
- 1. ラズパイでPythonのvenvを使いつつCronで定期的に自動実行する方法
- 2. フェルマーの二平方和定理の応用
- 3. Raspberry Pi 3B+ に Minicondaを導入
- 4. Pythonで例外処理を関数化
- 5. 【Python】NetworkXで辺の太さを指定するとき、add_edgeとwidthの順番でハマった話
- 6. 【Pyrhon演算処理】自然指数関数(Natural Exponential Function)とは何か?
- 7. python-email-validator で example.com アドレスが拒否される理由と対処法
- 8. PyScriptの惜しいところ
- 9. 重回帰分析(単回帰分析)
- 10. 【Python】対話型シェルの使用中にhelp()から抜け出す方法
- 11. AutoVizを使用して一行EDA
- 12. 一元配置分散分析
- 13. VOSKを使って日本語でストリームでローカル音声認識する
- 14. Python学習記録_9日目.回帰分析・評価指標・ランダムフォレスト
- 15. 三角裁定取引・Triangular arbitrage(三角アービトラージ)の仮想通貨(暗号資産)アルゴリズム取引をPython×CCXTで製作
- 16. pytorchで作ったネットワークの可視化
- 17. edfファイルを上書きする
- 18. Pythonのテスト実行を並列化する
- 19. Pythonのリストのメソッについて
- 20. Ubuntu導入後~GPU(CUDA等)+PyTorchの環境構築【簡単】メモ
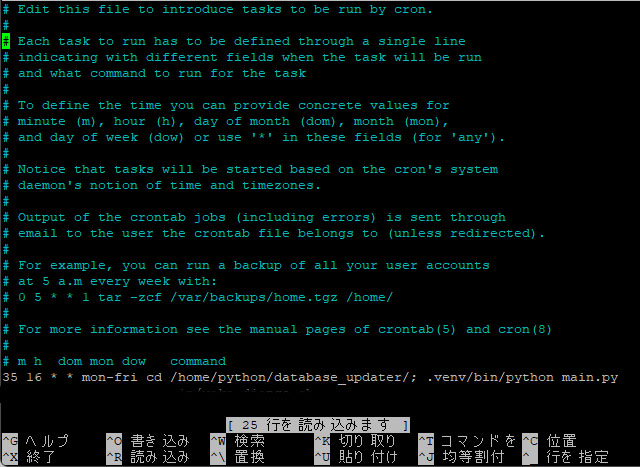
ラズパイでPythonのvenvを使いつつCronで定期的に自動実行する方法
# Pythonスクリプトをvenv環境下で起動する、Crontab設定を記述してみた。
Windows上で開発していたプログラムをRaspberryPiに移植したときに、日々手動で実行するのもめんどくさいし、実行するのを忘れたりすることも多々あったので、自動化するべと意気込んでやってみた。# 実際に行った作業
まずはcrontab -e を実行。

cron上で、まずカレントディレクトリを移動して、仮想環境の.venv/binにあるpythonでpyファイルを起動するという感じ。
※*
フェルマーの二平方和定理の応用
以下のような問題を考えます
**【問題】$x^2+y^2=1105$を満たす自然数$(x,y)$の組をすべて求めよ**
### フェルマーの二平方和定理
[フェルマーの二平方和定理(高校数学の美しい物語)](https://manabitimes.jp/math/844)によると
“`math
奇素数 \; p=x^{2}+y^{2} (x,y \in \mathbb{Z})と表せる \\ \Leftrightarrow p\equiv 1\pmod {4} \dots (1) \\
“`### ブラーマグプタ-フィボナッチ恒等式(BF恒等式)
以下の式が成り立つので$x^2+y^2$で表される2つの数$m,n$があるときその積$m \times n$も$x^2+y^2$で表される。しかもその$(x,y)$のペアの数は2倍になる。“`math
(a^2 +b^2)(c^2+d^2) \\
=(ac−bd)^2+(ad+bc)^2 \\
=(ac+bd)^2+(ad−bc)^2 \dots (2) \\
“`### 右辺の素因数分解
【
Raspberry Pi 3B+ に Minicondaを導入
# 0.Intro
自宅にRaspberryでソフトウェアRaidで常時稼働させているのでなんだったらスクレイピング走らせておくのもいいかなぁと思い導入することにしました。
やはりconda環境を入れたいと思います。当方の環境は
“`
pi@raspberrypi:~ $ cat /proc/device-tree/model
Raspberry Pi 3 Model B Plus Rev 1.3pi@raspberrypi:~ $
pi@raspberrypi:~ $ uname -a
Linux raspberrypi 5.10.103-v8+ #1530 SMP PREEMPT Tue Mar 8 13:06:35 GMT 2022 aarch64 GNU/Linux
“`# 1.試行錯誤
ラズパイでcondaで検索すると
[Berry Conda](https://github.com/jjhelmus/berryconda)
が出てきます。インストール試みましたが、
“`
cannot execute native linux-armv7l binary
`
Pythonで例外処理を関数化
