- 1. SPSS Modelerのフラットファイル・エクスポートノードをPythonで書き換える。
- 2. ヘッダーが壊れているLASファイルを修正して、XY座標を入れ替えた上でpy3dtilesで3DTilesを作成する
- 3. 【Python】心臓画像のだいたいの中心を求めて可視化したお話【dicom】
- 4. 非一般名称(宝塚芸名)でNameDividerによる姓名分離を試みる
- 5. 【備忘録】Pythonで自然言語処理の学習を始めるにあたって参考にしたサイト
- 6. 石手川ダムリアルタイムデータをスクレイピングして貯水率を調べる
- 7. PrometheusのExporterをPythonで作る。Client Library無しで
- 8. GCPでPythonプログラムを定期実行する【GCP/Python】
- 9. AtCoder ABC196 D – Hanjoを Python+next_permutationで解いたり、C++でO(3^HW)で通す
- 10. 日鉄ソリューションズプログラミングコンテスト2022(ABC257) A~C問題 ものすごく丁寧でわかりやすい解説 python 灰色~茶色コーダー向け #AtCoder
- 11. ABC077 C – Snuke Festival を 3通りで解く 二分探索/イベントソート
- 12. CloudFunctionsをdeploy時、OperationError: code=3が表示される場合
- 13. 問題 B – Counting Grids解説
- 14. Numbaでnumpyのみのループを最適化するとどの程度早くなるのか?
- 15. ROS:点群の座標変換(Python)
- 16. Google Cloud SQLインスタンスを定期的に停止する
- 17. 最近話題のPyScriptを使ってみる
- 18. qiskitのインストール
- 19. エンティティリンキングシステム「BLINK」の使用環境構築メモ
- 20. Cloud FunctionsによるGCSとBigquery連携:GCS-Trigger
SPSS Modelerのフラットファイル・エクスポートノードをPythonで書き換える。
SPSS Modelerでデータをファイル形式でエクスポートするのが、フラットファイル・エクスポートノードです。
これをPythonのpandasで書き換えてみます。ここでは、以下の5つのオプションについてフォーカスします。
# 0.使用するデータ
以下のID付POSデータ(■ファイル名:sampletranDEPT4en2019S.csv)を使用します。
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータです。

(https://cesium.com/blog/2015/08/10/introducing-3d-tiles/ より)
3DTilesは主にCesium.jsというライブラリを利用して、Google Earthのような地球儀の上に建物など地理空間情報を載せることので
【Python】心臓画像のだいたいの中心を求めて可視化したお話【dicom】
タイトルの通りですね。心臓の輪切りデータから、その中心を求めて可視化したいです。
ただ、公開できそうなdicomデータの持ち合わせがないので、dicomのいじるところはコード上でのみ解説、
その後の動作は[こちらの画像データ](https://www.fmu.ac.jp/home/radtech/RI/RI_kensa1.html)を一部利用させていただいてます。# Dicom画像の読み込み
そもそもdicomデータがどんな構造になってるかですが、上記画像のように複数枚の画像が層のように重なってるイメージでいいかなと思います。
配列で表すと3次元配列の構造になっていることになります。
一つ一つの画像に対してアプローチしたい場合は、まず何層目のデータを利用したいかを指定してあげることで、その層の画像をいじることができます。それでは読み込ん
非一般名称(宝塚芸名)でNameDividerによる姓名分離を試みる
[この記事](https://qiita.com/muto-jo/items/79c41aa2fb8ff27c047c)を書いたとき、Wikipediaの宝塚の生徒一覧は、芸名が姓名に分かれていないと記載しました。
せっかくなので、芸名も姓名に分けてみたいなと思っていたところ、[こちらの記事](https://qiita.com/tanaka_n/items/0bb58c3e7ccfd3ef6b07)でNameDividerなる姓名を分離するPythonライブラリがあるのを見つけたので、トライしてみました。
# サンプルコードでずっこける
インストールはNameDividerの[公式サイト](https://github.com/rskmoi/namedivider-python)にある通りのコマンドで完了。
同じく公式サイトにあるサンプルのコードを実行したところ、FileNotFoundErrorでずっこけました…“`Python
———————————————————————-
