
- 1. 【Python】pandas.read_csvの列指定
- 2. 【Python】”和え麺” 屋さんの券売機のボタンが “油そば” だった事件
- 3. Juman++をインストールしてpythonで使える環境を作る(pyknp,MacOS,homebrew)
- 4. Outlookから日報メールを取得してネガポジ判定をしてみた。
- 5. Vision Transformerでダーツの自動計算をやってみる
- 6. Python:statsmodelsパッケージを利用して簡単に最小二乗法を実現する方法
- 7. TensorFlow を低コストのサーバレス(AWS SAM)で実行する
- 8. Markdownを設定ファイルとして活用する(FrontMatterの活用)
- 9. DiscordBot色厳選くん
- 10. pickleを利用した際のFlagPrinterエラー
- 11. リストと辞書型 (小学生高学年向け・python)
- 12. 【Pytorch】コロナウイルスの感染者数をLSTMで予測する
- 13. numpy 行列の積: 備忘録
- 14. python mapを使った置換 pandas
- 15. Blenderでmidiから自動演奏ピアノっぽいアニメーションを作成するPythonスクリプト
- 16. pythonのいろんな書き方 pep8を見て
- 17. 【Django】ページをPDF出力する(オプション)【Python】
- 18. pythonでwordleを作成
- 19. YOLOv5の学習時に指定可能なオプションについての解説
- 20. Pythonでウェブサイトから東方のセリフを抽出する
【Python】pandas.read_csvの列指定
# 概要
pandasでcsvを読み込むときの列指定方法。
データ分析の際、データが大きいかつ不要なカラムが多い時はこれを使うと読み込み速度が大きく変わる。https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
# データ
“`python
df = pd.read_csv(“example.csv”)
print(df)# a,b,c,d
# 1,20,2,100
# 2,30,3,200
# 3,10,1,300
“`# 書き方①
`usecols`オプションを指定する。
このオプションで指定したカラムのみを読み込む。
カラムをintで指定することも文字列で指定することもできる。
“`python
df = pd.read_csv(“example.csv”, usecols=[0, 2])
print(df)# a c
# 0 1 2
# 1 2 3
# 2 3 1df = pd.read_csv(“example.csv”, usecols=[“a”
【Python】”和え麺” 屋さんの券売機のボタンが “油そば” だった事件
## 概要
タイトルのとおりです。券売機を前にとまどいを隠せなかったです。
そんなやりきれない思いを、Pythonで再現してみました。## コード
“`python
# 2022/08/02 “和え麺” 屋さんの券売機のボタンが “油そば” だった事件okane = 1000
menus = {“油そば”:750, “鶏ラーメン”:800, “塩ラーメン”:800}def show_menu():
print(“=====おしながき=====”)
for menu in menus:
print(” {}:{}円”.format(menu,menus[menu]))
print(“=====================\n”)show_menu()
while True:
want = input(“何を食べる? >>>”)
if want == “”:
pass
elif want in menus.keys():
print(want + “を注文した!”)
