
- 1. 卒業制作にてAIによる手書きひらがな文字認識ソフトを作った結果、、、(随時書き足し)
- 2. scipy.stats: 正規分布の検定(オムニバス検定) normaltest
- 3. numpy, list の append の速度の違い
- 4. Pythonで一様乱数の配列を生成するときの速度比較
- 5. scipy.stats: 幾何平均と調和平均 gmean, hmean
- 6. SOFAframework備忘録 Softrobotpluginを使うための事前準備
- 7. scipy.stats: 平均値まわりの第 r 次母積率 moment
- 8. scipy.stats: 記述統計 describe
- 9. scipy.stats: 尖度と歪度
- 10. Python Thin Driver for Oracle Database を試す
- 11. RubyでPythonのようにfor i in range(n)する
- 12. CORSハンズオン
- 13. tensorflow 2.9で画像認識をしてみた
- 14. PythonでMinecraftサーバーの独自コマンドを作る
- 15. Python基礎文法まとめ
- 16. Pythonでリストの要素を順に出力する簡潔な書き方を知った
- 17. PythonでもQiitaApiから自分の記事一覧を取得したい
- 18. M1 MacOSにtensorflowをinstall
- 19. SpeechRecognitionでの文字起こしを試してみた。
- 20. Python3 class書き方
卒業制作にてAIによる手書きひらがな文字認識ソフトを作った結果、、、(随時書き足し)
# 経緯と状況
初めまして。この5月にアメリカの4年制大学をComputer Science専攻で卒業した者です。
最後の春学期に卒業制作として何か作れと言われ、その直前の冬休みに独学で学んだDeep Learningに関連したものを作ろうとこのプロジェクトに挑みました。
学校の大きさはD2なのでそこまで大きくはないですが、その分クラスの規模が小さく、教授との距離がとても近く親身になってくれる学びやすい環境でした。が、全くもってAIについての知識はなく、勿論さらに細分化されたDeep Learningなんていうものは全く理解していませんでした。
そんなこんなで始めたこのプロジェクトですが、先駆者様達の残してくれた研究結果やブログ、コード等のおかげでなんとか形にすることができました。
この記事は、レゴブロックを組み合わせて一つのものを作るように、様々な記事を読みその情報を無理くり組み合わせて完成したものとその経緯をこの後に続く方々の役に立てばと思い、参考にさせていただいた記事のリンク先も併せて綴りたいと思います。※おそらく長くなるため、毎日少しずつ書いていきます。(毎日書くとは言って
scipy.stats: 正規分布の検定(オムニバス検定) normaltest
# 正規分布の検定(オムニバス検定) `normaltest`
データは正規分布からの標本といえるか?の検定。
$H_0$:母分布は正規分布である。
$H_1$:母分布は正規分布ではない。
以下の 2 論文に基づいたオムニバス検定である。
1. D’Agostino, R. B. (1971), “An omnibus test of normality for
moderate and large sample size”, Biometrika, 58, 341-348
2. D’Agostino, R. and Pearson, E. S. (1973), “Tests for departure from
normality”, Biometrika, 60, 613-622`normaltest(a, axis=0, nan_policy=’propagate’)`
## 1. 正規乱数について検定を行う
平均値=50,標準偏差=10 の正規乱数 25 個について検定を行う。
“`python
from sc
numpy, list の append の速度の違い
# やること
`numpy` と `python list` の `append` が結構速度が違うと見たので、実際に違いを計測してみる。
https://numpy.org/doc/stable/reference/generated/numpy.append.html
https://docs.python.org/ja/3/library/stdtypes.html#sequence-types-list-tuple-range
# コード
“`python
import numpy as np
import time
