
- 1. 【PyScript】PyScript使ってめちゃ適当にデータの可視化してみる【BI】
- 2. 要素数の異なる配列を長い方の要素数だけzipでループする実装
- 3. 【備忘録】numpyのarrayについて
- 4. ダイアログで日付設定
- 5. Web3.pyでThe field extraData is 97 bytes, but should be 32
- 6. 特定のリストから別のリストに存在する要素を全て取り除いた
- 7. GASの配列操作をPythonのようにしたい(自分用メモ)
- 8. Pythonの仮想環境の作り方 Mac/venv
- 9. アルゴリズムのモヤモヤをPythonで解消(2): 挿入ソート
- 10. wordcloudインストール時のエラー
- 11. LaTeXのエディタを作った2(初心者)
- 12. 【Python】icrawlerを用いた画像収集(たった3行!)
- 13. scipy.stats: 独立 k 標本の等分散性の検定
- 14. 【jishaku】discord botでpythonのコマンドを実行する方法
- 15. KerasでCIFAR-10の画像分類をしてみた
- 16. Blenderのアドオン作成のメモ
- 17. 特微量と次元
- 18. ガウス過程と機械学習(ノート目次)
- 19. ガウス過程と機械学習- 第3章(1)
- 20. Python WEBサイトが更新されたらSlackに通知する
【PyScript】PyScript使ってめちゃ適当にデータの可視化してみる【BI】
なんかPyScriptとかいうのが出たらしいですね。
ちょうどデータの可視化云々をやる機会があったので、CSVアップロードしてそのデータの中身を可視化するアプリ的なのを作ってみます。なお、めちゃ適当にするので散布図だけでいったんやってみます。
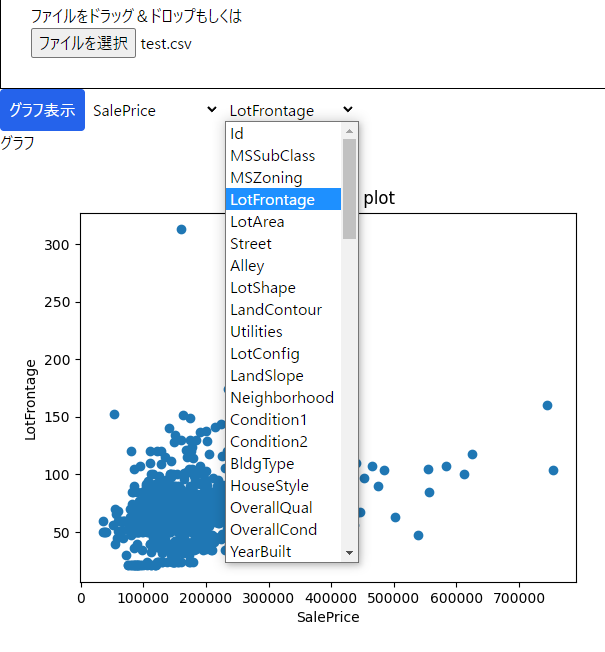# やること
csvの受け取りや要素の追加(カラムの選択とかしたいので)等はJSで行い、PyScriptでは可視化だけやってみたいとおもいます。# HTML要素
利用するHTML要素です。
ファイルの受け取り、データを置いておくダミー要素、プルダウン、グラフの表示部分、表示ボタンを用意してます。“`html:index.html
要素数の異なる配列を長い方の要素数だけzipでループする実装
カードゲームを実装する際、異なる配列を同時にループさせて要素を比較するということがあるかと思います。
そういった場合、pythonでは異なる要素を同時にループさせるzipを用いて実装することを最初のうちは考えるかと思います。
しかし、以下のようにzipは短い方の配列に合わせて、長い方をスライスしてしまいますので要素数が多い方が勝ちみたいなケースには対応できません。
“`
a_array = [4, 3, 2]
b_array = [4, 3, 2, 1]for a, b in zip(a_array, b_array):
print(f'{a}:{b}’)==== 出力 ====
4:4
3:3
2:2
“`そういった場合は以下のように短い方の配列に仮の値を埋めるような実装を行うかと思います。
“`
a_array = [4, 3, 2]
b_array = [4, 3, 2, 1]
lenDiff = len(a_array) – len(b_array)
if lenDiff > 0:
b_array += [-1] * lenDiff
if l
【備忘録】numpyのarrayについて
numpyのarrayについてまとめました。
# arrayの生成
リスト
“`python
import numpy as np
a = np.array([1, 2, 3, 4])
a
#array([1, 2, 3, 4])
“`タプルも可
“`python
np.array((2, 3, 5, 7))
#array([2, 3, 5, 7])
“`二重にネストした配列
“`python
a = np.array([[11, 12, 13], [22, 33, 44]])
a
“””
array([[11, 12, 13],
[22, 33, 44]])
“””
“`リストの要素にarrayを入れても大丈夫
“`python
a = np.array([1, 1, 2, 3])
b = np.array([a, [5, 8, 13, 21]])
b
“””
array([[ 1, 1, 2, 3],
