
- 1. ABC250 A~D問題 ものすごく丁寧でわかりやすい解説 python 灰色~茶色コーダー向け #AtCoder
- 2. 【Python】配列の順序を保持しながら集合演算(和集合、差集合、積集合)を行いたい
- 3. ざっくり分かるpytestのfixture
- 4. Foobar Google Challengeに挑戦してみた
- 5. NFCを用いて入室管理システムの作成備忘録Ver1.0
- 6. SPSS Modeler ノードリファレンス 7-4 拡張のエクスポート
- 7. SPSS Modeler ノードリファレンス 6-8 拡張の出力
- 8. SPSS Modeler ノードリファレンス 5-13 拡張モデル
- 9. SPSS Modeler ノードリファレンス 2-11 拡張の変換
- 10. SPSS Modeler ノードリファレンス 1-7 拡張のインポート
- 11. 【Python】 MQTTチャットアプリ
- 12. Python Excelより値を取得し、メールテンプレートを作成する
- 13. 「テキストアナリティクスの基礎と実践」をpythonで読む6 アソシエーション分析による共起分析
- 14. Python で Datastore SDK を利用する
- 15. 【Python】PyScriptで、HTMLにPythonを書き込む
- 16. 【スクレイピング】Coincheckの過去レートをCSV形式で取得する
- 17. Foliumを使って国土数値情報を地図上に表示する
- 18. Python を Numba で高速化するときの間違えやすいポイントまとめ
- 19. numpyとpandasの役立つ処理まとめ
- 20. Irisで前処理を試してみる。 ~標準化、無相関化、白色化~
ABC250 A~D問題 ものすごく丁寧でわかりやすい解説 python 灰色~茶色コーダー向け #AtCoder
ABC250(AtCoder Beginner Contest 250) A~D問題の解説記事です。
灰色~茶色コーダーの方向けに解説しています。更新時はツイッターにて通知します。
Tweets by AtCoder4その他のABC解説、動画などは以下です。
https://qiita.com/sano192/items/54accd04df62242b70f0
# A – Adjacent Squares
https://atcoder.jp/contests/abc250/tasks/abc250_a
辺でつながっているというのは要するに(R,C)の上下左右のマスの意味です。
それぞれのマスの座標は以下のようになります。
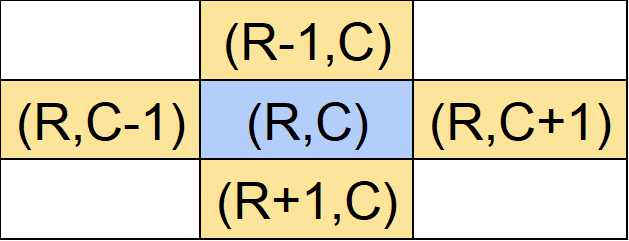それぞれのマスがマス目の中にあるか確認します。
例えばH=10,W=10で
【Python】配列の順序を保持しながら集合演算(和集合、差集合、積集合)を行いたい
# はじめに
私ごとですが、最近RubyのプログラムをPythonに書き換える機会がありました。
その時、配列に対して集合演算する必要があり、Pythonでこの方法を調べるとlistを一度setに変換して集合演算を行い、再度listに変換し直す記事が多数でした。
setは便利ですし、大半の場合はこの方法で十分だと思いますが、わたしの場合はもとのlistの順序を保持したかったので、setを使うことはできませんでした。よって本記事には、Pythonでsetを使わずに配列の順序を保持しながら集合演算を行う方法を残したいと思います。
# 目指す動作(Rubyの集合演算)
## 和集合「|」
“`ruby
[2, 1, 1, 7, 5, 5] | [3, 3, 5, 7, 9]
# => [2, 1, 7, 5, 3, 9]
“`
重複している要素は取り除かれます。
左辺を基準に順番が保持されています。
## 差集合「-」
“`ruby
[2, 1, 1, 7, 5, 5] – [3, 3, 5, 7, 9]
# => [2, 1,
ざっくり分かるpytestのfixture
## pytestにおけるfixtureとは
– テストの事前処理、事後処理を記載できるpytestの機能です。
– SetUp(事前処理), TearDown(事後処理)を1つの関数で書けます。
– `setup_class`, `setup_function`のように、スコープごとに違う関数を呼ぶ必要がありません。
– fixtureからfixtureを呼び出すことができ、処理を階層的に記述できます。## SetUp, TearDownじゃダメなの?
– ダメかと言われるとダメじゃありません。チーム内でスタイルが統一されている方が大事です。
– 機能面だけで言うと、pytestにおいてはfixtureを利用する方がリッチではあります。
– ブラウザ操作自動化ツールである[Playwright for Python](https://playwright.dev/python/)はfixtureを利用しています。
– 上記を採用する場合、可読性と保守性の観点からfixtureに統一することを勧めます。## 基本的な構文
“`python
import pyte
Foobar Google Challengeに挑戦してみた
`foobar google challenge`の招待が届いたので挑戦してみた
`challenge1`の回答例について記載します
# 問題
“`:問題
Write a function called solution(data, n) that takes in a list of less than 100 integers and a
number n, and returns that same list but with all of the numbers that occur more than n times
removed entirely. The returned list should retain the same ordering as the original list – you
don’t want to mix up those carefully-planned shift rotations! For instance, if data was [5, 10,
15, 10, 7] and n was 1, solution(data,
NFCを用いて入室管理システムの作成備忘録Ver1.0
# システム作成の経緯
先日メリカリを閲覧していたところ、「Sony Corporation©︎ RC-S330」を格安で入手することができました。
そこで、NFCを用いて遊んでみようと思い入室管理システムの開発を行いました。
※今購入するのであれば、「Sony Corporation©︎ RC-S380S」が最新モデルなのでこちらを買うと良いと思います。# 開発環境
* OS : macOS Monterey12.2.1(Intel Mac)
* リーダ : Sony CorporationRC-S330
* 言語 : Python3.10.0
* DB : AWS RDS(MySQLを使用)# 搭載する機能の決定
入退室管理システムで必要な機能をまとめました。
1. 新規登録機能(ICカードの情報と名前等を登録する機能)
2. 削除機能(ユーザーの削除を行う機能)
3. 入退室記録(何時にどこに入退室したのか)まずはシンプルに基本機能である上記3点の機能を実装することとします。
# システム構成図 & システムフロー
1. 新規登録機能のシステムフロ
SPSS Modeler ノードリファレンス 7-4 拡張のエクスポート
# 7-4 拡張のエクスポート[エクスポートタブ]
## 1.ノードの目的(拡張ノード共通)
SPSS ModelerにないアルゴリズムなどをPythonまたはRから呼び出して連携する。
*ノードリファレンスの拡張ノード5つの記事は全て共通です。
## 2.解説動画(拡張ノード共通)
#### Rによる地図連携(115秒)
