
- 1. 完全順列(Derangement)の個数を包除原理で求める方法とその応用
- 2. 同じものを含む順列の生成と数
- 3. MacのTabでハマった(vscode-python-split)
- 4. 【Django】1度のフォーム送信で複数テーブルにデータを保存する方法
- 5. リストからL以上R以下を取り出す
- 6. PyLadies勉強会(OpenPyXLライブラリ研究) 参加レビュー ~ 4月29日@飯田橋
- 7. Python3エンジニア認定基礎試験の勉強でつまずいたところ【ユーザー定義関数編】
- 8. Multi-Page Tiff で保存された動画をPythonで開く
- 9. Heroku Posgres へ pg8000 に接続しようとしてどハマリした話
- 10. 初期値鋭敏性について(ロジスティック写像)
- 11. pythonで画像を実寸大印刷してみる
- 12. 楽して使うTkinter(ウィジット編)
- 13. M1macでのPython環境にうんざりしちゃったので再環境構築した
- 14. Python で型ヒントを明記する
- 15. 【Python】pythonでtweetしてみた
- 16. [Python実践]Loggingに挑戦してみよう!《応用編》〜公式ドキュメントをもとに解説〜
- 17. KNIMEで自作の物性予測モデルを実行する
- 18. Flask についてまとめ
- 19. サンプルプログラムの使い勝手を向上させる。
- 20. AWSのライフサイエンス分野向けグラフ深層学習ライブラリ DGL-LifeSci を触ってみた
完全順列(Derangement)の個数を包除原理で求める方法とその応用
### 完全順列(Derangement)とは
以下に詳しい説明と公式が載っていますが、今回は後の応用も考えて包除原理を用いたものを使います。
> [攪乱順列(完全順列)の個数を求める公式(高校数学の美しい物語)](https://manabitimes.jp/math/612)
> 1 から n までの整数を並び替えてできる順列のうち,すべての i について「i 番目が i でない」を満たすものの個数### 包除原理を用いて完全順列の式を求める
「完全順列ではない」= 「1が移動しない」または「2が移動しない」または …「nが移動しない」と考えて
“`math
A_i : iが移動しない順列の集合 \\
a_n = n!-|A_1 \cup A_2 \cup \dots \cup A_n | \\
この和集合の部分を包除原理を用いて \\
積集合に変換します \\
a_n = n!-(\sum_i |A_i| \\
-\sum_{i
同じものを含む順列の生成と数
### 同じものを含む順列(distinct_permutations)
結構よく使うけど自分で作ると実装に工夫が必要なので**more_itertools**の**distinct_permutations**を使うと簡単です。
“`python
from more_itertools import distinct_permutationsfor p in distinct_permutations(‘1122’):
print(”.join(p))
#1122
#1212
#1221
#2112
#2121
#2211
“`### 同じものを含む順列の数
もちろんdistinct_permutationsを数えても良いのですが、もう少し効率よく以下の手順で。
* ソート ⇒ ランレングス ⇒ 全体の階乗をランレングスの階乗で割る
“`python
from math import factorial as fct
def rl(a): # run length of the list
a.sort()
ret, l = [], 1
MacのTabでハマった(vscode-python-split)
pythonでタブ区切りのデータを取得しようとした時にうまくいかなくてハマったのでメモを残しておく
元データはとある教本(とても勉強になります)に書いてあったらサンプルデータをダウンロードしたもの
“`sample.txt
# 実は区切りがスペース4個になってしまっています
こんばん(は|わ)$ こんばんは|お疲れ様です
・・・・・
“`ファイル自体は恐らくWindows向けを想定されていると思います。
それを以下の文で読んでみる“`getdata.py
pfile = open(‘sample.txt’,’r’,encoding=’utf_8′)
p_lines = pfile.readlines()
pfile.close()
new_lines = []
for line in p_lines:
# 区切り文字で右から分割
str = line.rstrip(‘¥n’)
if (str != ”):
new_lines.append(str)
pattern = {}
for line in new_lines:
【Django】1度のフォーム送信で複数テーブルにデータを保存する方法
Djangoを使用して漫画の評価を登録できるアプリを作成することにしました。
