
- 1. APIでコンフルエンスのグループを取得してExcelに書き出す
- 2. FASTAPIのクエリパラメータをプルダウンに
- 3. 【Python】日付ありデータの縦持ち→横持ち変換
- 4. グラフ上でマウスドラッグしてデータの詳細を表示させたい
- 5. 【Kaggle】H&M Recommendation Competition ルールベースを用いた解法
- 6. [Python] list, tuple, dict, bitへのアクセス速度比較
- 7. デュエル・マスターズのカードをdoc2vecでベクトル化して類似カードを探してみた
- 8. 約数の総和の逆関数を作った
- 9. 【詳解】数理最適化ソルバーGurobiのインストール/アップデート/アンインストール【Python】
- 10. [python] Key-Value 形式の dict を階層構造の dict に
- 11. Pymongo4.0以降で[Errno 11001] getaddrinfo failed.になる問題
- 12. Blenderでシェーダーのノード位置の調整
- 13. オブジェクト間通信にUDPを使う
- 14. 統計的推定と検定をPythonで解く「統計的仮説検定(2標本の平均の差の検定、対応のないt検定」(2020.4.26)
- 15. Pythonの計算量の話
- 16. 【クソアプリ】個人開発三つ目だがアウトプットの話をしようと思う【アウトプットは大切という話】
- 17. [Python]sympyを使って多項式から任意の着目する変数の係数を求める方法
- 18. Cost Explorer API でアカウント毎に日別の請求額を取得する
- 19. Python学習記録_4日目.自作関数のモジュール化とNumpyについて
- 20. 逆引き言語差確認メモ(C++,C#,Python,Go)
APIでコンフルエンスのグループを取得してExcelに書き出す
# はじめに
コンフルエンスのグループ情報を取得してExcelに書き出す処理の実装です。
実務で地味に使ってるので記事にしました。その内Githubに集約していきます。
数年前に書いたモノなので恥ずかしいコードになってるのはご容赦ください。
—
## ライブラリ
openpyxlはpipで追加インストールrequests、json、astは標準ライブラリです。
## コード
“`getgroups.py
import openpyxl
import requests
import json
import astauth = (“hogehoge@hoge.co.jp”, “APIキー情報”)
def GetGroups():
wb = openpyxl.load_workbook(“test.xlsx”)
sht = wb[‘Sheet1’]
url = “https://xxxx.atlassian.net/wiki/rest/api/group”headers = {
“Accept”: “appli
FASTAPIのクエリパラメータをプルダウンに
# ML基盤構築
Fastapiを使った機械学習システムを検討している。
前提としては、Pythonでバックエンドサーバーを構築する部分で、
基本はAPIを基本とした疎結合を考えている。# FastAPI関係
これまでの記事...
https://qiita.com/EasyCording/items/4256c33854ebfbbb85e8
https://qiita.com/EasyCording/items/3756358fafdfc184dbdb# 今回の内容
ある程度、APIの使い方はマスター出来てきた。
但し、クエリパラメータやパスパラメータなど、これと言ったスタンダードが無い世界なので、なかなか苦労している。
少し自分の経験から、今後こうしたほうが良いなと言う気付きをメモする。## 教訓1 フォルダで何とかする作戦はやめたほうが良い
* Pytorchなどのリポジトリでは、フォルダにTRAIN,VAL,TESTに振り分けて、そこに入れればワンタッチなどと言うパターンが多い。
* テキスト分類の類で言えば、livedoorコーパスのように、ラベル名ごとにテキス
【Python】日付ありデータの縦持ち→横持ち変換
血液検査のデータをデータベースから取り出して,縦持ちデータを横持ちデータに変換しました.
日本語にすると一見難しそうですが,結論からいうとpandasのpivotを使うと1行で変換することができます.
縦持ちデータとは明確な定義は知りませんが,縦にダラダラと長く伸びるデータです.
実際に見ると分かりやすいので,縦持ちデータのサンプルを用意しました.
