
- 1. [AtCoder] 個人的に使用頻度が高いitertoolsまとめ
- 2. 学習済みモデルを用いて特徴量化(Azure Databricks)
- 3. 連続した日付をグループで取り出す
- 4. asyncio、コルーチン、async/await
- 5. RailsアプリにPython3系の実行環境構築する
- 6. 【Pandas】両者のDataframeの差分を確認したい!
- 7. jupyter環境に自動でライブラリをインポートする
- 8. Pythonと比べて学ぶ競プロのためのRust
- 9. pyinstallerで作ったexeをタイムスケジュールで実行する際のエラーの対処方法
- 10. コイン問題(動的計画法)をpythonで実装
- 11. JPXのデータを用いてデータ分析をしていく【データ読み込みからデータの中身理解】(Kaggleコンペ)
- 12. [Python] 各種変数へのアクセス速度比較
- 13. [学習メモ]pytorchでよく使う関数
- 14. [学習メモ]テンソル生成時の注意点
- 15. 【Python】SageMakerでPyTorchうごかしてみたった【SageMaker】
- 16. 【図解】なぜ活性化関数が必要なのか
- 17. Pythonで日向坂46⊿メンバー22人の顔識別してみた
- 18. pymupdfを使ってpdfのwidthとheightを取得する
- 19. 初心者は面倒くさくてもprint系関数で挙動を確認しようね
- 20. APIでコンフルエンスのグループを取得してExcelに書き出す
[AtCoder] 個人的に使用頻度が高いitertoolsまとめ
AtCoderで組み合わせ問題など抽出方法をどうしようか迷いますよね。
自作するのも一つの手ですが、itertools関数を使った方がバグらないです。
※一度自作して処理を考えることをお勧めします## 表示用関数用意
“`python
import itertoolsdef printitertools(itertool_return, describe):
print(describe)
for i in itertool_return:
print(i)
print(“”)“`
## デカルト積(product)
全bit探索にも使えます。“`python
printitertools(itertools.product(range(2), repeat=3), “product”)#product
#(0, 0, 0)
#(0, 0, 1)
#(0, 1, 0)
#(0, 1, 1)
#(1, 0, 0)
#(1, 0, 1)
#(1, 1, 0)
#(1, 1, 1)“`
## 順列(Permutat
学習済みモデルを用いて特徴量化(Azure Databricks)
# はじめに
これやっていきまーすhttps://docs.databricks.com/_static/notebooks/deep-learning/deep-learning-transfer-learning-keras.html
# 開発環境
1.ライブラリをインストール
~~~
%pip install tensorflow
~~~2.ライブラリをインポート
~~~python
import pandas as pd
from PIL import Image
import numpy as np
import ioimport tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
from tensorflow.keras.preprocessing.image import img_to_arrayfrom pyspark.sql.functions import col, pandas_udf, PandasU
連続した日付をグループで取り出す
# やりたいこと
**以下のようなデータ (`pd.Series`)で、連続している日付をグループとして取り出す。**“`python
import pandas as pdexample_data = pd.Series([‘2021-10-14’, ‘2021-10-15’, ‘2021-10-16’, ‘2021-10-17’, ‘2021-10-18’, ‘2021-10-19’, ‘2021-10-20’, ‘2021-10-21’, ‘2021-10-22’, ‘2021-10-26’, ‘2021-10-30’, ‘2021-10-31’, ‘2021-11-01’, ‘2021-11-03’, ‘2021-11-04’, ‘2021-11-08’, ‘2021-11-09’, ‘2021-11-10’, ‘2021-11-11’, ‘2021-11-15’, ‘2021-11-16’, ‘2022-02-07’, ‘2022-02-08’, ‘2022-02-09’, ‘2022-02-10’, ‘2022-02-11’, ‘2022-02-16’, ‘202
asyncio、コルーチン、async/await
# asyncio
>async/await 構文を使い 並行処理の コードを書くためのライブラリです
https://docs.python.org/ja/3/library/asyncio.htmlでは、`async/await`とは?
# async/await
* 非同期で実装する際に使用する
“`sample.py
async def edit():
results = await get()
return results
“`次の様にawaitを使わない場合、
“`sample.py
async def edit():
print(get())
