- 1. 0. 目次
- 2. 1. 概要
- 3. 2. 環境情報
- 4. 3. 作成方法
- 4.0.1. pythonでDunnett’s test
- 4.0.2. WindowsのPythonでデスクトップ通知(トースト)作ってみた【WinRT】
- 4.0.3. GINZAで形態素解析してWordCloud出力[少女地獄]
- 4.0.4. Colab メモ
- 4.0.5. データサイエンスで犯罪者を捕まえる
- 4.0.6. 機械学習、Python、GridDBを用いて通信事業者の解約率を予測する
- 4.0.7. PythonとGridDBを用いて住宅データの線形回帰モデルを構築する
- 4.0.8. PythonとGridDBを用いたLDAによるトピックモデリング
- 4.0.9. scikit-learnを使った機械学習
- 4.0.10. PythonでのSeleniumを使ったWEBサイト操作
- 4.0.11. (後編) 運営している家計簿サービスに新機能を搭載して大幅リニューアルしました
- 4.0.12. anyenv+pyenv+poetryでPythonの環境構築
- 4.0.13. 【トリビアのDelta Lake】#8 Pysparkで、Dataframe内の値を省略せず全表示させたい
- 4.0.14. 初めて公開Webサービス作ってみた奮闘の記録
- 4.0.15. Pythonでテキストアナリティクス 〜『テキストアナリティクス入門』に沿い共起ネットワークなど描いてみた〜 Part2:複合語編
- 4.0.16. Ubuntu22.04 MySQL+mysqlclient+Django+Django REST frameworkで簡単なAPIサーバを作る
- 4.0.17. TensorFlowのチュートリアルをGPUで動かす(MNIST)
PostmanからPythonのpost処理に飛ばす(formのPostman版)
# Postman側での送信内容
今回は問い合わせ内容をpostする。形式はjson形式で送信する。
“`
{“name”:”メガネ”,”company_name”:”株式会社暴力反対”,”mail_adress”:”@gmail.com”,”title”:”剛田武”,”body_text”:”やばくね”}
“`
# python側での受け取りのコード
“`python:qiita.py
@app.route(‘/’, methods=[‘GET’, ‘POST’])
def form():
if request.method == ‘POST’:
name = request.json[“name”]
company_name = request.json[“company_name”]
mail_adress = request.json[“mail_adress”]
title = request.json[“title”]
body_text = request.js
モンテカルロ法を理解しやすいコードで書く
# はじめに
初記事で拙いところがあると思いますが、ご容赦ください。
コードは[Github](https://github.com/Tomoro0726/Monte)にあります。
# 実行環境
Python 3.8.5(‘base:’conda)
[Anaconda](https://www.anaconda.com/)の実行環境を導入している。# 基本原理
N回シュミレーションを行ったときある事象がM回起これば、
その事象が起こる確率はM/Nで近似されるという性質を持っているということがモンテカルロ法の原理。
# 観測方法
1×1のXY平面上に原点から半径1の90度の弧を描いてランダムに点を打って
弧の外側と内側の点の個数の割合から円周率を求める。
# コードの実装
“`python:monte1.rb
import random
import numpy
import timestart = time.time()
trial = 100
#試行回数
x = []
y = []
true = 0
false = 0
for i in range(trial
Lambdaのpython Layer(simple_salesforce)作成
0. 目次
- 概要
- 環境情報
- 作成方法
1. 概要
Lambdaのpythonを使用してSalesforceへの処理を実装したいので、pythonのSalesforceモジュールである『simple_salesforce』をimportするためにLayerを作成します。
2. 環境情報
pythonは、バージョン3.8を使用します。
Lambdaのpythonバージョン3.8はAmazon Linux2上で動作しているので、Amazon Linux2のEC2インスタンス上でLayerを作成します。詳細に関しては、Lambda ランタイムを参照してください。
3. 作成方法
1. EC2インスタンス作成AmazonpythonでDunnett’s test
# はじめに
本記事は以前の記事(https://qiita.com/mosomoso_1910/items/101783b4e59446d00d42)の改訂版となります。
(凡ミスで計算違いしてました。。。あと無限大の積分でもそこまで計算速度は変わらなさそうなので式のままにしています)Backgroundはそこらへんの製薬企業で働いている基礎研究者なので統計学的知識もプログラミングも独学のみです…
生暖かい気持ちで読んでいただけると幸いです。## Dunnett’s test
生物系研究ではよく**Student’s t testを行い、有意差を示したい**ということがありますね([有意差という表現をなくすべき](https://www.nature.com/articles/d41586-019-00857-9)というのはまた別の機会に…)。多群間で評価を行う場合は多重性の問題が起こるため、Tukey-HSD testなどを使う機会が多いです。
Dunnett’s testも多群の対比較の検定のひとつで、すべての対比較を行う必要がなく、**コントロール群(や対照群)と他WindowsのPythonでデスクトップ通知(トースト)作ってみた【WinRT】
win10toastを使っているのですがWin32のため、WinRTで実装してみました。シングルファイルモジュールで作ってみました。
https://github.com/GitHub30/win11toast
[](https://badge.fury.io/py/win11toast)[](https://badge.fury.io/py/win11toast)
## インストール“`bash
pip install win11toast
“`## 使い方
“`python
from win11toast import toasttoast(‘Hello Python?’)