【縦持ちデータサンプル】
同じ検査日が1行となっておらず,検査の項目だけ行数が存在している状況で,視認性も悪く,データ分析する際に色々と面倒となりそうです.
あと,名前のみをインデックスとしてではなく,検査日と名前のマルチインデックスとした方が見やすそうです.
【完成図】
# できたもの
(gif)
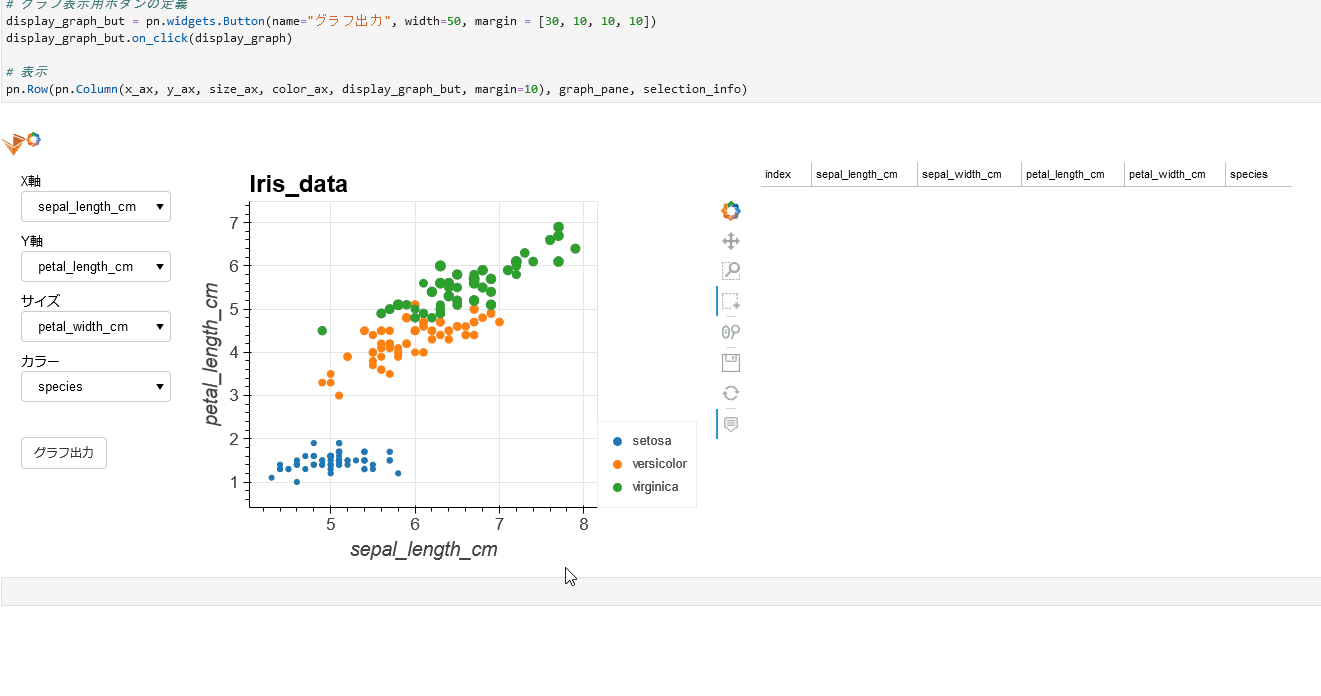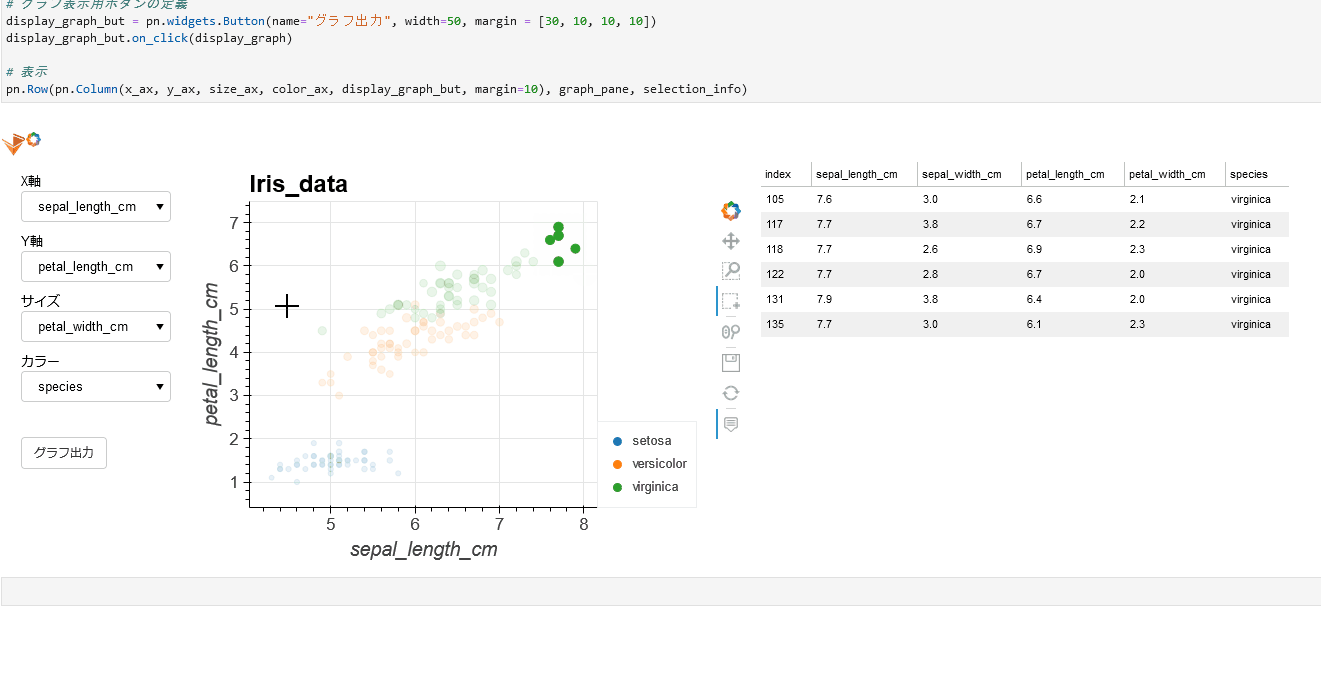