
- 1. ルーチンワークはPythonにやらせよう Seleniumで勤怠処理を自動化する
- 2. Kaggle超入門 ~タイタニック号の生存予測~(lightGBM編)
- 3. LambdaでSecretsManagerからシークレット情報を取得してみた
- 4. GiNZA入門2(基本操作編1)(基本的な使い方マスターを目指す方向け)
- 5. Youtube「広告をスキップ」を自動でクリック(python)
- 6. github actions を使って、pythonのpytest、flake8などの試しⅡ
- 7. OR-Toolsのシフトスケジュール問題のサンプルコードを解読してみた!!(その1:サンプルコードの概要)
- 8. OR-ToolsのAddBoolOrの使い方(基本編:動作を理解するためのサンプルコード)
- 9. 40歳初心者pythonでタプルを書き換えられるじゃん!
- 10. [習作]猫の種類判別アプリを作成してみた。
- 11. plotlyで軸の数値が省略される(1000=K)問題の解決
- 12. 【Django】prefetch_related の挙動を理解する
- 13. MySQLのProgrammingError
- 14. 機械学習の初心者が、信号処理フィルターに深層学習の適用を試みる
- 15. スマートスピーカーを使って日々の健康状態を記録してみた
- 16. Google SpreadSheetのデータを Pythonで取得する
- 17. pydicomを使って感動した話
- 18. SQLAlchemyのIntegrityErrorを一意制約違反の例外としてexceptしてはいけない
- 19. [AWS Lambda Powertools Python]API GatewayレスポンスのJSONシリアライズエラーに対応する
- 20. markovifyで文章生成時にKeyErrorが発生する【Python+markovify】
ルーチンワークはPythonにやらせよう Seleniumで勤怠処理を自動化する
# はじめに
本記事は勤怠管理システムにおける日々の勤怠入力を自動化し、ルーチンワークを自動化するための方法について記載しています。勤怠入力などのルーチンワークを自動化することで、日々の勤怠入力にかかる時間を削減します。
また入力漏れや入力不備を防止し、入力不備によって発生する対応がなくなることで、余計なストレスを低減できます。## 概要
本記事で紹介している勤怠処理の自動化を行うための環境は以下の通りです。
OSはmacOSですが、Windowsの場合はタスクスケジューラを使用することで、同様の仕組みが構築できます。
| 項目 | バージョン等 |
|:———–|:————|
| OS |macOS |
| Python |3.8 |
|
Kaggle超入門 ~タイタニック号の生存予測~(lightGBM編)
# 目的
前回、kaggleのタイタニック号生存予測のデータの確認を行なったので、今回は実際にモデルで訓練・予測を行っていきたいと思います。その過程で、モデルの特徴やモデル選択、モデル評価、パラメータ調整の手法など学んでいければと思います。
# モデル選択
モデル選択に関しては、まず教師あり学習か、教師なし学習かを理解する。今回は教師あり学習であるためカテゴリ予測である分類問題か、数値予測の回帰問題かで大まかに使うモデルを絞り込める。
今回は、生存しているかどうかを分類するので分類問題である。
