
- 1. scikit-learn データセット分割の覚え書き
- 2. M1にpythonをインストールしてみた
- 3. Pythonのフレームワーク「Flask」を用いてHelloWolrdしてみた
- 4. ダミー変数化について
- 5. pdb.set_trace()のかわりにVSCodeでアタッチしてデバッグしたい
- 6. pythonを使ってAWSのログのインサイトを実行し、結果をCSVファイルで出力する
- 7. 詐欺メール検証用WEBによる検索program
- 8. Python べからず集
- 9. ロースペックPCでStableDiffusionを実装し実行時間を計測
- 10. オフラインでPythonライブラリをインストールする方法
- 11. Pythonでcsvにスペース区切りのリストを書き込む
- 12. Pythonでよく使うこと。コード、コマンド、スクレイピング、Anaconda、selenium
- 13. OpenPyxlの備忘録
- 14. pythonでExcel操作を自動化する
- 15. Windowsでpoetryが上手くインストールできない場合の対処
- 16. Python3 標準入力を辞書にする方法
- 17. PyScriptのすすめ
- 18. tensorflowがインストールできないだと!?
- 19. statsmodelsのseasonal_decomposeを活用した時系列データの可視化
- 20. CodeRunnerでpython: command not foundが出る場合
scikit-learn データセット分割の覚え書き
# この記事の内容
scikit-learnに付属しているデータセット分割法の覚え書きです。– ホールドアウト法
– K-分割交差検証(KFold)
– 層化K-分割交差検証(Stratified KFold)
– グループ付き交差検証(Group KFold)
– 時系列データ分割(Time Series Split)# データセットのインポート
scikit learnのデータセットとして利用できるiris datasetを使用します。
“`python
import pandas as pd
from sklearn.datasets import load_irisiris = load_iris()
df_iris = pd.DataFrame(data=iris.data,columns=iris.feature_names)“`
# ホールドアウト法
単純にデータセットを訓練データとテストデータに分割します。(デフォルト=7:3)
“`python
from sklearn.model_selection import train_test_spli
M1にpythonをインストールしてみた
## はじめに
今回の投稿がQiitaの初めてなので、markdown記法に慣れていないので申し訳ございません。
今後、勉強したことや困ったことを投稿していきますので、よろしくお願いします。## pythonを入れる方法
今後、競技プログラミングの方でpythonを使って行なっていきたいと思ったのですが、先日いきなりpythonの方でやろうとしたら、M1にはpythonが元々入っていない?という状態に気づいて、急遽Javaの方でやりました。
そのため、今回の記事はM1にpython環境を入れるのに参考にした記事を貼っておこうと思います。
[参考記事](https://hitori-sekai.com/python/mac-python-install/)
※いつもの感覚でバージョンを確認するときに`python -v`と入力するとpythonが起動してしまいました。原因としては`-v`が大文字の`-V`でないといけないことを知りませんでした。## 最後に
最近、macを買い替えてM1チップ搭載のMacBook Airにしたのですが、友人に聞いたところpython以外にもdock
Pythonのフレームワーク「Flask」を用いてHelloWolrdしてみた
# 概要
pythonでのWebアプリ開発の経験がなかったため、勉強としてFlaskフレームワークを使用していろいろ作成を行ってみました。