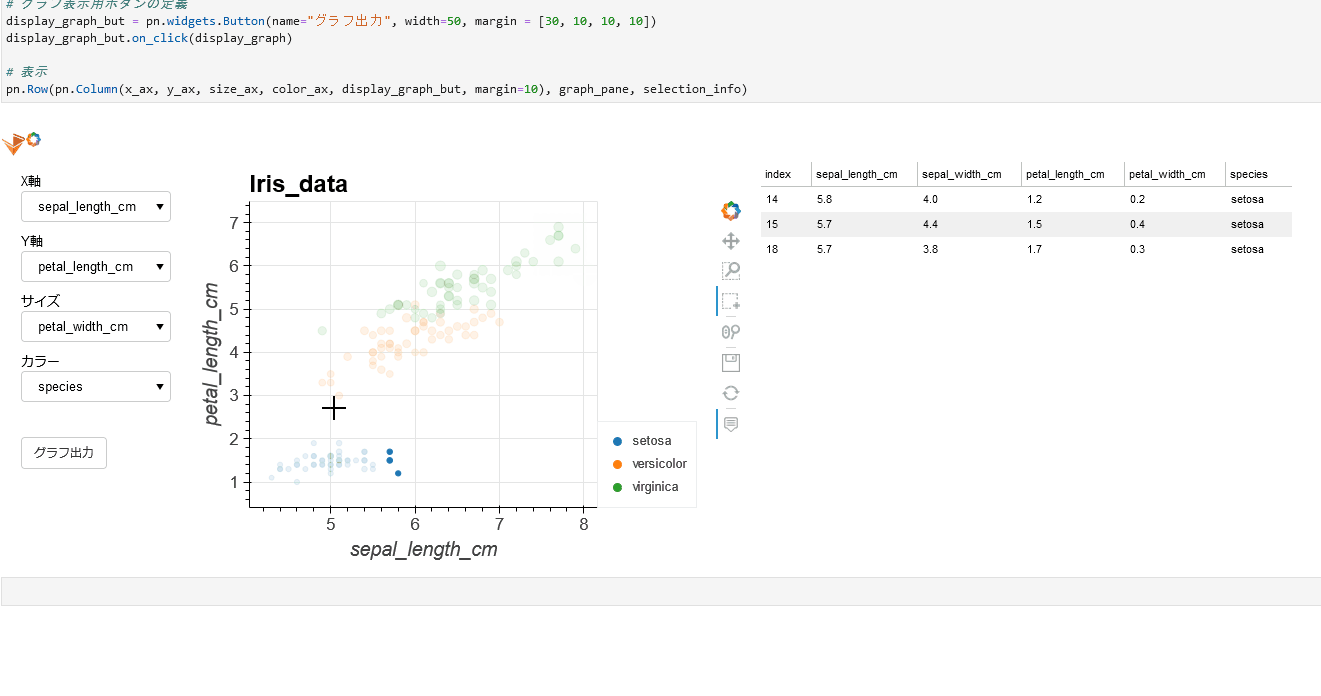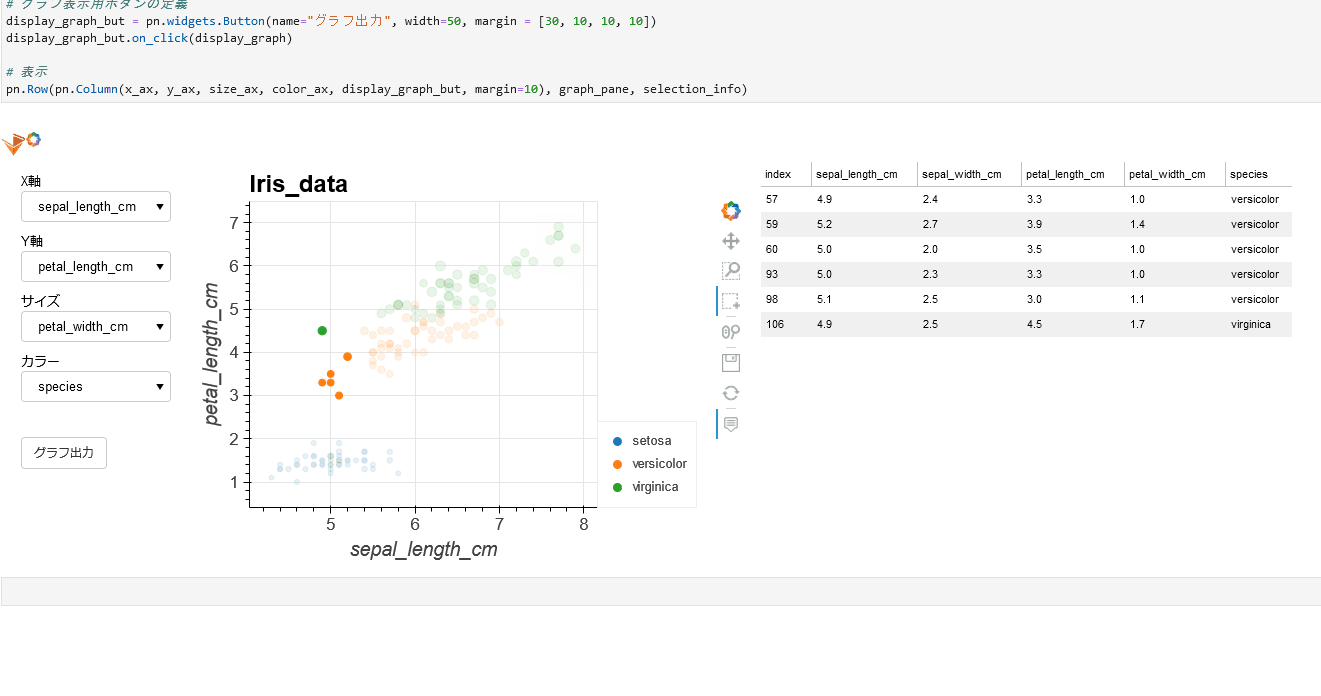**HoloViews**の**Selection1D**を活用して実現できました。
# 解説
上記をつくる過程を紹介しながら、解説をします。
過去の記事で紹介したようなHoloViewsやPanelの解説と一部重複しますが、ご承知おきください。https://qiita.com/8_hisakichi_8/items/8be
【Kaggle】H&M Recommendation Competition ルールベースを用いた解法
# はじめに
こんにちは.株式会社音圧爆上げくんにプロKagglerとして所属していますAshmeと申します.私は業務の一環としてKaggleの様々なコンペティションに参加し,そこで得られた知見などを記事にして投稿しております.よろしくお願いいたします.