Juman++をインストールしてpythonで使える環境を作る(pyknp,MacOS,homebrew)
# Juman++をインストールしてpythonで使える環境を作る
とても精度のいい形態素解析ツールであるJuman++をインストールしてpythonから呼び出して使えるようにしていきたいと思います。
今回はhomebrewとpythonの環境があることを前提としています。
もしできていない人がいれば[こちら](https://qiita.com/TakayoshiK/items/e4273336044880d3eea0)の記事を参考にしてみてください。## 環境
MacBook Pro (13-inch, 2018)
macOS Monterey Version 12.5
メモリ intel Core i5
zsh 5.8.1 (x86_64-apple-darwin21.0)pythonはhomebrew、pyenv経由で環境構築しています。
## Juman++のインストール
早速juman++をhomebrewを使ってインストールしていきましょう。
“`:terminal.app
user@host $brew install jumanpp
“`
入ったか確認
Outlookから日報メールを取得してネガポジ判定をしてみた。
# ■概要
テキストデータのネガポジ判定の手法を学んだので、
試しに昨年新卒入社した時の日報でネガポジ判定を行ってみました。
書いたソースコードの紹介と共に、
「日報の提出時間が遅くなるにつれて、所感部分の文字数が減り、またPN値も下がるのでは」
という疑問を解明して参ります。# ■環境
OS: Windows10
言語: Python 3.10.4
IDE: Visual Studio Code (バージョン 1.69.2)# ■分析の流れ
以下の手順で日報データの分析を行いました。
1. Outlookのフォルダから自分の送った日報のデータを取得、CSVファイルとして保存。
2. CSvファイルを読み込んで、DataFrameの整形
3. 極性辞書の読み込み、PN値の算出
4. 外れ値の処理
5. データ可視化1,2
6. 結果と考察# ■ソースコード紹介
では早速、用いたコードを紹介して参ります。## 0.モジュール、オブジェクトのインポート
“` python
import win32com.client
import re
import pandas as
Vision Transformerでダーツの自動計算をやってみる
## ダーツ練習用ボード買っちゃった
最近、10年振りに友達とダーツしたんだけど、めっちゃ楽しくて、もっと上手くなりたい!と思って、その日の夜、練習用ボードをAmazonで購入しました。こんな感じで自室にセッティングしてやってます。静音タイプのボードなので、夜でもやれます。
でもね、やっぱり自動計算できてゲームできると楽しいよね?
でもね、自動計算できる機能付きボードは相当高いんよね・・・。
AI使って、ダーツが刺さったところを認識できれば、点数計算ソフト作れるな・・・。というわけで、やってみることにしました。
## 撮影環境
まずダーツボードから手前に130cm、左に60cmのところに高さ160cmでWebカメラを設置。
を簡単に実現する方法がありましたので、備忘として書きます。# テストデータ
今回はseabornパッケージからIris(あやめ)のデータセットを使って、テストデータとします。“`python
import seaborn as snsiris_data = sns.load_dataset(‘iris’)
iris.head()
(実行結果)
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1
TensorFlow を低コストのサーバレス(AWS SAM)で実行する
## はじめに
以前、 SAM を使って TensorFlow をサーバレスで実行する方法について記事を書きました
ざっくり言うと、超低コストで AI を動かそう、と言うことです
https://qiita.com/RyoWakabayashi/items/0734f7f0a76a5dad3770
しかし、その時から SAM がバージョンアップして、 `sam init` のときの質問などが変わってしまいました
また、最終的に出来上がったコードを GitHub に上げていなかったため、今どうすればいいのか少し迷子になりました
というわけで、改めて TensorFlow を SAM でビルド、デプロイする方法とコードをまとめておきます
実装コードはこちら
https://github.com/RyoWakabayashi/tensorflow-lambda
今回は `sam init` ではなく、このリポジトリーのコードを使ってデプロイする手順を紹介します
Lambda と SAM の解説は過去の自分に任せます
– [Lambda とは](https://qiita
Markdownを設定ファイルとして活用する(FrontMatterの活用)
## はじめに
何かソフトウェアを作ったとき、メモ帳などでソフトの振る舞いを簡単に変えられるようにすることは多いです。
昔だと`xxxxx.ini`みたいなファイルに設定が書いてあったり、今だとJSON使って設定を記述して、ソフトの振る舞いを変えられるようにしています。しかし、そこでいつも問題になるのは、**設定ファイルの変更手順が設定ファイルに直接書けない**というところです。
以下のような努力である程度は解決しますが、不足する場面があります。
[Pythonでコメント付きのJSONファイル(JSONC)を読み込む](https://qiita.com/koppe/items/f27be003726b03304b24)## 何が不満なのか?
簡単なソフトを作って配布する場面が増えてきました。
そして、人に渡すならドキュメントが必要です。### 設定ファイルを弄りたいユーザーの立場
– 設定ファイルの書き方、どこにあったっけ?探すの面倒。
– なんかコメント書いてあるけど、これだけじゃ分からん。しかも長すぎて読む気がしない!
