
- 1. FastAPI メモ
- 2. 夜間光データでコロナによる影響を調査してみた〜②東京大阪編〜
- 3. LightGBMのearly_stoppingの仕様が変わったので、使用法を調べてみた
- 4. 【Python】inspectを使った仮引数(Parameter)とキーワード引数(kwargs)の取得の仕方
- 5. 言語処理100本ノック俺の解答 第3章
- 6. Pythonでコラッツ予想を虱潰しにつぶしてみた
- 7. Python仮想環境の構築(pyenv + venv)
- 8. Toil削減取り組みしてみた ~マネージドサービス活用とスクラッチ開発でSREs体感
- 9. beautifulsoupで[特定の親要素]配下の[特定の子要素]だけを取得する方法
- 10. XGBoost(勾配ブースティング)で癌データの検証
- 11. ランダムフォレストでirisデータを可視化
- 12. Pythonでスピーカーからの音声出力をオフラインで文字起こし
- 13. 13億パラメータの GPT モデルを GCP Cloud Run で動かす
- 14. pythonでstrをdictへ変換する
- 15. numpyで公差と要素数から等差数列を生成する
- 16. Numbaでjitclassのコンパイル結果をキャッシュやAOT (事前) コンパイルできることを確認した
- 17. 「フェルマーの二平方和定理の応用」を参考に、wolframalphaとvbaでやってみた。
- 18. Pythonで一つのディレクトリに一気に複数フォルダを作成する方法
- 19. ラズパイで消費電力を取得する(3)完結
- 20. Pythonでつくる対話システム(その先)
FastAPI メモ
# FastAPIメモ
FastAPIの自分用メモです。## 複数ファイルのアップロード方法
– FastAPIで一つのファイルをアップロードする場合、 例として以下のように記述する。
“`
app = FastAPI()@app.post(“/api/”)
async def upload(
students:UploadFile = File(…)
):
“`– 呼び出し側から2つ以上のファイルをアップロードする場合
– 下記は名前がstudentsとteachersに分かれている。“`
curl -X POST -F students=@students.csv -F teachers=@teachers.csv http://localhost:8000/api
“`以下のように記述することでそれぞれ別に取得できる。
“`
app = FastAPI()@app.post(“/api/”)
async def upload(
students:UploadFile = File(…),
t
夜間光データでコロナによる影響を調査してみた〜②東京大阪編〜
## はじめに
[前回](https://qiita.com/oz_oz/items/69fa23ea37ec9a3b0b20)に引き続き、夜間光を用いてCOVID-19による影響を見てみたいと思います。
前回は日本全体のコロナによる影響の調査のため、日本全体のSum Of Light(SOL)の推移、各都道府県の平均輝度の増減を可視化しました。今回は東京と大阪に絞って、夜間光の推移を見てみます。
## 東京と大阪の夜間光の推移
東京と大阪の夜間光の推移を見ていきます。
今回は2014年から2021年の東京と大阪の夜間光の輝度平均の推移を見てみます。前回の日本全体のときには合計値であるSOLの推移を見ました。しかし合計値は面積が広いほど大きくなってしまい比較地域の面積が異なる場合には比較ができません。今回のように比較地域の面積が異なる場合は輝度平均が良さそうです。
まずはモジュールをインポートします。
“`python
import numpy as np
import pandas as pd
import warnings
warnings.filterwarning
LightGBMのearly_stoppingの仕様が変わったので、使用法を調べてみた
# LightGBMとearly_stopping
LightGBMは2022年現在、回帰問題において最も広く用いられている学習器の一つであり、**機械学習を学ぶ上で避けては通れない手法**と言えます。LightGBMの一機能である**early_stopping**は学習を効率化できる(詳細は[後述](https://qiita.com/c60evaporator/items/2b7a2820d575e212bcf4#early_stoppingとは))人気機能ですが、この度**使用方法に大きな変更があった**ようなので、**内容を記事にまとめたい**と思います
## 変更の概要
early_stoppingを使用するためには、元来は学習実行メソッド([`train()`](https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.train.html)または[`fit()`](https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMRegr
【Python】inspectを使った仮引数(Parameter)とキーワード引数(kwargs)の取得の仕方
# この記事の背景
– あるクラス(Class)がどのような仮引数(Parameter)やキーワード引数(kwargs)を取るか知りたい
– そしてその方法は(思っていたより)ややこしかった
– よって、筆者の備忘も兼ねて記事にします# 本記事の想定読者
– Pythonユーザー
– 外部ライブラリのクラスの仮引数、kwargsの一覧を利用したいケースがある
– できれば自動でその一覧を出力したい# 結論
– 標準ライブラリのinspectを使用する
– 仮引数の取得は`list(inspect.signature(target_class).parameters.keys())`
