
- 1. Qiitaの記事からコードブロック部分だけ抽出して表示するPythonスクリプト
- 2. [python] バイト数指定でテキスト切り出し
- 3. [AtCoder]Pythonにおける配列のコピー
- 4. NDLOCRのWebアプリを作ってみた【Gradio】
- 5. Githubに100MB以上のファイルをプッシュする方法
- 6. Apache AirflowのDAG設定値についてまとめてみる
- 7. DropboxAPIのAccessToken&RefreshToken備忘録
- 8. 【Pythonで作図】忙しい人のための Matplotlib【初心者向け】
- 9. データフレーム同士の結合(merge関数) について
- 10. 『Python2年生 スクレイピングのしくみ』で勉強中(その1)
- 11. requestsで非同期Asyncリクエスト【HTTPX】
- 12. Python3エンジニア認定基礎試験の勉強でつまずいたところ【ユーザー定義関数編】
- 13. 【Django】インストール方法
- 14. 競馬予想AI 勉強メモ#1 pandas DataFrameの特定行の抽出方法
- 15. discord、どう動いてる?
- 16. FastAPI: SQLAlchemy で MariaDB を使う (その 4)
- 17. Pythonで作るスネークゲーム
- 18. asyncio、コルーチン、async/await
- 19. JPXのデータを用いてデータ分析をしていく【データ読み込みからデータの中身理解】(Kaggleコンペ)
- 20. boto3を使って、さくらのオブジェクトストレージにファイルをアップしてみる
Qiitaの記事からコードブロック部分だけ抽出して表示するPythonスクリプト
Qiitaの記事に書かれたコードを動作確認することが多いので、Qiita記事のURLを指定してコードブロック部分だけを表示するスクリプトを作りました。
### 使用例
“`text:すべてのコードブロックを表示
$ python3 qiitacode.py https://qiita.com/shiracamus/items/556ff8d916712a9f7055
“`“`text:c言語部分だけ表示
$ python3 qiitacode.py https://qiita.com/shiracamus/items/556ff8d916712a9f7055 c
“`“`text:Python(py)部分だけ表示
$ python3 qiitacode.py https://qiita.com/shiracamus/items/556ff8d916712a9f7055 py
“`### プログラムコード
“`py:qiitacode.py
#!/usr/bin/env python3“””
download a Qiita article and p
[python] バイト数指定でテキスト切り出し
以前、python2系で作成していたテキストファイルの一部を切り出して別ファイルにしていた処理が、python3系で切り取りに使っていた len がバイト数じゃなくて文字数カウントになってしまったので修正が必要になったメモです。
“`python
text = “012345あいう67890”
charcode = ‘cp932′ # 文字コード指定
byte_text = text.encode(charcode) # 文字列エンコード
clip_text = byte_text[6:12].decode(charcode, errors=’ignore’) # バイト単位で切り取った文字をでコードで戻す
“`ちょっと面倒だけど、できました。
もっといい方法は無いのかしら。
[AtCoder]Pythonにおける配列のコピー
# 目的
pythonを使用すると、配列を代入した際に値が書き換わってしまい困ってしまうケースがあると思います。
そこで、どのような場合に値が書き換わるのか、どのように対処できるのかをまとめました。
# 環境
AtCoderでの使用を前提としているため、AtCoderのコードテストで実行しています。
言語は実行速度を考慮しPypy3(7.3.0)としています。
# 一次元配列
## 代入される例
~~~
A = [0,1,2]
B = A
B[0] = 3
print(A)
#[3, 1, 2]
~~~
上記の例では、BにAを代入するとBの要素を変更してもAの配列が書き換わります。
これはBへはAの配列のコピーでなく、Aの配列をアドレスごと代入しているからと考えられます。## 代入されない例
~~~
A = [0,1,2]
B = A[0]
B = 3
print(A)
#[0, 1, 2]
~~~
ここではBに配列ではなく、int型の値が代入されるため、Bの値を変更してもAの配列は変化しません。## 対処法
~~~
A = [0,1,2]
B = A.copy()
B[0]
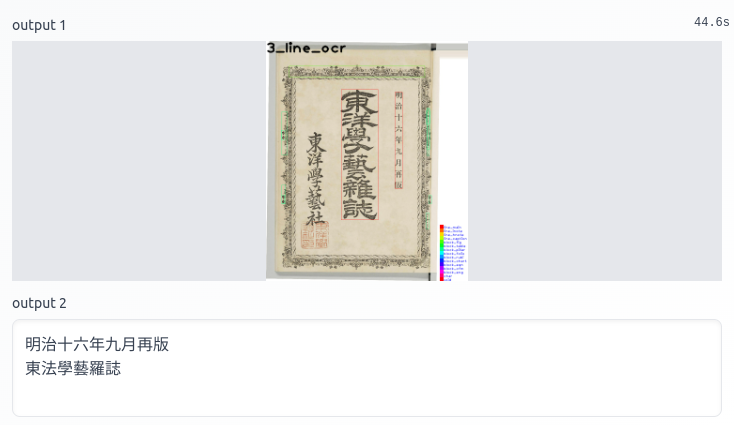
NDLOCRのWebアプリを作ってみた【Gradio】
https://huggingface.co/spaces/tomofi/NDLOCR
NDLOCRを試せるWebアプリ作ってみました。
“`python
import os
import torchprint(torch.__version__)