モデル選択のやり方として、scikit-learnのドキュメントに以下のようなアルゴリズムチートシートというものがある。

今回の例だと、まず、LinearSVCを試し、精度が良くなければK近傍法分類、その後カーネルSVCもしくはアンサンブルモデルを利用す
LambdaでSecretsManagerからシークレット情報を取得してみた
# はじめに
Githubから流出したソースコードに認証情報が含まれていて
問題になったというセキュリティーインシデントを見かけることがあります。
ソースコード内には認証情報をベタ書きせずに扱う事が大切です。Lambdaで認証情報を参照したい時のベストプラクティスとして
SecretsManagerから値を取得する方法があります。
ハンズオンとして行ってみたので記事に残したいと思います。# 環境
Lambdaのランタイム:Python3.9# SecretsManagerでシークレット情報を作成する
SecretsManagerでは目的に応じたシークレット情報の作成が可能です。
今回は汎用的に使用できるように「その他のシークレットタイプ」でユーザー名とパスワードを作成しました。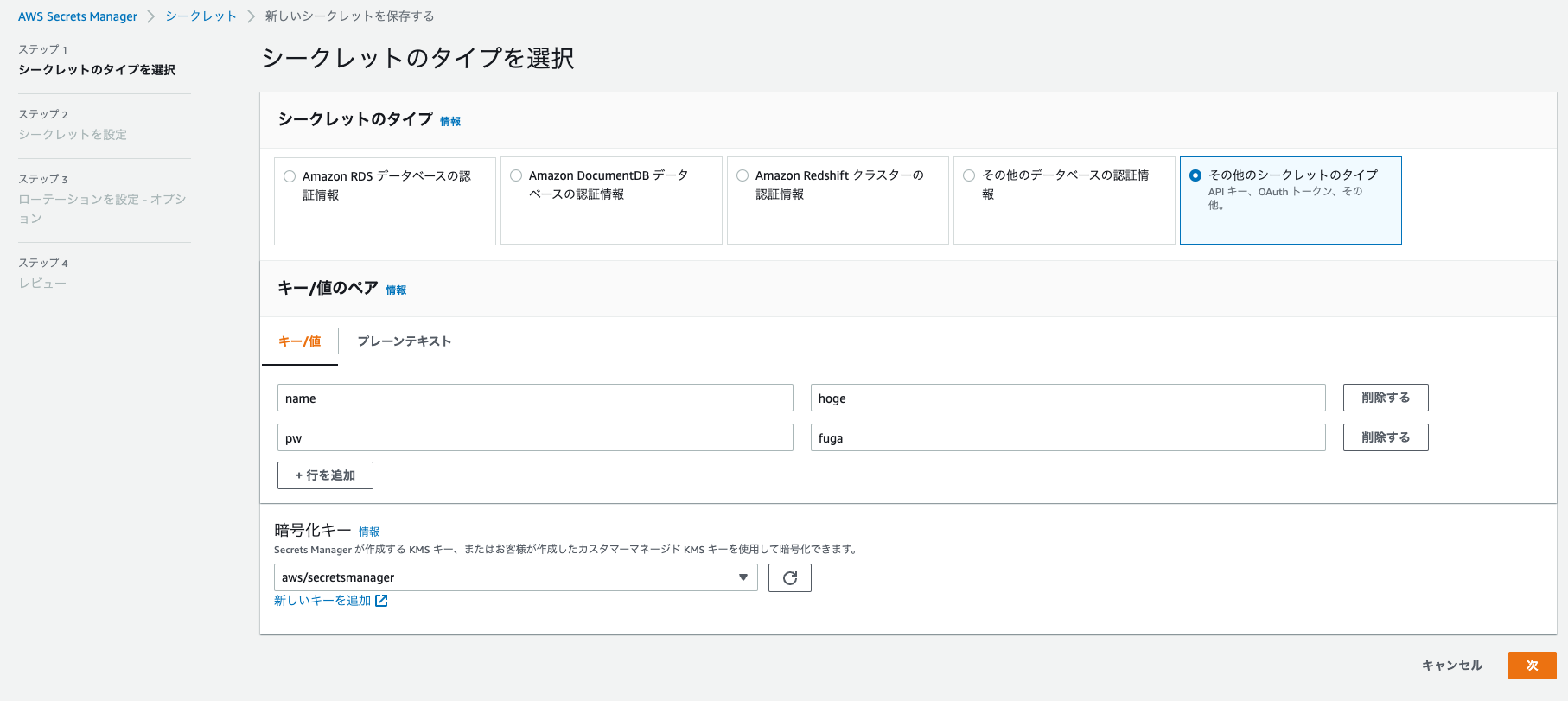
GiNZA入門2(基本操作編1)(基本的な使い方マスターを目指す方向け)
こんにちにゃんです❕
GiNZA入門に関する記事2本目です。
この記事ではGiNZAの基本的な操作方法について書いていきます。
まず主にGiNZAで出来ることは次の通りです。

一つ一つ説明していきます。まずGiNZAを用いるために、spaCyをインポートします。
そうしたらそのあとGiNZAのロードを行い、nlpという変数に渡します。
GiNZAではdocクラスというものがあります。
docクラスはこの後説明する解析の結果を保持するクラスで、doc=nlp(文章(str型))で解析が完了します。
簡単に言うと文章とそれに関する情報をまとめて持っているというイメージです(どこからどこまでが一つの単語かなど)“`ruby:sent_div.py
import spacynlp=spacy.load(‘ja_ginza’) #GiNZ
Youtube「広告をスキップ」を自動でクリック(python)
PythonがWindows上できちんと動くことに今更ながら気づき、ちょっと楽しくなっております。
Youtubeの「広告をスキップ」を自動でクリックするプログラムを書いてみました。
画面内で「広告をスキップ」が出てくる領域を指定して、OCR処理で文字列化して、
「広告をスキップ」が出るまで、待ち続けて、出たら、自動クリックするプログラムです。画面クリックは、「pyautogui」
文字列OCRは、「Tesseract-OCR」、「pyocr」
GUI化は、「PySimpleGUI」
を利用していています。といいますか、これらのツールの利用方法の勉強ですね。
各ツールをインストールしてください。参考にさせていただきましたページ
[Tesseract、pyocr]
https://qiita.com/ku_a_i/items/93fdbd75edacb34ec610
[pyautogui]
https://slash-z.com/python-pyautogui/
[pysimplegui]
https://www.pysimplegui.org/en/latest/
github actions を使って、pythonのpytest、flake8などの試しⅡ