【備忘録】Pythonで自然言語処理の学習を始めるにあたって参考にしたサイト
こちらは個人的にGPT3とGPT2の自然言語処理について調べた際に参考にしたサイトを備忘録としてまとめたページです。
# GPT2&GPT3自然言語処理の可能性や実行した際の印象
自然言語処理のスキルが今後必ず必要になると思い立ちました。
GPT3とGPT2を使ったPythonの自然言語処理を実際に行いました。
GPT3は日本語の情報がまだ少ないのですが、精度は高いことを実感できました。
GPT2でテキスト生成された文章はそのまま使うにはクオリティが低いのですが、そのクセのようなものを理解して応用すると文章作成のヒントのような使い方ができます。
GPT2は、ボキャブラリーをたくさん知っている小学3年生といった印象です。# 自然言語処理の学習するにあたって参考にしたサイト
## OpenAI GPT-3 APIの使い方を解説
https://data-analytics.fun/2021/12/01/gpt-3-api/## 【Pythonコード】gpt-3のAPI申請通ったので試してみたら気持ち悪いほど正確なボットができた話
https://note.com/bena
石手川ダムリアルタイムデータをスクレイピングして貯水率を調べる
https://www.skr.mlit.go.jp/matsuyam/river/ishitegawa/chosui/chosui.html
石手川ダムリアルタイムデータ
http://www1.river.go.jp/cgi-bin/DspDamData.exe?ID=1368080150020&KIND=3&PAGE=0“`python
from urllib.parse import urljoinimport pandas as pd
import requests
from bs4 import BeautifulSoupdef fetch_soup(url, parser=”html.parser”):
r = requests.get(url)
r.raise_for_status()soup = BeautifulSoup(r.content, parser)
return soup
url = “http://www1.river.go.jp/cgi-bin/DspDamData.exe?ID=136808
PrometheusのExporterをPythonで作る。Client Library無しで
Prometheusでのモニタリングのアーキテクチャというのは凡そ以下のとおりである。

図の左から、
– Exporterは監視対象をモニターし、問い合わせを受ければ監視対象の現在のモニター値を返答する。
– Prometheusは複数あるExporterからモニター情報を収集し、自身のデータベースに蓄積する。
– GrafanaはPrometheusから一定期間のモニター情報を抽出し、ユーザーにグラフ表示する。
– Alert ManagerはPrometheusのあるモニター値が閾値を超えた場合に、ユーザーにアラート通知する。実用的にはGrafanaは冗長化したPrometheusから重複排除したデータを抽出するThanos Querierを介したりするのだが、割愛する。
何の話がしたいかというと、PrometheusのExporter
GCPでPythonプログラムを定期実行する【GCP/Python】
# やりたいこと
Pythonプログラムを定期実行させる必要がありました。
が、cronだとPCを起動していないといけない。。。ちょっときついので、GCPにやってもらうことにします。
GCPのCloudFunctions、PubSub、CloudSchedulerを使用します。
各種サービスやジョブはコンソールからぽちぽちと作成します、ご了承ください。(terraform勉強中なので、いつかtfファイルで書き直したいです。。)# 設計
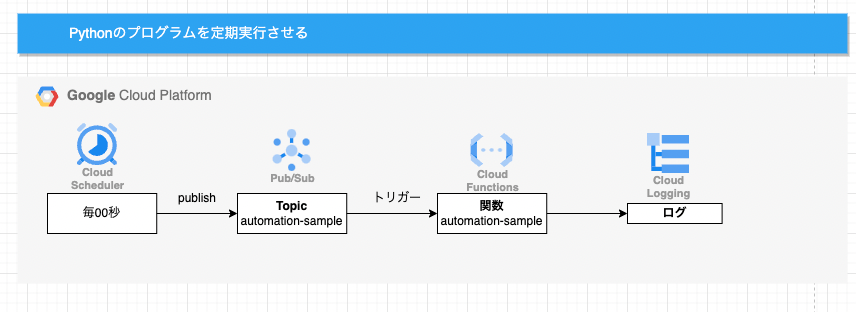CloudSchedulerで、定期的にPubSubトピックにメッセージをpublishさせる。
そのPubSubトピックにメッセージがpublishされることをトリガーに、CloudFunctionsの関数が実行される。
CloudFunctionsの実行結果はCloudLoggingに出力される。
AtCoder ABC196 D – Hanjoを Python+next_permutationで解いたり、C++でO(3^HW)で通す
https://atcoder.jp/contests/abc196/tasks/abc196_d
公式解説ではDFSですがnext_permutaionで解きます。最後にC++でゴリ押ししたO(3^(HW))の例があります。
# 考え方
盤面の候補のあり得る初期状態を全列挙することを考え、以下のようなマスの盤面を考えます。
“`
0: 空いているマス 。1が伸びてくる。(a個)
1: 1マスだけ埋まっているマス(b個)
2: 右か下に1マス伸びたいマス(a個)
“`これを成立する盤面で考えます。
(引用:AtCoderの問題ページより)これらは以下の初期状態から成立できるものです。