その際、1度のフォーム送信で複数テーブルにデータを保存する必要があったため、以下の記事を参考にしてその実装を行いました。[Django、インラインフォームセットの基本的な使い方](https://blog.narito.ninja/detail/32/)
では実装方法を説明します。
説明に不要なコードは省略して記載しています。## 使用したモデル
なぜ1度のフォーム送信で複数テーブルにデータを保存する必要があったかというと、1つの漫画に対して複数の評価を登録できるようにしたかったからです。
また今後評価項目を増やし、評価内容の詳細を別テーブルに保存する方法も考えています。
まず暫定的に作成したモデルが以下のようになっています。この漫画の名前と漫画の評価を同時に保存できるようにしていきます。models.py
“`python
from django.db import models
from django.core.validators import MaxValueValida
リストからL以上R以下を取り出す
# きっかけ
範囲指定のあるクエリを処理していくタイプの問題で、以上以下の条件を満たす個数だったり要素だったりを集計することがあります。その問題対策用の個人的なメモです。# 注意点
高速化を考えてみたのですが、二分探索でのゴリ押ししか思い浮かびませんでした。
なので、配列をソートしている必要があります。なにかいいアイデアがあったら教えてください。。。また、コンテストでの利用などは自己責任でお願いいたします。
# コード
“`python
from bisect import bisect_left,bisect_right#任意の数列
seq = [3,5,8,9,12,12,22,23,30]def LR_calc(L,R,seq):
# L以上R以下の要素の個数と、切り出したリストを返す
return bisect_right(seq,R)-bisect_left(seq,L),seq[bisect_left(seq,L):bisect_right(seq,R)]# すべて取り出す
print(LR_calc(2,31,seq))
prin
PyLadies勉強会(OpenPyXLライブラリ研究) 参加レビュー ~ 4月29日@飯田橋
今回、初めてPyLadies Tokyo のオフライン勉強会(4月29日 13:00~17:00 @ 飯田橋)に参加してきました。
■ PyLadies Tokyoとは?

当日は
PyLadiesの概要説明 ⇒ 課題着手 ⇒ 発表という流れでStaffの方にサポートして頂きながら、実際にPythonライブラリについて調べていき、各人それぞれ簡単にGoogleSlideにまとめて発表をしました。
以下、OpenPyXLライブラリについて調べた内容について記載していきます
<
Python3エンジニア認定基礎試験の勉強でつまずいたところ【ユーザー定義関数編】
# はじめに
2022年4月15日、Python3エンジニア認定基礎試験に合格しました。
試験対策は各認定スクールさんが出している模擬試験で行っていました。
模擬試験を解いていて、プログラミング初学者の私がつまずいたところを備忘録としてまとめようと思います。
今後同じ箇所でつまずいた方の一助となれば幸いです。
*問題は一部改変しています。# 模擬試験の問題
##### 問1.以下のプログラムを実行した際の出力結果を答えよ。
“`python:test.py
def dive_into_code(teacher, L = []):
L.append(teacher)
return Lprint(dive_into_code(‘Noro’))
print(dive_into_code(‘Nakao’))
print(dive_into_code(‘Miyashita’))
“`
***正解***がこちら。
“`console:console
[‘Noro’]
[‘Noro’, ‘Nakao’]
[‘Noro’, ‘Nakao’, ‘Miyashita’]
“`
こ
Multi-Page Tiff で保存された動画をPythonで開く
昔 ImageJ で撮影した動画を再生するために
“`py
from PIL import Image, ImageSequence # Tiffファイルを開くのに使う
import numpy as np # PILの画像ファイルを numpy の array に変換する
import cv2 # 動画を表示する
import time # フレームレート算出のためim = Image.open(“multi-page.tif”)
frames = map(np.asarray, ImageSequence.Iterator(im))
FRAME_RATE = 30
delay = int(1000 / FRAME_RATE)t = time.time()
for frame in frames:
# show frame
cv2.imshow(“frame”, frame)# frame rate (viewing)
_t = time.time()
print(“Frame Rate: {}”.format(1.
