
- 1. 特定のデータの名前を取得する方法:str.contains, srt.startswith
- 2. 書籍「Pytorch&深層学習プログラミング」2章補足PART2 sum関数をmax関数に置き換えると何がおきるか?
- 3. Githubに100MB以上のファイルをプッシュする方法
- 4. フォルダの構成や、命名規則のベストプラクティス
- 5. DropboxAPIのAccessToken&RefreshToken備忘録
- 6. 表面符号をqiskitで実装①
- 7. 【Pythonで作図】忙しい人のための Matplotlib【初心者向け】
- 8. [Python実践]argparseに挑戦!《ArgumentParser編》
- 9. FastAPIで作ったAPIをPowerBIからGETする方法
- 10. 書籍「Pytorch&深層学習プログラミング」2章補足 sum関数で微分計算ができる理由
- 11. 「ベクトル・行列からはじめる最適化数学」でお勉強 -Vol.1-
- 12. pymatgenを用いてVASP POSCARファイルからdensityを計算する
- 13. python flaskアプリ作成とPOSTリクエスト
- 14. AWS Lambda HTTP APIでPOSTデータを取得・デコードする関数(関数URL対応)
- 15. ksnctf q40 Deep Flag Network
- 16. 日経平均、ダウなどの構成銘柄一覧を取得する
- 17. 『Python2年生 スクレイピングのしくみ』で勉強中(その1)
- 18. pythonで「統計学入門」7 仮説検定
- 19. requestsで非同期Asyncリクエスト【HTTPX】
- 20. 完全順列(Derangement)の個数を包除原理で求める方法とその応用
特定のデータの名前を取得する方法:str.contains, srt.startswith
顧客IDがAから始まるデータだけ取り出したいなぁ
1学年から2学年のデータだけ取り出したいなぁなんてことが大量のデータの中から取り出すのなにかと面倒ですよね。
そんなときに用いるのが、
`str.startswith(‘文字列’)`と`.str.contains( )`になります。
これをqueryメソッドと合わせて書き込むことで、特定の情報のみ取り出すことができます。“`Python
import pandas as pd
df01 = pd.DataFrame( {‘name’:[‘A’, ‘B’, ‘C’],
‘学年’:[“1学年”, “2学年”, “3学年”],
‘math’:[60, 70, 80]})
df01
“`
“`
name 学年 math
0 A 1学年 60
1 B 2学年 70
2 C 3学年 80
“`
これらの3学年のデータを取り出したいときは、以下の記述をします。
“`Python
df01.query(“学年.str.startswith(‘3’)” , engine=”python”)
`
書籍「Pytorch&深層学習プログラミング」2章補足PART2 sum関数をmax関数に置き換えると何がおきるか?
# はじめに
この記事は、別記事[書籍「Pytorch&深層学習プログラミング」2章補足 sum関数で微分計算ができる理由](https://qiita.com/makaishi2/items/a6cf19add4b6d16b8483)の続編です。
前の記事では、$y=f(x)$の値の1階テンソルをsum関数で集約すると微分計算ができること、mean関数だと、微分計算ができるが、値は導関数値をデータ個数で割ったものになることを示しました。
この記事のテーマは、**代わりにmax関数を使うとなにがおきるか**ということです。# 実装と結果
# 数学的な解説
Githubに100MB以上のファイルをプッシュする方法
# はじめに
– GitHubでは100MB以上のファイルをプッシュすると拒否され、50MB以上のファイルをプッシュすると警告される仕組みとなっています。
– 今回はGitHubに100MB以上のファイルをプッシュする方法を考えてみたいと思います。# Githubに100MB以上のファイルをプッシュする方法
– 100MB以上のファイルをそのままプッシュするとGithubに拒否されてしまうため、ファイルを分割してプッシュしようと思います。
– また、50 MBより大きいファイルを追加または更新しようとすると、Githubから警告が表示されるので、49MBでファイル分割しようと思います。
– 具体的には、ZIPファイルをbase64にエンコードして、49MBのテキストファイルに分割してプッシュします。
– 元のファイルに戻すときは、分割したテキストファイルのテキストを結合して、デコードすればZIPファイルに戻ります。# 実装
