
- 1. Pythonでcsvにスペース区切りのリストを書き込む
- 2. モノクロ画像をAIでカラー化してくれるPythonツールを試してみた
- 3. 画像認識における Pytorch VS Tensorflow
- 4. Python,Ruby,PHP,Java,JavaScript,Perlの正規表現の比較
- 5. Pymatgenチュートリアル⑤ Structure型のデータを作る
- 6. 空間周波数フィルタリング
- 7. Mediapipeを用いたFlaskアプリのHerokuへのデプロイ方法
- 8. [OMNI3D] Virtual Depthによる単眼距離推定の安定化
- 9. [ROS] Pythonで色付き点群をpublish
- 10. とりまMecabで形態素解析を行いたい方へ。
- 11. pythonで統計の基礎を学んでみた(並び替え検定編)
- 12. How to use dictionary without ‘KeyError’ in python?
- 13. PaizaラーニングでBランクを目指して勉強①
- 14. maya python カメラを選択
- 15. maya python slect curves by name
- 16. Pythonでよく使うこと。コード、コマンド、スクレイピング、Anaconda、selenium
- 17. python find module location
- 18. [Python]Generationsメンバーの顔識別AIを作成
- 19. Stable DiffusionをWindowsかつCPUで実行してみる
- 20. Python TweepyでTweet取得(search_full_archive)
Pythonでcsvにスペース区切りのリストを書き込む
## 実現したいこと
リストを含むcsvをつくりたい ↓“`hoge.csv
a, b, [1 2 3], c
“`## 結論
これで実現できます。
“` hoge.py
l = [1, 2, 3] # リスト
l = ‘[‘ + ‘ ‘.join([str(x) for x in l]) + ‘]’ # リストをあらかじめ文字列にする!
row = [‘a’, ‘b’, l, ‘c’] # csvの1行# csvに出力
with open(‘hoge.csv’, ‘w’) as f:
writer = csv.writer(f)
writer.writerow(row)
“`## 失敗した方法
愚直に書いたコード ↓“`hoge.py
l = [1, 2, 3]
row = [‘a’, ‘b’, l, ‘c’] # csvの1行# csvに出力
with open(‘hoge.csv’, ‘w’) as f:
writer = csv.writer(f)
writer.writerow(row)
“`
モノクロ画像をAIでカラー化してくれるPythonツールを試してみた
このツイートが目に留まったのがきっかけでした。
AIを使って白黒画像やモノクロ画像をカラーに変換できます☺✨簡単!キレイ!でおススメです✨? pic.twitter.com/SYWCjl8ijR
— みやさかしんや@Python/DX/エンジニア (@miyashin_prg) July 11, 2022
お、コマンド3行打つだけじゃん!面白そうやってみよう。
↓
環境準備&地味に色々なエラーと格闘したので奮闘記を残します。# 環境前提
私の環境は以下でした。
– M1 MacBook Air
– 標準ターミナル(zsh)# その1:環境準備編
### Pythonのインストール
公式ページからMac OS用の最新Python 3をダウンロード。GUIインストーラーを利用して導入。
pipも同梱されています。https://www.python.org/downloads/
実行確認
“`zsh
$ python3 –version
$ pip3 –version
