
- 1. モジュールのインポート
- 2. データの準備
- 2.0.1. Asyncio 互換の PostgreSQLドライバ asyncpg
- 2.0.2. pythonでMicrosoft Graphを操作する(OneNoteのページ取得)
- 2.0.3. M1Macで姿勢推定「Kapao」を試す
- 2.0.4. 競プロ(Python)で~したいときに使うコード
- 2.0.5. 【Python】png,jpeg,gif画像をeps形式に変換する
- 2.0.6. VSCodeでPythonだけ自動整形が効かなかった時の対処法
- 2.0.7. 【Stable Diffusion】面倒事なしでいっぱいAI画像生成する【Google Colab】
- 2.0.8. Wiener deconvolutionをシミュレーションで理解しよう
- 2.0.9. Pythonでtar.gzファイルを扱う【tarfile】
- 2.0.10. scikit-learn データセット分割の覚え書き
- 2.0.11. Blenderファイルの分類方法メモ
- 2.0.12. Pythonでファイルのタイプを特定する
- 2.0.13. maya python hide all
- 2.0.14. [Docker] seleniumでUserProfileを利用する
- 2.0.15. maya python world transform
- 2.0.16. クッキー画像でサクッと異常検知AIを作る
- 2.0.17. 【LINE WORKS】IFTTTを経由してカレンダーを連携してみる
- 2.0.18. gensimで類似単語を取得する
[前編]そのt検定間違ってませんか?
先日線形回帰分析に関して、基本的でありながら実務家でも間違った理解をしていることが多い点について[解説](https://qiita.com/HiroyukiTachikawa/items/cc2f48161e4da8da69f1)したんですが、t検定についても、間違った情報をもとにした質問をされることがあるので解説します。
とはいえ私も勉強中なので、間違いがあれば指摘いただけるとありがたいです。
ちなみにサンプルサイズ、効果量、検出力についてはいい情報があるので触れていません。本記事ではもっと基本的なトピックを扱います。サンプルサイズ周辺で興味がある方は[TJO氏の記事](https://twitter.com/tjo_datasci/status/1306243667884081155)や[書籍:サンプルサイズの決め方](https://www.amazon.co.jp/%E3%82%B5%E3%83%B3%E3%83%97%E3%83%AB%E3%82%B5%E3%82%A4%E3%82%BA%E3%81%AE%E6%B1%BA%E3%82%81%E6%96%B9-%E7%B5%
Python、scipyのcurve_fitを使ってミカエリスメンテン式へのfittingを行う
Pythonのscipyを使ってcurve_fitを利用したミカエリスメンテン式へのfittingを行う。
Pandasを利用してデータを読み込み、seabornを用いてグラフを出力します。
この方法を用いてGoogle Colaboratoryでも描画できます。https://ja.wikipedia.org/wiki/%E3%83%9F%E3%82%AB%E3%82%A8%E3%83%AA%E3%82%B9%E3%83%BB%E3%83%A1%E3%83%B3%E3%83%86%E3%83%B3%E5%BC%8F
モジュールのインポート
まず、必要なモジュールをimportする。
“`
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.optimize import curve_fit
import seaborn as sns
“`データの準備
Pandas形式のデータを作成する。
直接コードに書き込む場合は以下
Asyncio 互換の PostgreSQLドライバ asyncpg
Pythonプログラムに速度を求めていろいろ**asyncio**を試しています。
**(関連過去記事)**
[Python Asyncio入門 – Qiita](https://qiita.com/sand/items/0e445a13d81d20ea33c3)
[Python Asyncio で作る Socket Server -Qiita](https://qiita.com/sand/items/4f27e62c7491b8e85d12)Asyncio 互換の PostgreSQLドライバ **asyncpg** を試してみました。 特徴は速いことです。公式サイトで公開されている以下のパフォーマンスレポートをご参照ください。
[PostgreSQL Driver Performance Benchmark Report](https://github.com/MagicStack/asyncpg)以下に**asyncpg**の簡単なサンプルプログラムを掲載します。
“`Python:main.py
import asyncpg
import asyncio
pythonでMicrosoft Graphを操作する(OneNoteのページ取得)