今回は現在開催されている[H&M Personalized Fashion Recommendations](https://www.kaggle.com/c/h-and-m-personalized-fashion-recommendations/overview/description)でのルールベースでの解法がありましたのでこちらの紹介と,私の方で少し工夫を加えたものを紹介します.
ルールベースの手法では前回紹介したLGBMRankerなどの機械学習アルゴリズムと異なりモデルを学習する必要がありません.その代わりデータに対する仮定などに基づいて顧客が購入しそうな製品を候補として出していくことになります.私も最初自分でルールベースを実装したのですが全く精度が出ませんでした.モデルを学習するときよりもEDAが重要になり,顧
[Python] list, tuple, dict, bitへのアクセス速度比較
# 概要
Pythonで数億回の単位のループの中で何度も読み込まれる情報の取り扱いに際して、list, tuple, dict, bitシフトのうち、listを使うと一番良いことがわかったため、その結果をまとめる。なお、Pythonのバージョンは3.9.12を用いた。
**追記: 環境依存でlistとtupleの実行速度が逆転したり、同じになったりする場合があるようです。
ただ、他の方から指摘を受けましたが、この程度の差なら可読性を優先(とはいえlistでよいですが)すればよいと思います。
また、これ差が影響するレベルのプログラムなら、そもそもPythonを使うべきではないかと思います。**# 結果
後述するプログラムで各処理に1億回アクセスした際の実行結果を先に示す。~~~
list 6.8316689 s
tuple 7.3425238 s
dict 7.111480700000001 s
bit shift 8.7826661 s
~~~~このように、listを用いた場合において、最も早い結果を示した。
実際に実行したプログラムが下記で、条件を揃えるため、それぞれのア
デュエル・マスターズのカードをdoc2vecでベクトル化して類似カードを探してみた
# 背景
春休みに途中まで書いて放置してた記事があったので書ききって公開。\使用しているデータは少し古いです。デュエル・マスターズは、タカラトミーが提供するトレーディングカード(TCG)の一種で、去年20周年を迎えました。
まぁそんな続いていると、カードの種類も膨大になり、似たような効果を持つカードが出てきます。
また、機械的にそんなカードを見つけることができるのか気になって調べてみると、doc2vecという技術があることがわかり、ハーフストーン(デジタルTCG)や遊戯王などのTCGでやっている例([1](https://qiita.com/Morinikiz/items/66941b9e3e57b9224fd7),[2](https://upura.hatenablog.com/entry/2018/01/21/184700))が見つかりました。(デュエル・マスターズもやっている人がいた気がするが、探しても見つからなかった)
doc2vecについて詳しい解説は他の方の方がわかりやすいので、そちらを参照してください。
簡単に説明しとくと、語順もきちんと理解できるアルゴリズム
約数の総和の逆関数を作った
何言ってるのかよくわからないので例を挙げます。
たとえば、自然数 $60$ の約数を列挙すると、 $1, 2, 3, 4, 5, 6, 10, 12, 15, 20, 30, 60$ です。この総和は $168$ ですね。
この関係を表す関数に約数関数 https://ja.wikipedia.org/wiki/%E7%B4%84%E6%95%B0%E9%96%A2%E6%95%B0 というものがあって、 $σ_1(60)=168$ と書いたり、あるいは単に $σ(60)=168$ と書いたりします。
