
- 1. 最大実行時間9分→60分になった第二世代CloudFunctionsを使ってみた。
- 2. AWS Lambdaで動かすStable Diffusion/Waifu Diffusionをちょっと効率的に使うTips
- 3. Python lambda解説
- 4. AWSに特化したChaliceフレームワークを触ってみた
- 5. Lambda(Python)のテストイベントを作成するために、関数の先頭に入れる1行
- 6. AWS API Gateway Lambda オーソライザーを使用してアクセス制御を行ってみる
- 7. Waifu DiffusionをAWS Lambdaで動かしたい
- 8. 画像生成AI Stable DiffusionをAWS Lambdaで動かす(img2img対応)
- 9. Selenium Wireが出力するHARファイルをAWS Lambda上で分析する(JSON/Pandas/Seaborn)
- 10. lambda invokeがnat gateway経由で通信していた
- 11. 1日の振り返りを簡単に楽しくできるSlack botを作ってみた(furikaeru)
- 12. 俺みたいになるな!Lambda+Node.jsでDynamoDBにputItemするだけで半日溶かしたAWS SAP
- 13. AWS Lambda + Node.jsの実行環境でローカルタイムを扱いたいが、とりま日本時間JSTに甘んじる(JavaScript)
- 14. AWS LambdaにリクエストしたらNo ‘Access-Control-Allow-Origin’ header is present on the requested resourceのエラーがでた.
- 15. 【AWS】Lambdaコンテナイメージ利用に対する覚え書き
- 16. Aurora Serverless v2のスケールアップ・スケールダウンをスケジューリングする
- 17. Lambda で CloudWatch Logs のログを自動で S3 にアーカイブする、をちょこっと便利にした。
- 18. AWS Step Functions で簡易的なジョブ管理ステートマシンを作成してみる
- 19. LambdaでSecretsManagerからシークレット情報を取得してみた
- 20. Node.jsランタイムのLambdaでNodeモジュールを使いたいときにやったこと
最大実行時間9分→60分になった第二世代CloudFunctionsを使ってみた。
# tl;dr
– 2022年8月にGAとなった第二世代CloudFunctions(以下CF)。主な変更点として、最大使用可能リソースと最大実行時間が大幅に増加した。(具体的な変更点は[こちら](https://shinyorke.hatenablog.com/entry/cloud-functions-gen2))
– 最大実行時間が`9分→60分`と、AWSのFaaSであるLambda(最大15分)も屁じゃないくらいに最大実行時間が増えたように聞こえるが、実際には`HTTP関数以外の最大実行時間は今まで通り9分のまま`([参考](https://cloud.google.com/functions/docs/configuring/timeout?hl=ja))。# やったこと

– pan
AWS Lambdaで動かすStable Diffusion/Waifu Diffusionをちょっと効率的に使うTips
# はじめに
LambdaでStable Diffusion/Waifu Diffusionを動かすと、画像生成に1枚当たり約3分かかります(パラメータで前後します)。
基本的な作業の流れとしては次のとおりですが、、**prompt等のパラメータの設定→Lambda実行→【画像生成[3分待機]】→画像ダウンロード→チェック→パラメータの・・・(略)**
面倒です。特に3分待機が。煩雑です。
ということで本記事はこの辺りの状況を少しだけ改善するための小ネタです。
なお、AWS LambdaでStable Diffusion/Waifu Diffusionを動かすためのプロジェクトは次のものを使用します。
最新版のソースコード一式をクローン or ダウンロードしてご利用ください。https://github.com/densenkouji/stable_diffusion.openvino.lambda