import matplotlib.pyplot as plt
import pandas as pddata_nums = np.logspace(1, 5, 5)
# [1.e+01 1.e+02 1.e+03 1.e+04 1.e+05]
data_nums = data_nums.astype(“int64”)df = pd.DataFrame(
index=range(len(data_nums)), columns=[
Pythonで一様乱数の配列を生成するときの速度比較
# やること
**一様乱数の配列を生成するための時間を比較する**
一様分布とは。
https://ja.wikipedia.org/wiki/%E4%B8%80%E6%A7%98%E5%88%86%E5%B8%83#:~:text=%E4%B8%80%E6%A7%98%E5%88%86%E5%B8%83%EF%BC%88%E3%81%84%E3%81%A1%E3%82%88%E3%81%86,%E8%B7%9D%E9%9B%A2%E3%81%AE%E5%88%86%E5%B8%83%E3%82%92%E6%8C%87%E3%81%99%E3%80%82
# 一様乱数を生成するために使用したライブラリ
– “`numpy.random.uniform“`
https://numpy.org/doc/stable/reference/random/generated/numpy.random.uniform.html
– “`numpy.random.default_rng“` (Numpy version1.17以降で推奨されているようです)
https
scipy.stats: 幾何平均と調和平均 gmean, hmean
# 1. 幾何平均 `gmean`
`gmean(a, axis=0, dtype=None, weights=None)`
“`python
from scipy.stats import gmean
x = [1.2, 3.1, 4.6, 2.2, 5.7]
gmean(x)
“`2.9263054868319522
`gmean` 関数を使わずに計算すると以下のようになる。
“`python
import numpy as np
np.exp(np.mean(np.log(x)))
“`2.9263054868319522
“`python
np.prod(x)**(1/len(x)) # 非推奨
“`2.9263054868319527
“`python
以下のようなテストデータ(平均値=50,標準偏差=10)で幾何平均を求めてみる。
“`“`python
from scipy.stats import norm
z = norm.rvs(loc=50, scale=
SOFAframework備忘録 Softrobotpluginを使うための事前準備
SOFA flameworkのSoftrobot pluginのチュートリアルでいろいろ一緒にビルドされたパッケージが配布されてるのでこれを始めるための環境設定について記す
https://project.inria.fr/softrobot/# 必要なもの
– 本体
– SOFA framework
– プラグイン
– Sofrrobot plugin
– ソフトロボットの制御に関するあれこれを楽にしてくれる
– STLIB(SOFA template library)
– SOFAを使うにあたってよく書くテンプレ文を省略するためのライブラリ
– SOFApython3
– SOFAで.pyが使えるようになるplugin
STLIBを使う場合必要になる—–
自前で設定の必要のある項目
– python3.8
(python3.7-3.9なら大丈夫そうだけど公式が3.8を推奨)
– numpy scipy
– 環境変数周り# 手順
### 1 pythonの準備
pyth
scipy.stats: 平均値まわりの第 r 次母積率 moment
# 平均値まわりの r 次母積率
$(x-\mu)^r$ の期待値のことである。$\nu_r’$ で表すことが多い。
離散変数のときは
$\nu_r’ = \sum(x-\mu)^r f(x)$
連続変数のときは
$\nu_r’ = \displaystyle \int_{-\infty}^{\infty} (x-\mu)^rf(x)dx$
`moment(a, moment=1, axis=0, nan_policy=’propagate’)`
“`python
from scipy.stats import moment
x = [1.2, 3.1, 4.6, 2.2, 5.7]
“`1次(デフォルト),2次,3次,4次の母積率(モーメント)
“`python
