
新しい部署が(名目上)「分析チーム」でした。
しかしこれが蓋を開けてみると~~データリテラシーが終わっていて~~
・施策に用いるデータをExcelで手動でポチポチやって作っている
・データの正確性?目検で見てるし大丈夫でしょ!
・あく…せす…?えすきゅー…える?
・機械学習を専門にしているチームとの協業の際に相手方が何を言っているのか分からずMTGがお通夜と言った状況。
そしてある日のMTGにて
「分析チームって名前なのに今時機械学習も触ったことがないんですね^^(意訳)」
という火の玉ストレートを投げられて何も言えなかったので
python習得し
pythonで「統計学入門」5 正規分布からの標本
とても有名な「統計学入門」をpythonで実装しながら読んでいきます。
本をしっかり読むことと実装の勉強が目的ですので説明が不足していたりします。
また、実装方法に関してはベストなものではないと思いますのでご了承ください。### 前回
標本分布
https://qiita.com/tanaka_benkyo/items/0ed6d0a94492b7161169
### 正規分布からの標本
正規母集団とは、母集団分布が正規分布であるような母集団である。
正規母集団から標本がとられるという仮定は、統計学の理論の中心である。このとき、正規母集団からの標本$X_1,X_2,\cdots,X_n$に基づく統計量の標本分布を計算することが必要となり、この計算を行うのが正規標本論である。
### 正規分布の性質
確率変数$X$が正規分布に従うとき、その密度関数は、“`math
f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{\frac{-(x-\mu)^2}{2\sigma^2}}
“`であり、その平均・分散は、
“`math
E(X)=\mu,\hs
pythonで「統計学入門」4 標本分布
とても有名な「統計学入門」をpythonで実装しながら読んでいきます。
本をしっかり読むことと実装の勉強が目的ですので説明が不足していたりします。
また、実装方法に関してはベストなものではないと思いますのでご了承ください。### 前回
大数の法則と中心極限定理
https://qiita.com/tanaka_benkyo/items/ad8a08da60d79f64b64f
### 標本分布
“`python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from IPython.display import display
import seaborn as sns
import japanize_matplotlib
“`“`python
d = pd.read_csv(‘pokemon_for_stats.csv’).iloc[:,1:]
gen = [“第1世代”]*151+[“第2世代”]*100+[“第3世代”]*135+[“第4世代”]*107+[“
DataFrame を Validation する pandera 入門
# はじめに
Python を用いてデータ分析を行うにあたりよく使われるライブラリとして pandas があります。
pandas は大変使い勝手の良いライブラリですが、多くの場合データを丸ごと `pd.DataFrame` 型で保持するため「どのような列を持っているのか」、「各列がどのような型か」、「各列の値にどのような値が入りうるのか」等がソースコードを一見しただけでは分からないことが多いです。
結果として処理がブラックボックス化してしまい、デバッグコストの増加やコードの可読性低下といった問題を生じさせることがあります。
この問題への解決策の一つとして、本記事ではデータフレームのバリデーション機能を提供するライブラリである pandera を紹介します。# pandera とは
データ処理パイプラインの可読性とロバストさを高めるために dataframe に対してデータ検証を行う機能を提供するライブラリです。
https://github.com/pandera-dev/pandera
https://pandera.readthedocs.io/en/stable/
FlaskのBlueprintを使ったひな形
# はじめに
大して難しい話ではないけれど、ちょっと時間が経つと忘れちゃうBlueprintのところ。
ひな形を作ってGitHubに置きました。自分用ですがよろしければどうぞ。↓https://github.com/yo16/simple_flask_view
viewを使わないもっとシンプルなFlaskが欲しければこちら↓をどうぞ。Blueprint版↑は一応こちらをベースにしてます。(フォルダ構成から変えてるだけど)
https://github.com/yo16/simple_flask
以下は簡単な説明・備忘録。
# フォルダ構成
“`
src/
main.py
app/
__init__.py
views/
top_page.py
second_page.py
templates/
top_page.html