“`という本を選んで実行すると以下が出力されます。本は、全く読んだことも聞いたこともなくタイトルから中身がまるで想像できなかったものを選びました。病院で手術が関係しているという店だけがわかりました。
# 環境
Python3.7.13でGoogle Colaboratory上で動かしています。基本はGoogle Colabプリインストールされているパッケージはそのまま使っています。
`spacy`はGINZAとの互換性の関係で3.2.4にダウングレードしています。|Package|Version|備考|
|:-:|:-:|:-:|
|spacy|3.Colab メモ
# seet→df
“`python
!pip install gspreadfrom google.colab import auth
from google.auth import default
import gspreadauth.authenticate_user()
creds, _ = default()
gc = gspread.authorize(creds)url = ‘https://docs.google.com/spreadsheets/d/file’
worksheet = gc.open_by_url(url).get_worksheet(0)
df = pd.DataFrame(worksheet.get_all_values())
df.columns = list(df.loc[0, :])
df.drop(0, inplace=True)
df.reset_index(inplace=True)
df.drop(‘index’, axis=1, inplace=True)
“`# JSONL→df
“`python
dfデータサイエンスで犯罪者を捕まえる
データサイエンスの力は、技術やビジネスの課題解決にとどまりません。その使い道は、新しい技術を生み出すためのデータ分析、消費者に向けた広告、ビジネスにおける利益や売上の最大化などにとどまりません。オープンサイエンスのコンセプトにより、組織はデータを使って社会問題を処理するようになりました。人間の隠れた行動や文化的パターンに対して、統計的かつデータ主導の解決策を提供することが出来るのです。
[ 記事の全コードはこちら][1]
我々は、サンフランシスコの犯罪部門のデータを使って、市民が報告する犯罪事件と、警察が報告する犯罪事件の関係を理解します。そして大量のデータを保存し、容易にアクセスできるようにするため、データベースプラットフォームとしてGridDBを使用します。
## GridDBを使ったデータセットのエクスポートとインポート
GridDBは拡張性の高いインメモリデータベースであるため、並列処理により高いパフォーマンスと効率性を実現することが出来ます。GridDBのpythonクライアントを利用することで、GridDBとpythonを簡単に接続し、リアルタイムにデータのインポー
機械学習、Python、GridDBを用いて通信事業者の解約率を予測する
顧客解約率とは、特定の企業との取引を停止する顧客の数を決定する重要なビジネス概念です。解約率は、企業が一定の期間に顧客を失う割合と定義されます。例えば、解約率が年15%であれば、その企業は毎年総顧客数の15%を失っていることになります。通信業界では、競争の激化や新規通信事業者の出現により、顧客離れが特に重要視されています。このため、通信業界では毎年高い解約率が予想されます。
> 通信業界の解約率は毎月約1.9%であり、毎年67%まで上昇する可能性があります。([出典][1])
これは顧客維持率に直接影響するため、企業にとって非常に慎重に検討すべきリスクです。
> 同記事によると、通信業界では新規顧客獲得コストは顧客維持コストの25倍であり、このことも解約率を決定的にする要因の一つです。
高度な機械学習アルゴリズムは、継続率のようなビジネスコンセプトと連携し、ビジネスインテリジェンスソリューションを提供します。この記事では、広範かつ詳細なデータセットを用いて、通信業界における解約率を予測するモデルについて説明します。この目的のために、Python、GridDB、機械学習アルゴリズ
PythonとGridDBを用いて住宅データの線形回帰モデルを構築する
このチュートリアルでは、Pythonを使用して住宅データセットを調査します。まず、必要に応じてデータセットのプルーニングを行います。その後、データセットに適合する機械学習モデルを構築し、将来の予測を行う方法を見ます。
チュートリアルの概要は以下の通りです。
1. 前提条件
2. データセットについて
3. ライブラリのインポート