# はじめに
共有いただいた下記の記事はうまく行かないパータンを見つけた。補足として、対応方法を共有させていただきました。https://qiita.com/Guan21/items/c5b2ca69710763638ee2
# Target
– 以下のディレクトリ構成で、github actionsで、「ubuntu環境」と「Docker仮想環境」それぞれの自動テストが無事に実行できること。### ディレクトリ構成
~~~bash.sh
├── .github
│ └── workflows
│ ├── pipenv.yml
│ ├── pytest.yml
│ └── pythonPipenv.yml
├── source
│ ├── modules
│ │ ├── tests
│ │ │ └── test_util.py
│ │ └── util.py
│ ├── static
│ │ └── style.css
│ ├── templates
│ │ ├── error.
OR-Toolsのシフトスケジュール問題のサンプルコードを解読してみた!!(その1:サンプルコードの概要)
# 内容
– Googleの数理最適化ツール[OR-Tools](https://developers.google.com/optimization)のサンプルコードとして公開されている、[シフトスケジュール問題を解くプログラム](https://github.com/google/or-tools/blob/master/examples/python/shift_scheduling_sat.py)に、解説がついていなかったため、勉強がてら、解読してみました。
– その1では、「[シフトスケジュール問題を解くプログラム](https://github.com/google/or-tools/blob/master/examples/python/shift_scheduling_sat.py)の概要」をまとめています。目次は、以下の通りです。
– シフトスケジュール問題の概要
– シフトの表現
– 目的関数
– 制約条件
– ハード制約条件
– ソフト制約条件
– 別途、制約条件をいくつか抜粋して、実装の仕方の例を紹
OR-ToolsのAddBoolOrの使い方(基本編:動作を理解するためのサンプルコード)
# 内容
– 備忘のため、Googleの数理最適化ツール[OR-Tools](https://developers.google.com/optimization)の、cp_modelモジュールのCpModelクラスの[AddBoolOrメソッド](https://developers.google.com/optimization/reference/python/sat/python/cp_model#addboolor)の使い方をまとめてみました。– 「基本編 その1」では、AddBoolOrメソッドの動作を理解するためのサンプルコード(ハード制約)とその実行結果を紹介しています。
– OR-Toolsのエキスパートの方には、少々退屈な内容かもしれません。初心者の方であれば、参考になるかもしれません。
# 注意
– 当方、OR-Toolsの初心者です。おおむね理解したつもりで書いていますが、もしかしたら間違っているところがあるかもしれません。ご容赦下さい。# AddBoolOrメソッド
– 数理最適化のモデルに、制約条件を加えるメソッドのひとつ。OR-Toolsの
40歳初心者pythonでタプルを書き換えられるじゃん!