moment(x), moment(x, 2), moment(x, 3), moment(x, 4)
“`(0.0, 2.6184, 0.6126720000000052, 11.18588832)
“`python
moment(x, [0, 1, 2, 3,
scipy.stats: 記述統計 describe
# 記述統計 `describe`
サンプルサイズ,最小値,最大値,平均値,分散,歪度,尖度を求める。
`describe(a, axis=0, ddof=1, bias=True, nan_policy=’propagate’)`
“`python
from scipy.stats import describe
x = [1.2, 3.1, 4.6, 2.2, 5.7]
describe(x)
“`DescribeResult(nobs=5, minmax=(1.2, 5.7), mean=3.3599999999999994, variance=3.2729999999999997, skewness=0.14460191499270095, kurtosis=-1.3684571122281206)
表示される variance は,デフォルトで `ddof=1`, `numpy.var(x, ddof=1)` すなわち,不偏分散である。
“`python
np.var(x, ddof=1)
“`3.27299999
scipy.stats: 尖度と歪度
# 1. 尖度 `kurtosis`
`kurtosis(a, axis=0, fisher=True, bias=True, nan_policy=’propagate’)`
“`python
import numpy as np
from scipy.stats import kurtosis
x = [1.2, 3.1, 4.6, 2.2, 5.7]
“`## 1.1. Fisher の定義(正規分布のとき 0 になる)
“`python
kurtosis(x) # g2:後述
“`-1.3684571122281206
関数を使わずに計算すると以下のようになる。
“`python
from scipy.stats import zscore
np.mean(zscore(x)**4) – 3
“`-1.3684571122281206
## 1.2. Pearson の定義(正規分布のとき 3 になる) `fisher=False`
“`python
kurtosis(x, fisher=False)
“`
Python Thin Driver for Oracle Database を試す
## はじめに
こちらのサイト「[Open Source Python Thin Driver for Oracle Database](https://cjones-oracle.medium.com/open-source-python-thin-driver-for-oracle-database-e82aac7ecf5a) 」にてPython言語に対するOracle Database接続のThin Driverがリリースされたと発表がありましたので試してみました。Oracle Database への言語別アクセスドライバについては nakaie さんのこちらのまとめ記事「[Oracle Databaseへの言語別アクセスドライバのまとめ](https://qiita.com/nakaie/items/b6e699e720cdbd184705)」をご確認ください。
これまで Python から Oracle Databaseへアクセスするには cx_oracle というアクセスドライバが必要で、これにはOracle Instant Client といったOracle Cli
RubyでPythonのようにfor i in range(n)する
# 普通のコード
rubyの普通のrangeオブジェクトだとこうです
“`ruby
(0…n).each do |i|
puts i
end
“`
for文で書き直すと以下。
“`ruby
for i in 0…n
puts i
end
“`
# range関数
しかし、私はPythonのようにrangeを書きたいと思いました。
そこで、以下の関数を定義します。
“`ruby
def range(l, r=nil, s=nil)
return 0…l unless r
return l…r unless s
(l…r).step(s)
end
“`
`range(l)`のとき、`0…l`を返す。
`range(l, r)`のとき、`l…r`を返す。
`range(l, r, s)`のとき、`(l…r).step(s)`を返す。使い方は以下です。※コロンは不必要、endは必要です。