4. データセットの読み込み
5. データの前処理
6. データの正規化
7. データセットの分割
8. モデルの構築
9. 予測する
10. モデルの評価
11. 結論## 1\. 前提条件
このチュートリアルは、Jupyter Notebooks (Anaconda version 4.8.3) と Python version 3.8 on Windows 10 Operating system を使用して実行されています。実行前に以下のパッケージがインストールされている必要があります。
1. [Pandas][1]
2. [scikit-learn][2]Anaconda を使用している場合、パッケージはユーザーイ
PythonとGridDBを用いたLDAによるトピックモデリング
自然言語処理において、トピックモデリングは与えられたコーパスに含まれる単語を基にトピックを割り当てます。テキストデータはラベル付けされていないため、教師なし技法です。データに溢れる現代において、文書をトピックに分類することの重要性はますます高まっています。例えば、ある企業が何百件ものレビューを受け取った場合、どのカテゴリのレビューが最も重要なのか、逆にどのカテゴリのレビューが重要ではないのかを知る必要があります。
キーワードと同様に、トピックは文書を記述するために使われます。例えば、経済に関するトピックといえば、株式市場、米ドル、インフレ、GDPなどを思い浮かべるでしょう。トピックモデルとは、文書中に現れる単語をもとに、自動的にトピックを検出できるモデルのことです。ここで取り組む問題は、トピックモデリングになります。
`LDA – (Latent Dirichlet Allocation)`
Latentとは、隠された、まだ発見されていないものという意味です。Dirichletで示されるように、文書中のトピックや単語パターンの分布はDirichlet分布が支配していると想定されま
scikit-learnを使った機械学習
## はじめに
scikit-learnのバージョンについて、教科書に記載の環境(0.19.1)と私の環境(1.1.1)が結構違っていたので調べながら勉強しました。
内容が多くて少し心が折れましたが、機械学習の基本的なところなのでかなり参考になりました。https://www.shoeisha.co.jp/book/detail/9784798158341
## データの前処理
### 欠損値の補完
データフレームの欠損値を補完するにはpandasのfilnaメソッドを使う方法がありますが、
scikit-learnでも同様のことができます。
以下は欠損値のあるデータフレームを作成して、SimpleImputerを使って補完しています。“` python:in
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputerdf = pd.DataFrame(
{
‘A’:[1,np.nan,3,4,5],
‘B’:[6,7,8,npPythonでのSeleniumを使ったWEBサイト操作
個人的備忘録です。
自社の申請システムで入力がいつも同じなので使ってみました。# 準備
## Webドライバーのダウンロード
自動操作したいWebブラウザのWebドライバを用意する。
ChromeならChromeの。EdgeならEdgeのWEBドライバーが必要。
### 重要
1. ブラウザのバージョンに対応したバージョンのドライバーが必要
1. EdgeのWebドライバーは32bitを使った方がよい。(64bitは不具合多めという話を聞いたことがある。)## 実装
### 基本的な流れ
1. URLアクセス
1. 操作したい要素を探索・選択
1. 操作(入力やデータの収集など)
### URLアクセス
ブラウザによりimportモジュールが違うため注意(以下はEdge)
~~~python
# import
from selenium import webdriver
from selenium.webdriver.edge import service as fs # edgeウェブドライバ# Edgeドライバの作成
service = fs.Service(exec(後編) 運営している家計簿サービスに新機能を搭載して大幅リニューアルしました
前編の記事では、リニューアル経緯や新機能の紹介を主にしました。後編ではSUMUMAで使われている技術の知識や、開発環境などについて紹介していきます。
技術知識や開発ノウハウのインプットとしてや、これから個人開発を考えている方など多くの方の役立てたらと思います。前編をまだお読みになっていない方は、ぜひご覧ください!
