
- 1. 事前準備
- 2. サンプルコード
- 2.1. Raspberry PiとSwitchbotを使って自然に起きられる光目覚ましを作ってみた(python)
- 2.2. PythonとSeleniumとWebDriverでドライバとブラウザのバージョン確認
- 2.3. GitHub Actionsを用いて調整さんの候補日程を自動生成
- 2.4. [Python] Webサイトに自動ログイン
- 2.5. Codility lesson4 FrogRiverOne
- 2.6. プログラミング初学者がプログラミング言語と周辺知識の概要を知るための記事
- 2.7. 【Python】エクセルの入力内容の読み込みと書き出しをしてみた
- 2.8. Pythonによるキーフレーズ抽出(KPE)アルゴリズムの比較
- 2.9. DRFのModelSerializerを通して新規登録、更新(create / update)
- 2.10. Django 管理画面でのカスタムフィルター admin.SimpleListFilter
- 2.11. 実際に私が試したブロックチェーン学習素材 | 5つのコンテンツのメリット・デメリットを解説
- 2.12. Pythonで.envファイルから環境変数を設定する
- 2.13. pyenvで.python_versionを設定していてもPythonのバージョンが切り替わらないとき
- 2.14. condaでopencvをinstallすると「ImportError: DLL load failed: 指定されたモジュールが見つかりません」
- 2.15. PythonとSQLiteを使ってみた
Tenable.io_SDK_for_Pythonでスキャン結果を自動エクスポートする
# Tenable.io_SDK_for_Pythonでスキャン結果を自動エクスポートする
**1.環境**
OS:Windows10
Python3.8.xx(Pythonのパスは通しておく)**2.前準備**
Tenalbe.ioでアカウントの作成
Tenalbe.ioでスキャン作成、検査対象のスキャンが完了している**3.手順**
**3.1.APIキーの取得**
Tenalbe.ioでAPIを叩くにはAPIキーで認証を通過する必要があります。
アカウントの設定画面のAPIの項目でGenerateボタンを押して
Access KeyとSecret Keyを表示させて
内容をメモして下さい。**3.2.Tenale.io SDK for Pythonのインストール**
コマンドプロンプトにて以下を実行
“`
pip install tenable_io
“`***3.3.作業用ディレクトリの作成***
“`
mkdir tio
cd tio
“`***3.4.自動エクスポート用スクリプト作成***
{スキャン名1}
{スキャン名2}
{スキャン名3}
{
Pythonでword2vecを使ってみる(Windows11)
# まえおき
この記事は[wikipediaを使ったword2vecコーパスの作り方をまとめてみた](https://qiita.com/Zect/items/d106d46fc94eaa2ed361)、[【Python】Word2Vecの使い方](https://qiita.com/kenta1984/items/93b64768494f971edf86)を参考にして作られています。
SSH接続したPCで動かすためにコマンドラインのみで完結するようにしました。(インストール手順は割愛します。)# 開発環境
– Windows11
– python: 3.10
– gensim: 4.1.2
– wsl2(これを使えばLinuxのように動かせるので楽ですが今回は極力使いません)# wikipediaのデータをもってくる
現ディレクトリ内に`jawiki-latest-pages-articles.xml.bz2`をダウンロードします。
~~~
curl https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-a
PythonでRabbitMQ使ってみる
## RabbitMQの起動
DockerでRabbitMQを起動します。
“`sh
# DockerHub: https://hub.docker.com/_/rabbitmq
$ docker pull rabbitmq
$ docker run -d –hostname my-rabbit –name some-rabbit -p 5672:5672 rabbitmq:3
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4e0ebfaec33e rabbitmq:3 “docker-entrypoint.s…” 3 seconds ago Up 2 seconds 4369/tcp, 5671/tcp, 15691-15692/tcp, 25672/tc
好奇心でスーパーマリオ1-1をクリアする
[強化学習でスーパーマリオをクリアする話](https://qiita.com/hrs1985/items/d249bf5d41078ded60c2)の続きです。読んでいない方は先にそちらを読んでおいた方がいいかもしれません。

1. エージェントは環境から時刻$t$の状態$s_{t}$と報酬$r_{t}$を受け取る
1. エージェントは$s_{t}$に応じた行動$a_{t}$を環境に渡す
1. 環境は$a_{t}$を用いて時刻を1ステップ分進めて時刻$t+1$の状態$s_{t+1}$と報酬$r_{t+1}$を得る
1. エージェントは環境から$s_{t+1}, r_{t+1}$を受け取る
1. 1に戻る強化学習では以上のような手順を繰り返すことで得られる報酬$r_{t}$の総和(の期待値)を最大化する方策を得ることを目的とします。報酬は学習のた
flacファイルをm4aにタグやカバー画像などすべて変換する(Python)
ipadにflacを移行できなかったためpythonでm4aにする。
またflac-m4a変換だけはなくタグの情報等も編集する。
当方、初投稿、故にMarkdown記法適当です。見にくかったらすみません。事前準備
ffmpegをPCにインストールする
https://ffmpeg.org/
上のサイトからダウソして、解凍。詳しいインストール方法は各自お調べください。
次にPythonのライブラリのpydubとmutagenをインストールする
“`
pip install pydub
pip install mutagen
“`サンプルコード
“`python:encode.py
#-*- coding:utf-8 -*-
import time, os, re
from pydub import AudioSegment
AudioSegment.converter = “C:\\ffmpeg\\bin\\ffmpeg.exe”
from mutagen.flac import FLAC, Picture
from mutagen.