– kwargsの取得は`dir(target_class)`や`inspect.getmembers()`を使う“`python: コード例import inspect
from typing import Callablefrom matplotlib.figure import Figure
from matplotlib.axes._axes import Axesdef e
言語処理100本ノック俺の解答 第3章
[言語処理100本ノック第3章: UNIXコマンド](https://nlp100.github.io/ja/ch03.html)の俺の解答。[その他の章はこちら](https://qiita.com/sangoro/items/9bb6b5c39e756818cce2)。
# 20
Windows上でやっているので文字コードまわりでちょっと苦労した。
“`
import argparse
import gzip
import jsonparser = argparse.ArgumentParser()
parser.add_argument(‘-i’, help=”input gzipped JSON filename”)
parser.add_argument(‘-o’, help=”outpuf filename”)
args = parser.parse_args()f_o = open(args.o, “w”, encoding=”utf_8″, newline=’\n’)
f_i = gzip.open(args.i, ‘rt’, encoding=”utf_8
Pythonでコラッツ予想を虱潰しにつぶしてみた
# はじめに
Python初学者がPythonで遊んでみただけの記事です。
大した情報もないのでお急ぎの方はブラウザバックを推奨します。# コラッツ予想とは
数論の未解決問題のひとつやで。
任意の正の整数 n に対して、
n が偶数の場合、n を 2 で割る
n が奇数の場合、n に 3 をかけて 1 を足す
という操作を繰り返すと必ず1に到達する予想やで。
小学生でも理解できるほどシンプルな内容やけど、まだ未解決問題であるというってとこがおもろいな。## 具体的にはどうすんよ
nを10とすると、
10は偶数なので2で割ると5になる。
5は奇数なので3倍して1を足すと16になる。
16は偶数なので2で割ると8になる。
8は偶数なので2で割ると4になる。
4は偶数なので2で割ると2になる。
2は偶数なので2で割ると1になる。1に到達したので、n=10に対してこの予想は正しいと言えるやで。
これがすべての整数に対して正しいかを証明する必要があるやで。## Wikipediaより
> コンピュータを用いた計算により、2^268 までの初期値には反例がないことが確かめられている
Python仮想環境の構築(pyenv + venv)
# 始めに
Python仮想環境の構築に当たっての備忘録です.往々にして,プロジェクト毎に異なるバージョンのPythonを使わなければならない状況に遭遇します.例えば,プロジェクトAではパッケージX(Python 3.5 < ver < 3.7を要求)を使うが,プロジェクトBではパッケージY(Python 3.9 < verを要求)が必要,など.あるいは,Pythonのバージョンは同一でも良いがパッケージ毎のコンフリクトが発生することもあります. このような状況では,各プロジェクト用の[仮想環境](https://docs.python.org/3/tutorial/venv.html)を作ることで対応することができます. 以下は,主に[こちらの記事](https://qiita.com/Shiba-You/items/93c4e043e4c8dbc60cad)を参考に,同記事に則した内容です. # 環境 Microsoft Windows 10 MacOS,Linux,Ubuntuをご利用の場合は別記事をご覧ください.また,恐縮ながらAnacondaやDockerを使う方も
Toil削減取り組みしてみた ~マネージドサービス活用とスクラッチ開発でSREs体感
# はじめに
GW中の肩慣らしとしてこんな感じなものを作ってみた。
ちなみにGW中と言っといてつまずいたポイントがあり結果としてGW明けに投稿となってしまった。。
トラシューも含めてまとめてみたが長くなったのでお時間ある方はぜひ目的と得られるスキルは下記の通り
__目的__
業務でJIRAを利用しているが、セキュリティ観点から定期的なパスワード変更が必要であり、地味に面倒くさくなっている。(地味にがポイント)
また5月からスポット案件として久々にコーディングする機会をいただいたため久々にと言うことでPythonで色々スクラッチで開発と__スキル__
・今回はAWSのマネージドをフル活用すべく下記を利用した:::note info
・EventBridge
・EC2
・SNS
:::
*EC2に関しては賛否あるが結果としてEC2を利用して正解だった(後述記載)## 要件を詰める
簡単ではあるが、以下の要件とこうなったらいいなみたいのをまずリスト化してみた。その要件に対して要件を満たす条件を当てはめてみた。
:::note warn
・JIRAを利用している
beautifulsoupで[特定の親要素]配下の[特定の子要素]だけを取得する方法
## やりたいこと
(備忘録を兼ねての内容なのであしからず)ターゲットとするhtmlから、繰り返される親要素(タグ)のうち、特定の「id」に合致するものを取得。
さらに特定の「class」に該当する子要素(タグ)を取得したい。
※「id」、「class」と記載ありますが、あくまで今回やりたかったケースなので、他の組み合わせも可能## やったこと
beautifulsoupのfindメソッドを連結させることで対応できました。簡単にいえば
find(親要素).find(子要素)
ですね。“`python:
from selenium import webdriver