[ 5, 8, 13, 21]])
“””
“`arange()で公差を指定して等差数列をつくる
“`
ダイアログで日付設定
### 概要
パイソン初心者です。
処理を自動化する際に、日付をインプットに作業したいことがあったので、
日付入力をするダイアログを作成。
デフォルトで前営業日(祝日は考慮しない)を設定します。“`
import tkinter.simpledialog as simpledialog
import datetimedef pre_business_day(date):
“”” 前営業日を取得(祝日は考慮しない) “””
# 月曜日の場合
if datetime.date.weekday(date) == 0 :
pre = date – datetime.timedelta(days=3)
# 日曜日の場合
elif datetime.date.weekday(date) == 6 :
pre = date – datetime.timedelta(days=2)
else:
pre = date-datetime.timedelta(days=1)
return pre
Web3.pyでThe field extraData is 97 bytes, but should be 32
どうやら、ミドルウェアをインストールしなければならない。
“` python:add
from web3.middleware import geth_poa_middleware
self.web3.middleware_onion.inject(geth_poa_middleware, layer=0)
“`“` python:sample.py
from web3 import Web3
from web3.middleware import geth_poa_middlewareurl = “https://sample.com” #Infura、Alchemy、QuickNodeなどから取得
web3 = Web3(Web3.HTTPProvider(url))
web3.middleware_onion.inject(geth_poa_middleware, layer=0)
print(web3.eth.get_block(‘latest’))
“`https://web3py.readthedocs.io/en/stable/quickstart.
特定のリストから別のリストに存在する要素を全て取り除いた
# 課題
リストAからリストBに含まれる要素を除きたい# 検索結果
リスト中の重複削除のみだった# 検索ワード
list 重複削除# 参考資料
https://codechacha.com/ja/python-list-remove-duplicates/
https://note.nkmk.me/python-list-unique-duplicate/# コード
“`python:delete_reject_list.py
def unique_list_make(input_base_list, input_reject_list):
# リストA中の重複削除
# set()を使うと高速化できるが、リストの順番が変わるためdictを使用した
base_list = list(dict.fromkeys(input_base_list))
# リストB中の重複削除
reject_list = list(dict.fromkeys(input_reject_list))# リストAからリストBをfor文で削除
GASの配列操作をPythonのようにしたい(自分用メモ)
# 概要
pythonの配列操作は慣れてきたが、GASにおいてJavascriptを使用してコーディングする際に、配列操作の違いについて考えるうちに時間が溶けた。今後簡単に思い出せるために、自分用メモを残しておく`(※全然体系的にはまとめていません)`。
本記事はPythonとJavascriptの違いを対比しながら説明していく。# 配列について
配列とは、[]で囲まれた複数の値のまとまりであり、$[1,2,3,4]$とかで表される。
JavaScriptではそのまま「配列」と呼ばれるが、Pythonでは名前が違い「リスト」と呼ばれる。ややこしいので、本稿においては双方ともに`「配列」`と統一して呼ぶことにする。配列から数値を取り出したり、追加したりするわけだが、PythonとJavaScriptでは若干違う。# 配列の要素をループにおいて取り出したいとき