[(前編) 運営している家計簿サービスに新機能を搭載して大幅リニューアルしました](https://qiita.com/uichi/items/4fc5b221c5b6466d4a1b)前編で既に紹介済みですが、もう一度SUMUMAのリンクを共有させていただきます。
[SUMUMA](https://sumuma.com/lp/general/)
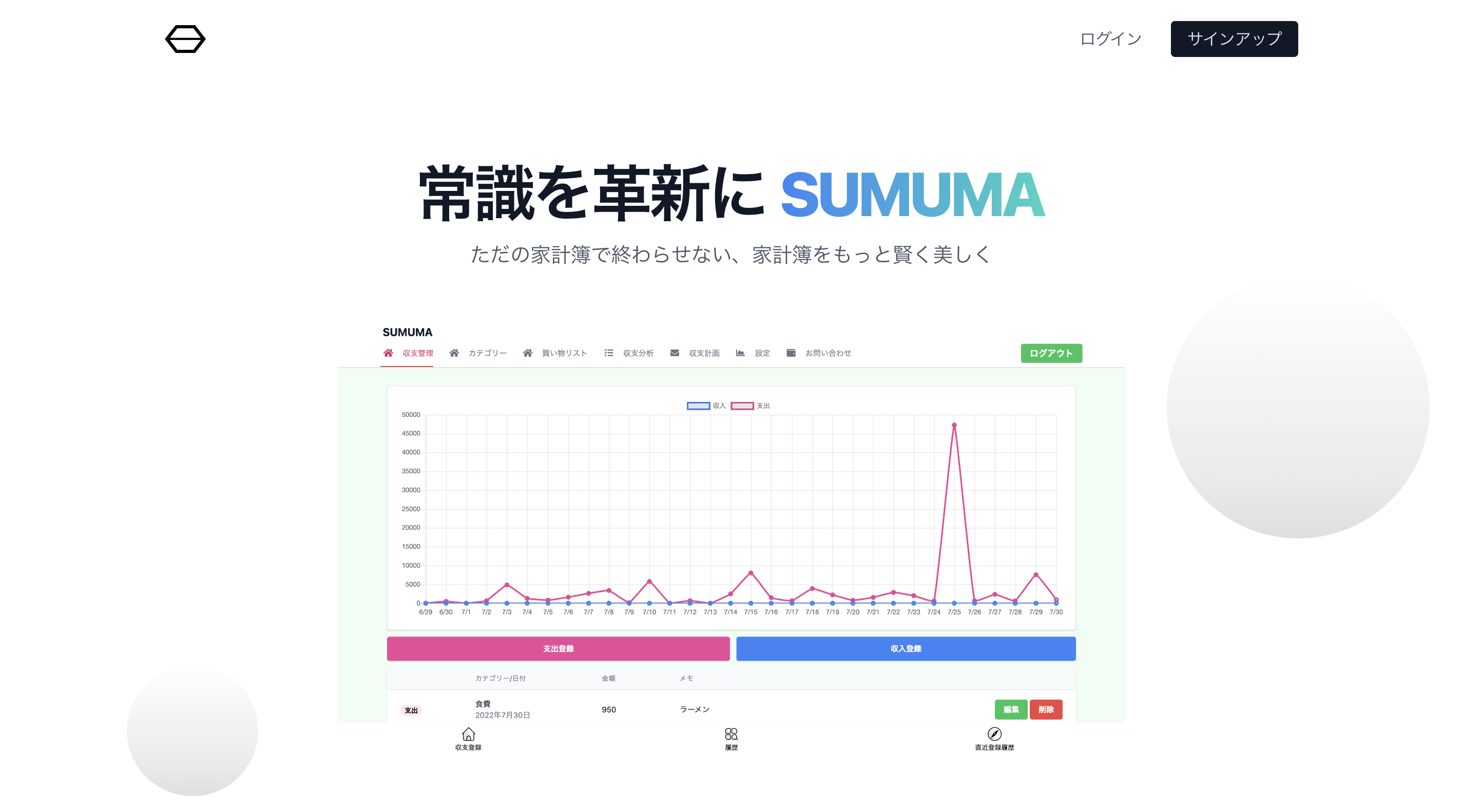# SUMUMA開発の技術スタ
anyenv+pyenv+poetryでPythonの環境構築
## はじめに
Pythonの環境構築を行ったので、インストール手順と各ツールの操作方法をまとめました。
備忘録ではありますが、誰かのお役に立てば、、、
## 実行環境と前提条件
* 実行環境
* OS: macOS
* shell: zsh
* 前提条件
* Homebrewがインストール済みであること## 各ツールについて
#### anyenv
– **env系ツールを管理するツール。今回はpyenvのインストールに使用しました。
– anyenvのアップデート用plugin
– anyenv-update(https://github.com/znz/anyenv-update)
– GitHub: https://github.com/anyenv/anyenv#### pyenv
– Pythonのバージョン管理ツール。
– GitHub: https://github.com/pyenv/pyenv#### poetry
– パッケージ管理+仮想環境構築ツール。
– GitHub: https://g【トリビアのDelta Lake】#8 Pysparkで、Dataframe内の値を省略せず全表示させたい
Google ColabなどでPysparkを動かし、Dataframeの中身を確認したいとき。
“`Python:show_dataframe.py
.show()
“`
で見ることになりますが、カラム内の値が長いと、このように省略されてしまうことも。
“`Python:show_dataframe_2.py
df_include_json = spark.createDataFrame([
(1, ‘{“year”: 2021,”rank”:”junior”}’),
(2, ‘{“year”: 2022,”rank”:”senior”}’)],
[“no”, “value”]
)
>>>
+—+——————–+
| no| value|
+—+——————–+
| 1|{“year”: 2021,”ra…|
| 2|{“year”: 2022,”ra…|
+—+——————–+初めて公開Webサービス作ってみた奮闘の記録
## はじめに
先日、初めて公開Webサービスを作ってみた。
[【個人ブログのためのSEOツール】キーワードの重要度比較](https://inmylife65.net/extract-rival-keywords/)
ブログのSEO対策ツールで、自分のURLと競合ページのURLを入力するとそれぞれのページに含まれるキーワード別の重要度がわかる、というものだ。

これ、このページの下の方に書いた通り、いろんなライブラリの寄せ集めで、ぼくは何も難しいことをしていないんだけど、何しろ初めて公開Webサービスを作ったので、色々試行錯誤があった。
だれもがはじめて作るときは初心者だ。
初心者には初心者なりの悩みがある。これからWebサービスを作りたいと思っている人に、少しでも参考になればと思って筆をとってみた(キーボードを叩いてみた)