pythonのタプルって書き換えられないってあるけど、書き換えられました
っていうかこういう方法あるんだなぁ~ってびっくりしました海外SNSのどっかでみつけた
l=(1,2,3,4,5)
print(l)
s1,s2,s3,s4,s5 = l
s2 = 6
l = s1,s2,s3,s4,s5
print(l)結果
(1, 2, 3, 4, 5)
(1, 6, 3, 4, 5)
[習作]猫の種類判別アプリを作成してみた。
# はじめに
こんにちは。機械学習初学者です。
今回はAidemyさんの「AIアプリ開発講座」を受講し、その成果物として簡単なアプリの開発を行いました。
テーマは「猫の種類判別」です。参考にしたサイト
参照1:[ねこと画像処理 part 3 – Deep Learningで猫の品種識別](https://rest-term.com/archives/3172/)
参照2:[ネコと犬の種類判別器を作ってみた](https://qiita.com/nekotanku/items/9fe1f454460c3656c370)# 開発環境
・Google Colaboratoryほぼ全編にわたって`Google Colaboratory`にて開発を行いました。
パソコンとの画像のやり取りは`Google Drive`との連携が簡単ですので、まずは連携させておきます。[【Google Colaboratory】Google ドライブにマウントし、ファイルへアクセスする方法](https://blog.kikagaku.co.jp/google-colab-drive-mount
plotlyで軸の数値が省略される(1000=K)問題の解決
# 現状
以下のグラフだと縦軸が400Kや200Kになってしまう。
実際の値は400,000 や200,000であり、そのままの値で表示したい場合がある。
# 解決策
以下のコードを入れるのみ。
“`
fig.update_yaxes(
tickformat=”d”,
)
“`
eや%表記がしたい場合は以下参照
tickformatのところを変えるといろいろできそう。https://github.com/d3/d3-format/tree/v1.4.5#d3-format
# ち
【Django】prefetch_related の挙動を理解する
# Djangoのprefetch_relatedについて
prefetch_relatedはDjangoのN+1問題を回避するための機能です。
select_relatedと並び重要なメソッドですが、理解が曖昧な部分があったので整理したいと思います。## DjangoのSQLが実行されるタイミングについて
DjangoがDBを叩きにいくタイミングについて確認しておきます。### 1.メソッドが呼ばれたタイミング
いくつかのメソッドはクエリセットは返さずに、呼び出されたタイミングでDBを叩きに行きます。
代表的なものをあげておきます。
| メソッド名 | 機能 |
| —- | —- |
| first() | はじめの一つを取得する。返す値がない場合は None を返す |
| last() | 最後の一つを取得する。対象がない場合は None を返す |
| get() | 一つのオブジェクトを返す。対象が1つ以外の場合は models.DoesNotExists, models.MultipleObjectReturned エラーが起きる|
| count() |
MySQLのProgrammingError
何のエラーか探すのに困ったシリーズ。
環境:
Windows10
Python3.7(Anaconda)
MySQL“`
ProgrammingError: (1064, “You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘99999.9e9’ at line 999”)
“`Python側のpymysqlモジュールにて、
MySQL文のLIMIT句に渡した変数が
予期せず float型 になっていたからだった。
行数だから int型 でないとダメ。ProgrammingError:
なんて出たから、SQL文が悪いのかとずいぶん考えた。