# 前提
– AWS CLI、Docker、Pythonはインストール済み
– 「aws configure」でAWS Access Key ID、AWS Secret Acc
Python lambda解説
# lambdaとは?
無名関数のこと。
関数を短く書けて便利。
関数名がないので、何回も使いまわしたい関数には使わない。# 書き方
## 基本
“`
lambda 引数 : 処理
“`
## lambdaを使わない例と、使った例
### lambdaなし
“`
def example(x, y):
return x + y
“`
### lambdaで書いた場合
“`
lambda x,y : x+y
“`
関数名なしで、短く書ける
## lambdaの引数に値を入れる時
さっきの例のxとyに値を入れる時の書き方
“`
(lambda 引数:処理)(引数に入れたい値) と書くので、
(lambda x,y : x+y)(1,2)
となる
“`
AWSに特化したChaliceフレームワークを触ってみた
今回とあるプロジェクトでChaliceのフレームワークを使うことになり、その導入資料を作成したので、記事として残そうと思います。
## Chaliceとは
Chaliceは、Amazon製であるため、AWS専用のフレームワークとなっています。
– デプロイ周りを簡単にかつ自動で構築できるため、コードを書くことに集中できる
– Flask、bottle、FastAPIなどのフレームワークで使用されているおなじみのデコレーターベースの構文を使用しているため、学習コストが低い
– さまざまなデプロイツールに対応しているため、自分が慣れ親しんだデプロイツールを利用できる(TerraformやAWS SDKなど)公式ドキュメントではデプロイまでの時間が早いことを示すため、ターミナルでの実行時間を見れるようにしています。
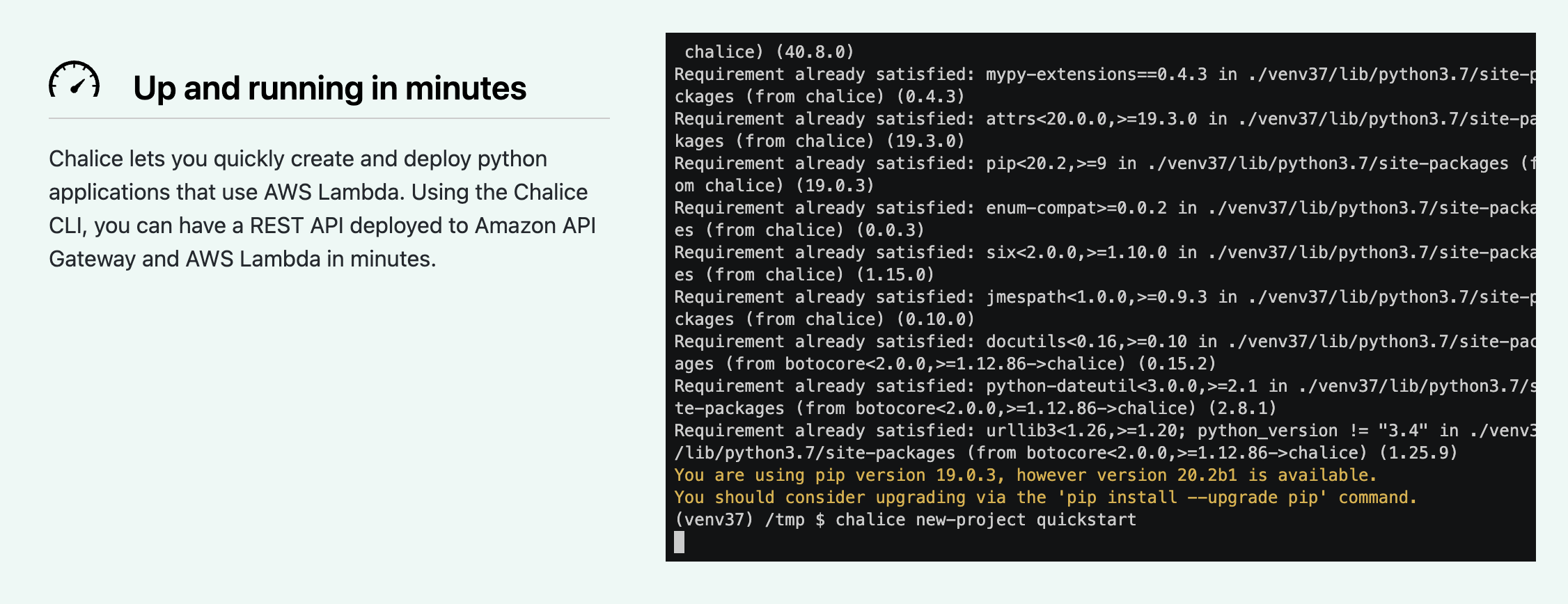
とても自信がおありの
Lambda(Python)のテストイベントを作成するために、関数の先頭に入れる1行
# はじめに
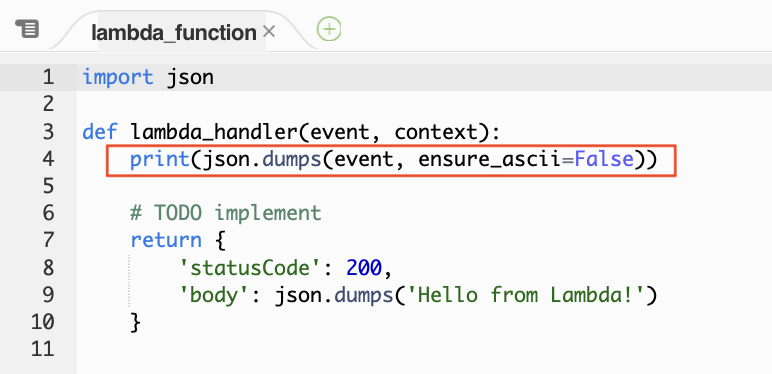
「API Gateway→Lambda」などのLambdaを書くときに、最初にlambda_handlerのeventに渡ってくるデータを取得したい場合のワンライン、コピペ用メモです。# Lambda
“`Python
print(json.dumps(event, ensure_ascii=False))
“`
まず、この1行を入れて、APIを送信するなどして、Lambdaを動かします。
eventの内容をCloudWatchLogsから取得して、テストのイベントJSONに使います。
# おわりに
小技として記事にしてみました。
AWS API Gateway Lambda オーソライザーを使用してアクセス制御を行ってみる
# Lambdaオーソライザーとは
API Gatewayを使うとインターネット上にREST APIを公開できます。
そしてLambdaオーソライザー(以前のカスタムオーソライザー)は、Lambda関数を使用してAPIへのアクセスを制御するAPI Gatewayの機能です。(公式より抜粋)# 実行イメージ
Lambdaオーソライザーの実行イメージは以下の通りです。(公式より抜粋)