Raspberry PiとSwitchbotを使って自然に起きられる光目覚ましを作ってみた(python)
# はじめに
スマートホーム化第2弾です!今回は光目覚ましを作ってみたいと思います。
Raspberry Pi zero WHとSwitchBotのテープライトを買ってみました〜!
私はとても寝起きが悪いので、光を徐々に明るくすることで自然にスッキリ起きられるところを目指します!!
# 必要なもの
– SwitchBotテープライト
– Raspberry Pi
– mic


PythonとSeleniumとWebDriverでドライバとブラウザのバージョン確認
“`python
from selenium import webdriverdef main():
try:
# ————————————————————–
# Firefox
# ————————————————————–
driver = None
driver = webdriver.Firefox()
print(driver.session_id)
print(driver.capabilities[“platformName”])
print(driver.capabilities[“browserName”])
print(driver.capabilities[“browserVersion”])
if driver.capabili
GitHub Actionsを用いて調整さんの候補日程を自動生成
[調整さん](https://chouseisan.com/)の候補日程をGitHub Actions上でPythonを用いて自動生成します。
## 使い方
1. [https://github.com/yarakigit/chouseisan_script](https://github.com/yarakigit/chouseisan_script)を**fork**
2. **Actions >> I understand my workflows, go ahead and enable them**をクリック
2. [setting.csv](https://github.com/yarakigit/chouseisan_script/blob/main/setting.csv)を変更して**push**
3. *
[Python] Webサイトに自動ログイン
## はじめに
大学の健康管理システムに毎日ログインして健康と入力する作業が面倒と感じたので今回基本となるWebサイトへの自動入力に関する記事を書こうと思いました。
会社員や学生の方にもこういうルーティンワークがある人が参考となると嬉しいです。## 開発環境
|OS|使用言語|ブラウザ|
|:—:|:—:|:–:|
|Windows10|Python|Google Chrome|## 事前準備
### まずはGoogle Chromeのversion確認
Google chromeの右上にある3つの点々→「ヘルプ」→「Google Chromeについて」をクリック
__自分の場合はバージョン:103.0.5060.66と確認__
### バージョンに沿ったChromedriverのインストール
以下のサイト
Codility lesson4 FrogRiverOne
Lesson4のFrogRiverOneは位置1から位置Xまでいく最短の時間を求めるというものです。具体例で確認してみましょう。
例えば長さ4の配列[4,1,2,3]について、4に行く(X=4)には時間はどのくらいかかるでしょうか?
今回の問題設定では各配列の要素が位置を表し、0,1,2…インデックス番号が時間を表していると考えてください。つまり、
時間0(インデックス番号0の時)の時は4の位置が現れ、
時間1(インデックス番号1の時)の時は1の位置が現れ、
時間2(インデックス番号2の時)の時は2の位置が現れ、
時間3(インデックス番号3の時)の時は3の位置が現れます。時間3の時になって初めて1~4の全てと数字が登場するので4秒後になって初めて位置4まで移動できます。なので今回の場合、最短で位置4まで行くための時間は3であることがわかります。
つまり今回考える設定は至ってシンプルであり、
『初めて1~Xまでの全てが登場するのは配列の何番目の時か』を問われているのです。今回の場合ポイントとなるのは、いかに二重ループを回避してコードを書くかということでした。
アルゴリズ
プログラミング初学者がプログラミング言語と周辺知識の概要を知るための記事
# どのような人向けの記事か
私のような、【駆け出しエンジニアの方やプログラミングに関心のある方、初心者の方】向けにどんなプログラム言語があるのかをざっくりわかるようにゆる〜くまとめたものです。また、備忘録としても投稿しておこうと考えました!※当方も未経験エンジニアの立場で実務未経験であるため、間違いはあると思いますので適宜ご指摘いただければ幸いです。
# なぜ、この記事を記述するに至ったのか
理由としては、3点あります。
・自分自身が今後フルスタックエンジニアを目指しており、さまざまな言語や技術を習得したいと考えているから
・各言語の特徴を知ることで今後の開発等で最適な言語やライブラリ・コンポーネントへの理解が必須であると考えたから
・自分の武器を増やす上で特徴をまずはざっくり理解したいと考えたから# 本編
ここからが本番です!自分自身が記事等で学習したものをざっくばらんに言語化していきます。気になる言語があれば、ご自身でも深く調べてみることで、どんな言語なのか実感できるはずなので是非深掘りして見てくださいね!