– pythonでは`in [配列]`を使う
– JavaScriptでは`of [配列]`や`list.forEach(function([配列]){})`を使う
“`python:python
list = [5,9,
Pythonの仮想環境の作り方 Mac/venv
ディレクトリを作る
“`terminal:手順1
$ mkdir project_name
“`作ったディレクトリに移動する
“`terminal:手順2
$ cd project_name
“`仮想環境作成コマンド
“`terminal:手順3
$ python3 -m venv フォルダ名
“`仮想環境を起動
“`terminal:手順4
$ source フォルダ名/bin/activate
“`仮想環境を終了
“`terminal:手順5
(フォルダ名) project_name $ deactivate
“`番外編
パッケージの入れ方
“`terminal:
$ pip install superjson
“`パッケージの確認
“`terminal:
(フォルダ名) project_name $ pip freeze
superjson==0.0.13
“`
アルゴリズムのモヤモヤをPythonで解消(2): 挿入ソート
##### [前回] [アルゴリズムのモヤモヤをPythonで解消(1): バブルソート](https://qiita.com/mingchun_zhao/items/679e96f0d3bb90b720c1)
## はじめに
`Pythonでアルゴリズムを楽しむ`、第2弾です。
## 理論: アルゴリズムの性能評価指標
### 計算量による評価
– 時間計算量
– 単位は、必要な処理/操作回数(ステップ数)
– 処理時間(秒など)は、実行環境(ハードウェア/ソフトウェア)に依存するため使用しない
– 空間計算量
– 記憶容量(メモリ)がどれだけ必要か### O記法(オーきほう、OはOrder)
– 計算量の表記法
– 例えば、データの数`n`に比例し、計算量増加する場合
– O(n)と表す|表記|意味|例|
|:—–:|:—–:|:—–:|
|O(1)|定数|配列を添字アクセスする場合|
|O($log\ {n}$)|対数|二分探索|
|O(n)|1次|線形探索|
|O($n\ log\ {
wordcloudインストール時のエラー
よくネットで見るこんな感じの画像を作りたいと思い、[wordcloud](https://github.com/amueller/word_cloud)をインストールすることに

“`cmd
pip install wordcloud
“`
でエラーが発生しました。“`cmd
error: command ‘C:\\ Visual Studio\\2017\\Community\\VC\\Tools\\MSVC\\14.14.26428\\bin
\\HostX86\\x64\\cl.exe’ failed with exit status 2
“`## 解決方法
最新版の[Visual Studio BuildTools](https://visualstudio.microsoft.com/ja/downloads/)をイン
LaTeXのエディタを作った2(初心者)
※この記事は、[LaTeXのエディタを作った(初心者)](https://qiita.com/tt_and_tk/items/48c10390c36d16c54c3e)の続きです
# なぜ続きを作ろうと思ったのか
前回の記事で、とりあえずtexファイルの編集とコンパイルや閲覧が可能になりました。
しかし不満は残ります。
まず、pdfが見づらいということ。これは由々しき問題です。
私はノートパソコンを主に使っているので、普段pdfファイルを触る時はEdgeで開いてマウスパッドから拡大や縮小・ページ移動などを楽々行っています。
LaTeXエディタでもEdgeみたいなことができたらいいな、と思ったところでひらめきました。Edgeでpdfファイルを開けばいいじゃないかと。
次の問題は、LaTeXのよく使うコマンドをGUIで書き込めるようにしたい、というもの。私は普段コマンドを直接書き込んでtexファイルを編集しています。しかし時間が空けばコマンドを忘れますし、たまにしか使わないコマンドは使うたびに調べるという非効率なことを行っていました。
まとめると、* Edgeでpdfファイルを開く
【Python】icrawlerを用いた画像収集(たった3行!)