Heroku Posgres へ pg8000 に接続しようとしてどハマリした話
# 序文
[Heroku Postgres](https://jp.heroku.com/postgres) と [pg8000](https://pypi.org/project/pg8000/) のイケていない部分が負のシナジー効果を生み出した結果大変苦労した話です。
# 本文
## Heroku Postgres について
Heroku Postgres は ポートフォリオ作成用サーバ御用達となって久しい Heroku が公式に用意している PosgreSQL のアドオンサーバーです。
よく使用されるClearDB, JawsDB と同じく無料プランと、スケーラブルが容易な有料プランに分かれています。
今回は無料プランに関するお話です。(有料プランも同じかもしれない)## pg8000 について
pipでも配布されている PostgreSQL 用接続ドライバモジュールです。
pythonでPostgreSQLに接続するモジュールは “psycopg2” あたりがよく使用されている印象ですが、このモジュールはプレースホルダの文字列が `%s` 固定で、一般的な `?`
初期値鋭敏性について(ロジスティック写像)
初期値鋭敏性について紹介したいと思います。
非線形の数理モデルであるロジスティック写像を対象として、初期値鋭敏性を確認します。ロジスティック写像については、[ロジスティック写像の紹介](https://qiita.com/reser_ml_memo/items/878927bf473bd025b16a)に掲載しています
ロジスティック写像は以下の漸化式のような形で表されます。
$x_{n+1} = a x_{n}(1-x_{n})$
漸化式の形で書けますが、カオスと呼ばれる不規則な動き(以下の図)をします。
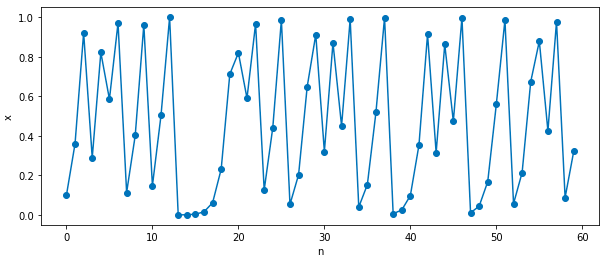では本題の初期値鋭敏性の話に入っていきます。
初期値鋭敏性とは、カオスの定義あるいは特性の一つになります[1]。
初期値鋭敏性を実際に見てもらうために、初期値$x_{0}=0.1$に微
pythonで画像を実寸大印刷してみる
## はじめに
皆さん、「この画像を8cm × 4cmで印刷したい!」という時にどうすればいいかご存知でしょうか?
ちなみに私はわかりませんでした。調べてみるとExcelでああしてWordではこうして・・と説明されるのですが面倒になって諦めました。
という訳で、pythonで実寸大印刷するコードを書いてみます。※Windowsのみで動作します
## コード
“`python
import win32print
import win32ui
from PIL import Image, ImageWinclass Printer:
# 下記はプリンタの固有情報を取得するためのキー
# http://chokuto.ifdef.jp/urawaza/api/GetDeviceCaps.html
WIDTH_IN_PIXEL = 8
HEIGHT_IN_PIXEL = 10
WIDTH_IN_MM = 4
HEIGHT_IN_MM = 6
LOGPIXELSX = 88
LOGPIXELSY = 90
楽して使うTkinter(ウィジット編)
# 楽して使うTkinter(ウィジット編)
同じコードをコピペするというのはその場では簡単かもしれませんけれども後々地獄になりがちです。ちょっとした動作の変更をしたいのに直す場所が多数、しかも分散していて、とか目も当てられません。
ずぼらに楽をするには一か所直せばすべて直るくらいの勢いでスマートにやりたいものです。
今回はよくある疑問でよく目にする
– ラベルの文字って後からどうやって変えるのー?