– え?なに?詳細は別のエクセルファイルを見ない
DiscordBot色厳選くん
# 色厳選くんとは・・・
Discordのチャットでポケモンの色厳選ができるBotです。# 仕様
### エンカウント
“e” とメッセージを送ると、選択中のポケモンにエンカウントします

### 確率を変更
確率はサーバーおよびDMごとに保存されます。
“.” + n(整数) とメッセージを送ると、色違いに遭遇する確率を1/nに変更します。
デフォルトは1/8192です。

### ポケモンを変更
ポケモンはサーバーおよびDMごとに保存されます。
今のところはNo.151まで対応しています。
“;”
pickleを利用した際のFlagPrinterエラー
## エラー
pickleでdumpされたファイルを開こうとした際に
~~~
AttributeError: Can’t get attribute ‘FlagPrinter’ on
~~~
のようなエラーがでた。## 解決策
~~~python3
class FlagPrinter:
pass
~~~
と記述を加えることで解決した。
リストと辞書型 (小学生高学年向け・python)
# リストの使い方まとめ + dictionary(辞書)型
皆さん電子辞書って持ってますか?先生は高校入学と同時に買ってもらった覚えがあります。 
あれ、今のはどうかわかんないですが、昔のヤツでOS(パソコンのベースになるソフト)を入れて、いろいろ遊ぶことができたんですよ。ファミコン(知ってる?)世代のゲームを入れて授業中遊んだり、よくやってました。今はもう電子辞書どころかタブレットを配ってるわけですから、すげー時代になったもんだと思うわけです。ただ、そんなことばっかしてるとリッキーみたいになっちゃうよ。
# リストってなんだっけ
次のコードを見てみましょう。単純に変数の中身を表示していますが、varという変数に、5と10の数字が代入されているのに、10しか表示されていません。
“`python
var = 5
【Pytorch】コロナウイルスの感染者数をLSTMで予測する
# はじめに
何番煎じかという感じですが、PytorchにおけるLSTMの扱いに習熟する為、コロナウイルス陽性者数の予測を行います。
初めに全国の過去の感染者数から、将来の全国の感染者数を予測します。
その後、各都道府県の過去の感染者数から、将来の全国の感染者数の予測を行います。# LSTM
LSTMの構造については以下のリンクが分かり易いかと思います。
[Understanding LSTM Networks](http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
[LSTMネットワークの概要(上記リンクの翻訳)](https://qiita.com/KojiOhki/items/89cd7b69a8a6239d67ca)ざっくり説明するとLSTMはRNN(Recurrent Neural Network)の進化系です。
RNNは通常の全結合型ニューラルネットワークと異なり、ニューラルネットワークの出力を別のネットワークの入力として利用することから、Recurrent(回帰性の)という言葉が当てられています。
L
numpy 行列の積: 備忘録
# 初めに
einsumを使うため、行列の演算を整理しておく。
# 基本操作
## matrix generation
“`python
import numpy as np
mat = np.array([[1,2],
[3,4],
[5,6]])array([[1, 2],
[3, 4],
[5, 6]])
“`## inverse matrix
“`python
mat = np.array([[1,2],
[3,4],
])
mat_inv = np.linalg.inv(mat)array([[-2. , 1. ],