Pythonでテキストアナリティクス 〜『テキストアナリティクス入門』に沿い共起ネットワークなど描いてみた〜 Part2:複合語編
## はじめに
**[テキストアナリティクス入門](www.amazon.co.jp/dp/4065274109)**
この書籍は、テキストアナリティクス初学者向けの入門書です。
テキストアナリティクスとは何だということのみならず、頻出語やこれを表現したWordCloud、共起ネットワークをどのように活用すべきかが、実例に沿ってわかりやすく解説されていて、とても参考になりました。[**前回記事**](https://qiita.com/hima2b4/items/5619e617c34f588b418a)(以下)では、この書籍で紹介されていたインタラクティブな動的共起ネットワークを、他に紹介されていたWordCloudを含め、やってみました。
https://qiita.com/hima2b4/items/5619e617c34f588b418a
もう一つ紹介されていた内容で興味を
Ubuntu22.04 MySQL+mysqlclient+Django+Django REST frameworkで簡単なAPIサーバを作る
## 概要
Ubuntu22.04のMySQL8.0.30と、venv仮想環境のDjango3.2+Django REST frameworkをDjango公式推奨のmysqlclientで連携して、環境構築がちゃんとできているか確認するために簡単なAPIサーバを作成します。Pythonのバージョンは3.10.6です。Pyhon、MySQLはインストール済みです。https://qiita.com/lustm5/items/ef8dc276872d04707a90
https://qiita.com/lustm5/items/18dcea509e190a62e83a
2022/8/10現在Djangoは3.2系の最新は3.2.15、Django REST frameworkの最新は3.13.1でした。
“`
$ python3 -m pip install Django==
“`

# はじめに
TensorFlowを触ってみたくてとりあえずチュートリアルを動かしたい。
せっかくなのでGPUで!
と思ったのですが、動くようにするまでに少し苦戦したので情報を残しておきます。# 誰向け?
* TensorFlowをGPUで動かしたい人# 概要
基本的にはTensorFlowの公式チュートリアルに沿って進めます
ビギナーと書いてあるだけあって上手くいけば簡単!
https://www.tensorflow.org/tutorials/quickstart/beginner下記の環境で動かしました。
* OS:Windows10
* Ptython:Python 3.10.6
* TensorFlow:tensorflow-gpu 2.9.1
* グラフィックボード:RTX2070Super# Pythonの仮想環境を作る
ライブラリや各種バージョンで環境を汚すと面倒なので仮想環境を作成するのがおすすめらしいです。
こちらも公式でやり方書いてあるのでリンクを貼っておきます。
https://www.tensorflow.org/install/pip?hlOTHERカテゴリの最新記事

- 2024.09.20
JAVA関連のことを調べてみた

- 2024.09.20
iOS関連のことを調べてみた

- 2024.09.20
JavaScript関連のことを調べてみた

- 2024.09.20
Rails関連のことを調べてみた

- 2024.09.20
Python関連のことを調べてみた

- 2024.09.20
Lambda関連のことを調べてみた