second_page.html
“`
– `top_page.py`と`second_page.py`は、page”s”の方がいいかもしれません。後で説明しますがURL群
FastAPIでホットリロードを有効にする方法(2パターン)
## 1. 起動オプションから指定
FastAPIでホットリロードを有効にする方法を調べると、大体こんな感じで起動オプションを設定する方法が出てきます。
~~~
$ uvicorn main:app –reload
~~~## 2. uvicorn.run()で指定
コマンドラインからではなく、コード上でホットリロードを指定するには以下のように`reload=True`を追記します。~~~ruby:main.py
if __name__ == ‘__main__’:
uvicorn.run(“main:app”, port=8000, reload=True)
~~~
ちなみにアクセスログの設定は`access_log=True/False`とすれば良いそうです。そのまま立ち上げればOKです。
~~~
$ python main.py
~~~`uvicorn`パスが通らない環境(windows)等ではこの方法が良いのではないでしょうか。
## 参考文献
https://www.uvicorn.org/settings/
https://zenn.dev
Python: Selenium: Dockerで、Chromeブラウザ最新版が動く仮想環境を立てて、24時間自動WEBサーフィンさせる環境の基礎を作る
https://github.com/SeleniumHQ/docker-selenium
Selenium は、プログラムコードでWEBブラウザを自動操縦できるソフトウェアです。
ただSeleniumを使ってWEBブラウザを自動操縦するにしても、そのままでは、実行するのにPCやMacが必要です。あなたが寝てる間もPCやMacを起動しっぱなしにするのは不毛ですよね。そこで有用なのが docker-selenium です。
ブラウザが動く仮想環境をDockerで好きなように立てられる便利なOSSです。
docker-selenium を使えば、AWSなどクラウド環境を利用して24時間自動WEB巡回や自動テストを実行させる環境を構築できます。WEBブラウザは色々ありますよね。
その中でもメジャーなのはやはりGoogle Chrome。
やはり、動作確認にはChromeを使いたい。ただそのままでは、最新版Chromeが動くDockerイメージ `selenium/node-chrome`(v4.x。Chromeバージョンは100.X)で起動したdockerコンテナにリモート接続
TensorFlowでALICesを判別(顔判定モデル作成)
# 目的
機械学習について学んでみたいと思った。
よく聞くTensorFlowの入門編として、顔判定モデルを作成した。
ALICesの二人は似ていると噂されており、機械学習でも判別できるのか試してみた。# 参考ページ
– https://qiita.com/Ringa_hyj/items/3b4b6ea1db30e30134eb
– https://www.pc-koubou.jp/magazine/15856# 環境準備
– AnacondaのCreateから、Python3.6.13を選択して仮想環境作成
– 各ライブラリインストール
“`
pip install –ignore-installed –upgrade tensorflow
pip install python-opencv
pip install tensorflow-hub
pip install google_images_download
“`# データ準備
## 画像収集
– 画像をgoogle_images_downloadを使用して集める。
“`
googleimagesdownl
OpenCVに加わった深層学習ベースの顔検出・顔照合のデモ用のサンプル
OpenCV (>= 4.5.4) で深層学習ベースの顔検出・顔照合ライブラリが含まれるようになった。
その利用の普及を応援するために、自作のサンプルプログラムを作ったので、それを紹介する。
既に作成されているサンプルスクリプトを参照して作りました。## OpenCV自体の中のサンプルスクリプト
Github のOpenCV のなかにもオリジナルのサンプルコードがある。https://github.com/opencv/opencv/blob/4.x/samples/dnn/face_detect.py
## Qiita, Gist でのサンプル
また、以下の場所にも顔検出から顔照合までのステップがわかるサンプルコードがある。
Qiita https://qiita.com/UnaNancyOwen/items/8c65a976b0da2a558f06
Gist https://gist.github.com/UnaNancyOwen/49df508ad8b6d9520024354df0e3e740– generate_aligned_faces.py : 画像