[ 1.5, -0.5]])“`
## pseudo inverser matrix
“`python
mat = np.array([[1,2],
[3,4],
python mapを使った置換 pandas
dataframeの値を置換する
sex_dictを作って、置換する組み合わせを作成する。
dataframeの中の性別をmapを使用して文字に置換する。“`python
import pandas as pdsex_dict = {1:’男’,2:’女’,3:’出生前’,4:’不明’}
df = pd.DataFrame(
data ={‘年齢’: [10, 20, 30, 40],
‘性別’: [1, 2, 1, 3],
‘列3’: [‘a’, ‘b’, ‘c’, ‘d’]}
)print(df)
#=>
年齢 性別 列3
0 10 1 a
1 20 2 b
2 30 1 c
3 40 3 d#map使用
df[‘性別’] = df[‘性別’].map(sex_dict)print(df)
#=>
年齢 性別 列3
0 10 男 a
1 20 女 b
2 30 男 c
3 40 出生前 d
“`参考:
https
Blenderでmidiから自動演奏ピアノっぽいアニメーションを作成するPythonスクリプト
## 1. はじめに
blenderでmidoを使用してmidiを読み込み、ピアノっぽいオブジェクトと自動演奏っぽいアニメーションを生成するPythonスクリプトの解説です。
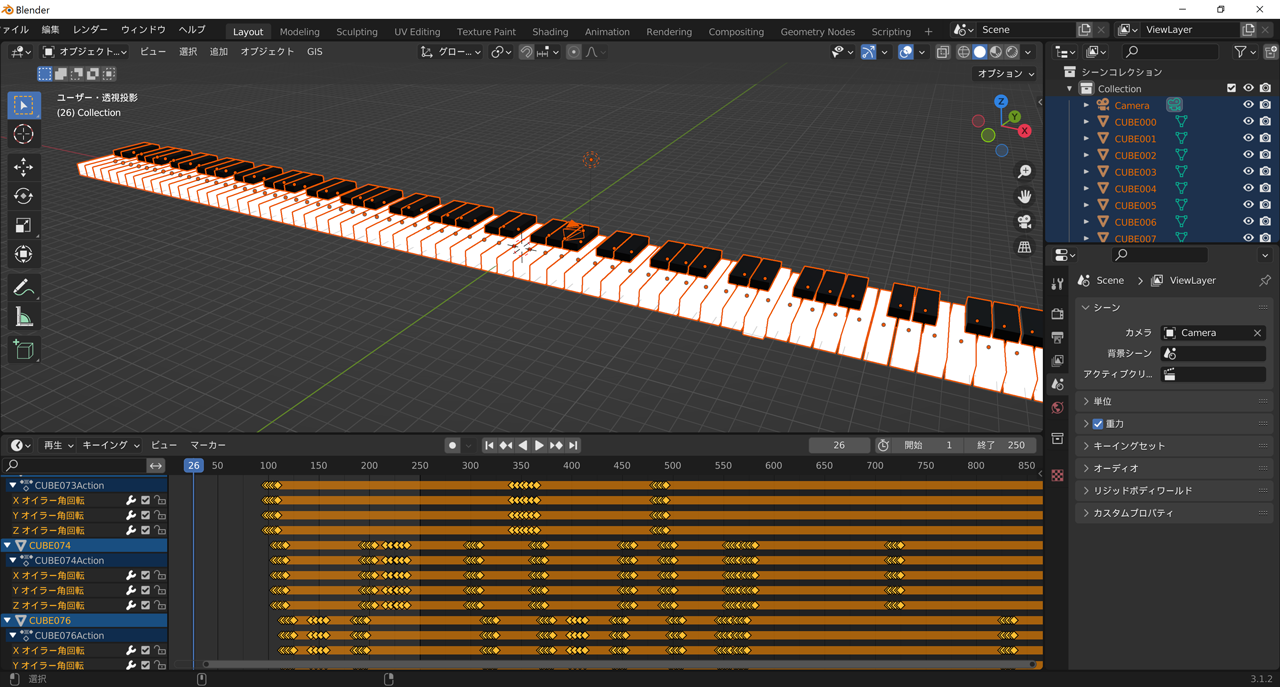
今回はスクリプトを簡略化するため1つのchannelのnote_on情報のみを使用していますが、正確にする場合すべてのチャンネルとnote_offやvelocityの値も使用する必要があります。ピアノ生成部分は急ごしらえなので、あまりじろじろ見ないでください。
## 2. 準備
### Pythonライブラリmidoのインストール
pip install midoでmidiファイルを読み込むためにblenderのPythonにmidoをインストールします。
公式ドキュメントはこちらです。https://mido.readthedocs.io/en/latest/i
pythonのいろんな書き方 pep8を見て
pep8を見て少しだけ、自分の記述と違うところがあったので書き方を学ぶ。
## 1レベルインデントするごとに、スペースを4つ使いましょう。
これまでは、エディタでenterを押すと勝手に2スペース開けてくれていたが、4スペース入れた方が良い。
少し不思議な感じ“`python
#これまで
def test():
return 1#pep8
def test():
return 1def test(
var1,var2
var3):
print(11)def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
“`## すべての行の長さを、最大79文字までに制限しましょう。
どうしてもif文の条件が多くなってしまうことがありますが、そういった場合には折り返しを行い長くならないように調整。## 1行にまとめすぎない
多分文法的にどちらも正しいのだろうけど、見やすいのは正しい
【Django】ページをPDF出力する(オプション)【Python】
# 初めに
※以下の記事の続きです。未読の場合は先に目を通してください。
[【Django】ページをPDF出力する【Python】](https://qiita.com/nagisa_O/items/3eaaa18d68468e8de7e5)前回、Djangoで作成されたWebアプリケーションのページの最も簡単なpdf出力をまとめました。
今回はpdfkitで指定できるオプションを検証します。# 環境
|名称 |バージョン |
|—|—|
|Python |3.10.4 |