# はじめに
Pythonで簡単に画像収集ができるので、趣味での収集だけでなく、機械学習でのデータセットでも活用できると思ったので記載します。## icrawlerパッケージのインストール
“`
pip install icrawler
“`## コード
例として、Googleから犬の画像を10枚取得します。
keywordに検索したい用語を記載(日本語でも英語でも可)
max_numにダウンロード枚数を記載
“`
from icrawler.builtin import GoogleImageCrawler
crawler = GoogleImageCrawler(storage = {“root_dir”:”dogs”}) # ダウンロード先のディレクトリ名
crawler.crawl(keyword=”犬”,max_num = 10)
“`実行すると下記の通り、動き出しますので少し待ちます。
“`
2022-05-28 20:32:53,646 – INFO – icrawler.crawler – start crawling…
2022-05-28
scipy.stats: 独立 k 標本の等分散性の検定
# scipy.stats: 独立 k 標本の等分散性の検定
複数の群の母分散が等しいかどうか検定する。
帰無仮説 $H_0$: それぞれの母分散は等しい。$\sigma^2_1 = \sigma^2_2 = \dots = \sigma^2_k$
対立仮説 $H_1$: それぞれの母分散は等しいとはいえない。$\sigma^2_1 = \sigma^2_2 = \dots = \sigma^2_k$ ではない(どこか少なくとも 1 つの等号は不等号である)。
## 1. Levene 検定,Brown-Forsythe 検定
`levene(*args, center=’median’, proportiontocut=0.05)`
関数名が levene であるが,それはデフォルトの `center=’median’` から見れば不適切である。
Levene は `center=’mean’` に相当する検定を提唱した(1960)。
Brown と Forsythe は後に `center=’median’` とする検定を提唱した(1974)。そのため,Brown-
【jishaku】discord botでpythonのコマンドを実行する方法
## 今回は、discord.pyのbotで、pythonのコマンドやコードを動かす方法を紹介していきます!
では、まず、以下のコマンドを実行してください。
“`pip install jishaku“`
できない場合は
“`py -m pip install jishaku“`
を実行してください。
discord.pyは以下のコマンドで入れられます。
“`py -m pip install discord.py“`
そしたら、メモ帳などを開いてください。(僕は今VScode持ってないのでIDLEを使います。)
## botを作成する方法
https://discord.com/developers/applications
上のサイトにアクセスします。
こんな画面になると思うので、New Applicationをクリックします。

そしたら
KerasでCIFAR-10の画像分類をしてみた
# はじめに
深層学習の勉強として取り組んだMNISTの画像分類の次のステップとして、CIFAR-10の画像分類に取り組んでみた。[以前](https://qiita.com/rython/items/3aa34e4a6935f16020cc)MNISTに取り組んだ際に使用したライブラリ、Kerasを使って同じようにCNNを実装してみる。# CIFAR-10
CIFAR-10データセット(Canadian Institute For Advanced Research)は10種類の画像からなるデータセットで、MNISTと同様に画像認識を目的としたディープラーニング/機械学習の研究や初心者向けチュートリアルで使われている。データセットは5万枚の訓練データと1万枚のテストデータで構成され、中身の画像は24bitのRGBフルカラー画像で、0~255のピクセル値で表される。サイズは幅32×高さ32CIFAR-10には、以下の10種類が用意されている。
ラベル「0」: airplane(飛行機)
ラベル「1」: automobile(自動車)
ラベル「2」: bird(鳥)
ラベル「
Blenderのアドオン作成のメモ
## 概要
Blenderのアドオンを作るときのメモです。
### 前提
– 作成するアドオンは、GitHubで管理します。
– Pythonコードは、Visual Studio Code(以降VSCode)で編集します。
– [WatchAddon](https://github.com/SaitoTsutomu/WatchAddon)アドオンを使って、アドオンファイルを保存すると機能が自動で有効になるようにします。## 手順