Python: Selenium: 自分のMacのChromeブラウザ設定を使って自動WEBサーフィンするプログラミング
ただ単にSeleniumを使うのと違うところは、普段使いの自分のCookieや設定を維持したままChromeを自動操縦できることです。
あとは、起動しっぱなしのChromeブラウザを好きに操作できるので、毎回Chromeが立ち上がっては消えてしまう、のを避けられること。試行錯誤しながらコーディングするのに有用です。# 手順
## MacにChromeをインストールする
まず、SafariなどでWEB検索して普通にChromeをインストールします。
## Chromeのメジャーバージョンナンバーを調べる
Chromeを起動して、アドレスバーに `chrome://version/` と入力してジャンプすると調べられます。
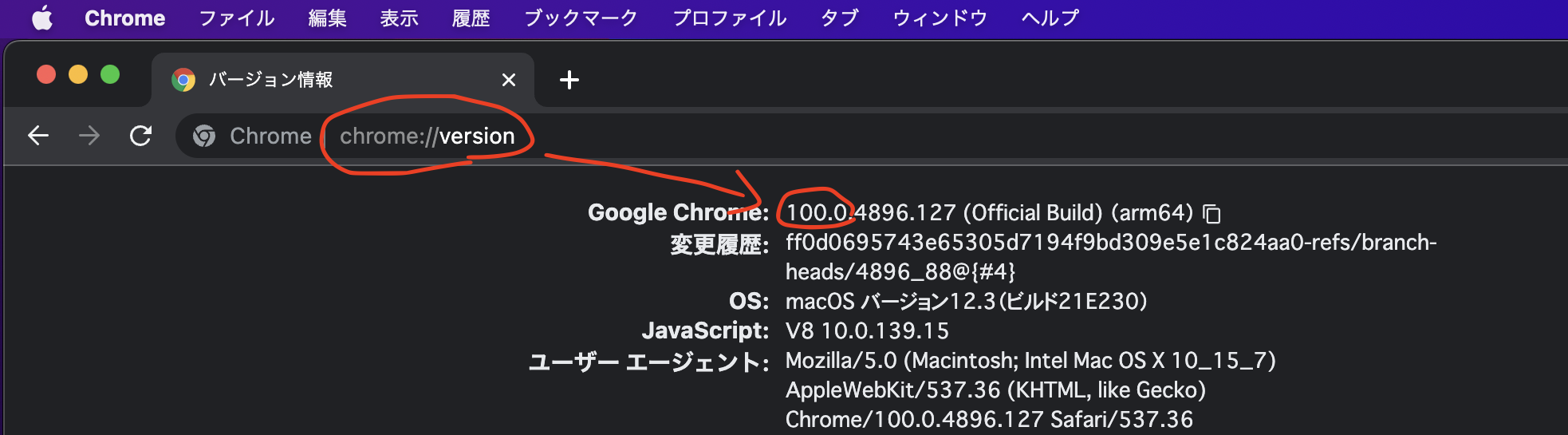
## 自分のChromeプロファイル名を調べる
これも先ほどの
pythonでの設定ファイルの作り方
私が最もシンプルで分かり易いと思っているやり方です.
調べるとよく出てくるJSONはコメントが書けないデメリットがありそれを補うメリットが見出せませんでした.
#### 設定ファイルとは
機械学習をやっていると,何かのパラメータを変更したローラー作戦をやりたくなることがあります.
そういったときに1つの変数の値だけを変更したメインのファイルを沢山つくるのは管理がとても大変です.
そのため,変更しそうなパラメータ類だけを抜き出したサブのファイルを作成して,そのファイルのみを複製して1つの実行ファイルでパラメタ読み込み→学習→別ファイルから別のパラメタ読み込み→学習…のループを回すやり方が一般的です.
このパラメータを抜き出したファイルのことを設定ファイル(あるいはconfigファイル)と呼びます.
#### 設定ファイルの書き方
まずconfig.pyというpyファイルを作ります.
そこにconfigクラスを作りパラメータを羅列します.
(パラメータが沢山ある場合はココでクラスを分けて可読性を高めるのもアリです.)“`python:config.py
class config:
venv 環境での OpenCVのインストール上の注意点
## 要点
venv 環境にopencv をソースからビルドしてインストールする際には、インストール先の変数をカスタマイズしてからビルドして、インストールするようにということ。# やらかした失敗
venv 環境を使っているのにもかかわらず、CMAKE_INSTALL_PREFIXをデフォルトのままcmake、 make 、 sudo make install
してしまうと、 利用環境先の環境には、別の版のopencv のライブラリが残ってしまう。## 手順
OpenCV のソースコードを入手する。
$ git clone https://github.com/opencv/opencv.git$ mkdir build
$ cd build
$ cmake-gui .. &ここで変数CMAKE_INSTALL_PREFIXの値をvenvでの利用環境に合わせる。/home/{your_name}/.venv
そうすると、その下にインストールされるようになる。$ make -j4 ..
$ sudo make install## 確認方法
“`
import c
【Python】Excel、Word、PowerPointの図形処理をしたら嵌った話
## 目次
[1. はじめに](#1-はじめに)
[2. 環境](#2-環境)
[3. インストールするライブラリ](#3-インストールするライブラリ)
[4. サンプルコード](#4-サンプルコード)
[5. 補足](#5-補足)
[6. 参考にしたサイト](#6-参考にしたサイト)## 1. はじめに
Pythonで`Excel`、`Word`、`PowerPoint`の図形処理をしたら嵌ったお話– Googleで検索すると`python-docx`、`python-pptx`のライブラリが出てくるが、このライブラリだと図形で操作できない機能があるので嵌る(結局、`pywin32`になる)
– `Excel`、`Word`、`PowerPoint`でパスワード(読み取り、書き込み)を設定されてるとダイアログが表示されて処理が停止して嵌る(Googleで検索するパスワード解析ばかりで、スキップするだけの内容が出てこない)
– ネットワークドライブ経由のファイルサーバ操作で大量処理すると`win32com`でネットワークエラーになり嵌る(`win32com`エラーはあまり情報が
pythonのosモジュールを初めて調べた備忘録
# osモジュールの概要
OSに依存した機能を利用できる。
主にファイルやディレクトリ操作に用いられる。使いそうなメソッドだけ備忘録にする。
# os.system()でunixコマンドを使う
わざわざ端末を使う必要がなくなる。
cdを使ったディレクトリ移動はできなかった。
“`python
os.system(“ls”)
“`
“`bash:結果
folder1
a.txt
b.txt
.