この記事では、Hello Worldレベルの最低限の実装となっています。# Flaskとは
[Flask Documentation](https://flask.palletsprojects.com/en/2.2.x/)
[Flask 日本語Documentation](https://msiz07-flask-docs-ja.readthedocs.io/ja/latest/)Flaskは、Python製のマイクロWebフレームワークです。
__マイクロ=コアとなる機能を保ちつつ拡張性を持っている__ という解釈です。
拡張機能を多く持ち、必要に応じて追加することで自由度が高いです。
また、最低限の機能を使うための学習コストが低く、誰にでもすぐに利用することができます。開発に必要な多くの機能が実装されているという点では、[Django](https://www.djangoproject.com/)の方がフルスタックフレームワー
ダミー変数化について
# Pythonでのダミー変数化
ダミー変数化とは・・・
日付や時刻などの文字列(カテゴリ変数)を数値データに変換すること。
Pythonでは一般的にPandasの関数get_dummies()を用いてダミー変数化される。また、one-hot encodingとして出力される。
## one-hot encoding
文字列のカテゴリの変数に応じてカラムを用意し、0,1に置き換える。
ただし、欠点としてカテゴリの変数が多い場合はデータが膨大になってしまう。## label encoding
カテゴリの変数の種類に応じず、1つの列で収まるデータを作成する。
使用するには、sklearnのLabelEncoder()を利用する。その後fitでデータを読み込み、transformで変換を実施する。
pdb.set_trace()のかわりにVSCodeでアタッチしてデバッグしたい
# 目的
`import pdb; pdb.set_trace();`や`breakpoint()`はちょっとしたデバッグの時に便利だが、VSCodeでデバッグしたい時がある。
# 環境
Windows10、Python 3.10.4、VSCode 1.70.2(2022-08-16T05:35:13.448Z)
# 準備
`debugpy`があること。なければpipか何かで導入する。
“`
> pip list |findstr debugpy
debugpy 1.6.3
“``import pdb; pdb.set_trace();`の代わりになるものを書く。
ブレークさせたいところに`break_here()`と書く。“`python:debug_util.py
import sys
import debugpydef _wait_debugger():
port = 5678
debugpy.listen(port)
print(f”debugpy {port=}”, file=sys.stderr)
pythonを使ってAWSのログのインサイトを実行し、結果をCSVファイルで出力する
## 背景、目的
AWS環境を使用したWebサイトを提供しており、日次の運用としてエラー有無、内容の調査を行います。
エラーが出ている場合(基本はなにかしらのエラーが出ている)は、どのようなエラーであるか、対応が必要であるかを判断します。その前段のエラー有無を取得するためにCloudWatch Logsを使用しているのですが、毎回以下の操作を行います。
– ブラウザを開いてコンソールへログイン
– CloudWatchを開いてログのインサイトを選択
– 対象日時を範囲選択
– 保存済みのクエリから対象を選択
– 実行して結果が出るのを待つ
– 結果をダウンロード「保存済みのクエリから対象を選択」以降は複数回実行します。
この後にエラー有無と対応要否を判断します。毎日やる作業と考えると結構しんどいです。
## 環境
| key | value |
| ——– | ———— |
| OS | mac 11.6.1 |
| language | Python 3.9.1 |
| AWS CLI | 2.7
詐欺メール検証用WEBによる検索program
# 実行環境
>・macOS Monterey バージョン12.4
