
- 1. PyTorch の dataloader の shuffle 機能に再現性をもたせる方法
- 2. Django 管理画面でのカスタムフィルター admin.SimpleListFilter
- 3. PythonとSQLiteを使ってみた
- 4. 2022年のPythonの組み込みvenvツールについて
- 5. Hello Python3
- 6. 無自覚に rm /* した話(pathlib)
- 7. Python 学習ノート #3【自動PDF変換】
- 8. Python 学習ノート #2【自動フォルダ作成】
- 9. Python 学習ノート #1【自動ファイル名変換】
- 10. IPアドレスからおおよその場所(緯度経度)を取得する
- 11. Google Vision APIを用いてOCRをした結果をJSONファイルで保存/読み込みする
- 12. ゴルゴ13のISBNリストを取得する
- 13. 参院選2022候補者アンケートの検索用スプシの共有とそのデータ分析
- 14. 少し外側のキリのいい数値を求める
- 15. 【Python】WebスクレイピングでHTML内のscriptタグにあるJavaScriptの変数(JSON)を抽出したい
- 16. Jupyter NotebookをMacにインストールした方法
- 17. Pythonのデコレーターで引数情報や型情報を保持する方法
- 18. Pythonのインストール[2022/06/28版]
- 19. GoogleCloudRunからGCSにファイルをアップロードする
- 20. pythonのバージョン変更方法(aliasとpyenv)
PyTorch の dataloader の shuffle 機能に再現性をもたせる方法
# はじめに
複数の実験条件で比較検証を行う場合、比較したい条件以外は同じ条件で実験しなければなりませんが、dataloader の shuffle 機能を使うと実行ごとに毎度変わったデータの読み込み順になってしまいます。これでは学習モデルの再現性を保つことができません。
今回は、データの読み込み順にランダム性をもたせつつ、shuffle機能の再現性をseedで担保する解決策を残しておきます。# 解決方法
**torch.manual_seed(seed)を加えます。**“`train.py
seed = 20220703”’
追加コード: shuffle の再現性を担保する
”’
torch.manual_seed(seed)train_set = mydataset.MyDatasets(input_dir)
train_loader = torch.utils.data.DataLoader(train_set,batch_size=n_batch,shuffle=True,num_workers=4,pin_memory=True,drop_last=
Django 管理画面でのカスタムフィルター admin.SimpleListFilter
—
## 環境
Windows 11 Home
Python 3.10.2
Django 4.0.2
venv利用あり## 背景
管理画面において、フィルターの名称を変えたりカスタマイズしたフィルターを使用したかった。
例えばBool値のフィルタにおいて、「はい」「いいえ」だけでなく、データ登録されていないものを抽出するために
「はい か いいえ=登録あり」「はいでもいいえでもない=登録なし」といったものを用意したかった。## models.py
“`python:mysite\models.py
from django.db import modelsclass TestModel(models.Model):
class Meta:
verbose_name = ‘テストモデル’
verbose_name_plural = ‘テストモデル’columnA = models.CharField(max_length=30, unique=False, primary_key=True)
columnB =
PythonとSQLiteを使ってみた
仕事ではJavaやJavaScriptが多いですが、個人的にはpythonが好きです。
pythonの現場に行く機会があった時にできるようになっていたいなあとなるべく毎日勉強しています。今回はpythonに標準であるSQLiteを使って基本的なことをやってみました。
まず、DB作成からテーブル、データのinsertまで。“`
import sqlite3#データベースファイルを作る
dbfile = sqlite3.connect(‘fruit.db’)
c = dbfile.cursor()createSql = ‘create table FruitName(id,name);’
c.execute(createSql)insertSql = “insert into FruitName(1,’Apple’);”
c.execute(insertSql)dbfile.commit()
dbfile.close()
“`
作成したテーブル内のデータを表示するためのソースがこちら
“`
import sqlite3connectDb = sqlite3
2022年のPythonの組み込みvenvツールについて
・Pyenv:プロジェクトごとの仮想環境のコンテキスト外で、コマンドラインでさまざまなPythonエディションを使用する場合に便利です。
・Pipenv:Pipenvは、仮想環境とプロジェクトの依存関係管理ツールとして使えます。ただし、Pipenvはどのような形式のパッケージ化についても対応している訳ではないです。そのため、最終的にPyPIにアップロードしたり、他の人と共有したりするプロジェクトには理想的ではありません。
Poetry:Pipenvのツールセットを拡張したPoetryは、プロジェクトと要件を管理するだけでなく、プロジェクトをPyPIに簡単にデプロイする事が可能です。
PDM:最も最先端のプロジェクトです。PoetryやPipenvと同様に、PDMは、プロジェクトをセットアップし、その依存関係を管理し、そこから配布アーティファクトを構築するための単一のインターフェースを提供します。
Hello Python3
Code: sample
`
print(‘hello world’)
`
無自覚に rm /* した話(pathlib)
# 結論
`pathlib`の`joinpath()`に誤って**絶対パス**を入れてしまった
結果,`rm ./temp/hoge/*`のつもりが`rm /*`が走った`sudo`や`-rf`は付けてなかったので,実害はなし :innocent:
# 経緯
諸事情により,Python & subprocess経由で`rm ./temp/hoge/*`を実行したかった.