“`
[1, 2, 0] [1, 2, 0] [1, 2, 0] [1, 2, 2] [2, 2, 0] [2, 0, 2]
[2, 2, 2]
日鉄ソリューションズプログラミングコンテスト2022(ABC257) A~C問題 ものすごく丁寧でわかりやすい解説 python 灰色~茶色コーダー向け #AtCoder
日鉄ソリューションズプログラミングコンテスト2022(AtCoder Beginner Contest 257) A~C問題の解説記事です。
灰色~茶色コーダーの方向けに解説しています。その他のABC解説、動画などは以下です。
更新時はツイッターにて通知します。
Tweets by AtCoder4https://qiita.com/sano192/items/54accd04df62242b70f0
# 日鉄ソリューションズ(NSSOL)様について
本コンテストは日鉄ソリューションズ(NSSOL)様が主催されています。https://www.nssol.nipponsteel.com/saiyo/
# A – A to Z String 2 Dif:22
https://atcoder.jp/contests/abc257/tasks/abc257_a
実際に「A」をN個、「B」をN個、…と文字列を作ってしまいましょう。
例えば(文字列)に「A」をN個くっつけるときは
(文字列)+=”A”*N
となります。そうしてからX番目の文字を出
ABC077 C – Snuke Festival を 3通りで解く 二分探索/イベントソート
https://atcoder.jp/contests/abc077/tasks/arc084_a
– 解法1: 公式解説通りです
– 解法2: イベントソートのように解きます
– 解法3: LeetCodeっぽい解き方をします。入力がソートされていればO(N)です。# 解法1: すべてソートしておき、B[i]をもとに二分探索
公式解答通りです。
時間計算量はソートに$O(NlogN)$、各探索に$O(NlogN)$です。
空間計算量は$O(N)$です。実装(Python)
“`Python
from bisect import bisect_left, bisect_right
n = int(input())
d1 = list(map(int, input().split()))
d2 = list(map(int, input().split()))
d3 = list(map(int, input().split()))
d1.sort()
d3.sort()
ans = 0
for centeCloudFunctionsをdeploy時、OperationError: code=3が表示される場合
言語はPythonです。
# エラー内容
“`python
ERROR: (gcloud.functions.deploy) OperationError: code=3, message=Function
failed on loading user code. Error message: Please examine your function
logs to see the error cause:
https://cloud.google.com/functions/docs/monitoring/logging#viewing_logs
“`公式の回答はこちらなのですが
[Cloud Functions のトラブルシューティング | Google Cloud Functions に関するドキュメント](https://cloud.google.com/functions/docs/troubleshooting?hl=ja#cloud-sdk_6)
ここに書いてあるとおりにやっても駄目な場合
# エントリ ポイントが正しく指定されていてもエラーになっている
問題 B – Counting Grids解説
## B – Counting Grids AtCoder Regular Contest 143
> N×N のマス目の各マスに 1 から N2 までの整数を 1 つずつ書き込む方法であって, どのマスも以下の条件のうち少なくとも一方を満たすようなものの個数を998244353 で割ったあまりを求めてください.条件A : そのマスに書かれている数より大きい数が同じ列に存在する条件B : そのマスに書かれている数より小さい数が同じ行に存在する
N×Nの各マスに、1~Nの数字1つずつを、AまたはBの条件を満たしながら、どんどん書き込みます。それで、その書き込み方の個数を求めます。
## 考え方の方針
直接「${A\cup B}$を満たすマス」を考えるのはしんどいので、その逆、「${\bar{A} \cap \bar{B}}$を満たすマス」を考えれば、問題を「すべてのマスが${\bar{A}\cap \bar{B}}$を満たす書き込み方の個数を求める」ことに置き換えられそうです。
:::note info
${\bar{A}\cap \bar{B}}$
条件${\bar{A}Numbaでnumpyのみのループを最適化するとどの程度早くなるのか?