“`ruby
for i in range(10, 20, 2)
puts i
end
#=> 10
#=> 12
#=> 14
#=
CORSハンズオン
# CORSハンズオン
CORSを理解するためのハンズオンを書きました。
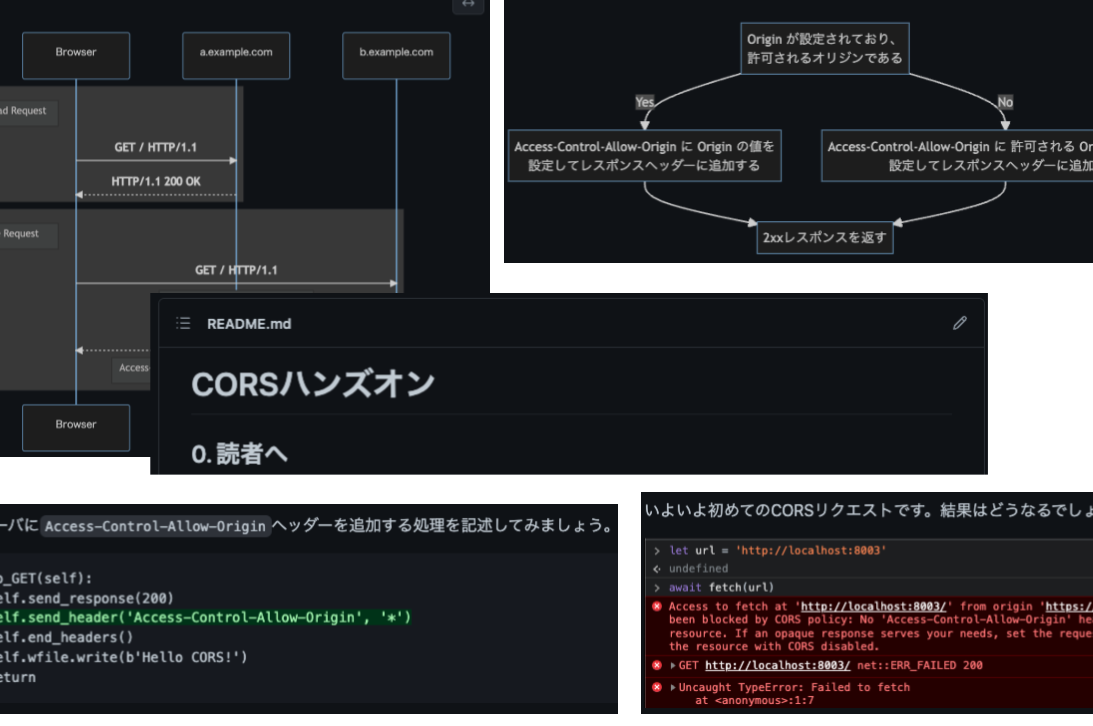
https://github.com/zeek0x/cors-handson
サーバ側のコードもいじりながら学べるようになっています。
CORSについて概要は知っているけれど、きちんと理解をしていない人向けになっています。
(調べた限りでは)インターネット上に同様の資料(サーバ側もいじりながらCORSを学習する資料)がなかったのが書いた理由です。
数十分で終わると思うので気軽にやってみてください。
tensorflow 2.9で画像認識をしてみた
# 目的
下記サイトを参考に画像認識を試してみました。[YOLOをpythonで動かして画像認識をしてみた](https://qiita.com/daiarg/items/a922c242af9bb76eb470)
私のPC環境では、いくつかエラーが発生しました。発生したエラーの回避方法をまとめ、画像認識の動作確認をします。
# 開発環境
Python version:3.9.7
OS: windows 10.0
Tensorflow:2.9# 環境構築
まず、必要なライブラリをインストールと、gitからデータと学習の重みファイルをダウンロードします。
[こちら](https://qiita.com/daiarg/items/a922c242af9bb76eb470)の環境構築と同じようにして設定してください。# 動作確認
上記リンクを使って、下記ファイルの動作を検証してみます。“`test.py
from darkflow.net.build import TFNet
import cv2options = {“model”: “cfg/yolo.cfg”,
PythonでMinecraftサーバーの独自コマンドを作る
## PythonでMinecraftのサーバーを……?
Minecraftのサーバーに自分で独自機能を実装したい!
そんな時は皆さんJavaでプラグインを書いたりするでしょう。
しかしJavaができない人はどうすれば……?
Javaを勉強して書けるようになれ!というのは至極まっとうでぐうの音も出ない正論です。
ですが手段はまだ残されています。Pythonを使うのです!## MCRconというライブラリ
PythonにはMCRconというライブラリがあります。(https://pypi.org/project/mcrcon/)
その名の通りMinecraftサーバーに実装されているRconという機能を手軽に利用できるようにするライブラリです。## MCRconを使う
MCRconを使えばサーバーの外からマインクラフトのサーバーにコマンドを簡単に送り込むことができます。
“`
with MCRcon(‘サーバーのアドレス’,’Rconのパスワード’,ポート) as mcr:
mcr.command(‘tellraw @a “hello world”‘)
Python基礎文法まとめ
## はじめに
本記事は学内の勉強会用に作成した資料をそのまま貼り付けたものとなります。
口頭での説明を前提として作成しているため、
一部内容が不十分であったり、正確ではない表現が含まれているものがあります。また、モジュールや例外処理など今後追加予定のものも多くあり、
現時点で内容を網羅しているわけではないことをご了承ください。## 目次 ##
1. 行構造
1. 式
1. 文
1. 節
1. コメント
2. 入出力
1. print関数
1. エスケープシーケンス
1. input関数
3. 算術演算
1. リテラル
1. 算術演算子
1. 文字列演算
4. 変数
1. 変数
1. 命名規則
1. 予約語
1. 代入演算子
1. 変数の演算
1. 複合演算子
5. オブジェクト
1. オブジェクト
1. ID
1. 型
6. 数値型
1. int
1. float
1. complex
7. シーケンス
Pythonでリストの要素を順に出力する簡潔な書き方を知った
pythonでリストの要素を一つずつ出力したいとき、そのままprintするとリストの書式?が出力されてしまう。
イテラブルな要素の先頭に*を付けるとfor文を使うことなく、出力できることを知った。“`python:
lst = [1,2,3,4]print(lst) # => [1, 2, 3, 4]
print(*lst) # => 1 2 3 4
“`半角空白で区切りたくない場合はprintの引数にsep=”を加える。
“`python