# Microsopf GraphはMSサービスのAPI
– [Graph Explorer](https://developer.microsoft.com/en-us/graph/graph-explorer#)利用できるAPIを色々お試しできます。
– [認証のpythonSDK公式ドキュメント](https://msal-python.readthedocs.io/en/latest/)
利用するパターンをクリックするとgit上のサンプルコードが開かれるようになっています。
パターンによってOauth2.0でのトークン付与方法が異なります。
今回の場合はmacbookからpythonで個人アカウントのAPIを叩きます。
何のアプリも通さずに、pythonから直接APIを叩くのでBrowserless Appになります。# Kapaoをクローンする
Google Colabで動くソースが用意されていますが、今回はあえてMacのローカルで動かします。
“`
git clone https://github.com/cedro3/kapao.git
“`ライブラリのインストールが必要です。
環境に合わせてインストールしてみてください。“`
pip install torch==1.9.1
pip install torchvision==0.10.1
pip install pytube
pip install imageio==2.4.1
pip install -r requirements.t
競プロ(Python)で~したいときに使うコード
Python向け。
# ~な入力を読み込みたい
“`Python:整数単独
N = int(input()) # (入力例) 12345
“`
“`Python:空白区切りの整数複数(個数があらかじめ決まっているとき)
A,B = map(int, input().split()) #(入力例) 100 200
A,B,C = map(int, input().split()) #(入力例) 100 200 300
A,B,C,X,Y = map(int, input().split()) #(入力例) 100 200 300 4 5
“`“`Python:空白区切りの整数複数(個数が決まっているとき)
# (入力例) 1 -2 3 -4 5 -6
A = [int(e) for e in input().split()] # A[2] = 3
# A = [0] + [int(e) for e in input().split()] と下駄を履かせればA[1] = 1 となる
“`“`Python:改行形式の数値リスト
【Python】png,jpeg,gif画像をeps形式に変換する
PillowライブラリのImageモジュールにより,png,jpeg,gifなどの画像をeps形式に変換することができます.
Pillowをインストールしているのであれば,怪しいフリーソフトをダウンロードする必要はありません.“`py:img2eps.py
import os
from PIL import Imageimage_path = ‘C:/Users/’ + os.getlogin() + ‘/Downloads/’
image_file = [‘ABC.png’, ‘DEF.jpg’, ‘GHI.gif’]for i in range(len(image_file)):
im = Image.open(image_path + image_file[i])
# print(im.mode)
fig = im.convert(‘RGB’)
fig.save(image_path + image_file[i].split(‘.’, 1)[0] + ‘.eps’, lossless = True)
“`ダウンロードフォルダ内
VSCodeでPythonだけ自動整形が効かなかった時の対処法
自分用のメモ
python.defaultInterpreterPathを編集して,以下のコマンドで表示されるパスを追加する.色々いじったら,デフォルトではVSCodeにpythonのパスがうまく認識されていなかったようだ.
“`
where python
“`
【Stable Diffusion】面倒事なしでいっぱいAI画像生成する【Google Colab】
# はじめに
この記事では今話題のStable DiffusionをGoogle Colabを利用して無料で使います。
所要時間は10分程度です。
一度初期設定が済めば、二回目からはほぼ作業なしで無限に生成が使えます。### ちなみに
最も簡単にStable Diffusionを試す方法として[DreamStudio](https://beta.dreamstudio.ai/home)というサイトがあります。
Googleアカウントがあれば誰でもすぐに生成を試すことができるので、AI画像生成とは何か体験してみたい方にはとてもオススメです。
ただし無料アカウントでは200枚までしか生成できないため、それ以上に生成を行いたければこの記事などのような方法を使うことになります。
# 概要
## この記事を読んででできること
・colab上で画像がいっぱい作れる です。Stable DiffusionをGoogle Colabで動かす記事は既に沢山あります。
本記事ではそれを拡張して、Colab上で見やすく、任意枚数生成できるプログラムを紹介しています。
## 閑話:神絵の作り方
Wiener deconvolutionをシミュレーションで理解しよう