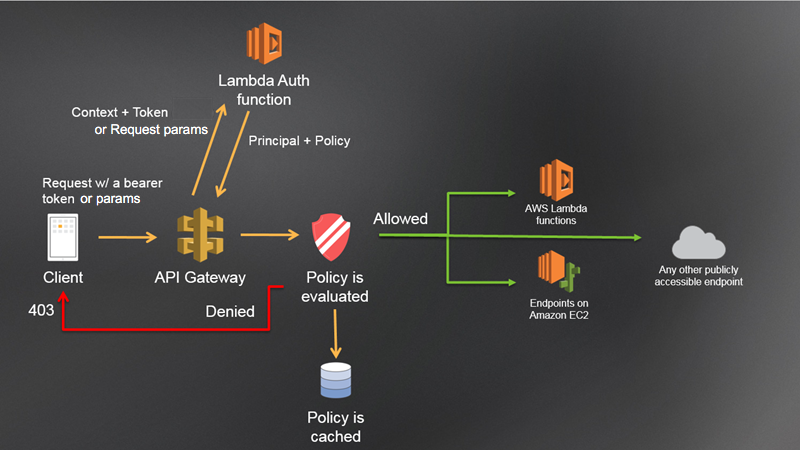
1. ClientがAPI Gatewayにアクセス
1. API Gatewayは必要情報をLambda Auth functionに送信
1. Lambda Auth functionは入力情報を元に認証を行った後、アクセス許可orアクセス拒否を返す
1. アクセスが拒否された場合、API GatewayはHTTP403等のエラーステータスをClientに返す
Waifu DiffusionをAWS Lambdaで動かしたい
# はじめに
本記事は以下の記事の内容を補足するものです。https://qiita.com/densenkouji/items/4db5a29f539b87de91e3
—
AWS LambdaでStable Diffusionを動かす場合、「数GBもあるモデルをどこに格納するのか?」という課題があります。
当初はモデルを任意に変えられるようオリジナルである「stable_diffusion.openvino」から特に変更せず、パラメータでモデルを指定可能にしていたのですが、これだと以下の問題がありました。
* モデルのダウンロードが都度発生する
* ダウンロードしたモデルを保存するためのエフェメラルストレージのサイズを増やす必要がある(モデルのサイズ分+α)これらはLambdaの特性に起因する問題で致し方ないのですが、どちらもコスト増につながるため、現在はモデルをDockerイメージに含めるようにしています(これはこれでDockerイメージの増大になり、別の問題が発生しますが…)。
そのためモデルを変更したい場合はDockerfileを修正する必要があります。そこ
画像生成AI Stable DiffusionをAWS Lambdaで動かす(img2img対応)
# はじめに
本記事はAWS Lambda上でStableDiffusion(img2img)を動作させることをゴールとします。
ソース一式はGitHubに置いてあるため、使い方の解説など特に必要ない方はそちらを参照してください。https://github.com/densenkouji/stable_diffusion.openvino.lambda
:::note info
本プロジェクトは「stable_diffusion.openvino」プロジェクトを基にAWS Lambdaに移植したものです。
https://github.com/bes-dev/stable_diffusion.openvino
:::# 実行結果
次節に示す手順を進めていただくことにより、AWS Lambda上で画像を作成することができます。
(コマンドの–function-nameにはデプロイしたLambda関数名を指定します)
“`sh:実行例
aws lambda invoke \
–function-name mySdFunction-yty7mdazmzzlywey \
Selenium Wireが出力するHARファイルをAWS Lambda上で分析する(JSON/Pandas/Seaborn)
# HARファイル(JSON)を加工して分かりやすくしたい
その汎用性から言語や場面を問わずJSON形式のデータが飛び交うようになり、結果としてJSON形式を扱うことが可能なライブラリも多種多様なものが開発/公開されています。先日Selenium Wireに関する記事を投稿しましたが、Selenium Wireの処理結果としての通信情報もJSON形式のHAR(HTTPアーカイブ)ファイルとして取得できます。