Pythonで実装したコードが以下です。### フォルダ構成
“`
ディレクトリ
├─main.py
├─setting.json
├─input
フォルダの構成や、命名規則のベストプラクティス
https://qiita.com/EasyCording/items/531ef712926b2419e494
# 昨日のハマり事
* 機械学習アプリをJupyterで開発していて、そろそろパッケージングを考えようとしている。
* しかしながら、フォルダの構成や、命名規則のベストプラクティスが見つからない。# フォルダ構成
* 登場すべきメンバーは、だいたい分かってきた。
* 機能としてはForexが前処理で、Resultが後処理になっている。
* 機械学習のコアは除いている。# 命名規則
元々のファイルは以下の状態であった。“`
├─crud.py
├─model.py
├─router.py
├─schema.py
“`* 今回、ソースが大きくなってきたこともあり、次のような命名規則にしている。
* フォルダ名を機能で分割し、ファイル名には“`名前_機能.py“`という規則にしている。“`
├─cruds
│ │ forex_crud.py
│ │ result_crud.py
├─models
│ │ forex_model.py
DropboxAPIのAccessToken&RefreshToken備忘録
# 結論
DropboxAPIのAccessTokenは一定期間でリセットされアクセス出来なくなる。
毎回AccessTokenを発行しなおすのは面倒なので、RefreshTokenを発行し接続することで回避する。## AccessTokenの発行方法(一応)
https://www.dropbox.com/developers/
ここにアクセスし、**アプリを作成** or **右上のAppConsole**から選択
permissonから必要な権限を有効化し、ダッシュボードの“`setting/Oauth2/GenerateAccessToken“`で発行する。
### AccessTokenでの利用方法
“`
import dropboxdbx = dropbox.Dropbox(`
‘)
“`## RefreshTokenの発行方法
まずはauthorization_codeを取得する。(後で“`“`に入力する) ダッシュボードの“`setting“`にある**App key
表面符号をqiskitで実装①
表面符号[5,1,2]をqiskitで実行できるLogicalqubitクラスというクラスを作成してみました。
“`
Logicalqubit(logicalqubits=2, codecycle=2, shots=1000, backend=’aer_simulator_stabilizer’)
“`
logicalqubitsは論理量子ビットの数、codecycleはシンドローム測定の回数、backendはqiskitのシミュレータを指定します。
この例では、2論理量子ビット、シンドローム測定を2回行います。
backendは’aer_simulator_stabilizer’を指定しました。aer_simulator_stabilizerはクリフォード演算しか実行できませんが、使えるビットの数が多いのでとりあえずこれを使います。以下のコードを実行すると、演算を実行した後のシンドローム測定の結果を返します。
“`
a = Logicalqubit(logicalqubits=2, codecycle=2, shots=1000, backend=’aer_simulat
【Pythonで作図】忙しい人のための Matplotlib【初心者向け】
# ✨Python って作図がカンタン!✨
**「Pythonで作図」**…。ネットにはたくさん記事があるけど、どれも**ややこし**くて**難しい**ですよね。
そんな方々のために、**手っ取り早く**て**分かりやすい**「Python 3分クッキング」をやっていこうと思います!# 0. 完成目標
これを作ります。
“`python:完成コード
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-100,100,0.1)
y = np.sin(x)/x
plt.plot(x,y)
plt.show()
“`
**結果**
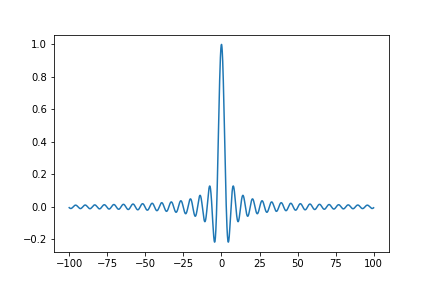では、始めます。
# 1. これをコピペ
“`python:【必須】おまじない(計算と作図に必要な道具を準備
[Python実践]argparseに挑戦!《ArgumentParser編》
# はじめに
今回はPythonの「**argparse**」の基礎と「**ArgumentParser**」の使い方について解説していこうと思います!