.
.
“`
os.get(“pwd”)とos.getcwd()の結果は同じだった。
なので、unixコマンドで賄える処理はわざわざメソッドを覚えなくてよさそう。# os.path()でファイルの存在確認やパスの取得をする
パス名の取得や分割、結合などの操作ができる。os.path.join()は引数に与えた2つ以上のパスを結合して返す。str型。
“`python
path = os.getcwd()
print(path)print(os.path.join(path, “abc.txt”))
“`
“`bash:結果
/home/user/デスクトップ
/h
delikaを使って日本の名山情報を見てみた
## はじめに
何か面白そうだったので、記載練習がてらに触ってみました。https://qiita.com/official-events/30be12dd14c0aad2c1c2
## データ取り出しまで
ほぼこの記事そのままです。https://qiita.com/hanaseleb/items/33649108281bd6d00aa4
“`python
# delikaのclientとPandas他、必要なパッケージ
!pip install –extra-index-url=https://docs.delika.io/python/ delika[DataFrame]import delika
#JWTの取得
token = delika.new_token(host= “https://api.delika.io/v1”, open_browser = “true”)
token.save()
client = delika.load_client()# データフレームで取得
import delika.pandas
df1 = delika.pa
3D空間で紙飛行機を回転(オイラー角)
# 紙飛行機をモデルにしてオイラー角で回転する様子をpython matplotlibで見てみます
https://github.com/OkitaSystemDesign/python3d
オイラー角を使って紙飛行機を回転
PaperAirplaneEuler.py
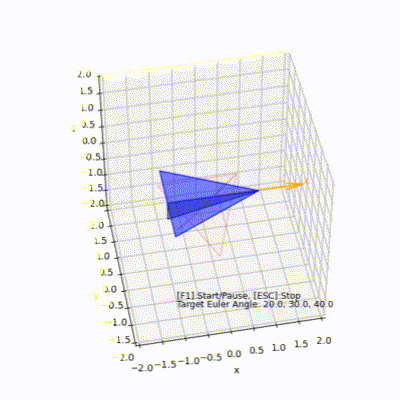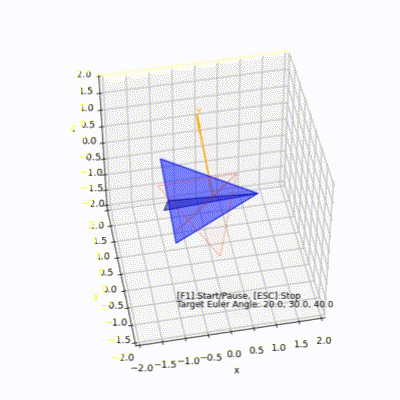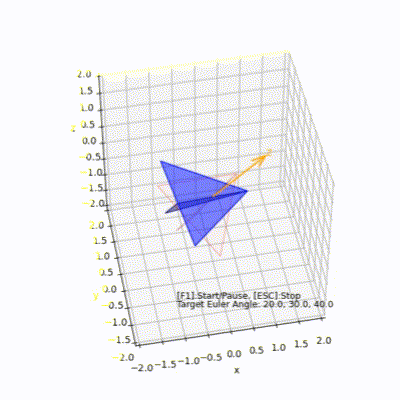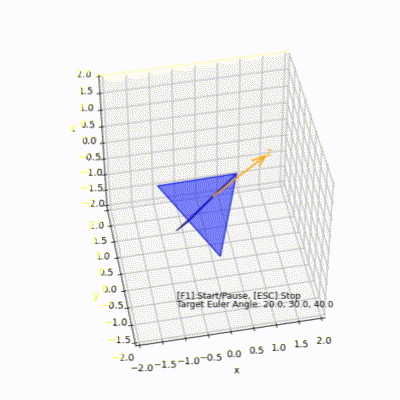
## 環境
Windows10
python3.9
numpy
Matplotlib## 使い方
#### 紙飛行機を回転させる関数
“`python
PaperAirplaneEuler(angle, order)
“`
angleに目標とする姿勢のオイラー角[x,y,z]をセットて渡します
orderは回転順でXYZ,XZY,YXZ,YZX,ZXY,ZYXの種類の中から選択します
#### 例
“`python
angle = [20.0, 30.0,