from bs4 import BeautifulSoup
import rebrowser = webdriver.Chrome((r’C:\Users\[ユーザ名]\chromedriver.exe’)
browser.get([目的のURL])html = browser.page_source
soup = BeautifulSoup(html,’html.parser’)#子要素の名称
XGBoost(勾配ブースティング)で癌データの検証
“`
#覚書
# xgboostのimportのためにしたこと
# 1. cmakeのinstall(!pip3 install cmake)
# 2. pipを最新にする
# 今のバージョン確認(!pip3 –version)
# 最新に(!pip3 install –upgrade pip)
# 3. xgboostのinstall(pip install xgboost)
# なぜか!pip3だとimportエラーになった
#必要かわからないがやったこと(conda install libgcc)import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import xgboost as xgbfrom sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
x = dataset.data
t
ランダムフォレストでirisデータを可視化
特徴量重要度の産出までのコード備忘録として。
ハイパーパラメータのn_estimatorsはどうやら高いほどモデルの精度が上がる印象。実際irisではn_estimatorsが上がると特徴量重要度の1/2位が逆転する。“`
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris# データセット読み込み
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
x = iris.data
y = iris.target# 学習データとテストデータに分割
x_train, x_test, y_train, y_te
Pythonでスピーカーからの音声出力をオフラインで文字起こし
# 目次
[モチベーション](#モチベーション)
[デモ](#デモ)
[ニュースの文字起こし結果](#ニュースの文字起こし結果)
[動作環境](#動作環境)
[SoundCard](#soundcard)
[VOSK](#vosk)
[設計](#設計)
[実装](#実装)
[使い心地](#使い心地)
[上手く動かなかったところ](#上手く動かなかったところ)# モチベーション
Web会議などで長々と話されると、ついつい集中が切れてしまい聞き逃してしまうことが多々あります。そこで **「発言をすべて文字起こししてしまえば、聞き逃さないのではないか!」** と思い立ち、今回の取り組みを始めました。# デモ
VOICEVOXで出力した音声をオフラインで文字起こしします。
*画質は480p以上でないと、PowerShell(ターミナル)に出力される認識結果が見えづらいかもしれません。
[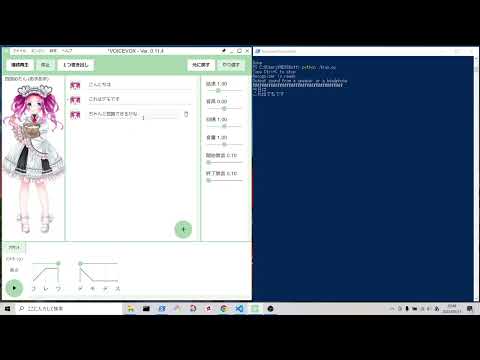](https://www.youtube.com/watch?v=8TGZBzI9u7E)# ニュ
13億パラメータの GPT モデルを GCP Cloud Run で動かす
サーバレスプラットフォームである **GCP Cloud Run** で、Transformersのモデルを動かしてみました。
https://cloud.google.com/run?hl=ja
Transformersの汎用言語モデルを動作させるにはそれなりのスペックが必要になりますが、サーバレスと言うとメモリ等のリソースに厳しい制限があり大きなモデルを動かすようなことは難しい印象です。ですがCloud Runは結構メモリを積める[^cloudrun-release-note]ので、実は普通に動かせてしまいます。
[^cloudrun-release-note]: 2022年4月22日のアップデートで、最大32GiBまでのメモリに対応した https://cloud.google.com/run/docs/release-notes#April_22_2022
## 環境
– Docker version 20.10.11, build dea9396
– Docker Compose version v2.2.1
– Google Cloud SDK 383.0.1
–
pythonでstrをdictへ変換する
astモジュールを使う
“`python
import aststr = “{‘Name’:’yuta’,’Country’:’Japan’}”
dict = ast.literal_eval(str)
print(dict[‘Name’])
print(dict[‘Country’])
“`“`
yuta / tmp python dict.py
yuta
Japan
“`
numpyで公差と要素数から等差数列を生成する
# 概要
`numpy` により始点の値 `start` と公差 `step` と要素数 `num` から等差数列を生成するには、下記のようにするとスマート。“`python
array = start + np.arange(num) * step
“`# `numpy` の等差数列を生成する関数
`numpy` には等差数列を生成する関数として、`numpy.arange` と `numpy.linspace` がある。https://numpy.org/doc/stable/reference/generated/numpy.arange.html
https://numpy.org/doc/stable/reference/generated/numpy.linspace.html