中身はHTTP(S)通信なので、その基本的な構造はリクエストとレスポンスのセットが複数個並んでいる単純なものではあるのですが、通信ログはそのままだと不要な情報も多く、一見すると圧倒されがちです。
HARの汎用的なビューアもあるとはいえ都度ビューアで内容を確認するよりも、自分の望む情報が分かっている場合は直接HARファイルを操作した方が効率的な場合もあることから、今回はAWS Lambda上でHARファイルを基にした解析っぽいことをしたいと思います。なお、対象とするHARファイルや環境など、前回の記事を(一部)基にしています。
# 注意事項
– HARファイルには通信内容が
lambda invokeがnat gateway経由で通信していた
Private VPCからLamdaをInvokeした際、Nat Gatewayを経由して通信 => NatGateway経由で通信費がかかっていた。
そらそーだ
VPC EndPoint作成することで回避可能。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/configuration-vpc-endpoints.htmlとはいえ、VPC Endpointも0.014$/h掛かるのも留意点。
Subnet単位でかかるので、3subnetsへ設定すると30$/monthくらい固定で必要。
1日の振り返りを簡単に楽しくできるSlack botを作ってみた(furikaeru)
## :frog: 解決したい課題
僕のチームでは有志のメンバーが、毎晩仕事が終わるときに、Slackのチームチャンネルで一日の振り返りを投稿しています。目的は2つ。
自分の頭の整理と、チームメンバーへの共有です。しかし、毎回フォーマットをコピペしに探しに行ったり、今日自分がやったことを思い出す作業にはまぁまぁの負荷があります。一日真剣に働いて、ウィルパワーが消耗し切っているのに、これはキツイです。それで、なかなか毎日続かない。一度サボると、やらなくなってしまう。そんな循環を繰り返しています。
それを少しでも楽にできるようにしようということで、botアプリを作りました。
アプリの名前は`furikaeru`にしました。:frog:
`今は一般公開はしていませんが、一応それも見据えてコード書いたので、ゆくゆくできたらと考えていたり、考えていなかったり。`会社のインフラ使わせてもらっているので、インフラ代が気になるところ。:money_with_wings:
## :frog: 仕様
### 実装済みのもの
#### 1. アプリをチャンネルに招待するアプリのいないチャ
俺みたいになるな!Lambda+Node.jsでDynamoDBにputItemするだけで半日溶かしたAWS SAP
## やりたいこと
ただただシンプルにLambdaでDynamoDBに書き込みたい。それだけなんです。初体験でも無い。
なのにハマって、シルバーウィークの初日の半日それで溶かしてしまいました。
AWS SAPの称号を剥奪されるかと思って誰にも相談できませんでした。https://qiita.com/kakudaisuke/items/174ff82b558b86d041b4
ちなみに、なんでそんなことしたいかというとコレです↓ :frog:
https://qiita.com/kakudaisuke/items/18681418cebc3bee93b5
## 実装!
### DyanmoDBの設計
完了したタスク(task)を、ユーザー(user)、日付(date)ごとに登録したいです。
で、取り出す時はあるuserとdateのtaskを全て取得したい。試行錯誤の末、保存したいアイテムはuser, unixtime, date, taskにしました。
ちなみに、user, dateはDynamoDBの予約語。予約語だけど使えちゃう。queryする時にちょい厄介だけど使
AWS Lambda + Node.jsの実行環境でローカルタイムを扱いたいが、とりま日本時間JSTに甘んじる(JavaScript)
## やりたいこと
AWS Lambdaで時間を扱うのに、日本時間JSTが欲しい。(本当はローカルタイムが欲しい。)
だけど、Lambdaではローカルタイムという概念がないらしく、全てUTCになってしまう。
日本時間JSTが欲しいと思っていると、9時間ずれた値が返ってきたり、表示が`19/9/2022`となって欧米か!とツッコミたくなったり、してしまう。ちなみに、なんでそんなことしたいかというとコレです↓ :frog:
https://qiita.com/kakudaisuke/items/18681418cebc3bee93b5
## 実装!
色々調べたが簡単に済ませたかったので、とりま+9時間してJ、日本的なフォーマットに自力でした。“`js:index.js
let dateTime = new Date();// JSTにする
time.setHours(dateTime.getHours() + 9);// 2022/9/19の形にする
const year = dateTime.getFullYear();
const month = dateTim
AWS LambdaにリクエストしたらNo ‘Access-Control-Allow-Origin’ header is present on the requested resourceのエラーがでた.
LambdaにAPI Gatewayを通して,リクエストしたところ
“`
Access to XMLHttpRequest at ‘<リクエストURL>‘ from origin ‘<オリジン名>‘ has been blocked by CORS policy:
No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
“`
のエラーが出ました.CORSの設定をしていたのに,このようなエラーが出ました.
また,通信が成功するときもありました.## 原因
Lambdaの実行時間制限が少ないことが原因でした.
以下,Lambdaのコンソール画面にあるtimeoutが実行時間制限です.