・ python3.7.7
・ selenium 3.141.0
・ webDriver GoogleChrome chromedriver version for 104.0.5112
>
# このプログラムを組んだ理由
>最近、Amazonを騙って下のようなメールがちょくちょく来るようになった。
「Amazon.com」とあるから最初ドキッとしたけど、差出人の **「Amazon.com」部分を右クリック -「アドレスをコピー」をクリック - テキストエディットに貼り付け** てみると、http://amazon@member-amazon.shopとなっていた。(99%怪しい)
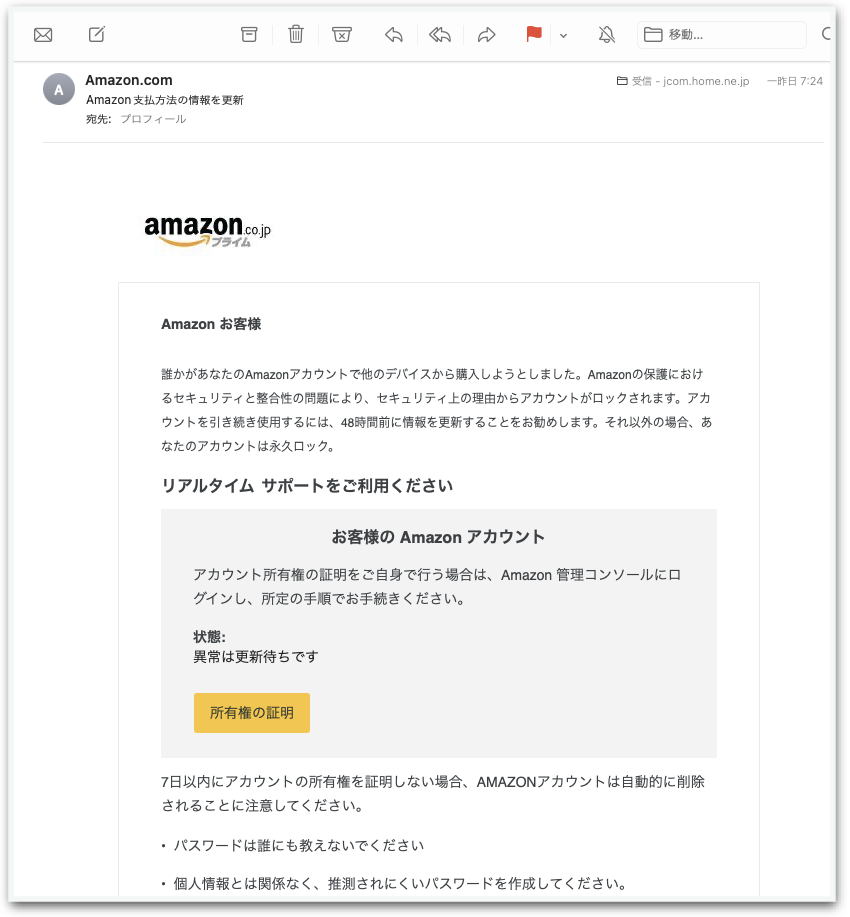
>でも、**amazon.shop
Python べからず集
# はじめに
## クレジット
@apple502j さんの [この記事](https://qiita.com/apple502j/items/898eb8149f1f40ac1da4) を見て Python 版を作ろうと思いました!
ありがとうございます!## 参考にしたもの
[PEP 8 ドキュメントの日本語版](https://pep8-ja.readthedocs.io/ja/latest/)# 何するの?
「これ Python でやんない方がいいお!」的な書き方を紹介します。
ささっと紹介するだけですが、だいたい分かると思います。# じゃあやろう!
## 1. `import` 編
### 1-1. 1 行でまとめるべからず
普通は `import` 文は行を分けたほうがいいです:
“`python:イイね
import os
import sys
“`
“`python:ダメだね
import os, sys
“`でも、次のやり方は良い例です:
“`python:イイね
from subprocess import Popen, PIPE
`
ロースペックPCでStableDiffusionを実装し実行時間を計測
# 挨拶
初めまして、日本システム開発株式会社の鈴木です。
技術者として更なる向上を目指すためQiitaアウトプットをする取り組みを行っています。
技術者としては経験が浅く発信内容はとにかく試したものの覚書になります。
本稿はロースペックPCでStableDiffusionを導入してみた際の手順です。# 環境(マシンスペック)
OS: Windows 10
CPU: Ryzen 5 3500U
GPU: AMD Radeon Vega8 Graphics VRAM 2GB(オンボード)
メモリー: 8GBPython : 3.9.13
diffusers : 0.2.4
torch : 1.12.1
transformers : 4.21.2## 目的
StableDiffusionの資料を探しているとCUDAを使用した環境の構築が多いものの一応動作させること自体はCUDAなしでもできそうだったためその環境を構築してみます。
## Python仮想環境設定
今回は実用的な速度にならないことが予想できていたため後から削除しやすいよう専用の仮想環境を用意します。
“`:コマン
オフラインでPythonライブラリをインストールする方法
会社や学校でPythonを利用する際、オフライン環境やプロキシの問題でライブラリをインストールできない状況に遭遇した方もいると思います。
本動画では、そのような状況を回避しながらインストールする方法をご紹介します。PCの不調でうまく録画できていなかったため、
仮想環境の構築方法を記載させて頂きます。
### 仮想環境の作成の仕方
“`py
python -m venv env
.\env\Scripts\activate
“`
Pythonでcsvにスペース区切りのリストを書き込む
## 実現したいこと
リストを含むcsvをつくりたい ↓“`hoge.csv
a, b, [1 2 3], c
“`## 結論
これで実現できます。
“` hoge.py
l = [1, 2, 3] # リスト
l = ‘[‘ + ‘ ‘.join([str(x) for x in l]) + ‘]’ # リストをあらかじめ文字列にする!