### WatchAddonをBlenderにインストールする
[WatchAddon](https://github.com/SaitoTsutomu/WatchAddon)アドオンをインストールしておきます。アドオンを有効化するには、**テスト中**を選ぶ必要があります。
このアドオンをインストールすると、インストール済みの特定のアドオンを直積編集して保存すると自動で有効化されます。
これにより、開発中のアドオンのコードを変更し保存するだけで、開発中のアドオンの機能を確認できるようになります。https://github.com/Sait
特微量と次元
特徴量の個数 = 次元の数
一言で言うと「特徴量」と「次元」とは・・・
求めたいものを特徴づけるもののことを特徴量と言い、特徴量の数が次元の数に相当します。3つの特徴量なら3次元となります。
特徴量の個数 = 次元の数
特徴量とは、求めたいものを特徴づけるもののことですが、これだけでは中々理解が難しいですよね。もっとわかりやすく言うと例えば、自分が飲食店で働いているとして過去の売上から未来の売上を予測したい場合、天気や気温、湿度等々売上に寄与する情報は、未来の売上げを予測するために必要な特徴量と言います。また特徴量に似た言葉に「次元」がありますが特徴量の個数が「次元の数」に相当し、特徴量を減らすとは次元の数を減らすということです。
さらに一般的に上記の例のように、求めたい(予測したい)もの(売上)を目的変数、目的変数に寄与するもの、影響を与えるものを説明変数と言います。
ややこしくなってきたので、整理すると、
特徴量の個数 = 次元の数 = 説明変数の数
となります。特徴量に似た言葉に「属性」がありますが、属性はデータタイプ(上記の例では「気温」)を表すのに対して、
ガウス過程と機械学習(ノート目次)
# ガウス過程と機械学習3章のノート
– [ガウス過程と機械学習](https://www.kspub.co.jp/book/detail/1529267.html)を読んだ自分用のノートです
– 後で見返す用なので、細かすぎることは書かずあらすじ程度の内容
– 詳しいことは本を買って読んでみてください
– 誤字脱字、間違いなどが有りましたらコメントよろしくおねがいします。
– ベイズ系の話を理解するときに自分が引っかかった部分を丁寧に書いたつもりです。ステップ3だけでも読むと他でも活きるかもしれないです
– python で実装しています。自分のノートの目次記事
#
– [ガウス過程と機械学習- 第0章](https://qiita.com/yoneXyone/items/52611e3580f0c4bb480c)
– [ガウス過程と機械学習- 第3章(1)](https://qiita.com/yoneXyone/items/d149471e9581cd3b912c)## 参考文献
詳細な参考文献は各ノートを御覧ください
– [ガウス過程と機械学習](https:/
ガウス過程と機械学習- 第3章(1)
# ガウス過程と機械学習3章のノート
– [ガウス過程と機械学習](https://www.kspub.co.jp/book/detail/1529267.html)を読んだ自分用のノートです
– 後で見返す用なので、細かすぎることは書かずあらすじ程度の内容
– 詳しいことは本を買って読んでみてください
– 誤字脱字、間違いなどが有りましたらコメントよろしくおねがいします。3章ではガウス過程における詳細について議論される.
今回は3.2節まで– [目次](https://qiita.com/yoneXyone/items/e4357c8898ce400de9d7)
– [第0章](https://qiita.com/yoneXyone/items/52611e3580f0c4bb480c)
## 3.1線形回帰モデルと次元の呪い線形モデルとは
“`math
\begin{align}
y &= f(x) = w_{i} \phi(x)_{i}
\end{align}
“`
のようにモデルのパラメータ ${w}$ と $x$ の関数 $\phi(x)$ の線形結合で表され
Python WEBサイトが更新されたらSlackに通知する
はじめに
—————————————
・日経新聞社のニュース記事が更新され次第、タイトルとURLをSLACKに通知するコードを記載する
・日経新聞社をスクレイピングをする際は、robots.txtを参照し、違反等の判断は自己責任でお願い致します。
・以下の参考記事を元に、コードのみを記載致します(詳しく知りたい方は、以下の記事をご確認下さい)
https://qiita.com/ryo-futebol/items/235c212fdfc3704b7e9c
・上記記事のように、定期実行までのコードは載せず、手動での実行コードを記載します。大まかな流れ
—————————————
・対象サイトをスクレイピングして必要情報取得
・更新がないかをチェック
・更新があれば内容をSlackで通知ライブラリ
—————————————
“`
import pandas as pd
import requests
from bs4 imp