この逆関数 $σ^{-1}$ は複数の値をとります。 $σ^{-1}(168)=60, 78, 92, 123, 143, 167$ など。この値を全て列挙してみようという試みです。
“`python: python
from sympy import sieve
import copydef sum_primes(n: int, primes: list):
mydict = {}
for p in primes:
p_now = 1
【詳解】数理最適化ソルバーGurobiのインストール/アップデート/アンインストール【Python】
# 1. 更新履歴
2022/04/26 Pythonのみ(Anaconda)完成# 2. はじめに
以前は[CPLEX](https://www.ibm.com/jp-ja/analytics/cplex-optimizer)を使用しており,[CPLEXのインストール方法に関する記事](https://qiita.com/nanametal_/items/ab9492193bf48e29b5ea)を書いたこともありました.とはいえ様々なソルバーがある中で,(どのソルバーの性能が最も優れているかはさておき)[Gurobi](https://www.gurobi.com)はインストールが楽で非常に便利ですよね.しかしPythonでGurobiを使用することを想定すると,Gurobiのインストールは様々なやり方があるのですが,インストール方法が異なるとアップデート方法やアンインストール方法が異なります.そこで本記事では**Windowsを対象として**,数理最適化ソルバーであるGurobi Optimizerの複数のインストール方法についてなるべくキャプチャ画像を増やして詳しく解
[python] Key-Value 形式の dict を階層構造の dict に
# やりたいこと
記事タイトルはちょっとわかりづらいというか不正確な気がしますが、やりたいことはコレ。
“`python
# ↓これを
src = {
“aaa”: “A”,
“bbb.ccc”: “BC”,
“bbb.ddd”: “BD”,
}# ↓こうしたい
{
“aaa”: “A”,
“bbb”: {
“ccc”: “BC”,
“ddd”: “BD”
}
}
“`# コードスニペット
とりあえず下記の function で実現できた。
もっとキレイに書けそうな気がするし、探せばライブラリもありそうだけど。“`python
def kv_to_stare(kv, path_delimiter=”.”, base_path=””):
result = {}
for k, v in kv.items():
if len(base_path) > 0 and not k.startswith(f”{base_path}{path_delimiter}”):
Pymongo4.0以降で[Errno 11001] getaddrinfo failed.になる問題
参考:
https://pymongo.readthedocs.io/en/stable/migrate-to-pymongo4.html
https://pymongo.readthedocs.io/en/stable/changelog.html1.pythonとmongoDBのバージョンを確認する。
“`
Warning PyMongo 4.0 drops support for Python 2.7, 3.4, and 3.5.
Warning PyMongo 4.0 drops support for MongoDB 2.6, 3.0, 3.2, and 3.4.
