
- 0.0.1. 気軽なファイルバックアップツールの勧め
- 0.0.2. poetry 1.2.0 を install する
- 0.0.3. xgb(一時保存用)
- 0.0.4. Python,Ruby,PHP,Java,JavaScript,Perlの関数定義の比較 (メソッド定義・サブルーチン定義なども)
- 0.0.5. 不均衡データに対するアプローチ 〜SMOTE・重み付け・アンダーサンプリングバギングの比較〜
- 0.0.6. 単語検索 with Alfred workflow (Longman英和・和英)
- 0.0.7. DjangoをVSCode+Anacondaで開発(Windows)
- 0.0.8. Kaggle の Titanicを今更やってみる(初心者)
- 0.0.9. 【Python】引張試験結果のcsvファイルからグラフ作成までを自動化した
- 0.0.10. python 使いの ruby メモ
- 0.0.11. AWS CDK初心者が爆速でS3とかlambdaとか「とりあえずそれっぽく」作る方法
- 0.0.12. Pythonでwebサイトの構築 Part2 アプリケーションの作成
- 0.1. 1, ブログサイトに必要な機能について
- 0.2. 2, アプリケーションの作成とurls.pyについて
- 1. 早速コードを書く前に
- 2. TwitterAPIの申請が通ったら
気軽なファイルバックアップツールの勧め
# QTTabBarの機能
エクスプローラをタブ化するエクスプローラー拡張である[QTTabBar](http://qttabbar-ja.wikidot.com/)を私は使っているんだが、これには以下の機能がある。| 選択しているファイルを引数に加えて、登録したコマンドをボタンを押すだけで実行できる |
|:-:|この機能(アプリケーションランチャー)を使い、下記のbackup.pyを実行するように設定すると、ファイルを簡単にバックアップできるようになります。
ファイルを修正する時に、とりあえず今のファイルを残しておこうとかをすぐにやるようになるのでお勧めです。* 参考ページ:[【中級者向け】QTTabBarのアプリケーションランチャを使う](https://ho-kiboshi.com/qttabbar/424/)
他のエクスプローラー拡張やファイラーでも同様の機能があれば、同じようにすれば便利です。
# backup.py
## 機能
* ファイルのコピーを作る。
* その際に作成日時は変更せず。
* コピー先のファイル名は、元のファイル名に「-backupYYY
poetry 1.2.0 を install する
# 概要
昨日 stable version になった `poetry 1.2.0` をインストールしたときのメモです。# how to install
## download
以下のコマンドで最新の poetry (記事執筆時点では `1.2.0`) が入ります。
“`bash
curl -sSL https://install.python-poetry.org | python3 –
“`バージョンを指定してダウンロードしたい場合は環境変数 `POETRY_VERSION` を指定してダウンロードします。
“`bash
POETRY_VERSION=1.2.0 curl -sSL https://install.python-poetry.org | python3 –
“`## path を通す
download された poetry にパスを通します。“`bash
export PATH=$PATH:$HOME/.local/bin
“`Dockerfile の中でやるならこっち。
“`Dockerfile
ENV PATH $HOME/.l
xgb(一時保存用)
“`python
# -*- coding: utf-8 -*-
“””big.ipynbAutomatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1fZJ90Dl7P9n2uSNy8ZsoY0VDB3HBHNlT
“””import pandas as pd
import numpy as np#見やすいデータフレーム
from IPython.display import display as dp#データ分割用
from sklearn.model_selection import train_test_split#XGBoost
import xgboost as xgb#読み込み
train = pd.read_csv(“train.csv”)
test = pd.read_csv(“test.csv”)
sample = pd.read_csv(“submit_sample.csv
Python,Ruby,PHP,Java,JavaScript,Perlの関数定義の比較 (メソッド定義・サブルーチン定義なども)
Python,Ruby,PHP,Java,JavaScript,Perlの関数定義の比較 (メソッド定義・サブルーチン定義なども)