「**add_argument**」についてはこちらを参考にしてください。
https://chaldene.net/argparse-addargument
https://chaldene.net/argparse-parseargs
「**argparse**」コマンドライン引数を渡してくれるもので、Pythonエンジニアを目指している方は知っておいた方が良いものになります。
ぜひこの記事でマスターしていってください!
この記事はPythonの公式ドキュメントを参考にしています。
Pythonに限らず、プログラミング言語の公式ドキュメントは非常に読みにくいので、この記事でわかりやすく解説していきます。
「**argparse使ってみたい**」
「**コマンドライン引数を渡してみたい**」
「**argparseって何?**」
「**自作モジュール作ってみたい**」
このような人のお役に立てれば幸いです。
FastAPIで作ったAPIをPowerBIからGETする方法
## モチベーション
* 任意のDBアクセスや機械学習、計算処理などをAPIにして、PowerBIからAPIをたたけば、ダッシュボードと複雑な計算処理を組み合わせることができ、色々なことがローコードで実現できるのではないか?
* PowerBIのカスタマイズ性を活かしつつ、計算処理はAPI側に任せることで、柔軟性・高機能のダッシュボードを作成できるのではないか?
* 社内政治的にローカルPCからDBサーバーへの直接接続が禁止されているため、APIサーバー(APIには認証機能を搭載することが前提)を介することで1つの解決策を提供できるのではないか?## この記事の前提
* 開発者はPython環境、PowerBI環境をすでに入手していること。
* PowerBIからAPIサーバを介してデータにアクセスする。
* APIサーバーはFastAPIで作る。
* FastAPIやPowerBIの詳しい使い方は解説しない。あくまで連携の手順のみ。
※API開発はFastAPIでなくても良いが、業務で使い始めた都合でここではFastAPIを使っている。## OS・Python・ライ
書籍「Pytorch&深層学習プログラミング」2章補足 sum関数で微分計算ができる理由
# はじめに
書籍「Pytorch&深層学習プログラミング」の著者です。[Amazonリンク](https://www.amazon.co.jp/dp/4296110322)
[サポートサイトリンク](https://github.com/makaishi2/pytorch_book_info/blob/main/README.md)この書籍の2章p.81-p.87にかけてPyTorchの勾配計算機能を使い、関数の導関数を計算し、グラフ表示をしてます。
そこでは、“`py
import numpy as np
import torch# xをnumpy配列で定義
x_np = np.arange(-2, 2.1, 0.25)# 勾配計算用変数の定義
x = torch.tensor(x_np, requires_grad=True,
dtype=torch.float32)# 2次関数の計算 裏で計算グラフが自動生成される
y = 2 * x**2 + 2# 勾配計算のためには、最終値はスカラーの必要があるため、sum関数をかける
z = y.s
「ベクトル・行列からはじめる最適化数学」でお勉強 -Vol.1-
Pythonを理解して使いこなせているわけではなく、膨大なライブラリをある程度覚えることやオブジェクト指向の理解など、まだまだ課題はあり相変わらず地道に勉強を続けているところだが、私がPythonを勉強する気になったキッカケとなった「機械学習」「統計分析」についてそろそろ勉強してみたいと思った。
そんで現在所属させて頂いているコミュニティのメンバーさんにご紹介された本[ベクトル・行列からはじめる最適化数学](https://amzn.to/3F09pRp)を使って勉強を進めていこうと思う。
私、学生の頃も真面目に勉強した試しがないので、こちらに記載している事に関しては一切責任は持てないのでご留意を。
# ベクトルとは
> ベクトル(vector)は有限個数の数値を並べた順序付きのリストである。
>> 引用:[ベクトル・行列からはじめる最適化数学](https://amzn.to/3F09pRp)ベクトルの定義はこんな感じだそう。ちなみに、同じ次元のベクトルを複数並べたものが行列っていう記事をどこかで読んだ気がする。ベクトルや行列は丸かっこや角かっこで囲むのが一般的だそう。
pymatgenを用いてVASP POSCARファイルからdensityを計算する
pymatgenを用いてお気軽に密度を求めるコードを作りました。秘匿すべきノウハウではないと判断し、ここに書き記すこととします。
結果だけであれば「1. まずは帰結」をご覧ください。
通常外部ライブラリを活用する場合、私は普段サンプルコードを探します。APIリファレンスというものの見方が分からない状態が長かったのですが、最近そのあたりの勘所を得るに至っています。今回はpymatgenのAPIリファレンスを見ながら自力解決を行ったプロセスというものをお見せできればと思います。今回は密度算出をテーマとしていますが、この思考回路があればそのときどきの問題に応じ自力解決を進めやすくなると考えています。ご興味持たれましたら「3. API紐解きの思考回路」をご笑覧ください。
# 1. まずは帰結
“`python
from pymatgen.io.vasp.inputs import Poscar### read POSCAR file (edit file name ‘xxxxx.vasp’ as you