スクリプトをノリノリで書いて実行した瞬間,エラーメッセージが山のように流れた.“`bash
rm: cannot remove ‘/bin’: Permission denied
rm: cannot remove ‘/boot’: Is a directory
rm: cannot remove ‘/dev’: Is a directory
rm: cannot remove ‘/etc’: Is a directory
…
“`# 実行したスクリプト
下のコードを実行すると`rm /*`が実行される.:::note alert
下のコードを実行しないでください
:::
“`python:
Python 学習ノート #3【自動PDF変換】
#1.きっかけ
昨日作成した自動ファイル名変換プログラムで図に命名することができた。
さらにそれぞれの図を連番フォルダに分けていくことができた。
しかし、それぞれの画像を参照しながら問題を解いていくと、どこを読んでいるかわからなくなってしまうことが多々あった。
なので、すべての図をPDFに変換して描画ツールの定規などを置いたり、マーカーで線を引くなどして対応したい。そのため、この大量の図をPDFに変換する必要がある。
#2.作成
盛り込みたい機能
– それぞれのフォルダに分かれてしまっているのでフォルダ指定ができるようにする。
– 画像のタイプも指定できるようにしたい
– 生成するPDFの名称も指定したい。以上の条件を満たすプログラムを作成していく。
##2-1.Pathを通す
まずは図が格納されているフォルダまでの経路をimg_pathに格納する。
“`Auto_Make_PDF.py
print(r”例)C:\Users\Owner\Downloads”)
img_path=input(“PDFに変換したい画像が存在するパスを入力してください==>”)
“
Python 学習ノート #2【自動フォルダ作成】
#1.きっかけ
昨日作成した自動ファイル名変換プログラムで図に命名することができた。
さらに、それぞれの模擬試験をフォルダに連番で分けていきたい。なので、連番のフォルダを自動で作成するプログラムを作成しようと考えた。
#2.作成
では、さっそく自動フォルダ作成機能をさっと作っておこうと思います。
##2-1.フォルダ数選択
まずは作成する量を入力値から読み込みます。
“`Auto_Make_Folder.py
#フォルダ数選択
print(“いくつのフォルダを作成しますか==>”,end=””)
folder_maker=int(input())
print(“{}件のフォルダが作成されます。”.format(folder_maker))
“`
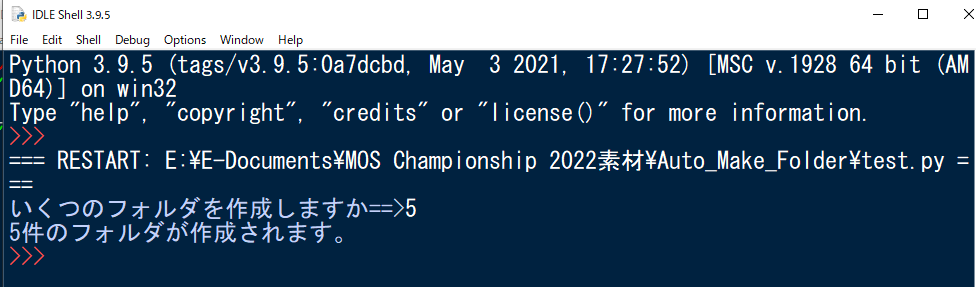これで作成する量をユーザー入力から任意で設定することができました。
##2-
Python 学習ノート #1【自動ファイル名変換】
#1.きっかけ
Wordの本を読みながらPCで実際の操作を学習していた。
しかし、キーボードを両手で打つと手が離れてしまい、本がめくれるなど不便なことばかり。
よって非破壊自炊法により、本をイメージ化することに成功した。([参考](https://follow-myheart.com/archives/990))実際の画像はこちら
それらを用いた実際の学習環境は以下のようになる。
今は6画面を用いて作業しているのでとても楽に作業ができる。
モニターリソースとしては以下のように使用している。
IPアドレスからおおよその場所(緯度経度)を取得する
# gecoderを使う方法
## install
“`bash
pip install geocoder
“`中を見るとWebサービスを利用しているから、オンラインアクセスが出来ないと駄目だったり、Webサービスがなんらかで中断してたら使えない。
## code
codeはこんな感じ
“`python
import geocoderdef ip2geocode(ip):
g = geocoder.ip(ip)
if len(g.latlng) == 0:
print(‘IPから位置情報が取れない IP={0}’.format(ip))
else:
print(‘latlng = {0},{1}’.format(g.latlng[0], g.latlng[1]))
print(‘https://www.google.com/maps?q={0},{1}’.format(g.latlng[0], g.latlng[1]))
“`# **GeoLite2を使う場合**
## DBのダウン
Google Vision APIを用いてOCRをした結果をJSONファイルで保存/読み込みする
# 記事概要
Google Vision APIを用いてOCRをした際の結果を再利用するためにJSONファイルに書き出し、読み込みを行います。
## 本記事の前提条件
環境における前提としてGoogleのVision APIのアクセスキー登録やライブラリのダウンロードが終わっているものとします。
筆者はソースコードも含め下記を参考にしているため、そちらを一度参照するとスムースに本記事が読めると思います。