Pythonは遅い遅いと言われて久しい、そして遅い。というか、LLで速い言語なんてあるはずがないので、そもそも遅いと文句を言うこと自体がお門違いという気もするが、労力が同じならプログラムは速い方が良いに決まっている。
ただし、下回りのライブラリが速い場合は別である。そして、numpyが生まれた。というわけで、Pythonで数値計算を行う場合、numpyを使えば言うほど遅くないのだが、問題はforループである。シミュレーションなどの計算で、データを順繰りに読み込んで処理するという処理は割と頻出するのだが、そんとき、ループのなかでnumpyを呼び出すコードはpure pythonになってしまうので、とても遅いと、少なくとも一般的にそう思われていると思う。
ところで、最近「じけいれつかいせき」に凝っていて、ちょうどKalmanFilterのパラメータ・フィッティングを行ったので、この遅い遅いと言われるforループをjitコンパイルすることでどの程度早くなるのか見てみることにした(よく、マンデルブロ集合とか、ローレンツの偏微分方程式とかを計算して20倍速くなったよ!みたいな話を聞くが、あ
ROS:点群の座標変換(Python)
# ROS:点群の座標変換(Python)
この記事では`ROS`で、ステレオカメラ等からの`PointCloud2`型の`topic`を座標変換する方法について説明します.これを使うとカメラ画像から検出した物体の座標をカメラローカルからマップグローバルに変換できます.## 環境
Ubuntu18.04
ROS(Melodic)## 準備
本記事では事前に静的な座標変換を行っていることを前提としています.
各センサを起動する`launch`ファイルに`static_transform_publisher`を用いて座標変換を記述してください.## 方法
`ROS`では`link`同士の座標変換を行うときには主に[`tf`](http://wiki.ros.org/ja/tf)と呼ばれるライブラリを使用します.これを用いると`source`と`target`を指定するだけで座標変換をすることができます.点群座標は`PointStamped`型を使用します.