## 背景
自作のスクレイピングツール、よく途中でコケて最初からやり直し、
になることが多いので、例外処理を追加したいと思い作成。
作成したところ思ったより汎用性が高いものができた気がするので、備忘も兼ねてメモ。## 関数
“` py
import sysdef try_func(func, *args):
print(f'{func}を試みます’)
try:
func(*args)
print(f'{func}が実行されました’)
except Exception as e:
print(e)
print(type(e))
print(‘実行中にエラーになりました’)
print(‘手動で継続する場合、手動で調整した後yを、中止する場合はn(y以外)を入力してください’)
flg = input(‘”y”or”n”:’)
if flg == ‘y’:
print(‘継続します’)
【Python】NetworkXで辺の太さを指定するとき、add_edgeとwidthの順番でハマった話
# 1. はじめに
下山輝昌・松田雄馬・三木孝行著『Python実践データ分析100本ノック』(第1版第10刷)をちょこちょこと進めていたところ、第6章ノック57をやっていて、NetworkXの文法でちょっとハマったので備忘録。ハマりポイントは、NetworkXでグラフを描画するときに、**各辺の線の太さを指定するには、設定されている辺の順番通りに太さの値が入ったリストを渡す**のですが、この**辺の順番と、指定したい太さのリストの順番ってどうやったら一致するの**?というところでした。
本記事では、NetworkXにおいて、設定された辺の順番についての文法理解と、ついでに辺の太さの指定方法について自分なりのコードを考えたので、記録に残しておきます。
もちろん太さの指定方法や順番の決め方は上記テキストを進めている人はテキスト通りでもよいですし、今回は自分の感覚に合ったコードを書いてみたいなとも思ったので、文法の整理をしながらまとめてみます。# 2. 前提
今回は、上記書籍がjupyter notebookを使って学習を進めていくことを前提としていたので、本記事でもこれに倣って
【Pyrhon演算処理】自然指数関数(Natural Exponential Function)とは何か?
# 自然指数関数(Natural Exponential Function)の場合
実数を定義域(Domain)とする自然指数関数(Natural Exponential Function)
“`math
exp(x)’=exp(x)\\
\int exp(x) dx= exp(x)
“`[指数関数の学び方](https://www.sit.ac.jp/lsc/webtext/Satoh’s_Math/Guide_ExponentialLogarithm.html)
>指数関数においては、一点で微分可能性さえわかれば、全ての指数関数の全ての点が微分可能となります。実際に試してみましょう。**指数関数**(Exponential Function)
$y=a^x(a=0.1≦a≦4)$と接点(0,1)で接する**接線**(Tangent)$y=\log(a) x+1$をグラフ化してみます。 のバージョンを上げたところ、 test で使用していた example.com アドレスが `EmailNotValidError` で拒否されました。(確認時、python-email-validator は 1.2.1)
example.com を含む諸々を拒否する経緯と対処法は以下に記載がありました。
https://github.com/JoshData/python-email-validator#test-addresses
https://github.com/JoshData/python-email-validator/issues/78
PyScriptの惜しいところ
# 開発と執筆の動機
* 某気圧予測アプリは無料版では36時間後までの気圧予報しかできない、そして広告が多い
* [OpenWeatherMap](https://openweathermap.org/ “OpenWeatherMap”)は海外サイトにも関わらず、無料版でも日本の都市の3時間ごと5日間分の天気予報データが得られる(データ取得制限はある)
* OpenWeatherMapはAPIも用意されているので、これを利用して自分用に3時間ごと5日間分の気温予測と気圧予測がしたかった
* Qiitaに投稿したのはPyScriptのAlpha版ではこういった不便さがあったよという備忘録のため# 想定していた開発の大まかな流れ
1. APIキーの取得などの下準備
2. PyScriptでAPIを叩き、json形式でデータを取得