# はじめに
本記事では撮像画像、点拡がり関数(Point Spread Function, 以下、PSF)、ノイズの3つの情報から真の画像を推定するWiener deconvolutionと呼ばれる手法を紹介する。
一般的な撮像観測では、観測装置の回折等により光源が拡がって撮像される。この拡がり具合はPSFで表され、このPSFを考慮して真の画像を推定する手法の代表としてRL法があるが、一般的に撮像時にPSFによる拡がりの他に電気的なノイズ等が入るため、より現実的なdeconvolutionではノイズも考慮する必要がある。Wiener deconvolutionは、撮像画像、PSF、ノイズの3つの情報から真の画像を推定することができ、本記事ではグレースケール、RGB画像でのシミュレーションにより性質を理解する。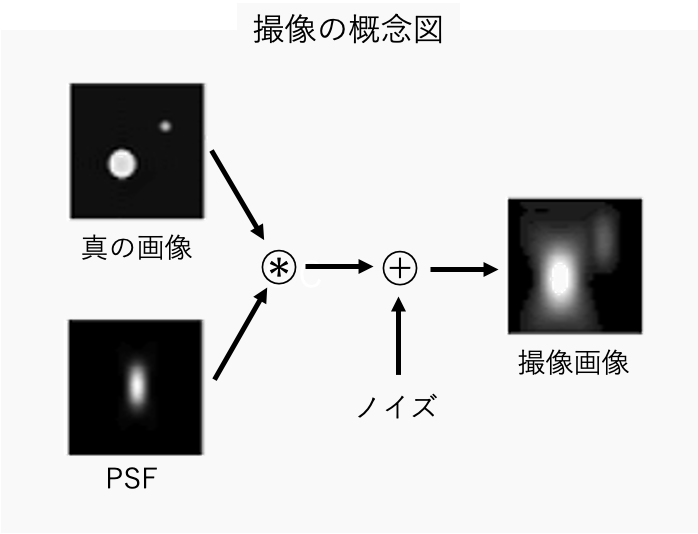
# Wiener decon
Pythonでtar.gzファイルを扱う【tarfile】
# はじめに
Pythonでtar.gzファイルを圧縮や展開する際に最低限必要なコードをまとめてみました。# sampleのフォルダ構成
サンプルコードは以下フォルダ構成で動かしてみました。> ├ sample.py
> └ target
> ├ text1.txt
> ├ text2.txt
> └ text3.txt# tarfileインポート
“`python
import tarfile
“`# tar.gzファイルに圧縮
“`python
with tarfile.open(‘target.tar.gz’, ‘w:gz’) as tar:
tar.add(‘target’)
“`# tar.gzファイルを展開
“`python
with tarfile.open(‘target.tar.gz’) as tar:
tar.extractall()
“`# 一部ファイルのみ展開
“`python
with tarfile.open(‘target.tar.gz’) as tar:
tar.extract(
scikit-learn データセット分割の覚え書き
# この記事の内容
scikit-learnに付属しているデータセット分割法の覚え書きです。– ホールドアウト法
– K-分割交差検証(KFold)
– 層化K-分割交差検証(Stratified KFold)
– グループ付き交差検証(Group KFold)
– 時系列データ分割(Time Series Split)# データセットのインポート
scikit learnのデータセットとして利用できるiris datasetを使用します。
“`python
import pandas as pd
from sklearn.datasets import load_irisiris = load_iris()
df_iris = pd.DataFrame(data=iris.data,columns=iris.feature_names)“`
# ホールドアウト法
単純にデータセットを訓練データとテストデータに分割します。(デフォルト=7:3)
“`python
from sklearn.model_selection import train_test_spli
Blenderファイルの分類方法メモ
## 概要
Blenderファイルを特徴別に分類する方法のメモです。macOSで確認しています。Windowsでは管理者で実行しないとアドオンで使っているos.symlinkが動かないようです。
### 要点
– 対象のBlenderのファイルは1つのフォルダに入れる。
– 各Blenderファイルに特徴などの情報をテキストで持たせる。
– 特徴別にツリー状のフォルダ構成でBlenderファイルのシンボリックリンクを管理し、ドリルダウンで絞り込みできるようにする。## 実現方法
下記の機能を持つ[アドオン](https://github.com/SaitoTsutomu/EditTag)を試しに作ってみました。
– 情報追加(`Add Info`)
– URL表示(`Open URLs`)
– タグ追加(`Add Tag to other`)
– リンクツリー(`Link Tree`)**アドオンのパネル**
“`python
import mimetypesmediaType = mimetypes.guess_type(“your_file_path”)[0]
if not (mediaType == None):
if mediaType.startswith(‘video’):
print(‘video’)
elif mediaType.startswith(‘image’):
print(‘image’)
elif mediaType.startswith(‘audio’)
print(‘audio’)
elif mediaType.startswith(‘application’)
print(‘application’)
elif mediaType.startswith(‘text’)
print(‘text’)
else:
print(“None”)
“`ディレクトリやmimetypesのタイプ一覧にないパスはNoneを返す。
一覧はこちら。
“`
pprint.pprint(mimety

maya python hide all
“`python