row = [‘a’, ‘b’, l, ‘c’] # csvの1行# csvに出力
with open(‘hoge.csv’, ‘w’) as f:
writer = csv.writer(f)
writer.writerow(row)
“`## 失敗した方法
愚直に書いたコード ↓“`hoge.py
l = [1, 2, 3]
row = [‘a’, ‘b’, l, ‘c’] # csvの1行# csvに出力
with open(‘hoge.csv’, ‘w’) as f:
writer = csv.writer(f)
writer.writerow(row)
“`
Pythonでよく使うこと。コード、コマンド、スクレイピング、Anaconda、selenium
個人的によく使うことをメモしておきます。使うんだけど忘れちゃうので。
思いついたらどんどん加筆していきます。# 仮想環境をbaseに切り替えるコマンド
“`
$ conda activate
(base) $
“`参考)Conda コマンド
https://www.python.jp/install/anaconda/conda.html# Google ChromeとChromeDriverのバージョン不一致のとき
ChromeDriverのinstall“`
$ pip3 install chromedriver-binary==79.0.3945.36.0
“`参考)【Python/Selenium】ChromeDriverバージョンエラー対処法
https://yuki.world/python-chrome-driver-version-error/# seleniumのoption
headlessとか“`py
from selenium import webdriveroptions = webdriver.ChromeOp
OpenPyxlの備忘録
## はじめに
### 使用しているもの
`openpyxl 3.0.10`“`python
# 前提コード
import openpyxlwb = openpyxl.Workbook()
“`### 注意
間違いやもっとこうした方がいい、みたいのがあるかも## 内容
### get_なんたらは基本使わない
調べるとよく出てくる、
`wb.get_sheet_by_name(‘Sheet1’)`
なんかはもう古いみたい。
他にもなにやら新しくなっているものがあり、ちょいちょい怒られる。
以下新旧対照表
|内容|新|旧|
|—|—|—|
|シート名を指定する|wb[“Sheet1”]|wb.get_sheet_by_name(‘Sheet1’)|
|シートを消す|wb.remove(worksheet=wb[“Sheet1”])|wb.remove_sheet(wb.get_sheet_by_name(‘Sheet1’))|
|シート一覧の取得|wb.sheetnames|wb.get_sheet_names()|## おわりズイ₍₍ (ง ˘
pythonでExcel操作を自動化する
openpyxlを使用して、seleniumで取得したデータをExcelへ入力する作業を自動化します。
csvに出力する等もあると思いますが、Excelはどこでも使っていると思うのでExcelを選びました。## インストール
openpyxlを以下でインストールします
“`bash
$ pip install openpyxl
“`インストール確認は以下です。
“`bash
$ pip list | grep openpyxl
openpyxl 3.0.10
“`## ファイル読み込み
“`python
import openpyxl
wb = openpyxl.load_workbook(“読み込みたいファイル”)
“`## シート読み込み
“`python
sheet = wb[“読み込みたいシート名”]
“`## セル読み込み
“`python
value = sheet.cell(row=1, column=1).value
“`A1セルを読み込む
row=行、column=列
“`python
Windowsでpoetryが上手くインストールできない場合の対処
いつも通りPowerShellからpoetryを入れようとしたら入らなくなってた
“`PS
PS C:\Users\hoge> (Invoke-WebRequest -Uri https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py -UseBasicParsing).Content | python –
Retrieving Poetry metadataThis installer is deprecated, and cannot install Poetry 1.2.0a1 or newer.
Additionally, Poetry installations created by this installer cannot `self update` to 1.2.0a1 or later.
You s
Python3 標準入力を辞書にする方法
先日、paizaラーニングのレベルアップ問題集で、連想配列の問題を解いていたときにでた疑問をまとめました。
https://paiza.jp/works/mondai/query_primer/query_primer__map_normal
(この練習問題の自分のコードも最後に載せてあります。)### python3 で 標準入力を辞書の形にする方法
まず、リストを作成し、そこに要素を順に入れていきます。
“`Python
list_dic = []for i in range(N):
list_dic.append(input().split())
“`
そして、“`dict()“`を使って辞書にします。“`Python
dictionary = dict(list_dic)
“`例:
標準入力
“`
1 Sin
2 Sakura
3 Kayo
4 Yui
“`コード
“`Python
mylist=[]for i in range(N):
mylist.append(input().split())mydict=d
PyScriptのすすめ
HTMLに直接Pythonが書ける画期的で革命的なライブラリのPyScriptについての情報を纏めます。
## 導入方法
ヘッダでJSライブラリをロードするだけです。
“`html