“`2.uriが正しく記述できているか確認する。
“`
uri = “xxx”
client = pymongo.MongoClient(uri)
“`3.directConnection = True を引数で渡しているか確認する。
“`
uri = “xxx”
client = pymongo.MongoClient(uri, directConnection=True)
“`
Blenderでシェーダーのノード位置の調整
## 概要
Pythonでマテリアルのシェーダーのノード位置を調整してみます。
シェーダーのノード自体をPythonで作成したときに使えるかもしれません(下図は実行例)。
## ロジック
[NetworkX](https://networkx.org/)で有向グラフを作り、マテリアル出力ノードまでの距離ごとにレイヤーを作り、上から配置していきます。
## 実行してみる
対象のマテリアルの名前を`Material`としたとき、下記を実行すると位置を調整します。
NetworkXのインストールが必要です。“`py
import bpy
import networkx as nx
from collections import defaultdict# 有向グラフの作成
g = nx.DiGraph()
m =

オブジェクト間通信にUDPを使う
# オブジェクトの参照が面倒
オブジェクトが多くなってくるとオブジェクト同士の通信が億劫になってきます。親とか子とかパスとか、も~めんどくさい! たまには違うプログラムとやり取りなんかも発生して本当に大変。
**ならばネットワークだ!** 昔から利用されていた方法だから間違いはない。(はず)
## お手軽通信、UDP
やっぱりこういう目的ならUDPでしょう。Open Sound Controlもちらっと考えたのですがモジュールとか導入したり諸々面倒なのでPythonで何も考えずに使えるudpで済ますことにしました。
受信を待つとかブロッキングで他の処理が止まるとかそういうのは使いづらくて困るのでデータが受信されたらコールバックが呼ばれるって感じで。
うん、なんか良さそうな気がしてきたぞ。
## コード
そんな感じでとりあえずでっち上げました。行儀悪いところがあったりするけど細かいツッコミは必要ないので気になるなら直して使うなり自由にすると良いです。
比較的簡単に使える、気をつけなきゃいけないのはIPアドレスが被らないようにすることくらい。
**udpnet
統計的推定と検定をPythonで解く「統計的仮説検定(2標本の平均の差の検定、対応のないt検定」(2020.4.26)
# 背景
前回は2標本の平均の差の検定、筋トレ前後のテストの差の確率分布を作って、それが正規分布かどうかを検定値を用いて判断するのでした。これは母分散がわからない場合の正規分布の母平均の検定、すなわち1標本のt検定と同意です。今回は対応のないt検定に取り組みたいと思います。今回は[統計WEB](https://bellcurve.jp/statistics/course/9446.html)から問題をピックさせて頂きたいと思います。前回の記事
[統計的推定と検定をPythonで解く「統計的仮説検定(2標本の平均の差の検定、対応のあるt検定」(2020.4.25)」](https://qiita.com/tan0ry0shiny/items/4f03e9ad3c9142a9e66c)
# 問題
ある学校の1組と2組の算数のテストの平均点を比較します。1組の生徒30人の平均点は75点、標準偏差は5点、2組の生徒32人の平均点は70点、標準偏差は8点でした。この結果から、1組と2組の算数のテストの平均点に差はあると言えるでしょうか。# 解答
## どういう問題か(問題の
Pythonの計算量の話
Pythonの計算量について誤った認識が多いとわかったため、計算量の話をまとめたいと思います。
この記事の他には、以下の記事が良くまとまっていて自分も良く拝見しています。
https://qiita.com/Hironsan/items/68161ee16b1c9d7b25fb
計算量の話だけを記載すると上の記事の丸パクリになってしまうため、データ構造に関する周辺話題や内部実装についてお話していこうと思います。
# 計算量 と その周辺話題
## リスト(`list`)
|操作 |平均計算量 |最悪計算量 |
|— |— |— |
|`append` |$O(1)$ |$O(1)$ |
|`pop` (末尾の要素) |$O(1)$ |$O(1)$ |
|`pop` (末尾以外) |$O(N)$ |$O(N)$ |
|`insert`| $O(N)$ | $O(N)$ |
|`in` | $O(N)$ | $O(N)$ |
|rand
【クソアプリ】個人開発三つ目だがアウトプットの話をしようと思う【アウトプットは大切という話】
まず宣伝させてください。。
今回もDjangoでアプリを作成しました。
みんなの宝箱というアプリで、宝物を入れて、それをガチャの要領で開けることができるアプリです。https://takara.quality-of-life1.com/
ログインなしで遊べますが、ログインするとお宝コレクションができるマイページが使えます。
よければテストユーザーで確認してみてください。
アドレス:test@example.com
パスワード:0000aaaa