import maya.cmds as cmdsmodelPanels = cmds.getPanel(type = ‘modelPanel’)
for eachmodelPanel in modelPanels:
cmds.modelEditor( eachmodelPanel, e=True, allObjects= False)
“`
[Docker] seleniumでUserProfileを利用する
## 前置き
こんにちは。Dockerを用いたpython環境でseleniumを利用しようとした際、UserProfileを利用するところで詰まったので共有します。調べたところによると、この不具合はlinux環境のみで生じるようです。
## TL;DR
“`Dockerfile
FROM joyzoursky/python-chromedriver:3.7-seleniumARG UID=1000
ARG GID=1000
ARG USERNAME=hoge
ARG GROUPNAME=fuga
# UID, GIDはDockerを利用するユーザーに合わせる
# `id`コマンドで確認可能RUN groupadd -g $GID $GROUPNAME && \
useradd -m -s /bin/bash -u $UID -g $GID $USERNAMECOPY . /home/$USERNAME/
WORKDIR /home/$USERNAME/RUN pip install –upgrade pip
RUN pip install –up
maya python world transform
“`python
from maya.api.OpenMaya import MVector, MMatrix, MPoint
import maya.cmds as cmdsdef get_world_transform (obj):
return MMatrix ( cmds.xform( obj, q=True, matrix=True, ws=True ) )selected_object = (cmds.ls(sl=1,sn=True))[0]
print ( get_world_transform( selected_object ) )
“`
クッキー画像でサクッと異常検知AIを作る
# 動機
AIを使って異常検知(製品の良品・不良品を見分ける等)を行いたいと考えたことがある人は多いのではないでしょうか?実際にAIが得意とする分野ではありますが、実際に取り組んでみると、不良画像のデータが十分に収集できない、異常判定の可視化が難しいなど、躓くポイントが多かったりします。今回は、シンプルな実装かつ最小のリソースで異常検知を実現するための手法の一つとして「オートエンコーダ」と呼ばれるAIモデルを、実際のコードサンプルや動作例と共に紹介したいと思います。
# オートエンコーダ(自己符号化器)[^1]
オートエンコーダはニューラルネットワーク構造のパターンの一つで、入力データを一度低次元データに変換するパート(エンコーダ)と低次元データから画像を復元するパート(デコーダ)で構成されます。モデル全体の目的としては、入力データをなるべくそのままに出力することです。
入力データがそのまま出力データとして出てくることに何の意味があるねん、と思われるかもしれません。このAIモデルのミソは「**途中で縮小されたデータに変換される**」という部分です。これにより、モデルは元データ復元
【LINE WORKS】IFTTTを経由してカレンダーを連携してみる
# はじめに
LINE WORKSのカレンダー機能はAPIも提供されており、それを使うことでカレンダー上で何かの実行スケジュールを管理することも可能。今回は、IFTTTを経由してカレンダーの予定と連携する仕組みを作った。

# ソースコード
https://github.com/mmclsntr/lineworks-calendar-ifttt-integration## 利用した言語・フレームワーク等
– 言語 : Python 3.9
– デプロイ : [Serverless Framework](https://www.serverless.com/framework/docs)
– 開発フレームワーク : [AWS Lambda Powertools for Python](htt
gensimで類似単語を取得する
# はじめに
データ分析をする際に,とある単語に対する類似単語を取得したかった。# 概要
Pythonの自然言語処理ライブラリであるgensimと学習済み単語ベクトル表現を用いて,とある単語に対する類似単語を取得する。# 準備
pipでgensimをインストールする。
“`bash
$ pip install gensim
“`学習済み単語ベクトル表現をダウンロードする。今回はFacebookが公開しているfastTextを使う。結構サイズが大きいのでダウンロードには少し時間がかかる。
“`bash
$ wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.vec.gz
“`# プログラムの作成
ダウンロードした学習済み単語ベクトル表現と同じ階層にプログラムを作成する。
“`
directory
├── ruizi.py
└── cc.ja.300.vec.gz
“`“`Python:ruizi.py
import gensimmodel = g