# > RuntimeWarning: coroutine ‘SampleController.get’ was never awaited
“`「コルーチンがawaitされていない」と。
**コルーチンを単に呼び出しただけでは実行出来ず、コルーチンオブジェクトが返るため**コルーチンとは?
# コルーチン
async/await 構文で宣言された関数はコルーチンと呼ば
RailsアプリにPython3系の実行環境構築する
## まえおき
Railsを使ったプロジェクトにて大量レコードをエクセルに書き込む処理があるのだが、
使用していたRubyライブラリの「RubyXL」ではメモリ効率や出力速度に限界があり、「数十時間出力にかかる」、「出力する前にメモリ枯渇」するなどの問題があった。
Rubyには他にもエクセルのライブラリがあるが、書式設定などが自由にできないものが多く採用に至らず。
調査したところ現状の仕様を満たすかつ、メモリ効率が高いライブラリとしてPythonに「openpyXL」というものあったので導入した。
そこでRailsアプリ内でPythonを実行するための環境を用意する必要が出てきた。
なお単発的にRubyファイルからシェルスクリプトを経由してPythonファイルを実行する想定。
特にバージョン管理は必要ないのでPyenvは無し。## 環境
– GCE
– OS:CentOS7
– 言語:Ruby(2.2.2)
– フレームワーク:Rails(4.2.5)## 環境のチェックなど
①OSのバージョン確認
cat /etc/redhat-release
>CentOS Linux
【Pandas】両者のDataframeの差分を確認したい!
同じカラムだけど、データ量が違う2つのdataframeがあったとする。
– dataframe 1
|index|a|b|c|
|—|—|—|—|
|0|1|2|3|
|1|4|5|6|– dataframe 2
|index|a|b|c|
|—|—|—|—|
|0|1|2|3|
|1|4|5|6|
|2|5|6|7|データ量が同じであれば、[compare関数](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.compare.html)を使うことができるが、
両者のデータ量が異なる場合、compare関数を利用すると
エラーとなってしまう。“`
ValueError: Can only compare identically-labeled DataFrame objects
“`そこで、両者のどこに差があるのかを確認する方法を紹介する。
# 差分の確認方法
以下のように、merge関数とquery関数をくみあわせればいい。
“`pyth
jupyter環境に自動でライブラリをインポートする
## 初めに
Jupyterでよく使うライブラリを毎回インポートしたり同じ設定を書くといった何気ないめんどくさい作業を自動化できないかと思い調べたので共有します。## 方法
`~/.ipython/profile_default/startup/start.py`に記述した内容がIpythonが立ち上がるタイミングで毎回実行されるため、この機能を利用します。
例えば、以下のような内容を記述しておくと、ライブラリのインポートの他にも設定などを統一できます。“`python
import pandas as pd
import numpy as np# Pandas options
pd.options.display.max_columns = 30
pd.options.display.max_rows = 20from IPython import get_ipython
ipython = get_ipython()# If in ipython, load autoreload extension
if ‘ipython’ in globals():
Pythonと比べて学ぶ競プロのためのRust
今までは Python で競技プログラミングをしていましたが、最近 Rust の勉強を始めました。同じように Python を書いたことがあり Rust へ入門しようと考えている人向けに AtCoder の過去問 (B~C) を両言語で解いてみます。
#### 役に立つ記事
– [RustCoder ―― AtCoder と Rust で始める競技プログラミング入門](https://zenn.dev/toga/books/rust-atcoder)
– [AtCoder 2020年言語アップデート以降の環境](https://github.com/rust-lang-ja/atcoder-rust-resources/wiki/2020-Update)
– [Docker × VSCode × Rust な開発環境を3ステップで作る](https://qiita.com/schrosis/items/1d99b68ae00d3cdbf9e1)#### ABC243 B – Hit and Blow
問題:
https://atcoder.jp/contests/a
pyinstallerで作ったexeをタイムスケジュールで実行する際のエラーの対処方法
# 概要
タスクスケジューラでpyinstallerでexe化した実行ファイルを実行させようとすると。”Failed to execute script”と出る問題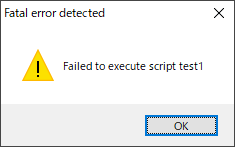
試したこと
1. exeを指定ー>上記のエラー
1. cmd経由の実行ー>不可能# 解決法
バッチファイルを作り、バッチファイルを実行させるexeのあるファイル内に次のようなバッシュファイルを入れます
“`bash:test.bat
@echo off
cd “C:\Users\name\Documents\Python Scripts\Oyasumi\dist”