python flaskアプリ作成とPOSTリクエスト
Flaskの初歩的な使い方を学んだので、備忘録として記録致します。
# Flaskとは?
pythonのWebアプリケーションフレームワークで、簡単なwebアプリケーションを作ることに適しています。Flaskの設計思想として「コアとなる機能を保ちつつ、拡張性を持っているフレームワーク」があるそうです。##### インストール方法
`pip install flask`# まずはHello Flask
“`python:flask_test1.py
from flask import *app = Flask(__name__)
@app.route(“/”)
def index():
return jsonify({“ans”: “Hello Flask!”})
“`ローカルにアクセスすると下記の結果が返ってくる

## HTTP APIや関数URLでもPOSTデータを受け取りたい
手軽に実装できてお財布にも優しいHTTP APIですが、POSTデータを受け取るのに一手間必要です。
リクエストbodyはbase64エンコードされた状態で取得できるため、 デコード & jsonパースしてあげる関数を使えばOKです。## コード
### Node.js
“`getBodyOnLambda.js
function getBodyOnLambda(event_body) {
let body_string_utf8 = Buffer.from(event_body, ‘base64’).toString(‘utf-8’);
//日本語が含まれる場合はdecodeURIする
//decodeURIComponentでは無くdecodeURIなのは、POSTされたデータの中に&が含まれているとJSON変換時にうまくいかないため
body_string_utf8 = decodeURI(body_string_utf8);
//パラメーター形式文字列のJSONへの変
ksnctf q40 Deep Flag Network
q40.zipをダウンロードすると学習用と評価用のコードがあった。
train.pyを見るとcifar10のデータセットを使い、7層の全結合層で11クラスの多クラス分類を学習している。
cifar10の10クラスに、flagクラスを11番目のクラスとして追加して学習している。flagの教師データは32×32サイズのQRコードのようだが学習に使用したflag.pngは当然入手できない。flag.pngを適当なQRコードで作成して、学習、評価を行ってみると、問題文と同様に、学習したflag.pngの推論結果が99.5%となった。
学習に使用したflag.pngをなんとかして復元する問題のようだ。pythonにはqrcodeモジュールがあり、文字列からQRコードを生成できるので、遺伝的アルゴリズムなどを使ってflag.pngを類推できないかやってみたが、無理そうだった。そもそも同じ文字列でも作成されるQRコードが、ライブラリによって違うようなので、この方法でflag.pngを類推するのは無理そう。
もう一度学習用スクリプトを見ると、教師データにflag.pngのQRコードが500
日経平均、ダウなどの構成銘柄一覧を取得する
# はじめに
株式投資においては銘柄探しが重要である。
国内だけも何千とある銘柄をスクリーニングしてお化け株を探し出すのは困難であるし、そもそも投資は博打ではないのでこのようなお宝探しは現実的ではない。個人的には過去に数回遭った憂き目(持ち株会社が倒産)から新興市場の銘柄は手を出さないほうがよいという教訓を得ている。
そのため最近では国内株だと東証プライム(≒旧東証一部)をメインに取引している。> とはいうものの武富士で苦い思いをしたのだが。
そうすると上場企業すべてを把握するよりある程度安定した企業の銘柄を絞ったほうが自分としては都合がよい。
また数年前より米国株も取引しているので、今回は国内株と合わせて主な指数の構成銘柄を取得してみた。
# 各指数
## 日経平均株価指数(日経225)
[SBI証券](https://www.sbisec.co.jp/ETGate)バージョン
“`python
import pandas as pd
url = ‘https://site1.sbisec.co.jp/ETGate/?OutSide=on&_ControlID