`numpy.arange` は、**始点の値** `start`、**終点の値** `stop`、**公差** `step` を指定する。
`numpy.linspace` は、**始点の値** `start`、**終点の値** `stop`、**要素数** `num` を指定
Numbaでjitclassのコンパイル結果をキャッシュやAOT (事前) コンパイルできることを確認した
## はじめに
Pythonを高速化するNumbaにはクラスをNumba化する`jitclass`があるが、jitclassはキャッシュやAOT (事前) コンパイルができないと思っていた。そんな中、jitclassもキャッシュできるという情報を発見。
https://github.com/numba/numba/issues/4830#issuecomment-862424725それどころかAOTもできるという情報も見つけた。
https://github.com/riantkb/typical90_python の L: 012、Q: 017なにやら、Numba化された関数から`@jitclass`したクラスを呼び出す構造にしておいて、元の関数をキャッシュもしくはAOTするとクラスの内容も保存されるとか。
本記事はjitclassのキャッシュ/AOTが可能か検証しただけだが、日本語どころか公式 ([jitclass](https://numba.readthedocs.io/en/stable/user/jitclass.html)、[AOT1](ht
「フェルマーの二平方和定理の応用」を参考に、wolframalphaとvbaでやってみた。
オリジナル
x^2+y^2=1105
https://qiita.com/masa0599/items/2bef1c9124cff23489ce
# wolfram alphaで
https://www.wolframalpha.com/input?i=1105+mod++4&lang=ja
https://www.wolframalpha.com/input?i=mod%281105%2C4%29
Result
1https://www.wolframalpha.com/input?i=x2%2By2%3D1105
Integer solutions
x = ± 33, y = ± 4
x = ± 32, y = ± 9
x = ± 31, y = ± 12
つづくhttps://www.wolframalpha.com/input?i=x2%2By2%3D1105+++positive+integer++&lang=ja
https://www.wolframalpha.com/input?i=x2%2By2%3D1105+over+the+positi
Pythonで一つのディレクトリに一気に複数フォルダを作成する方法
どうもエンジニアのirohasです。
今回はちょっとしたPythonの情報共有ができればと思い記事を投稿します。
内容としては、タイトルの通り、複数のフォルダを一気に作成しよう!というやつです。
ソースコードは以下になります。
“`python:make.py
import ospath_list = [“作成したいフォルダ名たちを格納”]
for dir in path_list:
if not os.path.exists(dir):
os.mkdir(dir)
“`まずは作成したいフォルダ名たちを格納したリストを作り、それをfor文で回し、
標準ライブラリであるosモジュールを使って要素ずつフォルダを作成していく形になります。
いくらでも作成可能なので是非みなさんも機会があれば使ってみてください!!!
ラズパイで消費電力を取得する(3)完結
# 目的
Raspberry Pi4とCTセンサーを用いて、消費電力を取得し、AWS IoT Core経由で、ElasticSearchに流し込むこと。
前回の記事は[こちら。](https://qiita.com/shof0322/items/a7b6217bedd05f7edd9f)# 方法
ざっくりの流れは以下の通りです。1. ハードウェアの構築
1. 消費電力取得プログラムの作成
1. AWS環境の構築### 3.AWS環境の構築
計測した消費電力を可視化するために、AWSのサービスをいくつか組み合わせて環境を構築します。
ざっくりいうと 「IoT Core → ElasticSearch → kibana」 という構成、フローとなっており、IoT Coreでエッジデバイスのセンシングデータを収集、ElasticSearchのエンジンを使ってデータベース化、ElasticSearchと紐付いたkibanaで可視化というイメージです。#### 3.1.IoT Coreの設定
##### 3.1.1.AWS IoT のエンドポイント確認1.AWS IoT Co
Pythonでつくる対話システム(その先)
# 類義語フリーの辞書
http://compling.hss.ntu.edu.sg/wnja/
## 参考ページ
https://qiita.com/pocket_kyoto/items/1e5d464b693a8b44eda5https://qiita.com/asakbiz/items/f82e95c13e5e9599306c
## pysqlite3 インストール
“`
pip install pysqlite3
“`## どんなテーブルがあるか
“`py
import sqlite3
conn = sqlite3.connect(“wnjpn.db”)cur = conn.execute(“select name from sqlite_master where type=’table'”)
for row in cur:
print(row)
“`### 結果
“`
(‘link_def’,)
(‘synset_def’,)
(‘synset_ex’,)
(‘synset’,)
(‘synlink’,)
(‘ancestor’,)