# Python
https://qiita.com/simonritchie/items/0f7b3768031dda834907
# Ruby
https://qiita.com/shizen-shin/items/dd41d1f0176a5e764f9f
# PHP
https://qiita.com/miriwo/items/a33688165a5f36ea8e76
# Java
https://qiita.com/takahirocook/items/5bfe43576d87a2a4006c
# JavaScript
https://qiita.com/tomcky/items/988fc5f56d019e9dc097
# Perl
ht
不均衡データに対するアプローチ 〜SMOTE・重み付け・アンダーサンプリングバギングの比較〜
# 本記事の概要
記事作成中
# 不均衡データって何? なぜ問題なの?詳細はこちら(前提内容のため折り畳み)
### 不均衡データとは
### どんな問題が起こるの?
# 不均衡データの対処法は?
SMOTE
重み付け
アンダーサンプリング×バギング# 使用データ
単語検索 with Alfred workflow (Longman英和・和英)
# TL;DR
MacOSで使える神ランチャーアプリAlfredで、検索窓から`long 調べたい単語`打てばLongman英和辞書(和英辞書)からスクレイピングで意味を引っ張ってきて、ブラウザで開かずとも単語の意味を検索できるようにした。Longman英和
元のサイトはこんな感じ。
https://www.ldoceonline.com/jp/dictionary/english-japanese/swim
主な意味と例文を引っ張ってきている。見やすいように1文を一行に表示するようにしている。
DjangoをVSCode+Anacondaで開発(Windows)
# 動機
データ分析や機械学習が絡むWEBアプリ開発において、Jupyter NotebookとVS Codeを併用したいと思った。
WEBアプリ自体は小規模で、まずは自分で試用するようなものを作る想定だった。(Googleカレンダーの予定を集計し、自身の行動分析や予定予測を行いたい。そのための分析基盤をDjangoからグラフィカルに提供したい。)# 仮想環境の選択肢
Djangoでアプリ開発をする上で、選択肢に上がったのは以下。* venv
* Anaconda
* Dockerまず小規模かつスピーディに行いたかったので、Dockerは選択肢から外した。
venvとAnacondaは以下のような違いがあると考えた。* venv
* python自体をOSにインストール必要がある
* ゆえに環境の一部を管理できない。
* python3に組み込まれていて手軽
* 一方で、python自体のバージョンを管理できない
* Anaconda
* anacondaのインストールは必要だが、pythonをOSにインストールしなくて済む
* python
Kaggle の Titanicを今更やってみる(初心者)
今回はKaggleのTitanicを久々にやってみた。
それの自分用の現時点での疑問とか気づいたことを書きなぐっていくだけ。コードは以下。https://www.kaggle.com/code/kawawawa23/titanic-0-80861-lightgbm/edit/run/104609691
まず体感したこととしては,いくら有効そうな特徴量を作っても実際には有効ではないケースが多いということ。むしろ期待通り有効なケースの方が稀な印象を受ける。「EDAを色々試してみて割ときれいにグループを分けることができたし,これを特徴量にしよう」みたいなことをやってみても精度が全く変わらない。なんなら下がるときもある。でも,こんなことが多いからこそ精度に大きな影響を与える特徴量を生成できた時には嬉しいのかな?
次は,出現数が少ない水準をまとめるべきなのかという問題。
【Python】引張試験結果のcsvファイルからグラフ作成までを自動化した
# はじめに
本プログラムは、↓こんな引張試験の電圧の出力値のcsvを指定すれば
実行するだけで以下のようなきれいなグラフを作成できるようにすることを目的としたプログラムです。

すぐに体験したい人は以下にgooglecolab上で動くように公開しました。
python 使いの ruby メモ
# 概要
python と ruby はメソッドなどは大体同じなんですがちょいちょい違うところがあるので個人的な備忘録として作成しました。随時加筆します。# ruby メモ
## 文法・作法
– `:` はいらない
– python だと定義文やコンテキストブロックを作るときに必要だが ruby は不要
– `if` `elsif` `else` `end`
– python だと `if` ブロックを閉じるときはインデントを抜けるだけだが ruby は終了範囲を明示的に `end` で指定する必要あり
– `return` は書かない
– 書いてもエラーは起きないが慣習的に書かない
– 関数 / メソッドの最後に評価された値が勝手に戻り値になるので明示的に書かなくてよい
– `unless`
– python で書くなら `if not`
– `case` `when`
– `case state` `when value` で条件分岐を書ける。複数条件あるときに便利
– python だと `match` `case
AWS CDK初心者が爆速でS3とかlambdaとか「とりあえずそれっぽく」作る方法
# 概要
AWSをwebから初めて使うときって特に気になりませんが、少し慣れてくると
「これいちいち所望のアプリ見に行って設定直すのめんどくせえ、、、!!!!」、と思いませんか?~~(思いますよね???)~~lambdaとS3を連携したりとかよくあると思うんですが、毎回どのlambdaだっけとか探すのめんどくさい。
これってなんとかならないの〜??