3. 引き続きPyScriptでデータを整形し、matplotlibでグラフを描画
4. 出力されたグラフをHTML+CSSでいい感じに配置してブラウザから見られるようにする→Step.2で失敗
# 原因
なんとPyScriptで外部ページから情報を取得
重回帰分析(単回帰分析)
# 重回帰分析(単回帰分析)
テストデータ
“`python
import pandas as pddf5 = pd.DataFrame({
‘x1’: [2, 2, 3, 1, 2, 3, 2, 2, 2, 3, 2, 2, 1, 3, 2, 2, 1, 2, 1, 1],
‘x2’: [2, 2, 3, 2, 2, 1, 2, 3, 2, 3, 2, 1, 3, 2, 2, 1, 1, 3, 2, 1],
‘y’: [17, 20, 24, 15, 20, 19, 20, 22, 20, 26, 24, 14, 22, 23, 23, 19, 13, 27, 17, 13]})
“`## 1. sklern.linear_model.LinearRegression による分析
“`python
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
X = df5.drop(‘y’, axis=1)
y = df5[‘y’]
lr = lr.fit(X
【Python】対話型シェルの使用中にhelp()から抜け出す方法
こんにちは、okoniです:rocket:
最近はJavaScript(React)の勉強してます:pencil2:今回は、python講座(入門編)で困った
対話型シェルの使用中に、help()からの抜け出す方法についてです。# 対話型シェル
pythonには対話型シェルというモードがあります。
文字通り、ターミナルにてpythonと対話するようにプログラミングすることができます。# 解決方法
結論ですが、キーボードのQを押すと一瞬で抜けられます。
※この方法以外にもあれば教えて下さい:bow_tone1:# まとめ
自分もググっただけで恐縮ですが、
アウトプットの第一歩だと思い投稿に至りました。お一人にでもお役に立てれば御の字です。
それでは、また:metal:
AutoVizを使用して一行EDA
## AutoVizとは
AutoVizは、The Kaggle Bookから以下のように紹介されている。
“`
もしあなたが怠け者だと感じたり、
どこからどのように始めたらよいかわからない場合、
最初は自動化された戦略に頼るのも一案です。
例えば、人気のあるラピッドEDAフリーウェアのツールであるAutoViz
“`条件にフィットしていると感じたので早速使用してみる。
## 使用方法
使用方法はとても簡単で、以下のようにコード一行で済ませる。
“`python
pip install autovizfrom autoviz.AutoViz_Class import AutoViz_Class
%matplotlib inlineautoviz = AutoViz_Class().AutoViz(“/kaggle/input/tabular-playground-series-may-2022/train.csv”)
“`出力できるものは以下となる。
* カラム間の関係性を表す散布図
* 各カラムのヒストグラム、箱ひげ図、正規確率プロット
* 連続値
一元配置分散分析
# 一元配置分散分析
– 帰無仮説 $H_0$:「各群の母平均値はすべて等しい」
– 対立仮説 $H_1$:「各群の母平均値はすべて等しいわけではない」
– 有意水準 $\alpha$ で検定を行う
– 独立2標本の場合以外では,片側検定は定義できない独立二標本の平均値の差の検定で Welch の方法を取り上げていても,独立 $k$ 標本($k \geqq 3$) の場合の Welch の方法を取り上げていないサイトや教科書も数多い。
検定の多重性の問題も考えれば,「各群の分散が等しい」と仮定する方法を採用する意義はほとんどない。更にひどい話だが,Julia の `OneWayANOVATest()` は,各群のサンプルサイズが等しくないときには誤った答えを出すというバグがあり,このバグは 2021/08/02 に報告されているにも関わらず,2022/05/13 現在でも未だに修正されていない。
## 1. 各群の分散が等しいと仮定する場合
群の数を $k$,全ケース数を $n$,各群のケース数を $n_j$,全体の平均値を $\bar{X}$,第 $j$ 群における平均
VOSKを使って日本語でストリームでローカル音声認識する
# VOSK
Kaldiがベースの完全ローカルで動作する音声認識ツールキット
日本語モデルが用意されてるしマイクでのストリーム認識もできる!!