『Python2年生 スクレイピングのしくみ』で勉強中(その1)
## この記事について
『Python2年生 スクレイピングのしくみ』(以下、書籍)でPythonを学習する超初心者の記録です。
『Python1年生』は人工知能を題材に、Pythonの基本的な文法等を解説していましたが、
こちらの書籍ではスクレイピングということで、人工知能とは別の題材になっています。■ バックナンバー
– [『Python1年生』で勉強中(その1)](https://qiita.com/megrim_q/items/c1417f507e96c1fb7015)
– [『Python1年生』で勉強中(その2)](https://qiita.com/megrim_q/items/333be033e5b4637d0eed)
– [『Python1年生』で勉強中(その3)](https://qiita.com/megrim_q/items/904f83c6a7e8594b7212)## 実行環境
| OS・MW・ライブラリ | バージョンなど |
|:-:|:-:|
| OS | Windows 10 Pro 21H2 19044.1645 |
| Pytho
pythonで「統計学入門」7 仮説検定
とても有名な「統計学入門」をpythonで実装しながら読んでいきます。
本をしっかり読むことと実装の勉強が目的ですので説明が不足していたりします。
また、実装方法に関してはベストなものではないと思いますのでご了承ください。### 前回
推定https://qiita.com/tanaka_benkyo/items/b6ab5cf96f3158daa0fc
### 仮説検定
### 検定の考え方
#### 有意性検定
仮説検定の目的は、母集団について仮定された命題を、標本に基づいて検証することである。
理論比からのずれが誤差の範囲内であるか、それ以上の何かの意味のあるものかということが重要である。
後者の場合、統計学では仮説からのずれは有意であるという。
ここに立てられた仮説を統計的仮説または仮説という。したがって、仮説検定とは統計的仮説の有意性検定にほかならない。
有意性は標本が有意なずれを示す確率で表される。あらかじめその程度の基準の確率である有意水準$\alpha$を考えておく。
仮説検定とは、仮説が有意であるか否かに応じてそれを棄却するかしないかを決定することである。
requestsで非同期Asyncリクエスト【HTTPX】
https://colab.research.google.com/drive/1O7v-OLPpb0yG56n1PjkvuBDH0HsYl3-8?usp=sharing
# requestsをインストール
“`bash
pip install httpx
“`# requestsをインポート
150個のリクエストを作成します。
“`python
import httpx as requests
from asyncio import run, gatherurls = [f”https://pokeapi.co/api/v2/pokemon/{n}” for n in range(1, 151)]
“`# 同期(Sync)リクエスト 処理時間8.8秒
“`python
def sync_func():
print([requests.get(u) for u in urls])sync_func()
“`の個数を包除原理で求める方法とその応用
### 完全順列(Derangement)とは
以下に詳しい説明と公式が載っていますが、今回は後の応用も考えて包除原理を用いたものを使います。
> [攪乱順列(完全順列)の個数を求める公式(高校数学の美しい物語)](https://manabitimes.jp/math/612)
> 1 から n までの整数を並び替えてできる順列のうち,すべての i について「i 番目が i でない」を満たすものの個数### 包除原理を用いて完全順列の式を求める
「完全順列ではない」= 「1が移動しない」または「2が移動しない」または …「nが移動しない」と考えて
“`math
A_i : iが移動しない順列の集合 \\
a_n = n!-|A_1 \cup A_2 \cup \dots \cup A_n | \\
この和集合の部分を包除原理を用いて \\
積集合に変換します \\
a_n = n!-(\sum_i |A_i| \\
-\sum_{i