ってことで今回はAWS CDKを使って設計をコード化してまとめてAWSにあげてみます。
コードでインフラストラクチャを定義できるようになりましょう!初心者用なので、「とりあえずそれっぽく」を軸に話します。
イメージはこんな感じ。
# AWS CDK
そもそもAWSCDKとは?となる人もいるので公式から説明を拝借。
> AWS Clou
Pythonでwebサイトの構築 Part2 アプリケーションの作成
[前回の記事](https://qiita.com/T_gdmuy/items/3a33867bdc3c339aa4a2)では「Dockerによる環境構築~プロジェクトの立ち上げ」までを行いました。
この記事ではブログサイトに必要な各機能を実装するためのアプリケーションの作成とURLディスパッチャについての簡単な説明を行います。1, ブログサイトに必要な機能について
ブログサイト構築にあたり必要な機能は以下になります。
“`Python:ブログサイトに必要な機能
・記事一覧
・記事詳細
・カテゴリごとでの記事
・トップページ(必ずしも必要ではない)
・管理人サイト(adminサイト)
“`2, アプリケーションの作成とurls.pyについて
2-1, アプリケーションの作成
ここではアプリケーションの作成を行います。
プロジェクトディレクトリと同じ階層でターミナルを新たに立ち上げ以下のコマンドを入力してください。
そうすることでコンテナ内に入ることができ「python manage.py ~」を利用できます。“`
PythonでTwitter自動で動かし懸賞を当てよう
早速コードを書く前に
twitterをpythonで操作するにはTwitterAPIを使用する。TwitterAPIを使うには利用申請をしないといけないのですが、ここでは省略します。
詳しくはこちら
のページがわかりやすいので、見ながら申請してみてください。最近は申請がゆるいみたいなのですぐに使用できるようになると思います。
TwitterAPIの申請が通ったら
申請でも使ったこちら
にアクセスしTwitterAPIを使うのに必要な各種キーを取得しましょう
リリースされました。筆者の環境ではDocker上などでインストールエラーが発生するようになったので1.1を指定してインストールする方法についてまとめます。## How to
ローカルでのインストールは以下のようになります。`POETRY_VERSION`はInstallしたいバージョンに適宜変更してください。“`bash
# この辺は .bashrc系に書くと良さそう
export POETRY_HOME=”/opt/poetry”
export POETRY_VERSION=1.1.14
export PATH=”$POETRY_HOME/bin::$PATH”
curl -sSL https://install.python-poetry.org | python3 –
“`
Dockerで書く場合は以下のような感じです。“`dockerfile
ENV POETRY_HOME=”/opt/poetry” \
POETRY_VERSION=1.1.14
ENV PATH=”$POETRY
【pandas】前処理・EDA処理でよく使うコードまとめ【Python】
データフレームのEDAや前処理でよく使うコードを(自分用に)まとめました。
作成途中、随時更新するつもり## 最初に
### インポート“`python
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns#(colab用) Googleドライブ上のファイルを読み込むため
from google.colab import drive#データフレームを見やすく表示(printの代わりに使用)
!pip install ipython # 未インストールの場合
from IPython.display import display as dp#グラフ描画で日本語を使用
!pip install japanize-matplotlib # 未インストールの場合
import japanize_matplotlib#一括でEDAしてくれる
!pip install -U pandas_profilin
[python] 定義済みEnumから動的にEnumを生成する
# やりたいこと
定義済みのEnumから指定したリストで動的にEnumを生成する。
## 実装例
“`python
from enum import Enumclass Color(Enum):
red = “赤”
blue = “青”
yellow = “黄”
purple = “紫”@classmethod
def generate_enum(cls, target_list: list[str]):
result = {e.name: e.value for e in cls if e.name in target_list}