|Django |4.0.6 |
|pdfkit |1.0.0 |# 書式指定
pdfkitのオプションは辞書型のオブジェクトで設定できます。
そして引数の「options」を指定してオブジェクトを渡します。
前回のpdf出力関数にオプション設定部分を追記しました。
“`php:views.py
def to_pdf(request):
url = ‘http://127.0.0.1:8000/test_app/’
options = {
‘
pythonでwordleを作成
## wordleとは?
https://www.nytimes.com/games/wordle/index.html
ワードル?ウードル?
5文字の英単語を当てるゲームです。>プレイヤーは6回の試行の間に5文字の英単語を推測する。推測の度にタイルの色が変化することでユーザーに情報が与えられ、正答の単語において推測した各文字が正しい位置にあるか、あるいは別の位置に存在するかが明らかにされる。(wikiより)
むずかしそうだったが、以外と仕組みだけは簡単でしたね。コードを写経したのですがね……..
## Richを使用
richというターミナルに色付けしてくれて、鮮やかにしてれるライブラリをinstallfrom words import word_listは別ファイルを作成して、取り入れています。
これは、5文字の単語の羅列でランダムな正解の単語をここから選出します。## 多分肝はここ
enumerateを使って、index番号と一緒に回す。
完全合致で、correct_place
一部一致(場所は違えど正解に含まれている文字)で、correct_lette
YOLOv5の学習時に指定可能なオプションについての解説
# 目的
YOLOv5の学習時に指定可能なオプションについて解説すると共に、理解をする。
# 背景
YOLOv5?の学習時に指定可能なオプションについての理解が不足していたのと、実際にどういった動作となるのか解説を見てもわからないことが多かったため、YOLOv5への理解を深める意味も含め、公式資料やソースコードを確認し動作を整理したいと思った。
# 前提条件
YOLOv5下記断面のソースにて調査
https://github.com/ultralytics/yolov5/tree/3e858633b283767f038b4cab910a95e40fe8577b
# 学習時(train.py実行時)のオプション一覧
|オプション名|説明|
|:-|:-|
|–weights|学習時のモデルを指定します。|
|–cfg|モデル構成を指定します。|
|–data|データセット構成を指定します。|
|–hyp|ハイパーパラメータを指定します。|
|–epochs|エポック数を指定します。|
|–batch-size|バッチサイズを指定します。|
|–imgsz,-
Pythonでウェブサイトから東方のセリフを抽出する
# この記事でやりたいこと
+ 東方作中のセリフをまとめているサイト[Radical Discovery](http://radical-d.extrem.ne.jp/index.html)からセリフをいい感じに抽出する。
+ いい感じとは、
1. dialoguesディレクトリを作成する。
2. その中に、dialogue_n.txt(nは整数)を作成する。
3. そのファイルに、[キャラ名:セリフ]の形式で一文ずつ書き出す。
+ 話題の分かれ目は何もない行を挿入する。
+ こうすると他のプログラムからデータを扱いやすい。
+ です。かなり雑に組まれているのでコード自体は汎用性は低いです。
# まずはソースから
“`Python:vacuum_data.py
import requests
from bs4 import BeautifulSoupdef main_soup_from_url(url):
response = requests.ge