以下の方法で`PointCloud2`型の`topic`を座標変換します.今回の場合は`camera_link`->`maGoogle Cloud SQLインスタンスを定期的に停止する
# 概要
Google Cloud SQLのインスタンスを停止するための関数をCloud Functionsで作成し、Cloud Schedulerで定期実行するように設定しました。
今後も使いそうなので備忘録として残しておきます。# 設定内容
## Cloud Functions
Python3.9を使用しています。
“`requirements.txt
google-api-python-client
Oauth2client
“`
“`main.py
import json
import os
import base64
import logging
import googleapiclient.discovery
from oauth2client.client import GoogleCredentialsfrom pprint import pprint
credentials = GoogleCredentials.get_application_default()
sqladmin = googleapiclient.discovery.build(‘最近話題のPyScriptを使ってみる
# 初めに〜PyScriptとは〜
最近、**PyScript**というものが少しホットな話題になっているようです。これまでHTMLの中に書くことができるのは**JavaScript**だけだったのですが、PyScriptを用いると**PythonコードをHTMLの中に書いて、実行することができます。**
例えば入力されたデータを用いてグラフを描画するといったことは、これまでJavaScriptでしかできませんでしたが、これからはPythonを使うことでも可能になるのです!2022年4月末に**Anaconda**から発表されたPyScriptですが、当記事執筆時点(2022年6月)で公開されているのは**アルファ版(パイロット版)** です。
まだまだ機能が足りないところもありますが、今後の開発が期待されます。# 開発環境
この記事では以下の環境で開発を行っています。
– MacOS Monterey version 12.4
– ブラウザ:Safari version 15.5
(エディタはCotEditorを使うことが多いです。同士いますか…)# 基本的
qiskitのインストール
qiskitというのはIBMが作った量子計算パッケージです。IBM-Quantumと連動して実際の量子コンピューターでコードを実行することもできます。
https://quantum-computing.ibm.com/
# 仮想環境構築
まず、仮想環境を用意します。というのもpipとcondaを両方使う必要があるからです。環境の名前はqiskitとしました。ターミナルから操作します。
“`
conda create -n qiskit
conda activate qiskit
“`# インストール
qiskit環境に入ったら以下のパッケージをインストールします。
“`
pip install qiskit
pip install qiskit[all]
“`最適化ツールの”qiskit-aqua”というパッケージがありましたが、いつの間にか廃止になってしまったようです。一応、次のコマンドでインストールできましたが、まともに動きませんでした。
“`
pip install qiskit-aqua[all]==0.7.1
“`# 参考
– httpエンティティリンキングシステム「BLINK」の使用環境構築メモ
# BLINKとは?
– リポジトリ:https://github.com/facebookresearch/BLINK
– [エンティティリンキング](https://ja.wikipedia.org/wiki/エンティティ・リンキング)を行うためのシステム
– 高速だが精度に劣るバイエンコーダというモデルと、精度は高いが速度は遅いクロスエンコーダというモデルの2つ(両方ともBERTを使用)を組み合わせてエンティティリンキングを行う
– エンティティリンキングの手がかりとして、エンティティを説明するディスクリプション(+エンティティ名)と文章中のエンティティメンション(+その周囲の文脈)しか使わないことが特徴
– 詳しくは、右の論文を参照:[Scalable Zero-shot Entity Linking with Dense Entity Retrieval](https://arxiv.org/pdf/1911.03814.pdf)
# 環境
– OS:Linux 4.18.0-240.1.1.el8_3.x86_64
– pyenvインストール済み
– GPU:GeFCloud FunctionsによるGCSとBigquery連携:GCS-Trigger
# 背景
CloudStorageに毎日アップロードされたデータを簡単なpython処理後、Bigquery上のtableにoutputすることです。
Airflow(CloudComposer)では簡単にできましたが、データ量がそこまで大きくはないので、CloudFunctionsだけで対応できるかなと思います。# 目次
1、サンプルデータ
2、事前準備ーGCS&Bigquery&ServiceAccount
3、CloudFunctionsの実装## 1、サンプルデータ
プラバシーの考慮で、サンプルデータを利用します。データセット:
・東京電力使用実績データ:https://www.tepco.co.jp/forecast/html/download-j.html
・東京天気気温データ:https://www.data.jma.go.jp/gmd/risk/obsdl/#
月別データを使用することを想定します。
データフォーマットはJsonlです(業務と一致にします。)。CSVファイルも同じです。## 2 準備ーGCSとBigqueryの設定
①outputとして、
OTHERカテゴリの最新記事
-

- 2024.09.19
JavaScript関連のことを調べてみた
-

- 2024.09.19
JAVA関連のことを調べてみた
-

- 2024.09.19
iOS関連のことを調べてみた
-

- 2024.09.19
Rails関連のことを調べてみた
-

- 2024.09.19
Lambda関連のことを調べてみた
-

- 2024.09.19
Python関連のことを調べてみた