### 【注意点】
・言語名の横に(マークアップ言語)と記載
【Python】エクセルの入力内容の読み込みと書き出しをしてみた
## 概要
pythonでエクセルに入力された内容の読み込みと書き出しの処理を作ってみました。## 前提条件
Pythonが既にインストールされていること。## openpyxlの導入
コンソールを開いて下記のコマンドを実行して「openpyxl」をインストールする。
“`
pip install openpyxl
“`## エクセルの読み込み/書き出し処理の実行
作成したエクセルの読み込み/書き出しのプログラムは下記になります。
「テスト用.xlsx」の「シート1」シートを参照するように設定しています。“`py
import openpyxl# 「テスト用.xlsx」を開く
wb = openpyxl.load_workbook(‘./テスト用.xlsx’)# 開くシートを指定
sheet = wb[‘シート1’]#2列、1行目のセルに入力されている内容を読み込む
value = sheet.cell(row=2, column=1).value
print(value)#2列、2行目のセルに「書き込みテスト」を書き込む
sheet.cell(r
Pythonによるキーフレーズ抽出(KPE)アルゴリズムの比較
最近、業務で文章からキーフレーズを抽出するアルゴリズムを選定する機会があったので、その際に調べたアルゴリズム間の比較を簡単にまとめておこうと思います。
## 環境
– Ubuntu 22.04; Intel Core i7 9700K
– Python3.10## 比較したアルゴリズム
すべてアルゴリズムを1から実装はせず、Pythonを使ってパッと試せるアルゴリズムをいくつか試しました。カッコ内はライブラリ名です。自分で中身を書かなくてもこれだけの数のアルゴリズムをライブラリから利用できるのは嬉しいですね。
– YAKE (textacy)
– SGRank (textacy)
– sCAKE (textacy)
– TextRank (textacy)
– RAKE (rake-ja)
– MultipartiteRank (pke)
– PositionRank (pke)
– TopicRank (pke)textacy内のアルゴリズムでは日本語パイプラインとして `ja_core_news_sm` を使いました。
“`bash
python -m spac
DRFのModelSerializerを通して新規登録、更新(create / update)
以下のような構成のTable、ModelSerializerで新規登録、更新する実現するための実装サンプル

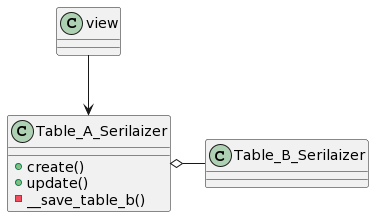
+ Table_A_Serilaizer で create、updateをオーバーライドする
+ オーバーライドした create、update で validated_data から table_b を抜き出す
+ create() では先にTable_A へvalidated_data で createを行い、id を生成してから Table_Bへの save を行う
Django 管理画面でのカスタムフィルター admin.SimpleListFilter
—
## 環境
Windows 11 Home
Python 3.10.2
Django 4.0.2
venv利用あり## 背景
管理画面において、フィルターの名称を変えたりカスタマイズしたフィルターを使用したかった。
例えばBool値のフィルタにおいて、「はい」「いいえ」だけでなく、データ登録されていないものを抽出するために
「はい か いいえ=登録あり」「はいでもいいえでもない=登録なし」といったものを用意したかった。## models.py
“`python:mysite\models.py
from django.db import modelsclass TestModel(models.Model):
class Meta:
verbose_name = ‘テストモデル’
verbose_name_plural = ‘テストモデル’columnA = models.CharField(max_length=30, unique=False, primary_key=True)
columnB =
実際に私が試したブロックチェーン学習素材 | 5つのコンテンツのメリット・デメリットを解説
最近、Web3.0やDAO、メタバース、NFT、スマートコントラクトなどのキーワードをよく耳にします。ブロックチェーンはこれらを支える重要な技術のひとつです。多くの人がブロックチェーン技術の学習の必要性を感じていることでしょう。本記事では、実際に私が学習に活用した5つのコンテンツのメリット・デメリットを解説します。これからブロックチェーンを学習予定の方は、ぜひ参考にしてください。