でログインできます。今回はこちらの作成に当たり、アウトプットはどのくらい大切かという話をしていきたいです。
:::note info
この記事で伝えたいこと
・勉強してるのにできるようにならない人が成長するには
・とりあえず作る大切さ
・アウトプットした分だけ成長が見込める
・覚えようとしない、その場で調べる
:::目次
1. プログラミングの勉強しているのに成果が出ない
2. 【アウトプット大事】1個目より2個目のほうが圧倒的早く作成できる
1. とりあえず、一つアプリを作るとやることが明確化されてくる
2. 前回の作成物
[Python]sympyを使って多項式から任意の着目する変数の係数を求める方法
“`python
import sympy as spsp.var(‘x1, x2, x3’) # 着目する変数
sp.var(‘c1, c2, c3, c4, c5’) # 係数
expr = c1*x1 + c2*x2 + c3*x3 + c4*x1*x2 + c5 # 式を定義expr_poly = sp.poly(expr, x1, x2, x3) # x1,x2,x3に着目した多項式オブジェクトを作成
x1_coef = expr_poly.nth(1, 0, 0) # x1の係数
x2_coef = expr_poly.nth(0, 1, 0) # x2の係数
x3_coef = expr_poly.nth(0, 0, 1) # x3の係数
x1_x2_coef = expr_poly.nth(1, 1, 0) # x1*x2の係数
constant = expr_poly.nth(0, 0, 0) # 定数print(x1_coef, x2_coef, x3_coef, x1_x2_coef, constant)
# 実行結果 -> c1 c2 c3 c4
Cost Explorer API でアカウント毎に日別の請求額を取得する
## モチベーション
Cost Explorer API を使用してアカウント毎に DAILY の請求額を取得し、以下のようなデータを CSV で出力したい。|Account Id|Account Name|2022/4/1|2022/4/2|2022/4/3| …|2022/4/30|
|—|—|—|—|—|—|—|
|000000000000|account-0000|42.792716528|40.124716527|43.123416527|…|50.922465287|
|111111111111|account-1111|32.263379809|30.235379809|31.263353594|…|22.133798094|
|222222222222|account-2222|751.71034839|720.51234839|772.62033294|…|651.71042035|
|333333333333|account-3333|4.6428|5.1234|7.8765|…|6.2234|
|44444444
Python学習記録_4日目.自作関数のモジュール化とNumpyについて
# 元記事
[Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記](https://qiita.com/noway6064/items/14ab494dc65d3040f733)
4日目numpyについてがメインになりそうです。
今日も頑張ります。### グリッドサーチ 15m …
##### はじめに
>このテキストは、交差検証の続きです。
先に交差検証のテキストをお進めください。~~じゃあ交差検証もカリキュラムに入れてくれ…~~
ということで交差検証から見ていきます。
これはたぶんクロスバリデーションってやつですね、機械学習チームとの協業で何度か出てきたワードな気がします。##### ホールドアウト法
>ホールドアウト法は、モデルを作る学習データ(x_train,y_train)と、モデルを評価するテストデータ(x_test,y_test)に分割して評価します。
学習したモデルで予測する際に、学習に使っていない未知のデータで予測します。
よってデータを分けることで、汎化性能(未知のデータに対する性能)を向上させることができます。
ホールドアウ
逆引き言語差確認メモ(C++,C#,Python,Go)
# アレってこの言語でどう書くんだっけ?
別言語を使う作業に移行した時に、たまにある **”アレって、この言語でどう書くんだっけ?”** をカバー## 宣言
2次元配列
“`func.cpp
//宣言,初期化
int** table = {{0,1,2},{3,4,5}};
int table[][]={{0,1,2},{3,4,5}};
//引数,返値
int** function(int** table){
return table;
}
int** function2(int table[][]){
return table;
}
“`“`func.cs
//宣言,初期化
int[,] table=new int[0,1,2][3,4,5];
//引数,返値
int[,] function(int[,] table){
return table;
}
“`“`func.py
#宣言,初期化
table=[[0,1,2],[3,4,5]]
#引数,返値
def functi