torch_ver, cuda_ver = torch.__version__.split(‘+’)
os.system(f’pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/{cuda_ver}/torch{torch_ver}/index.html –no-cache-dir’)
os.system(‘cd src/ndl_layout/mmdetection && python setu
Githubに100MB以上のファイルをプッシュする方法
# はじめに
– GitHubでは100MB以上のファイルをプッシュすると拒否され、50MB以上のファイルをプッシュすると警告される仕組みとなっています。
– 今回はGitHubに100MB以上のファイルをプッシュする方法を考えてみたいと思います。# Githubに100MB以上のファイルをプッシュする方法
– 100MB以上のファイルをそのままプッシュするとGithubに拒否されてしまうため、ファイルを分割してプッシュしようと思います。
– また、50 MBより大きいファイルを追加または更新しようとすると、Githubから警告が表示されるので、49MBでファイル分割しようと思います。
– 具体的には、ZIPファイルをbase64にエンコードして、49MBのテキストファイルに分割してプッシュします。
– 元のファイルに戻すときは、分割したテキストファイルのテキストを結合して、デコードすればZIPファイルに戻ります。# 実装
Pythonで実装したコードが以下です。### フォルダ構成
“`
ディレクトリ
├─main.py
├─setting.json
├─input
Apache AirflowのDAG設定値についてまとめてみる
前回Cloud Composerを利用して、BigQueryへのデータの取り込みについて記事を書きましたが、DAG実装の詳細(特に各パラメータの役割)については、記事が長くなりすぎるので割愛しました。なので今回から複数回に渡って、以下の内容を深堀りしていこうと思います。
– DAGの設定値について(今回分)
– テンプレート内で利用可能な変数について## DAGとオペレータについて
細々した話をする前に、まずはDAGとオペレータの概略からまとめてみました。
|構成要素|概要|
|—|—|
|オペレータ|処理を定義するための関数。クラウド操作毎に細かく用意されているため、自身がやりたい処理のオペレータの利用方法を調べる必要がある。前回BigQueryへのデータ取り込みで使用したオペレータは、「GoogleCloudStoragePrefixSensor」、「GoogleCloudStorageToBigQueryOperator」、「DummyOperator」です。|
|DAG|オペレータから定義された処理+処理同士の前後関係の情報をもった処理のグループのことです。|
DropboxAPIのAccessToken&RefreshToken備忘録
# 結論
DropboxAPIのAccessTokenは一定期間でリセットされアクセス出来なくなる。
毎回AccessTokenを発行しなおすのは面倒なので、RefreshTokenを発行し接続することで回避する。## AccessTokenの発行方法(一応)
https://www.dropbox.com/developers/
ここにアクセスし、**アプリを作成** or **右上のAppConsole**から選択
permissonから必要な権限を有効化し、ダッシュボードの“`setting/Oauth2/GenerateAccessToken“`で発行する。
### AccessTokenでの利用方法
“`
import dropboxdbx = dropbox.Dropbox(`
‘)
“`## RefreshTokenの発行方法
まずはauthorization_codeを取得する。(後で“`“`に入力する) ダッシュボードの“`setting“`にある**App key
【Pythonで作図】忙しい人のための Matplotlib【初心者向け】
# ✨Python って作図がカンタン!✨
**「Pythonで作図」**…。ネットにはたくさん記事があるけど、どれも**ややこし**くて**難しい**ですよね。
そんな方々のために、**手っ取り早く**て**分かりやすい**「Python 3分クッキング」をやっていこうと思います!# 0. 完成目標
これを作ります。
“`python:完成コード
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-100,100,0.1)
y = np.sin(x)/x
plt.plot(x,y)
plt.show()
“`
**結果**
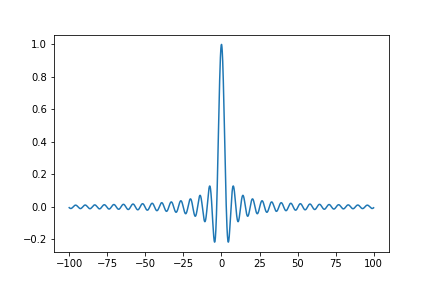では、始めます。
# 1. これをコピペ
“`python:【必須】おまじない(計算と作図に必要な道具を準備
データフレーム同士の結合(merge関数) について
「このデータは、数学のテストの結果で」
「このデータは、英語のテストの結果で」このようなデータフレームはまとめたいデータだと思います。
このようなデータを一つに結合させることができれば、情報がより分かりやすくなりますよね。
その時に用いる関数が`merge`関数ですこれはそれぞれのデータを横方向に結合させることができる関数です。