“`### Zshプロファイルにエイリアス登録
プロファイルをテキストエディターで開く
“`zsh
$ open ~/.zshrc
“`ファイ
画像認識における Pytorch VS Tensorflow
# 概要
よく議論されるTopicで一度は皆が疑問に思う、”PytorchかTensorFlowどっちが良いの?”について個人的な意見を述べたいと思います。PytorchとTensorflowそれぞれに良い所があり、場合によって使い分けましょうという記事が沢山あるので、今回はどちらか断言してみたいと思います。画像認識のタスクを学習し、ロボットに搭載する仮定で話します。# 論文で使われいる割合
画像認識ではPytorchが圧倒的に多いです。感覚的には9割くらいかなと。基本的に開発は前に書いた人のコードを元にするので、違うライブラリーだと一から書き直さないといけないので大変です(汗)。# Third Party Library
Pytorchには[Torchvision](https://github.com/pytorch/vision), [Pytorch-Lightning](https://github.com/Lightning-AI/lightning), [mmlab](https://github.com/open-mmlab)があります。これらが優秀すぎます
Python,Ruby,PHP,Java,JavaScript,Perlの正規表現の比較
Python,Ruby,PHP,Java,JavaScript,Perlの正規表現の比較
# Python
https://qiita.com/FukuharaYohei/items/459f27f0d7bbba551af7
# Ruby
https://qiita.com/shizuma/items/4279104026964f1efca6
# PHP
https://qiita.com/miriwo/items/da463cfcae441400381a
# Java
https://qiita.com/suema0331/items/5dde9f91671100a83905
# JavaScript
https://qiita.com/iLLviA/items/b6bf680cd2408edd050f
# Perl
https://perlzemi.com/blog/2
Pymatgenチュートリアル⑤ Structure型のデータを作る
### はじめに
前回の記事(https://qiita.com/ojiya/items/e98a9dd5cb6cd7ad38ca )に引き続き、PymatgenとOptunaでXRDの解析を目指す。前回の記事では、cifファイルを元に、構造を読み込んで、構造の情報を取り出してみた。実際にXRDの解析を行う場面では、構造、つまり格子や原子座標を最適化しなければならない。最適化の際には、構造を取り出す → 構造を少し変更する → 構造を作り直す というプロセスが必要になるので、ここでは構造を作り直すところについて、解説していく。### 実際のコードと説明
Structure型のデータを作るには、Pymatgen.core.structureモジュールの、Structureを使う。これは、以下のコードで読み込むことができる。
“`
from pymatgen.core.structure import Structure
“`
ここで読み込んだStructureは、引数として、格子(lattice)、元素種(species)、座標(coords)をとる。以下では、これらの作り方につ
空間周波数フィルタリング
# 空間周波数フィルタリング
# 基本関数
## min max scaler
“`Python
import cv2
import numpy as np
import mathdef _min_max(x):
return (x – x.min()) / (x.max() – x.min())“`
## FFT
“`Python