print(*lst, sep=”) # => 1234
“`for文を使わずコードが簡潔に書けて、かなり良いと思う。
なんで今まで知らなかったのだろう。
PythonでもQiitaApiから自分の記事一覧を取得したい
先日@nuxt/axiosを使ってQiitaApiから自分の記事一覧を取得しました
https://qiita.com/sYamaz/items/10c8c9db83e5dad62b90
ただ、この記事の最後に書いたようにスクリプトでコードを自動生成する方が目的に会っていると思っていたのでPythonでQiitaApiにアクセスしようと思います
### 環境
* Python 3.8.9
* `pip install requests`### スクリプト
`requests`パッケージを使用しApiから記事一覧を取得します。簡潔に書くと以下
“`python
import requests
import jsonresponse = requests.get(‘https://qiita.com/api/v2/items?query=user:sYamaz’)
items = json.loads(response.text)
for item in items:
# item(=記事)ごとの処理“`
この内容をもとにarticles.tsを
M1 MacOSにtensorflowをinstall
# M1 Macにtensorflowをインストール
## インストール失敗
普通にpipでインストールしようとすると失敗する。
“`shell
$ pip install tensorflowERROR: Could not find a version that satisfies the requirement tensorflow (from versions: none)
ERROR: No matching distribution found for tensorflow
“`## インストール方法
`tensorflow-macos`をインストールする。
“`shell
pip install tensorflow-macos
“`## 使用する
使用する際は`import tensorflow-macos`ではなく`import tensorflow`で良い。
`import tensorflow-macos`ではSyntaxErrorとなる。“`python
import tensorflow as tfinpu
SpeechRecognitionでの文字起こしを試してみた。
# 目的
SpeechRecognitionを使って、文字起こしをしてみたかったので、試してみました。# 開発環境
Python version:3.9.7
OS: windows 10.0
Anaconda:conda 4.11.0# ライブラリのインストール
SpeechRecognitionとpyaudioをインストールします。
SpeechRecognitionは、音声入力のライブラリ、pyaudioは、マイクロホンのからの入力に必要です。## SpeechRecognitionのインストール
SpeechRecognitionをインストールします。
“`pip install SpeechRecognition“`## pyaudioのインストール
pyaudioをインストールします。
“`pip install pyaudio“`すると、下記のようなエラーが発生しました。
“`terminal
Collecting pyaudio
Downloading PyAudio-0.2.11.tar.gz (37 kB)
Preparing
Python3 class書き方
## クラスの定義 3つのパターン
“`Python
class Enemy:
“`
“`Python
class Enemy():
“`
“`Python
class Enemy(object):
“`## クラスの初期化
呼び出された時、初めに実行される
引数にself必須
“`Python
class Enemy(object):# コンストラクタ
def __init__(self):
print(“初期化”)enemy1 = Enemy()
# 実行結果 ⇨ 初期化
“`### 何か値を保持させたい時
__init__に引数をつける
self.引数名 = 引数名実体化するとき、クラスに引数を与える
“`Python
class Enemy(object):def __init__(self, name):
self.name = name
print(name)enemy1 = Enemy(“スライム”)
# 実行結果 ⇨ スライム
“`
## メソッド
引数にselfが必須