ちなみに今回の記事の範囲外になりますが、同じ種類のデータを結合させたいとき
つまり縦方向にデータを結合させたいときは、pandasライブラリにある`pandas.concat`メソッドです。では実際に、merge関数を使用していきましょう。
“`Python
import pandas as pd
import numpy as np
“`
“`Python
df01 = pd.DataFrame( {‘name’:[‘A’, ‘B’, ‘C’],
‘math’:[60, 70, 80]})
df01
“`“`
name math
0 A 60
1 B 70
2 C 80
“`“`
『Python2年生 スクレイピングのしくみ』で勉強中(その1)
## この記事について
『Python2年生 スクレイピングのしくみ』(以下、書籍)でPythonを学習する超初心者の記録です。
『Python1年生』は人工知能を題材に、Pythonの基本的な文法等を解説していましたが、
こちらの書籍ではスクレイピングということで、人工知能とは別の題材になっています。■ バックナンバー
– [『Python1年生』で勉強中(その1)](https://qiita.com/megrim_q/items/c1417f507e96c1fb7015)
– [『Python1年生』で勉強中(その2)](https://qiita.com/megrim_q/items/333be033e5b4637d0eed)
– [『Python1年生』で勉強中(その3)](https://qiita.com/megrim_q/items/904f83c6a7e8594b7212)## 実行環境
| OS・MW・ライブラリ | バージョンなど |
|:-:|:-:|
| OS | Windows 10 Pro 21H2 19044.1645 |
| Pytho
requestsで非同期Asyncリクエスト【HTTPX】
https://colab.research.google.com/drive/1O7v-OLPpb0yG56n1PjkvuBDH0HsYl3-8?usp=sharing
# requestsをインストール
“`bash
pip install httpx
“`# requestsをインポート
150個のリクエストを作成します。
“`python
import httpx as requests
from asyncio import run, gatherurls = [f”https://pokeapi.co/api/v2/pokemon/{n}” for n in range(1, 151)]
“`# 同期(Sync)リクエスト 処理時間8.8秒
“`python
def sync_func():
print([requests.get(u) for u in urls])sync_func()
“`:
L.append(teacher)
return Lprint(dive_into_code(‘Noro’))
print(dive_into_code(‘Nakao’))
print(dive_into_code(‘Miyashita’))
“`
***正解***がこちら。
“`console:console
[‘Noro’]
[‘Noro’, ‘Nakao’]
[‘Noro’, ‘Nakao’, ‘Miyashita’]
“`
こ
【Django】インストール方法
## インストール方法
インストール方法は、ディストリビューション固有のパッケージをインストールするのか、 最新の公式リリースをダウンロードするのか、あるいは最新の開発版を取得するのかに よって、若干異なります。
以下はpipにてインストールする方法になります。1. pip で公式リリースをインストールする。
これは Django をインストールするのにお勧めの方法です。
2. pip をインストールします。最も簡単なのは、スタンドアロンの pip インストーラを使うことです。ディストリビューションに既に pip がインストールされている場合、それが古ければ 更新する必要があるかもしれません。古い場合、インストールが失敗します。
3. 仮想環境の作成と起動が完了したら、コマンドを入力します。“`
$ python -m pip install Django
Collecting Django
Downloading Django-4.0.4-py3-none-any.whl (8.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
競馬予想AI 勉強メモ#1 pandas DataFrameの特定行の抽出方法
競馬予想AI作成中にpandasのDataFrameの特定行を抽出したくなった際のメモです。
(参照:https://www.yutaka-note.com/entry/pandas_access#DataFrame%E3%81%AE%E8%A1%8C%E5%88%97%E5%80%A4%E3%82%92%E6%8A%BD%E5%87%BA%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95)特定の行を指定|df.loc[インデックス名, : ] または df.loc[インデックス名]
以上。これだけ!!
discord、どう動いてる?