ま、プログラミングのエラーと言えば間違いないが・・・
このエラーが出てハマった際、参考になれば幸い。
機械学習の初心者が、信号処理フィルターに深層学習の適用を試みる
# はじめに
初めまして、ソフトウエア設計者のnakarinrinと申します。
ソフトウエア設計を組込/PCアプリ中心に30年程携わり、その後10年近く管理職と
なっていました。退職を機にソフトウエア設計に再び関わりたいと思っていますが
あらたな技術を習得すべく、アイデミーさんのAI講座を受講しています。
その中で受講の成果として、成果物に関する記事を作成する必要があり、今回
稚拙な内容ですが投稿させていただきます。なお、本記事記載の開発は
Spyder 4.2.5
にて以下を使用して行いました。
Python 3.8.8
numpy 1.22.3
matplotlib 3.5.1
tensorflow 2.9.1
scikit-learn 1.1.1# 本記事の概要
深層学習の手法の一つであるオートエンコーダ(Autoencode)を信号の振幅等に反応する
特殊なフィルタに利用した適用例と欠点を記載してしています。
残念ながら実用的に利用できるフィルターとなっておりませんので、まだまだ改善が必要
な例です。深層
スマートスピーカーを使って日々の健康状態を記録してみた
## はじめに
ウェアラブル端末はヘルスケア目的としても活用が可能で、利用者は睡眠や運動などのデータを連携アプリから確認して日々の健康管理ができます。これらのデータに加えて、スマートスピーカーからも主観的な健康状態を記録し観察することで、もっと確実な健康管理ができるのではないかと考え、この仕組みを作ってみることにしました。
## 完成イメージ
決まった時刻になると、Amazon Echoが3つの質問を対話形式で行います。全ての質問に答えると、バックエンドのデータベースに回答した健康情報を登録します。
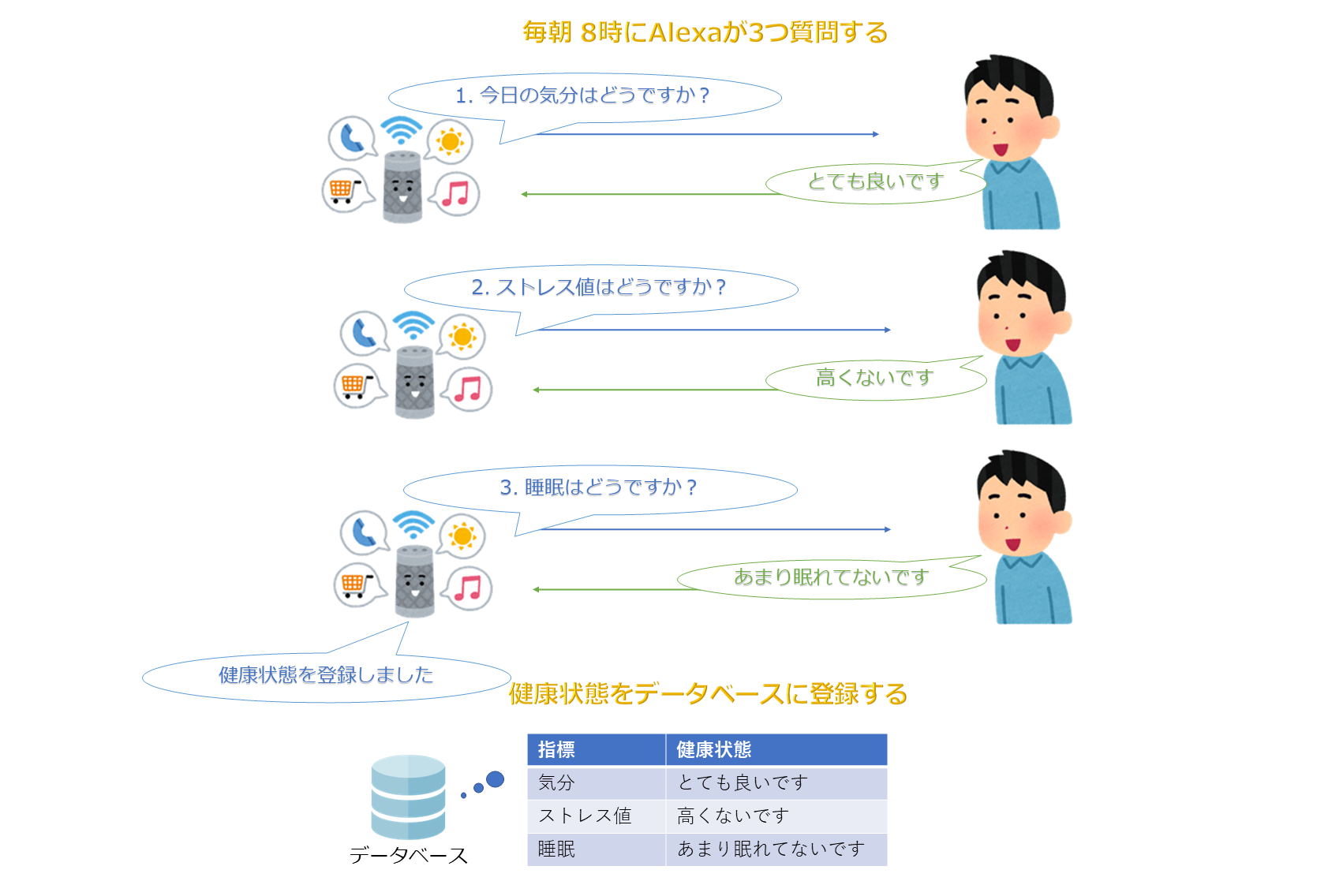## 概要
今回紹介するAlexaスキルを作るには以下の3つの実装と設定が必要です。
本記事では、初めてAlexaスキルを作成することを想定し、事前準備として必要なアカウント登録方法から順に記載していきます。– Alexaスキルの設定
Google SpreadSheetのデータを Pythonで取得する
# 目的
## 概要
ヴェネクト株式会社のディレクター 小峰です。
今回の記事では、Google SpreadsheetのデータをPythonで取得する方法をご紹介します。
VENECT内での活用事例を踏まえつつ、下記の要素を説明します。– どのPackageを利用すべきか
– アカウント認証をどのように行うか
– Google Spreadsheetのデータをどう取得するか
– 活用しやすいようにDataFrame変数に加工する## VENECTでの利用例
VENECTでは、Google Spreadsheetで記載される情報をBigQueryに送信するために利用しています。社内担当者が手動で入力・管理したい情報をGoogle Spreadsheetのテンプレートで管理し、PythonのアプリケーションでBigQueryに送信しています。そのデータを、システム側で処理し、マーケティングに必要なデータを加工して生成しています。# プログラム実行環境
## 利用するPackage
Google Spreadsheetのデータにアクセスするために、__gspread__ という
pydicomを使って感動した話
# プロローグ
テストのために数多くのDICOMファイルが必要になったヤマトンボ。
ネット上で拾えるDICOMだけでは到底テストを満たすファイルをそろえることができない。
タグ情報を変更すれば、テストの条件を満たすファイルを作り出すことができるが、DICOM Viewerを使ってポチポチ変えていくのは、時間もかかるしエンジニアらしくない。
そう思いながらいい手段はないかと調べていたら、**pydicom**を使えば簡単にDICOMファイルの操作が行えるらしいことが分かった。
「これは良さそうだ」