start test1.exe“`
cdはexeのある作業フォルダへの移動
startで実行です
をpythonで実装
# 問題を解く前に
## 動的計画法とは
動的計画法とは
* いくつかの小さな問題の解や計算結果を利用してより大きな問題を解く。
* 同じ計算をすることを防ぐため、表に計算結果を記録し利用する。というような条件を満たすアルゴリズムである。
# 問題
https://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=DPL_1_A&lang=jp
* コイン問題
* 額面がc1, c2,…, cm 円の m 種類のコインを使って、 n 円を支払うときの、コインの最小の枚数を求めて下さい。各額面のコインは何度でも使用することができます。
* 入力
M N
c1 c2 … cn
* 出力
コインの最小枚数を1行に出力してください。
* 制約
* 1 ≤ n ≤ 50,000
* 1 ≤ m ≤ 20
* 1 ≤ 額面 ≤ 10,000
額面はすべて異なり、必ず1を含む# なぜ動的計画法をつかうのか
なぜ動的計画法を使うのか、それは`計算が入れ子構造になっている`からである。
JPXのデータを用いてデータ分析をしていく【データ読み込みからデータの中身理解】(Kaggleコンペ)
みなさんこんにちは。
現在、Pythonを勉強している社会人3年目の転職希望者です。
プログラミングスクールに通い、様々な分析手法を学びました。これからは、更に実践で活躍できるようになる為、自らデータを探し、データの分析のみならず基礎から学んでいこうと考えています。
このブログが様々な人の役に立てれば光栄に思います。さて、本題ですが今回使用するデータセットは下記のとおりです
https://www.kaggle.com/competitions/jpx-tokyo-stock-exchange-prediction
JPXが主催のコンペディションになっています。ここで、JPXとは何か簡単に説明していきます。
日本取引所グループ(JPX)は、世界最大級の証券取引所である東京証券取引所(TSE)と、デリバティブ取引所である大阪取引所(OSE)および東京商品取引所(TOCOM)を運営する持株会社です。
今回はこのコンペディションのデータを用いて、データの読み込みからデータ手法まで幅広く学んでいきたいと思います。
1.データの読み込み
与えられたデータがかなり多いですが、まずは一
[Python] 各種変数へのアクセス速度比較
# 概要
Pythonで1億回の単位のループの中で変数へのアクセス速度を比較したところ、下記のような傾向が見られた。* local変数はglobal変数より早い。
* クラス内からクラス変数にアクセスする際は、self.~でアクセスした方が早い。
* クラス内からselfでクラス変数にアクセスするのと、インスタンス変数にアクセスするのは同程度の速度。
* ただの数値と変数に格納した数値へのアクセスはほとんど変わらない。これらの結果をまとめる。なお、Pythonのバージョンは3.9.12を用いた。
**環境依存で変わる可能性があるため、必要に応じて後述のコードで確認してください。**# 結果
後述するプログラムで各処理に1億回アクセスした際の実行結果を先に示す。~~~
数値 1.6297178 s
クラス外からクラス変数(staticに) 3.2673602000000006 s
クラス外からクラス変数(objectから) 2.5934605999999993 s
クラス内からクラス変数(staticに) 3.272198800000001 s
クラス内からクラス変数(
[学習メモ]pytorchでよく使う関数
[最短コースでわかる PyTorch &深層学習プログラミング](https://qiita.com/makaishi2/items/2c40fe43c01b35acb8c4)より
## view関数
numpyでいうところのreshape## item関数
スカラーに対しては、テンソルからpython本来のクラスの数値(floatまたはint)を取り出すのに使う。
1階以上のテンソルには使えない。## numpyへの変換
“`
x_np = x.data.numpy()
“`
[学習メモ]テンソル生成時の注意点
[最短コースでわかる PyTorch &深層学習プログラミング](https://qiita.com/makaishi2/items/2c40fe43c01b35acb8c4)より
テンソル生成時には、必ず後ろにfloat関数の呼び出しを付けてdtype(テンソル変数の要素のデータ型)を強制的にfloat32に変換するようにする。Numpy変数に対してこの処理を忘れた場合、dtypeがfloat64になり、機械学習で利用するライブラリを使うときにエラーになる
“`python
x=torch.tensor(1.0).float()print(type(x))
print(type(x.dtype))
“`
出力
“`
torch.float32
“`
【Python】SageMakerでPyTorchうごかしてみたった【SageMaker】
MLでSageMaker使ってみたいと思ったので、サンプルを一通りやってみたいと思います。
なお、SageMakerもPyTorchもほぼ触ったことなし。ノートブックで実行していきます。
# ノートブックインスタンスの作成
AmazonSageMakerを開くと右上にノートブックインスタンスの作成というボタンがあるのでそこから作成を開始。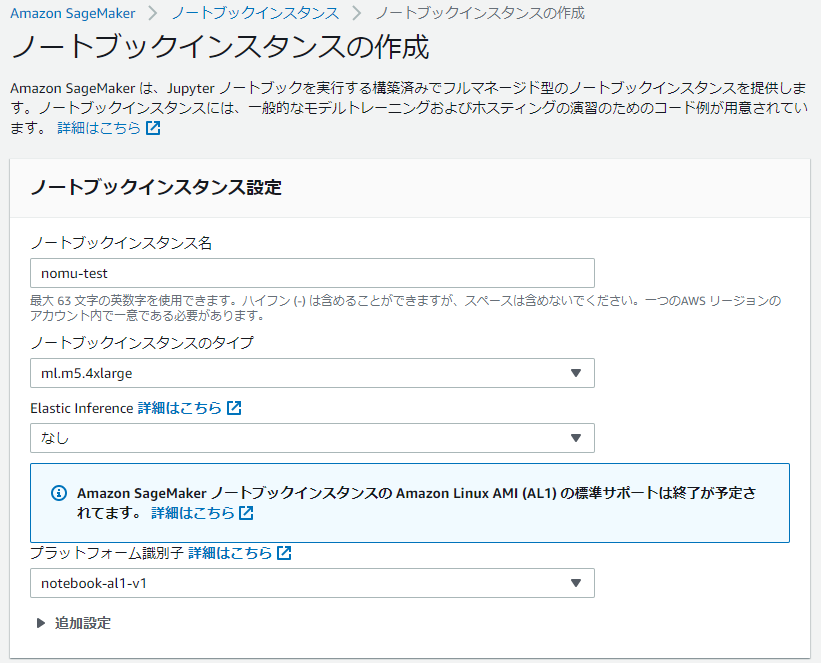
名前とml.m5.4xlargeを指定しました。これは無料枠らしいので選択してみてます。[参考](https://aws.amazon.com/jp/sagemaker/pricing/)
こちらでインスタンスを作成しました。
簡単ですね.