## ブロックチェーンとは
ブロックチェーンとは複数の取引情報のデータです。複数の取引情報をブロックという単位でまとめ、そのブロックを連結させたチェーンのようなデータ構造を持つため、ブロックチェーンと呼ばれます。ブロックチェーンはその構造上、データの改ざんに強いという特徴があります。また、中央管理者不在で、複数の組織や個人それぞれが同一のブロックチェーンのデータを保持できます。この管理技術を分散型台帳技術と呼びます。分散型台帳技術は、NFT、スマートコントラクト、仮想通貨などの取引記録に活用されています。これらの次世代技術が複合的に活用されるメタバース空間や、新時代の包括的なWeb概念であるWeb3.0
Pythonで.envファイルから環境変数を設定する
# はじめに
.envファイルから環境変数を設定し、その後環境変数を取得し、
GitHubにコミットする際に、APIキーやユーザID・パスワードなどを含めてコミットしないように
.envファイルに外出しして、.gitignoreファイルで.envファイルをコミットしない点をまとめた# 前提
pip3がインストールされていること
Python3がインストールされていること# 環境変数の設定〜取得方法
1.「.env」ファイルを作成し、隠したい情報を設定する
(例)
“`.env
username=”taro”
password=”sampletaro”
“`2.ターミナルを開いてモジュールをインストールする
“`
pip3 install python-dotenv
“`3.Pythonを開いて下記を記載する
“`python
from dotenv import load_dotenv
load_dotenv()
“`
これで.envファイルに記載したものが環境変数に設定できました4.環境変数を取得します
“`python
import osuse
pyenvで.python_versionを設定していてもPythonのバージョンが切り替わらないとき
「pyenvで`.python_version`を設定していてもPythonのバージョンが切り替わらないとき」とはこんな時です。
“`sh
$ ls
.python_version$ cat .python_version
3.9.8$ pyenv global 3.9.8
$ python -V
Python 3.10.3
“``pyenv versions`を実行します。
“`shell
$ pyenv versions
system
2.7.13
3.10.1
* 3.10.3 (set by PYENV_VERSION environment variable)
3.6.4
3.9.8
$ $PYENV_VERSION
zsh: command not found: 3.10.3
“`環境変数`PYENV_VERSION`に`3.10.3`が設定されていました。これをpyenvが優先して読み込んでいるようです。この環境変数を
condaでopencvをinstallすると「ImportError: DLL load failed: 指定されたモジュールが見つかりません」
何度か躓いている気がするので、解決策をメモ。
# やりたいこと
pythonでopencvを使いたい# 詰まったこと
検索して出てくる記事を参考に下記コマンドでopencvをinstallして`import cv2`をすると、「ImportError: DLL load failed: 指定されたモジュールが見つかりません」とエラーになる。
`conda install -c conda-forge opencv`# 解決策
pipで入れたらどうにかなる。(condaでpip使うなというのはあるが、どうしてもcondaだけでは解決できなかった)
`pip install opencv-python`# 補足
詳細は不明だが、他の仮想環境にconda installで入れたopencvが残ったままだとエラーが継続していた。
キャッシュを利用している?
pipでうまくいかなかったら、他仮想環境のopencvをuninstallするか、仮想環境ごと一回消すとよいかもしれない。
※仮想環境を消すと当然他のライブラリも消えるので、問題ないかを良く確認してから消すこと!
PythonとSQLiteを使ってみた
仕事ではJavaやJavaScriptが多いですが、個人的にはpythonが好きです。
pythonの現場に行く機会があった時にできるようになっていたいなあとなるべく毎日勉強しています。今回はpythonに標準であるSQLiteを使って基本的なことをやってみました。
まず、DB作成からテーブル、データのinsertまで。“`
import sqlite3#データベースファイルを作る
dbfile = sqlite3.connect(‘fruit.db’)
c = dbfile.cursor()createSql = ‘create table FruitName(id,name);’
c.execute(createSql)insertSql = “insert into FruitName(1,’Apple’);”
c.execute(insertSql)dbfile.commit()
dbfile.close()
“`
作成したテーブル内のデータを表示するためのソースがこちら
“`
import sqlite3connectDb = sqlite3