# 動機
普段使用しているpycordはどのようにして動いているのか気になったので。# 仕組み
ベース:
APIのバージョンは8以上が推奨されています。[参考](https://discord.com/developers/docs/reference#api-versioning)**下準備**
“`python
from pprint import pprintAPI_VERSION = 9
BASE_URL = “https://discord.com/api/v{}”.format(API_VERSION)TOKEN = “YOUR_BOT_TOKEN”
HEADER = {“Authorization”: “Bot {}”.format(TOKEN)}APP_ID = 000000000000000000 # BotのID
GUILD_ID = 111111111111111111 # 対象とするサーバーのID
CHANNEL_ID = 222222222222222222 # 対象とするチャンネルのID
“`
—
# [メッセージ送信](ht
FastAPI: SQLAlchemy で MariaDB を使う (その 4)
こちらのプログラムを改造しました。
[FastAPI: SQLAlchemy で MariaDB を使う (その 3)](https://qiita.com/ekzemplaro/items/d0c6321080ee14e2de36)
>API に PUT を追加## プログラム ##
フォルダー構造
“`text
$ tree
.
├── __init__.py
├── crud.py 変更
├── database.py
├── main.py 変更
├── models.py
└── schemas.py 変更
“`“`py:crud.py
from sqlalchemy.orm import Session
import sys
from datetime import datetimefrom . import models, schemas
#
def get_city(db: Session, city_id: str):
return db.query(models.City).filter(models.Ci
Pythonで作るスネークゲーム
## はじめに
今回はPythonで、ヘビ状のオブジェクトにエサを食べさせて成長させる「スネークゲーム」を作ってみたいと思います。前回の記事で取り上げたPing Pongゲームに引き続き、Python初心者向けのゲームの一つです。Youtubeなど、ネットに多く教材がありますので、ぜひ参考にしてみてください。
今回はpygameという、Pythonでゲーム作成をするときに便利なライブラリを使用しています。
今回のソースはこちらの動画に基づいて作成しています。
[“How to build SNAKE in Python!”](https://www.youtube.com/watch?v=9bBgyOkoBQ0)## ゲーム概要と必要なオブジェクト及び処理
そもそもスネークゲームとはどのようなゲームでしょうか。こちらが今回作るスネークゲームの外観です。:
results = await get()
return results
“`次の様にawaitを使わない場合、
“`sample.py
async def edit():
print(get())
# > RuntimeWarning: coroutine ‘SampleController.get’ was never awaited
“`「コルーチンがawaitされていない」と。
**コルーチンを単に呼び出しただけでは実行出来ず、コルーチンオブジェクトが返るため**コルーチンとは?
# コルーチン
async/await 構文で宣言された関数はコルーチンと呼ば
JPXのデータを用いてデータ分析をしていく【データ読み込みからデータの中身理解】(Kaggleコンペ)
みなさんこんにちは。
現在、Pythonを勉強している社会人3年目の転職希望者です。
プログラミングスクールに通い、様々な分析手法を学びました。これからは、更に実践で活躍できるようになる為、自らデータを探し、データの分析のみならず基礎から学んでいこうと考えています。
このブログが様々な人の役に立てれば光栄に思います。さて、本題ですが今回使用するデータセットは下記のとおりです
https://www.kaggle.com/competitions/jpx-tokyo-stock-exchange-prediction
JPXが主催のコンペディションになっています。ここで、JPXとは何か簡単に説明していきます。
日本取引所グループ(JPX)は、世界最大級の証券取引所である東京証券取引所(TSE)と、デリバティブ取引所である大阪取引所(OSE)および東京商品取引所(TOCOM)を運営する持株会社です。
今回はこのコンペディションのデータを用いて、データの読み込みからデータ手法まで幅広く学んでいきたいと思います。
1.データの読み込み
与えられたデータがかなり多いですが、まずは一
boto3を使って、さくらのオブジェクトストレージにファイルをアップしてみる
# はじめに
最近になって、さくらのクラウドを触り始めた初心者(筆者)が四苦八苦しながら
オブジェクトストレージにファイルをアップロードしてみたのが前回の内容。https://qiita.com/nkmr_RL/items/9b15c2eaddb97a830887
上記のアップロードができるようになったら
**「なんかPythonから操作できる気がしてきたわ…」**
と思い立ったので、Pythonから操作してみるのが今回の内容。あと、先に言っておきますが、**AWS公式ライブラリboto3を使った方法**になるので
**さくらインターネットの公式サポート対象外のやり方**です。(多分)だから、1年後には使えなくなっているかもしれない。(バナージ…悲しいね)
# 予想される検索ワード
以下、この記事を求めているであろう方が入力しそうな
(というか実際に私が必死で検索した)検索ワードです。さくらのクラウド, オブジェクトストレージ, アップロード方法, Python, boto3
# 実行環境
– ubuntu 18.04(Dockerで構築)
– Pytho




