
- 1. kaggle 日記① titanic 演習
- 2. 【Python】【上級者向け】型絞り込み(type-narrowing)を使ったガード節は`isinstance(a, B)`ではできるけど`type(a) is B`ではできない
- 3. GridDBとPythonを用いた消費者購買パターンの探索
- 4. Python & ビット演算でドドスコしてみた
- 5. Python,Ruby,PHP,Java,JavaScript,PerlのPDF作成の比較
- 6. pythonで対数グラフ(それと聴覚閾値)
- 7. マイク入力音声をリアルタイムでFFTしてグラフ化する
- 8. 【Python】GoogleフォームにCSVデータをSeleniumで自動入力してみる
- 9. trioによる並行処理④(Nursery)
- 10. Pythonによる日付処理
- 11. 【Tweepy編】WordCloudでTweetを可視化して楽しもう
- 12. 【TwitterAPI申請編】WordCloudでTweetを可視化して楽しもう
- 13. python×SQLite – 行の存在確認
- 14. 【競技プログラミング】巡回セールスマン問題をやってみた【組合せ最適化】
- 15. 【競技プログラミング】巨大ナップサック問題をやってみた【組合せ最適化】
- 16. DjangoでXSS対策を確認してみた
- 17. 処理のレイヤーを意識する
- 18. 【Pythonista3】ActivityIndicatorの使い方
- 19. Blenderボーンコンストレイントを名前基準で一括設定
- 20. pythonシミュレーションでネット麻雀(天鳳、雀魂)の段位の比較をやってみた
kaggle 日記① titanic 演習
はやたすさんの動画を見ながら kaggle コンペの titanic を始めました。
リンク : https://www.youtube.com/watch?v=F3D75T_wW4w&list=PL4Y-mUWLK2t0Vy2sUIXK3ItMX0s7CvoB_&index=1
【Python】【上級者向け】型絞り込み(type-narrowing)を使ったガード節は`isinstance(a, B)`ではできるけど`type(a) is B`ではできない
## きっかけ
チームメンバーから「VSCode上でPythonを書いていて、型判定をコード上でしているのにPylanceが型絞り込みからのガード節をしてくれない」という相談を受けたときに行った回答や例をまとめておこうと思ったため、記事を書きました。## 型絞り込みについて
一般的なPythonの静的型チェッカー(`mypy`や`pyright`など)は、プログラムのコードフローの中でより正確な式の型を決定するtype-narrowing(型の絞り込み)を行なっています。
– これは`typing.TypeGuard`に関するPEPであるPEP647にも記載があります。https://peps.python.org/pep-0647/#motivation
ざっくばらんに言うと、「直和型(`typing.Union`)の変数に対して型判定の分岐を書いたら、その分岐に入る/入らない場合で変数に対して異なる型推論をしてくれるよ」というものです。
## 関数の要件
**「整数インスタンスまたは文字列インスタンスが渡される。0以上の整数または数字であれば`True`、それ以外
GridDBとPythonを用いた消費者購買パターンの探索
消費者行動を理解することは、マーケティング担当者が消費者の購買意欲を理解する上で重要です。消費者はそれぞれ独自の購買パターンを持っています。購買パターンを認識し、分析し、測定することで、企業はターゲットとする消費者をよりよく理解し、リーチを拡大できる可能性があるのです。
このブログで紹介しているソースコードのリポジトリはこちらです。
このブログの目的は、Google Merchandise Storeの顧客の購買行動をGridDBの力を使って分析することです。分析結果は、Googleアナリティクスデータの上にデータ分析を利用することを選択した企業にとって、より実行可能な業務改革やマーケティング予算の有効活用につながるかもしれません。
[ Jupyterファイル(全文)はこちら ][1]
チュートリアルの概要は以下の通りです。
1. データセット概要
2. 必要なライブラリのインポート
3. データセットの読み込み
4. データの
Python & ビット演算でドドスコしてみた
# 今更ドドスコ
こちらが話題になっていた2022年の夏、コロナに罹ってダウンしていたところ完全に乗り遅れてしまったので今更ながらやってみました。
リプで配列を使った例はよく見かけたので今回はPythonのビット演算で実装してみることにします。【問題】配列{"ドド","スコ"}からランダムに要素を標準出力し続け、『その並びが「ドドスコスコスコ」を3回繰り返したもの』に一致したときに「ラブ注入♡」と標準出力して終了するプログラムを作成せよ(配点:5点)
— ((?++)) (@Sheeeeepla) August 1, 2022
# やってみた
コードはこんな感じ。
“`python:ddsk.py
import randombuffer = 0
while True:
buffer = buffer << 1 & 4095 if random.getrandbits(1): buffer |= 1 print("ドド", end="") else: print("スコ", end="") if buffer == 2184: print("ラブ注入♡") bre
Python,Ruby,PHP,Java,JavaScript,PerlのPDF作成の比較
Python,Ruby,PHP,Java,JavaScript,PerlのPDF作成の比較
# Python
https://qiita.com/godan09/items/13866970972bf3a1c243
# Ruby
https://qiita.com/inoue9951/items/4498e5d130702d884352
# PHP
https://qiita.com/one_punch_man/items/bf140d4300195577dd3d
# Java
https://qiita.com/iceblue/items/a059c99ef1c17226a02a
# JavaScript
https://qiita.com/shuhei_sakiyama/items/ef68d49b7199d50a853b
# Perl
https://perlzemi.c
pythonで対数グラフ(それと聴覚閾値)
# 初めに
この数式って本当にこのグラフになるのかな?って不安になることってありますよね。
今回はそんな自分の不安にpythonで解決しようとした際に出た問題を記事にしています。# 問題
最小可聴値あるいは聴覚閾値と呼ばれるグラフを探した際に次のようなグラフが見つかりました。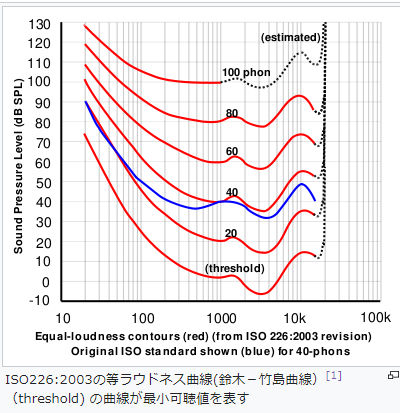
↑wikipediaよりこれをpythonで再現したい。
xが10の累乗のグラフなので、それが再現できるpythonのコードにしなくてはいけない。# コード
“`python
import matplotlib.pyplot as plt
import numpy as np
f = np.logspace(1,4,500000,base=10)
ath = 3.64*(f/1000)**-0.8-6.5*np.exp(-0.6*(f/1000
マイク入力音声をリアルタイムでFFTしてグラフ化する
# 初めに
この記事はガチでコードだけを置いておこうというやつです。
なので解説は行っていませんが悪しからず。# コード
“`python
import pyaudio
import matplotlib.pyplot as plot
import numpy as npdef audiostart():
audio = pyaudio.PyAudio()
stream = audio.open( format = pyaudio.paInt16,
rate = 44100,
channels = 1,
input_device_index = 1,
input = True,
frames_per_buffer = 1024)
return audio, streamdef audiostop(audio, stream):
stream.stop_stream()
stream.close()
audio.terminate()de
【Python】GoogleフォームにCSVデータをSeleniumで自動入力してみる
# はじめに
Webサイト上に大量のCSVデータを入力する必要があったので、Seleniumを使って自動入力してみました。折角なのでこの知識を忘れないよう備忘録として、Googleフォームを用いて疑似サイトを作って、フォームにCSVのデータをSeleniumで自動登録・回答するサンプルコードを作成しました。サンプル作成した[Googleフォーム](https://docs.google.com/forms/d/e/1FAIpQLSe-o70oaaAaSg1Ei_6i8hFQZTF6T6aBUAieb-FI3GN2_5MFpA/viewform?usp=sf_link)はこちらになります。今のところは削除予定がありませんので、よろしければ使ってみて下さい。
# 動作環境
* Windows 10
* Visual Studio code v1.70.2
* Python v3.9.1
* selenium v4.4.3# コード
サンプルコードの動作内容は、
1. CSVファイルアクセス
1. CSVデータ取得
1. Googleフォームアクセス
1. ログインデータ入力(模擬
trioによる並行処理④(Nursery)
前回:[trioによる並行処理③(move_on_after, move_on_at)](https://qiita.com/Kyosuke_Ichikawa/items/ab35c098e819316bdcf9)
[trio](https://trio.readthedocs.io/en/stable/index.html)の[Nursery](https://trio.readthedocs.io/en/stable/reference-core.html?highlight=Nursery#trio.Nursery)をもう少し深掘りします。
余談ですがNurseryは保育園とか苗床という意味のようです([参考](https://ejje.weblio.jp/content/nursery))。