こういうの待ってた。https://alphacephei.com/vosk/
# Pythonで使ってみる
## 試した環境
– Windows 10
– python 3.9.6
– pip 21.1.3## インストール
pip で一撃で入る
ただしpoetry環境だとエラーが出てインストールできなかった。
Python標準のvenv環境からpipコマンドにてインストールした“`
pip install vosk
“`## モデルの準備
https://alphacephei.com/vosk/models
↑ここからJapaneseのものをダウンロードする。
2022/05/13時点での最新は**vosk-model-small-ja-0.22**# サンプルプログラムの入手
ここからクローンhttps://github.com/alphacep/vosk-api
“`
git clone
Python学習記録_9日目.回帰分析・評価指標・ランダムフォレスト
# 元記事
[Python学習記録_プログラミングガチ初心者がKaggle参加を目指す日記](https://qiita.com/noway6064/items/14ab494dc65d3040f733)
9日目です。なんやかんや最終日まで来ました。
ちょっと色々詰め込みすぎた気もしますがとりあえずやっていこうと思います。### CRISP-DM入門 20m
##### CRISP-DMとは
>CRISP-DM(CRoss-Industry Standard Process for Data Mining)は、データ分析プロジェクトのためのプロセスモデルです。
CRISP-DMでは、下のようなプロセスでデータ解析が行われます。
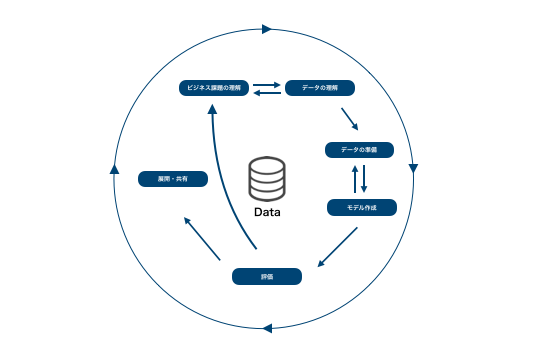
>プロセスに矢印が引かれ、円形のプロセスマップからもわかる通り、データ解析の分野では必要に応じて、処理を戻ってやり直
三角裁定取引・Triangular arbitrage(三角アービトラージ)の仮想通貨(暗号資産)アルゴリズム取引をPython×CCXTで製作
三角裁定取引、Triangular arbitrage(三角アービトラージ)とは、3つ以上の通貨間で売り買いを行い、最初に売った通貨が最終的に最初に売った通貨を増やす形で買い戻すことを目的とする取引のこと。通貨を増やせるタイミングが発生してから取引を開始できるので損失のリスクが低く、収益を上げることができる手法です。
但し、低リスクで収益を得ることが出来るメリットの反面、大勝ができるような取引手法ではありません。

# Python × CCXTによるアルゴリズム取引

“`
edfファイルを上書きする
# はじめに
pyedflibの使い方やedfファイルの読み込み方については既に@tchkwkzkさんの記事があるためそちらを参照ください。https://qiita.com/tchkwkzk/items/0e4e6cb1e29436c843c9
# EDFファイルの上書き
EDFファイルに書き込むこと自体は`pyedflib.EdfWriter`で可能ですが、EdfWriterは元のファイルを初期化してから書き込むため上書きできません。
対策としてedfファイルを複製し、複製したファイルに上書きします。“`python
import pyedflib
#—————–
def get_all_signals(edf:pyedflib.EdfReader):
“””
edfファイルから全チャンネルの波形を取得して返します。
“””
ewavs = []
for idx,_ in enumerate(edf.getSignalLabels()):
ewavs.append(edf.readSigna
Pythonのテスト実行を並列化する
## テストと並列化
ソフトウェアエンジニアリングを行う上で開発者テストは欠かせないものとなっています。テストはコードに対する素早いフィードバックを開発者に与え、高いアジリティを持った開発を支援します。また、CIによりテストを実行することで、コードのチェックインのたびにリグレッションがないかを検査することが容易になります。ところが開発を続けていくとやがてテストの数は増え、実行にかかる時間も増えていきます。テストの実行にあまりに時間がかかると、開発者へのフィードバックは遅くなり、テストから得られる恩恵も減ってしまいます。
この記事では並列化によるテスト実行の高速化を、Pythonのコードを例に紹介したいと思います。
## 並列化の実装
ここでは2段階の並列化を行います。1つ目は単一の計算インスタンス内におけるマルチプロセッシングによる並列化、2つ目は複数の計算インスタンスを使うことによる並列化です。### マルチプロセスによる並列化
#### テストの収集
まずはテストを集めるところからです。Test Discoveryによる方法と、Test Enumerationによる方
Pythonのリストのメソッについて
# リストのメソッド
“`
list.append()“`
Ubuntu導入後~GPU(CUDA等)+PyTorchの環境構築【簡単】メモ
# 目標,本記事の特徴
機械学習/深層学習用の環境を構築する。
PytorchがしっかりGPU上で動作するようにする。
なぜか他の記事より少ない手順でそれが実現できてしまった。# 手法
nvidiaドライバー導入
“`
sudo apt-get install ubuntu-drivers-common
ubuntu-drivers devices
sudo apt-get update
sudo ubuntu-drivers autoinstall
sudo reboot
“`
動作確認表が出力されればOK
“`
nvidia-smi
“`
anacondaに合わせてgitも一応入れておく
“`
sudo apt-get install git
wget https://repo.anaconda.com/archive/Anaconda3-2019.07-Linux-x86_64.sh
bash Anaconda3-2019.07-Linux-x86_64.sh
“`
仮想環境上にpytorchもろもろを導入(仮想じゃなくてもいいけど)
conda instal