## 次に2層の場合を見てみましょう$w_1$は1層目の重み,$w_2$は2層目の重みです.
で機械学習をテーマにしている授業動画を拝見したことをきっかけに、AIに興味を持ち、2021年11月1日から[Aidemy](https://aidemy.net/grit/premium/?utm_source=google&utm_medium=cpc&utm_campaign=brand_brand_PPLP&gclid=CjwKCAjwx46TBhBhEiwArA_DjJhr_wVlOGG_XJ1aQf4XR1lj5YqQrQq_iwiPjtxsNfKSGskZr-vNoRoCnBkQAvD_BwE)で機械学習について学び始めました。(受講期間:2021年11月1日〜2022年5月1日)
Pythonの基礎から機械学習の基礎までみっちり学ぶことができ、とても充実した半年になりました。受講終了後は、`かめ@米国??データサイエンティスト/コミュニティ”DataScienceHub”`を活用し、さらなるスキルアップに努めていきます。最終成果物として、顔識別アプリを作成しま
pymupdfを使ってpdfのwidthとheightを取得する
# 使用バージョン
> python==3.8
> PyMuPDF==1.19.6# やり方
“`python
import fitz
target_path = “xxx/yyy.pdf”
# pathlibを用いたパスでも良いdoc = fitz.open(target_path)
page_num = 0
page = doc.load_page(page_num)pdf_width = page.rect.width
pdf_height = page.rect.height
“`# 参考文献
[PyMuPDF公式ドキュメント](https://pymupdf.readthedocs.io/en/latest/page.html#Page.rect)
初心者は面倒くさくてもprint系関数で挙動を確認しようね
# print系関数使っていますか?
C言語なら `printf()` 、Pythonなら `print()`、どんな言語を学ぶ際にも「Hellow World!」を出力する関数をまず学びますよね?
(本記事ではそれらを **print系関数** と呼びます)それから多くの関数やループ処理を学んだあと、もしあなたのプログラムが思った通りに動かなかったら、それは最初に学んだ `print` 系の関数を使いこなしていないからではないでしょうか?
## 頭の中で何回シミュレートしても、実際コードを走らせると思った結果が出なくて悩んでませんか?
以下はPythonで `openpyxl` ライブラリを使って、Excelのシートをリストに従って並べ替える自作関数の一部です。リストを `reversed()` で逆順に読んだり、任意の位置以降に並べ替えたシートを配置するためにシートの移動距離 `offset=` を数式で表現したりと少しテクいことをしています。
慣れた人でないとパッと見このコードが何をしているかわかりにくいのではないでしょうか?
~~~python
import o
APIでコンフルエンスのグループを取得してExcelに書き出す
# はじめに
コンフルエンスのグループ情報を取得してExcelに書き出す処理の実装です。
実務で地味に使ってるので記事にしました。その内Githubに集約していきます。
数年前に書いたモノなので恥ずかしいコードになってるのはご容赦ください。
—
## ライブラリ
openpyxlはpipで追加インストールrequests、json、astは標準ライブラリです。
## コード
“`getgroups.py
import openpyxl
import requests
import json
import astauth = (“hogehoge@hoge.co.jp”, “APIキー情報”)
def GetGroups():
wb = openpyxl.load_workbook(“test.xlsx”)
sht = wb[‘Sheet1’]
url = “https://xxxx.atlassian.net/wiki/rest/api/group”headers = {
“Accept”: “appli