https://qiita.com/shoku-pan/items/bf5645894803769edc72#vision-api-%E3%82%BB%E3%83%83%E3%83%88%E3%82%A2%E3%83%83%E3%83%97
## モチベーション
Googleの提供するVision APIはかなり良い精度のOCRを可能にしてくれますが、**従量課金制になっているためなるべく少ない回数の呼び出しで済ませたい**という事情があります。
具体的には、OCRのテキスト抽出に限って言うとだいたい下記のようになっています。
– 月に1000画像まで無料
– 以
ゴルゴ13のISBNリストを取得する
# 概要
くだらない話ですが、所有するコミックのデータベースを作ろうとしてます。
ゴルゴ13は、200冊を超える状況で、「さいとう・たかを」先生が逝去された後も、まだ続いています。そんなゴルゴ13ですが、ISBNが採用された時期よりも前から出版されているので、ISBNリストを使った書籍情報の検索をしようとしてもISBNが書籍にのっていません。
が、、、、版数が版数なので、ISBNが始まった時期より後に増刷となった場合、古い書籍もISBNが採番されます。そこで、リイド社のゴルゴ13のページから200冊を超えるゴルゴ13のISBNを取得しようとしてます。
(200冊を超えるISBNのリストがあれば、そこから持っている巻数のISBNを把握すればいい)# リイド社を見てみる
https://www.leed.co.jp/standardbooks
から、大雑把にわかりそうである。大変ありがたい。さらに、その目的のために、NHKがすでに[ボートマッチ](https://www.nhk.or.jp/senkyo/database/sangiin/survey/votematch/)という特設Webサイトを用意している。そのサイトでは、自分自身が候補者と同じアンケートを回答し、その結果と各候補者の一致度が表示される。一致度の計算式も明確に公開されており、大変素晴らしい試みだと思う。
しかし、実際に使って自分の考えに近い候補者を選ぼうとすると、以下の点が気になった。
1. 比例区では、まず政党を選びその政党内での候補者比較しか一度に見られない
1. 同じ回答か否か(一致)で判断するため、例えば自分が「賛成」と回答した設問では候補
少し外側のキリのいい数値を求める
# 概要
小ネタです。
今回作成するpythonの関数を使うと
“`python
CalcOuterRange([-0.1234, 0.4321]) # 出力:[-0.2, 0.5]
CalcOuterRange([-0.1234, 0.4321], -1) # 出力:[-0.13, 0.44]
CalcOuterRange([-1234, 4321]) # 出力:[-2000.0, 5000.0]
CalcOuterRange([-1234, 4321], -1) # 出力:[-1300.0, 4400.0]
“`というように少し外側のキリのいい数値を得られます。
# はじめに
測定データの処理で、グラフの表示範囲やパラメータの探索範囲などを自動で設定させるとき、
「この計算値とこの計算値のちょっと外側」
にしておきたいということがあります。簡単なやり方としては、計算で得た範囲の小さい方が$s_1$で、大きい方が$s_2$なら、
「$0.9 \times s_1$ ~ $1.1 \times s_
【Python】WebスクレイピングでHTML内のscriptタグにあるJavaScriptの変数(JSON)を抽出したい
Webスクレイピングでは通常、クローラーで取得したHTMLの中から、metaタグにあるページのメタ情報やtableタグにある表形式のデータなどを抽出する。
scriptタグの中に埋め込まれた動的スクリプト内で、varで宣言されたJavaScriptの変数(JSON)に欲しい情報が入っている場合、下記のような方法で抽出できる。# 環境
Python 3.9
macOS# コード
“`sample.py
import json
import re
from bs4 import BeautifulSoup as bsdef extract_js_var(soup, js_var):
script = soup.find(‘script’, text=re.compile(js_var, re.DOTALL))
regex = ‘(?:var ‘ + js_var + ‘ = )({.*?})(?:;)’
json_str = re.search(regex, script.string).group(1)
return json.load
Jupyter NotebookをMacにインストールした方法
Homebrewのアップデートを行ったら(?)Jupyterがなくなってしまった(?)のでインストールした。
以下のことを記す。– Jupyter Notebookのインストール
– Jupyter Notebookの立ち上げ方
– Jupyter Labについて図の描き方はまた別記事にしたいと思う。