あたりをやってみましょうか。
## じぶんLabelウィジットクラスを作る。
tk.Labelを継承して じぶんラベル を作ります。
じぶんウィジットなので好きなように作ります。ポイントは毎回毎回書いていてめんどくさいなっていう部分はフォローしておくこと。
自分自身が使いやすければ、少なくとも自分しか使わないなら。最悪動作するならば何も問題ありません。好きにやりましょう。
“`python:label.py
import tkinter as tkclass Label(tk.Label):
def __init__(self, root, cnf={}
M1macでのPython環境にうんざりしちゃったので再環境構築した
現行販売されているMacがM1プロセッサーに置き換わり、対応するアプリはとても早くて満足なのですが、開発環境の構築などは、ライブラリが対応していないなど、引っかかることが多いです。
(研究室や職場で仕方なくM1使ってて、苦労している方もいるのではないでしょうか。)今回は、M1のMacbookで、『Intel MacのPython環境』を再現してみたのでやり方を残しておきます。
:::note warn
大事なデータを削除してしまう可能性があります。
TimeMachineでのバックアップなど、十分な対策の上、自己責任で行ってください。
:::## (Intel版)Homebrewのインストール
環境構築には必須なので、一番最初に入れます。
`arch -x86_64`を先頭に付けることで、Intel用がインストールされます。“`: bash
$ arch -x86_64 /bin/bash -c “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)”
“`
Python で型ヒントを明記する
# 当記事の目的
Python3 での型ヒントの書き方を紹介する。# 型ヒントを書く理由
Python では型を示さずとも変数、引数、戻り値の定義ができるので、型がいまいち分かりづらい。
そこで型ヒントを明記すると、それぞれの変数、引数、戻り値の型が一目見てわかるようになり、親切な実装になる。# 基本的な書き方
“`python
# メソッドの引数と戻り値の型を示す
def get_item(id: int) -> str:
“””
item を取得する:param id: ID
:return 文字列
“””
# 変数の型を示す
item_name: str = “hogehoge”
“`# 各種型ヒントの書き方
個人的に使用頻度の高い型の型ヒントの使い方を、以下に示す。## int
数値型の場合。“`python
# 使用例
number: int = 1
“`## str
文字列型の場合。“`python
# 使用例
name: str = “piyopiyo”
“`#
【Python】pythonでtweetしてみた
## 概要
pythonでtweetしてみた。## 前提条件
Pythonが既にインストールされていること。## API(tweepy)のインストール
コンソールを開いて下記のコマンドを実行する。“`
pip install tweepy
“`## APIキーとアクセスキー、トークンの取得
下記のURLを参考に認証に必要なキー情報を取得する。http://kakedashi-xx.com:25214/index.php/2021/05/23/post-2475/#toc8
## Pythonでツイートを実行
Essentialだと下記のエラーが出たためtweepy + Twitter API V2でツイートのプログラムを参考にしました。ありがとうございます。“`
53 – you currently have essential access which includes access to twitt
[Python実践]Loggingに挑戦してみよう!《応用編》〜公式ドキュメントをもとに解説〜
# はじめに
今回はPythonの「**Logging**」の応用について解説していこうと思います!
「**Logging**」の基礎についてはこちらの記事にまとめてあります。
https://chaldene.net/logging
「**Logging**」はPythonの実務などでよく使われるので、Pythonエンジニアを目指している方は是非この記事でマスターしていってください!
この記事はPythonの公式ドキュメントを参考にしています。
Pythonに限らず、プログラミング言語の公式ドキュメントは非常に読みにくいので、この記事でわかりやすく解説していきます。
「**Loggingよく見かけるんだけど全くわからない…**」
「**Pythonエンジニアを目指して学習中**」
「**Pythonスキルのレベルアップをしたい!**」
このような人のお役に立てれば幸いです。
それでは早速本題に入っていきましょう!