def make_FFT(img):
# FFT
dft = cv2.dft(np.float32(img), flags=cv2.DFT_COMPLEX_OUTPUT)
# ゼロ周波数の成分を中心に移動
dft_shift = np.fft.fftshift(dft)
# パワースペクトル
magnitude_spectrum = 20 * np.log((cv2.magnitude(dft_shift[:, :, 0], dft_shift[:, :, 1])) + 1)return dft_shift, magnitude_spectrum
“`
##
Mediapipeを用いたFlaskアプリのHerokuへのデプロイ方法
# 背景
Mediapipeを扱うアプリを作成したときにデプロイはできたがApplication Errorが起きて正常に動作しなかったので備忘録として置いておく。
MediapipeはOpenCVをもとに作っているので直接仮想環境にOpenCVをインストールしなくてもHeroku上では必要になってくる。# Heroku側の準備
herokuのsettingAのところのBuildPacksにopencvを追加する
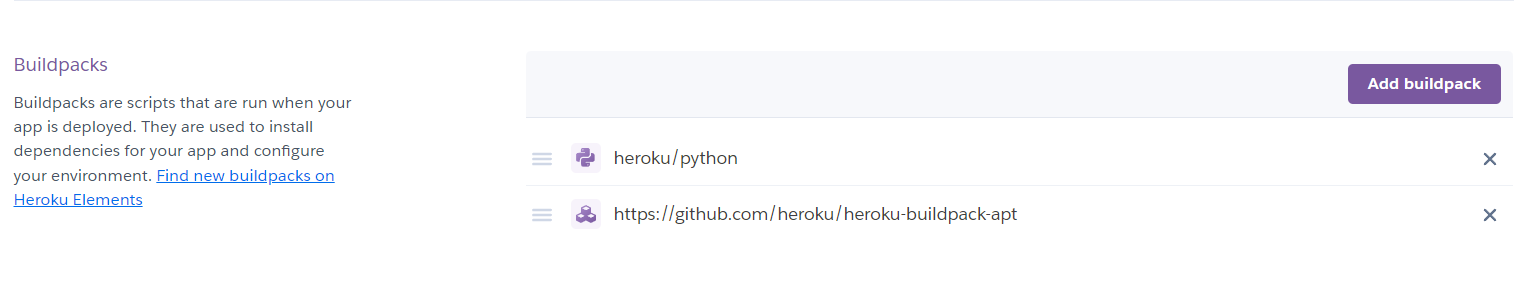追加には以下のURLをコピーして追加する
https://github.com/heroku/heroku-buildpack-apt# 実行ファイル側の準備
`requirements.txt`に`opencv-python-headless`を追加するだけ。
`requirem
[OMNI3D] Virtual Depthによる単眼距離推定の安定化
# 概要
単眼で距離を推定する時に、様々なセンサーを同時に学習しようとすると安定しないという課題がありました。
OMNI3DではVirtual Depthとうい手法を取り入れることで、その課題を解決しました。
# Virtual Depth
OMNI3Dでは距離をVirtual Depth(仮想距離)に変換する事で、焦点距離(f)と画像の高さ(H)の影響をなくす事を提案しています。
Virtual Depthを入力データに適応することで、焦点距離の違うカメラと画像のリサイズをして学習する事が出来るようになりました。距離画像だけではなく、三次元Bounding Boxにも適応出来ます。
“`
でもPythonのsensor_msgs.point_cloud2中は直接で色付き点群、つまりRGB PointCloud Messageを作る関数がない。
本文では PythonでこのRGB PointCloud Messageの作る方法を説明
本文のコードhttps://github.com/geturin/rgbpcd
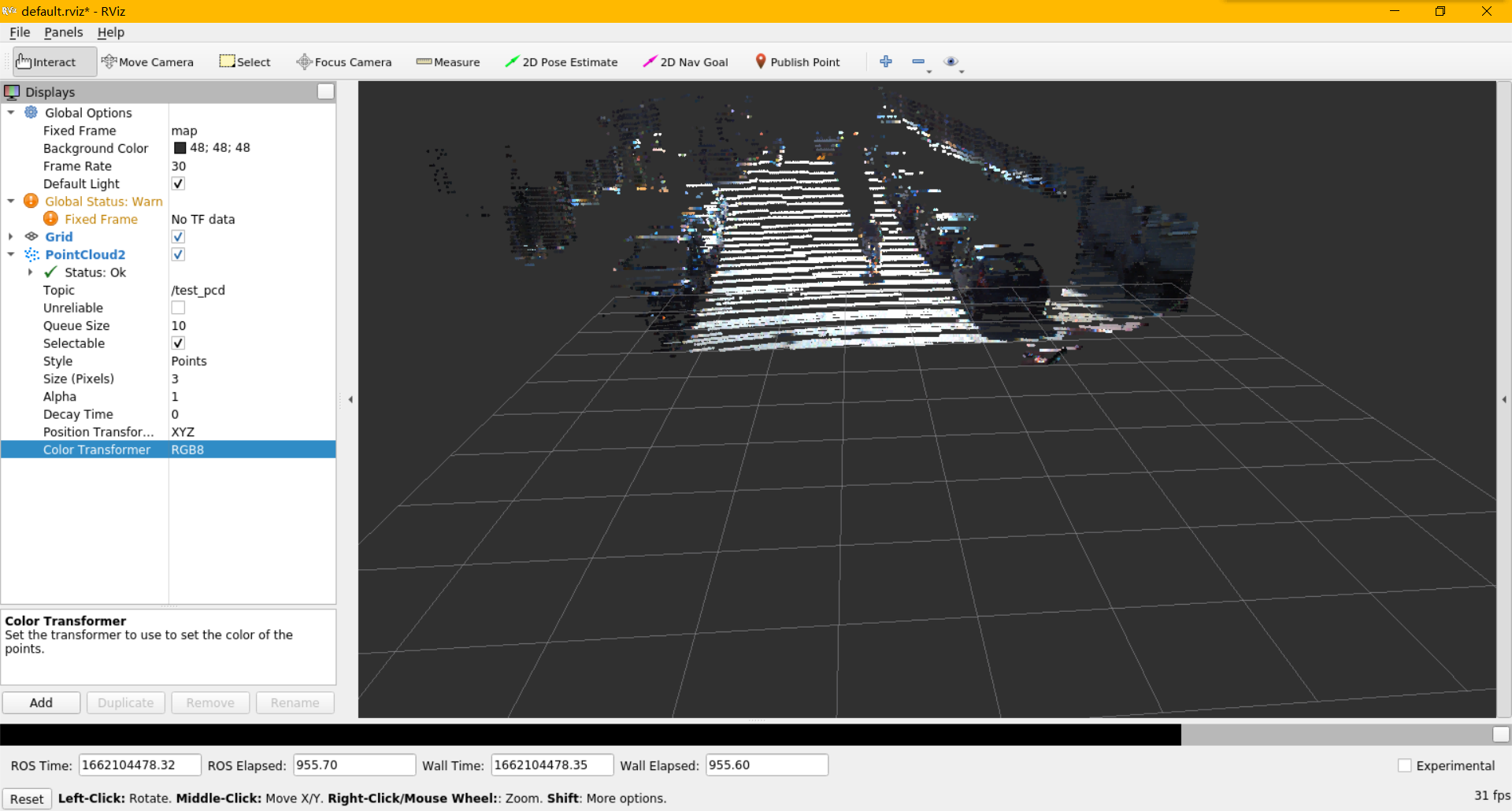
# データを用意
この部分は本文で使った色付き点群デー
とりまMecabで形態素解析を行いたい方へ。
## 初めに
Mecabって結構インストールが複雑?分かりにくくて多少苦労しました。
それらしいサイトを探っても前置きや広告で分かりにくかったり。今回はとにかく使いたい方にサクッとコードをシェア致します。
### 環境 colab windows 2022/9/2
## コード
“`python
# パターン①
! pip install mecab
! pip install unidic-lite
import MeCab
“`
これでいかがでしたか?偶にエラーになります。その場合はパターン②で“`python
# パターン②
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
“`
その後に“`python
import MeCab
# pip とimportは別のセルに分
pythonで統計の基礎を学んでみた(並び替え検定編)