return Enum(__class__.__name__, result)“`
## 使用例
“`python
target_list = [“red”, “purple”]
results = Color.generate_enum(target_list)
# results[“red”], results(“赤”), results[“pu
pandasのpd.TimestampとUnixTimestampの相互変換
`timestamp.astype(np.int64)` と `pd.to_datetime(unix_timestamp_index)` で相互変換できる。
# データ準備
“`python
date_index = pd.date_range(start=”2022-08-31 10:00:00″, end=”2022-08-31 11:00:00″, freq=”1S”)
“`“`
DatetimeIndex([‘2022-08-31 10:00:00’, ‘2022-08-31 10:00:01’,
‘2022-08-31 10:00:02’, ‘2022-08-31 10:00:03’,
‘2022-08-31 10:00:04’, ‘2022-08-31 10:00:05’,
‘2022-08-31 10:00:06’, ‘2022-08-31 10:00:07’,
‘2022-08-31 10:00:08’, ‘2022-08-31 10
ゼロからはじめる機械学習講座「AI x IoTセンサーデータ分析と画像分類物体検出」
### サンプルソースの公開場所
https://github.com/techgymjp/techgym_ai
実行環境がない場合はanacondaをinstallしてください。
(抜粋版なので問題番号は連番ではないです)## ■13-1:センサーデータ分析:eP4q.py
### 【問題】センサーデータを分析することでIoTからくるデータ分析の方法を実践してみよう
気象庁から温度湿度データをオープンデータとして得ることが出来る
そこで、気象庁のセンサーデータで以下のことをやってみよう□takamatsu.csvをgithubからダウンロードしてデータフレームで表示する
このとき以下の条件でファイルを読み込む
・”日時”を”data_hour”としてindexに指定する
・data_hourをdatetime型として読み込む
・”×”のデータはNaNとして読み込む
・「時」の列は使わないので削除する
□列の名前を英語に変更する
“降水量(mm)”: “rain”,”気温(℃)”: “temperatu
Hugging Face + WRIMEデータセットで、8クラスの感情分類
# 作るもの
本記事では、__日本語文の感情分析をするAIモデル__ を作ります。
入力文に含まれる感情を、__8つの基本感情__ の軸で推定します。こんな感じです。
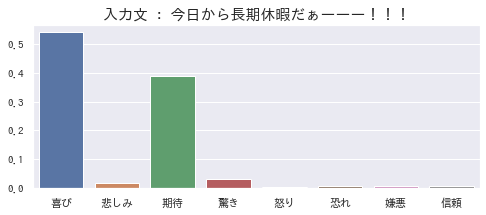
上記の棒グラフは、「今日から長期休暇だぁーーー!!!」という文章には「喜び」と「期待」の感情が含まれている、という推定結果を示したものです。(夏季休暇を目前にして、「せっかくの休みで時間もあるし、あれもしたいし、これもしたいな♪」と喜びと期待に胸を躍らせていた私の気持ちが見透かされているようで怖いです……。)
# 概要
タイトルの通り、「Hugging Face」と「WRIMEデータセット」を用いて、8クラスのテキスト感情分類をしてみる、という内容です。__対象読者__
– テキスト感情分類に興味がある方
– Hugging Face (Transfo
CとPythonの比較
C:Cは、1972年から73年にかけてベル研究所でDennis Ritchie氏によって開発された構造化された中級レベルの汎用プログラミング言語である。UNIXオペレーティングシステムを開発するための基盤として構築された。中級言語であるため、高級言語に特徴的な組み込み機能はないが、開発者が必要とするすべてのビルディングブロックを提供する。C言語は構造指向、つまりプログラムをより小さな関数に断片化するトップダウン・アプローチに従う。
C言語の特徴は、従来アセンブリ言語で書かれていた低レベルのメモリ管理作業(メモリ位置に直接アクセスできる16進数のコード形式)に最適化されていることである。現在でも、UNIXやLinuxの派生系は、多くの機能でCに大きく依存している。
Python Pythonは1989年にGuido Rossumによって開発された汎用的な高級プログラミング言語である。Pythonがすごいのは、英語に近いシンプルな構文と動的型付け機能です。構文が単純なため、コードを読みやすくすることができます。
また、インタプリタ型言語であるPythonは、ほとんどのプラットフォーム