ヤマトンボはpydicomを使って、テスト用のファイルを作り出すことを決意するのだった。# マシンスペックとPythonのインストール
OS:Windows 10
CPU:Intel(R) Core(TM) i7-8665U CPU @ 1.90GHz 2.11 GHz
メモリ:16GBこのマシンに、Python 3.10.xをインストール
インストール方法は次のHPを参照しました。[windows版Pythonのインストール](https://www.python.jp/in
SQLAlchemyのIntegrityErrorを一意制約違反の例外としてexceptしてはいけない
# はじめに
SQLAlchemyで一意制約違反した時に、以下のようなエラーが発生します。
“`
sqlalchemy.exc.IntegrityError: (sqlite3.IntegrityError) UNIQUE constraint failed: user.email_address
“`
一見、 `IntegrityError`の例外をexceptで囲んで一意制約違反の例外として処理したくなります。
しかし**これはNGです。**# なぜNGなのか
`IntegrityError`は一意制約違反のエラーではなく**DBのエラー全般をラップしたエラー**だからです。
つまり**一意制約違反**以外にも**NOT NULL制約違反**や**外部キー制約違反**も`IntegrityError`になります。以下は悪い例です。
“`python:悪い例
def create_user(session, user_name, email):
try:
user = User(user_name=user_name, e
[AWS Lambda Powertools Python]API GatewayレスポンスのJSONシリアライズエラーに対応する
# 概要
[AWS Lambda Powertools Python](https://awslabs.github.io/aws-lambda-powertools-python/latest/) を使うとAPI Gatewayのリソースマッピングが直感的に記述できます。
また、dictなりlistなりをreturnしておけば良い感じのJSONテキストにしてくれる等、とても便利です。このレスポンスをJSONに変換してくれる部分で少し困ったので、対応した内容を記録します。
# 準備
AWS Lambda Powertools をインストールします
“`
$ pip install aws-lambda-powertools
“`# サンプルハンドラーコード
リクエスト `GET /info` に対して、`name` と `created` 要素を返すシンプルな内容です。
問題点に特化したサンプルですが、リクエストと処理が一目でわかる仕組みになっています。“`handler.py
from datetime import datetime
from aws
markovifyで文章生成時にKeyErrorが発生する【Python+markovify】
# 経緯
markovifyを用いて自分のツイートから文章を自動生成してツイートするbotを作った。
ツイートするだけじゃ物足りないのでリプライを送る機能を追加しようとした。
リプライを送る際、送り先のツイートから単語を抜き出してその単語を起点として文章を自動生成しようとした。
ここでエラーが発生した。# 内容
発生箇所のコードは以下の通り
“`test.py
model = markovify.Text(text, well_formed=False, state_size=3)
sentence = model.make_sentence_with_start(beginning=’テスト’)
“`エラーの内容は以下の通り
“`
KeyError: (‘___BEGIN__’, ‘___BEGIN__’, ‘テスト’)
“`これは、“テスト“という単語を起点としてマルコフ連鎖を行い文章を自動生成する処理。
“make_sentence_with_start“関数の引数“beginning“が起点となる文字を表している。“markovify`