デフ
【AWS】Lambdaコンテナイメージ利用に対する覚え書き
## はじめに
機械学習用のライブラリを利用したAPIをLambdaで構築しようとした場合など、
デプロイパッケージサイズ制限(250MB)により利用できないケースがあります。その場合の対応方法としてコンテナイメージをLambdaで利用できるようになっていますが、
実際にLambdaコンテナイメージを使って構築/動作確認するまでに結構ハマったところがあるのでdockerfile作成からAmazon ECRへのプッシュまでを本記事にまとめます。同じくハマっているひとの参考になればと。※リポジトリの作成等の操作はSKIPしています
***
## 環境
Windows 10 Pro (WSL2を利用)
Docker v20.10.17## 目次
1. dockerfileを用意する(例としてPythonが動作するコンテナを作成)
2. dockerでコンテナを作成する
3. 作成したコンテナをAmazon ECRにプッシュする
4. ハマったところ### 1. dockerfileを用意する
“`dockerfile:dockerfile
#
Aurora Serverless v2のスケールアップ・スケールダウンをスケジューリングする
## Aurora Serverless v2
Aurora Serverless v2は、AWSマネージドな新しいDBインスタンスです。
Aurora Serverless v2ではインスタンスタイプではなくACU(Aurora Capacity Unit)と呼ばれる値を設定し、性能を決定します。その際、ACUの最小値と最大値を設定することができ、DBの負荷に応じてこの範囲内で自動的にスケールアップ/ダウンすることが特徴です。
詳しくは[公式リファレンス](https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-serverless-v2.how-it-works.html?#aurora-serverless-v2.how-it-works.capacity)をご確認ください。このようにAurora Serverless v2は負荷に応じてスケールする機能がありますが、スケールアップする速度はその時点でのACUによって決まります。したがって、スパイクが予測できる場合、あらかじめACUをあ
Lambda で CloudWatch Logs のログを自動で S3 にアーカイブする、をちょこっと便利にした。
AWSで各種クラウドサービスのログを、CloudWatch Logで保管することができます。CloudWatch Logではログの保管日数を指定することができます。手動であればS3へログをエクスポートすることもできます。S3も保管したデータの保管日数を指定することができます。
となると、以下のような処理を自動で実装したいもの。
・各種ログをCloudWatch Logに保管する。
・ある程度の日数が経過したら、S3にログをアーカイブする。古いログはCloudWatch Logから自動削除。
・必要なだけS3で長期保管する。必要な保管期間を過ぎたログは、S3からも自動削除。しかし定期的に自動でS3へログをエクスポートする機能はありません。何度もググりましたが、皆さん同じ悩みをお持ちです(笑)
という事で、「CloudWatch Log」「S3」「エクスポート」「自動」といった用語でググれば、Lambdaで実装されている事例・記事が多く見つかります。本当に助かります。