# pythonを使ってリサンプリングによる並べ替え検定を行い、データに有意な差があるかを検証してみる
## 今回想定する事例
– とある二つのwebページがありそれぞれクリック数とサイトの訪問時間を測定したデータを仮定する。この二つのwebページのどちらが売り上げに寄与しているか調べたい。
– データはcsvファイルで、以下のような記述となっている。Page , Time
PageA, 0.21
PageB, 2.53
:
PageA, 0.93– 今回、ページAが21、Bが15の合計36セッションであったので、これらを`並べ替え検定`
(すべての時間を一緒にまとめ繰り返しシャッフルしてA:21個、B:15個の2つのグループに分け、その時の平均値の差を算出)
によって差があるかを調べる。## データの可視化(箱ひげ図)
まずは、どのようなデータになっているかを可視化しておく“`python:boxplot.py
from pathlib import Path
impo
How to use dictionary without ‘KeyError’ in python?
# How to use dictionary without ‘KeyError’ in python?
`dict` is a built-in data type of Python that can store key and value combinations of data.
## dict
“`python
d = {‘count’: 0}
print(d[‘count’])>> 0
d[‘count’] += 1
print(d[‘count’])>> 1
“`It can be used by mapping the value to the existing key as above.
“`python
print( d[‘name’] )>> Traceback (most recent call last):
File ““, line 1, in
KeyError: 1
“`Accessing a key that does not exist may throw a KeyError
PaizaラーニングでBランクを目指して勉強①
Qiita初投稿!
## 整数の足し算
[問題リンク](https://paiza.jp/works/mondai/prob60/substring_upper_1)
a b を足し算
input a b
output a + b“`python
n = input()a = 0
for i in n.split():
a += int(i)print(a)
“`for分の range のところに .split() を入れられると思わなかった。
## 文字の長さ
“`python
word = input()print(len(word))
“`## 一文字目だけ出力
“`python
word = input()
print(word[0])
“`## 大文字に変換
“`python
word = input()
print(word.upper())
“`関数とメソッドの違いがわからない…
upper(word) ではだめな理由が…[ここにわかりやすく書かれていました](https://gammas
maya python カメラを選択
“`python
import maya.cmds as cmds# Get all cameras first
cameras = cmds.ls(type=(‘camera’), l=True)# Let’s filter all startup / default cameras
startup_cameras = [camera for camera in cameras if cmds.camera(cmds.listRelatives(camera, parent=True)[0], startupCamera=True, q=True)]# non-default cameras are easy to find now.