:::note
「Logging」はPythonの基礎を理解していないと難しいので、Pythonの基礎を理解していない人は以下を参考に学習してく
KNIMEで自作の物性予測モデルを実行する
# はじめに
前回記事 [AWSのライフサイエンス分野向けグラフ深層学習ライブラリ DGL-LifeSci を触ってみた](https://qiita.com/kimisyo/items/b5c73c9a599959ebc049)で作成した予測モデルを用いて、KNIME で化合物の物性を予測できるようにしてみたメモ# 前提
本記事では、KNIMEについては説明を省略する。# 環境
[前回](https://qiita.com/kimisyo/items/b5c73c9a599959ebc049)と同様以下の環境を用意する。ただしKNIMEは別途インストールする。
– Windows 10 (RAM16G、GPU:GetForce GTX 1060 6GB)
– Miniconda 3
– python 3.7
– pytorch 1.10.2
– dgl dgl-cuda11.0
– RDKit 2018.09.3
– KNIME 4.5.2# やり方
以下の方法で予測モデルを実行する。– 予測したい化合物のファイルはSDFに格納されている前提とする。
– SDFファイ
Flask についてまとめ
### Flaskはpython製のマイクロwebフレームワーク
マイクロwebフレームワーク
はコアとなる機能を保ちつつ、拡張性を持っているフレームワークのことを言います
こちらの記事は本の紹介となりますhttps://codezine.jp/article/detail/15432
電通国際情報サービスISID AIトランスフォーメーションセンター 小川 雄太郎様が翻訳されたサイトもあります
Google Colaboratoryでの実装https://colab.research.google.com/github/YutaroOgawa/pytorch_tutorials_jp/blob/main/notebook/5_Deployment/5_1_flask_rest_api_tutorial_jp.ipynb
### Google Colaboratoryでの実装コードを眺めて概要をつかむ
ソースコードを見るとFlaskのドキュメントを参考にした、シンプルなWebサーバーを構築されています
https://www.no1web.jp/blog/1500
サンプルプログラムの使い勝手を向上させる。
オープンソースで実装されているアルゴリズムを、ライセンスを確かめたうえで、自分なりに使いこなしてみよう。
想定する読者: 中級レベル
ふだんから、最新版のPythonの機能を活用しきっている人にとっては、何をいまさらという内容しか書いていません。前提:
Python3## 自分なりの改変の常套手段
### 不必要なimport をなくす。
– 高機能な開発環境(例: pycharm)の場合だと、不必要なimportがあると表示で区別してくれる。
– 不必要なimportは、そのプログラムの動作環境を無駄に狭めてしまう。
– 使っていないライブラリのために、動作環境を狭めてしまうことはやめよう。
– 参考: 言語によっては不必要なimportがあるとビルドに失敗する言語もある。### `from モジュール import *`をなくす
– モジュールからすべてをimportするのは、変数・関数などの由来を不明にしてしまうので止める。
– from モジュール import 識別子1, 識別子2と書き換えていく。
– `from モジュール import *`をなくした
AWSのライフサイエンス分野向けグラフ深層学習ライブラリ DGL-LifeSci を触ってみた
# はじめに
AWS がライフサイエンス分野向けグラフ深層学習ライブラリをリリースしていると聞き、触ってみたメモ。その名も「DGL-LifeSci」。
DGLというグラフ深層学習ライブラリをベースとした、ライフサイエンス分野向けの機能やアルゴリズム搭載したライブラリである。# 何ができるの?
ざっくりいうと以下の4種類のバイオ/化学に関するタスクを行うことができる。– Molecular property prediction (分子の特性予測)
– Generative models (生成モデル)
– Reaction prediction (反応予測)
– Protein-ligand binding affinity prediction (タンパク質-リガンド結合親和性予測)これらタスクを実現するための様々なアルゴリズムが搭載されている。
# 環境
以下の環境で確認した。– Windows 10 (RAM16G、GPU:GetForce GTX 1060 6GB)
– Miniconda 3
– python 3.7
– pytorch 1.10.2
–