# 【参考】
私がお世話になった記事です。https://qiita.com/tamura_CD/items
AWS Step Functions で簡易的なジョブ管理ステートマシンを作成してみる
AWS で簡易的なジョブ管理をしてみよう、という試みです。
# 概要
AWS 上でジョブ管理するにはどうしたら良い?という話がありましたので、自分なりに少し考えてみました。普通に考えれば、例えば以下のようになるかとおもいます。
* Cloud Watch Events、場合によっては Event Bridge を使ってジョブを起動する
* ジョブの流れは Step Functions で様々なフロー制御を組み込んで作成
* Step Functions から Lambda 関数、ECS RunTask、AWS Batch などを順次呼び出す
* ログは Cloud Watch Logs に格納
* 問題発生時には SNS から SES や Slack 連携などでアラートを発報するただですね、今回は以下のような制約をつけて考えてみました。
* 数人の小さなチームで、スケジュールがかなり厳しい中で開発する必要がある
* AWS に詳しいのは自分だけで、他のメンバーはこれから学ぶ必要があるこういった状態ですと、いまから AWS を学んでもらうのは効率が悪いです。期間も短いこと
LambdaでSecretsManagerからシークレット情報を取得してみた
# はじめに
Githubから流出したソースコードに認証情報が含まれていて
問題になったというセキュリティーインシデントを見かけることがあります。
ソースコード内には認証情報をベタ書きせずに扱う事が大切です。Lambdaで認証情報を参照したい時のベストプラクティスとして
SecretsManagerから値を取得する方法があります。
ハンズオンとして行ってみたので記事に残したいと思います。# 環境
Lambdaのランタイム:Python3.9# SecretsManagerでシークレット情報を作成する
SecretsManagerでは目的に応じたシークレット情報の作成が可能です。
今回は汎用的に使用できるように「その他のシークレットタイプ」でユーザー名とパスワードを作成しました。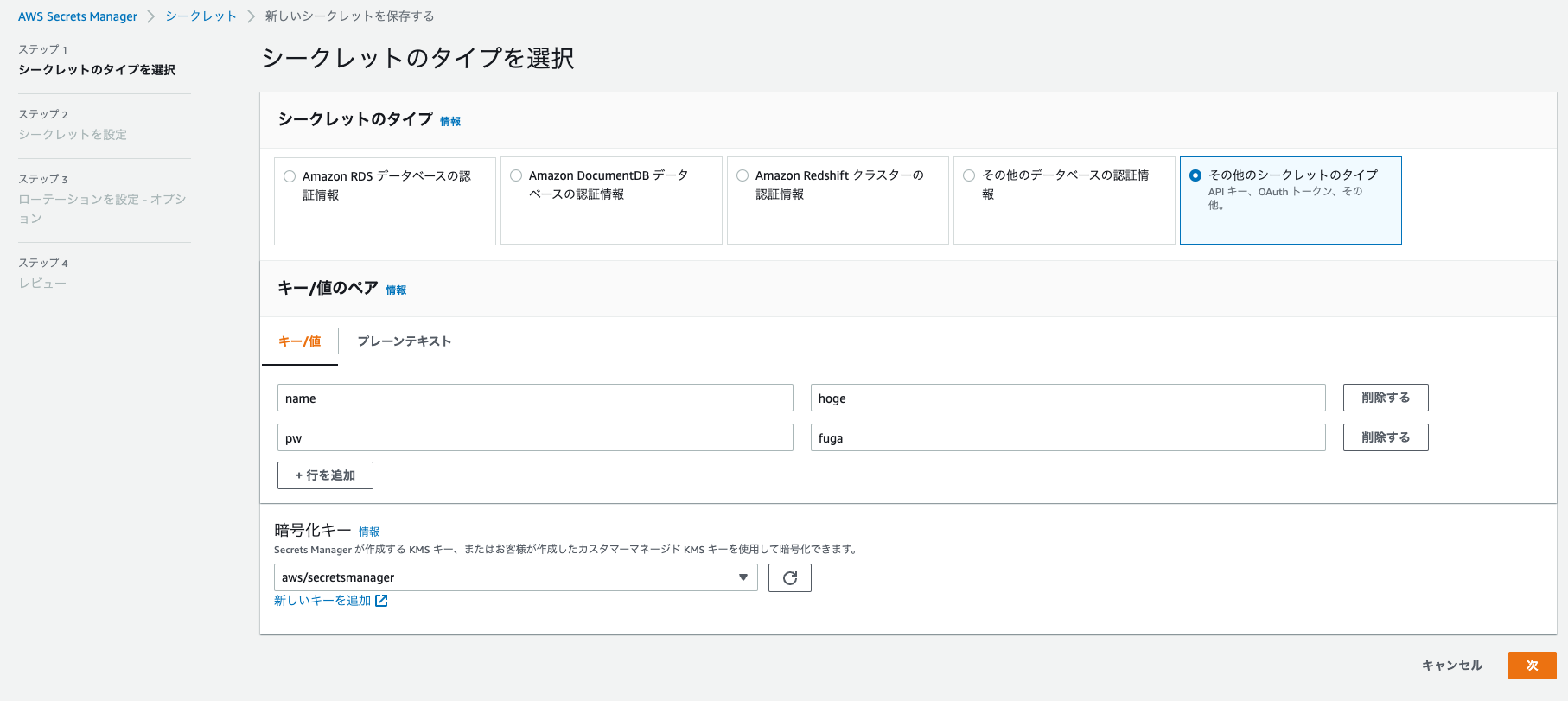
Node.jsランタイムのLambdaでNodeモジュールを使いたいときにやったこと
## はじめに
こんにちは。フリューでサーバサイド開発をしています、kitajimaです。最近CDKに入門しました。
弊チームでは先日、API Gateway + Lambdaの構成をCDKで構築し、APIを実装する機会がありました。その際Node.jsで書いたLambdaスクリプト単体をアップロードしたところ、`”Unable to import module”`が発生しました。
この記事ではその際対応したことを紹介させていただこうと思います。
同じようにNode.jsランタイムのLambdaを初めて構築してみたい方の参考になれば幸いです。※本記事と同様の内容を弊社テックブログでも掲載しております。
https://tech.furyu.jp/lambda-node-modules/## 環境
– AWS CDK v2
– CDK実装 TypeScript
– Lambdaランタイム Node.js 16.x
– Lambdaスクリプト実装 TypeScript## 状況再現
そのときのインフラ構成の一部を再現したものはこちらです。Constructは`aws_lam