# はじめに
前提知識は以下の通りである。
– macOS
– python3はすでに入っている[Jupyter Notebook](https://jupyter.org/)は図を作成するときに使っている。
合う合わないはあると思うが、私は使いやすいと思っている。# Jupyter Notebookのインストール
Jupyterがなくなってしまった。
~~~
% jupyter –version
zsh: command not found: jupyter
~~~まずはpython, pipのバージョン確認。
~~~
% python –version
Python 2.7.18
% python3 –version
Python 3.9.12
Pythonのデコレーターで引数情報や型情報を保持する方法
Pythonでデコレーターを使う際に引数情報やdocstring情報などがエディタやLint上で失われないようにするための小ネタです。
# 何が問題なのか
たとえば以下のような関数があったとします。
“`py
def sample_func(a: int, b: str = ”) -> int:
“””
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do
eiusmod tempor incididunt ut labore.Parameters
———-
a : int
Et dolore magna aliqua.
b : str, optional
Ut enim ad minim veniam, quis nostrud exercitation ullamco
laborisReturns
——-
c : int
Nisi
Pythonのインストール[2022/06/28版]
# Pyhonのインストール方法
私自身の備忘録のためにPythonのインストール方法を記載していきます。(2022/06/28 現在3.10.5)
## python公式サイトからダウンロード
– [Python公式サイト](https://www.python.org/downloads/)から`[Download Python x.xx.x]`を選択する。https://www.python.org/downloads/
– ダウンロードした`python-x.xx.x-amd64.exe`を実行する。

上記画像のInstall Nowに該当するボタンを押す。
(もし、Pathを通す必要がある場合は[Add Python 3.10 to PATH]にチェックを入れておく。)– 完了したらCloseを押す。
以上でインストー
GoogleCloudRunからGCSにファイルをアップロードする
# VS Codeの設定
もしもCloudRunが初めてで、VSCodeを使っているのなら、このあたりを試してみてデプロイ出来るようにしておくと良いです。
[サンプル アプリケーションからの Cloud Run サービスの作成 | Cloud Code for VS Code | Google Cloud](https://cloud.google.com/code/docs/vscode/creating-a-cloud-run-service?hl=ja)
# ソース
CloudRunように作っています。CloudFunctionsでも手直せば動くと思う。
言語はPythonです。“`python
import os
from functions.upload_file import upload_gcs
from flask import Flask, request# pylint: disable=C0103
app = Flask(__name__)@app.route(‘/upload-gcs’, methods=[‘GET’, ‘POST’])
d
pythonのバージョン変更方法(aliasとpyenv)
はじめに
—
pythonを使用して構築する際に、バージョンの変更方法によって違いが発生し、詰まってしまったため、まとめておくことにしました。
AmazonLinux2を使用してpython3.9.2の適用を検証していきます。
デフォルトではpythonコマンドでは2.7.18、python3コマンドでは3.7.10が呼び出されます。適用パターンは以下の3パターンです。
1.wgetを使用してインストール、aliasで適用
2.wgetを使用してインストール、シンボリックリンクの変更で適用
3.gitを使用してインストール、pyenvで適用インストール方法(1,2共通)
—### python3.9.2のインストール
インストールに必要なツールをインストールします。
“`
$ sudo yum groupinstall “development tools”
$ sudo yum install gcc zlib-devel bzip2 bzip2-devel readline-devel sqlite sqlite-devel openssl-devel tk-