non_startup_cameras = list(set(cameras) – set(startup_cameras))# Let’s get their respective transform names, just in-case
non_startup_cameras_transforms = map(lambda x:
maya python slect curves by name
“`python
import maya.cmds as cmds
curve_transforms = [cmds.listRelatives(i, p=1, type=’transform’)[0] for i
in cmds.ls(type=’nurbsCurve’, o=1, r=1, ni=1)]
selectList = []
for c in curve_transforms:
if “Root” in c or “Neck” in c:
selectList.append(c)
print(selectList)
cmds.select(selectList)
“`
Pythonでよく使うこと。コード、コマンド、スクレイピング、Anaconda、selenium
個人的によく使うことをメモしておきます。使うんだけど忘れちゃうので。
思いついたらどんどん加筆していきます。# 仮想環境をbaseに切り替えるコマンド
“`
$ conda activate
(base) $
“`参考)Conda コマンド
https://www.python.jp/install/anaconda/conda.html# Google ChromeとChromeDriverのバージョン不一致のとき
ChromeDriverのinstall“`
$ pip3 install chromedriver-binary==79.0.3945.36.0
“`参考)【Python/Selenium】ChromeDriverバージョンエラー対処法
https://yuki.world/python-chrome-driver-version-error/# seleniumのoption
headlessとか“`py
from selenium import webdriveroptions = webdriver.ChromeOp
python find module location
“`python
import datetime
print(datetime.__file__)
“`
[Python]Generationsメンバーの顔識別AIを作成
はじめに
私はPython初学者である。今回Aidemyで3ヶ月のアプリ開発コースを受講した成果を示すため、このAI及びブログを作成した。
受講に至った理由①生まれ持ちかつ見逃されていた難病とがんが最近見つかり、肉体労働には向いていないことが明らかになったから。理由②デスクワークできるようなスキルを持っておらず、今まで学んできた心理学や英語では将来食べていけないと思ったから。理由③AIやロボットに関心があり、小学生のときからプログラマーになりたいと思っていたから。
Stable DiffusionをWindowsかつCPUで実行してみる
## はじめに
ネットサーフィンをしてたらStable Diffusionという素晴らしいものを見つけたので、
GPUの環境でも使えたらいいなと思い調べてみました。## 参考
zennというサイトのこちらの投稿を参考にさせて頂きました。
https://zenn.dev/karaage0703/articles/4901bf68536907
上記ではWSL2やdockerを用いて環境を構築しておりますが、
anacondaでもできるんじゃないと思ったので試行。## gitからソースをダウンロード
https://github.com/bes-dev/stable_diffusion.openvino/tree/56b65312054d97b7b031ce8faba6310e7c120d00
こちらのページより右上の緑ボタンのCodeをクリック→Download ZIP。
Downloadしたzipを解凍して完了。## anacondaで環境構築
新しい仮想環境を作成し、解凍したzipフォルダにcdして、コマンド実行
~~~:anaconda prompt
c
Python TweepyでTweet取得(search_full_archive)
[Pythonパッケージの`tweepy`](https://www.tweepy.org/)を使ってTweet取得しました。少し前に短期間で実装したので、記憶が曖昧な部分も多いのですが、とりあえず記録に残しておきます。
[`search_tweets`関数](https://docs.tweepy.org/en/stable/api.html#tweepy.API.search_tweets)を使う記事は多かったのですが、[`search_full_archive`関数](https://docs.tweepy.org/en/stable/api.html#tweepy.API.search_full_archive)を扱う記事が少なかったので残しておきます。[`search_tweets`関数](https://docs.tweepy.org/en/stable/api.html#tweepy.API.search_tweets)は直近のTweetしか検索できません。そもそもAPIのバージョンを意識しないでコピペしたので、`Tweepy`のAPI V1.1を使っています(v2が