保育園で子供(子タスク)をどんどん走らせるイメージでいると中々可愛いですね。## Nursery.start_soon()
[trioによる並行処理①](https://qiita.com/Kyosuke_Ichikawa/items/60955d36fa4c181c198e)の記事
Pythonによる日付処理
SageMakerからデータベースにクエリを投げる際にデータ年月日やテーブル名に日付を指定する必要が多々ある。
その際に目当てのテーブル名や日付のカラムの形式、データ期間の指定において、日付を変数化して操作したい場合があるため、備忘メモとしてここにまとめる。## 形式の変換(日付型→文字列型)
“`python
from datetime import dateTARGET_DATE = date(2022, 9, 29)
print(type(TARGET_DATE))
print(TARGET_DATE)
“`
``
`2022-09-29`“`python
# 形式の変換(文字列)
Ymd = TARGET_DATE.strftime(‘%Y%m%d’)
hyphen = TARGET_DATE.strftime(‘%Y-%m-%d’)
slash = TARGET_DATE.strftime(‘%Y/%m/%d’)
Ym = TARGET_DATE.strftime(‘%Y%m’)print(type(Ymd)
【Tweepy編】WordCloudでTweetを可視化して楽しもう
# はじめに
今回は[TwitterAPI申請編](#)の続きです。
Tweepyを導入して、実際に色々としてみましょう。
> Twitter APIの申請まだ終わってないよ、って方は前の記事参照です。# 目次
1. [TwitterAPI申請編](https://qiita.com/Pomerican/items/2232ad4253ed32d02465)
2. [Tweepy編](#) ⏪ 今回はココ!
3. 形態素解析・Mecab編
4. WordCloud表示編
5. 最終目標・Tweet可視化編# Tweepyを導入してTwitter APIで遊ぶ準備をする
ここからはPythonにTweepyを導入して、色々遊んでみましょう!### ① Pythonのバージョンを確認する
“`shell:バージョン確認パターン1
python -V
“`
“`shell:出力結果
Python 3.10.6
“`
もし、**command not found: python**が出力された場合、以下のことが考えられます。
1. Python自体をインストールしていない
【TwitterAPI申請編】WordCloudでTweetを可視化して楽しもう
# はじめに
**”条件にあったツイートを収集して、好きな画像を背景に可視化しませんか?”**Pythonを勉強した後に「次何しようかな」「何かサクッと面白いもの作れないかな」
なんて考えたことありませんか?
機械学習は難しいし、Webスクレイピングで何を取得するのが楽しいかな…みたいな。そこで、「Twitterで最も多く呟かれた単語(形態素)を解析して可視化してみよう。」
というわけです。—
Qiitaなどで記事を書くのは初めてなので、投稿へのアドバイスなどあれば教えてもらえると嬉しいです!
直接お伝えしたい質問などもお気軽にどうぞ!
【Twitter】
Tweets by PomericanCoffee# 最終目標
以下のような画像を生成するのが最終目標です。

上記の画像は、[5月に開
python×SQLite – 行の存在確認
# python×SQLite – 行の存在確認
PythonでSQLiteを使用した行の存在確認を行う。
| number | name | type1 | type2 |
| —- | —- | —- | —- |
152|チコリータ|くさ||
875|コオリッポ|こおり||
884|ジュラルドン|はがね|ドラゴン|# 結論
fetchoneメソッドの戻り値がNoneかどうかで判定する。
## ある場合
“`python
import sqlite3dbname = “pokemon.db”
connection = sqlite3.connect(dbname)
cursor = connection.cursor()cursor.execute(“SELECT number FROM pokemon WHERE number = ?;”, (152, ))
if cursor.fetchone() == None:
print(“0 rec”)
quit()rint(“more than 0”)
# -> more t
【競技プログラミング】巡回セールスマン問題をやってみた【組合せ最適化】
# 1.初めに
・アルゴリズムを学ぶために、競技プログラミングを始めました。
・AOJのコースをやっていくので、その備忘録を残します。https://qiita.com/kindamu24005/private/cc0cb1e2498ca7f0dad0
・前回は巨大ナップサック問題を解いたので、今回からは**新たなトピック**の「巡回セールスマン問題」を解いていきます。
# 2.巡回セールスマン問題
https://onlinejudge.u-aizu.ac.jp/courses/library/7/DPL/2/DPL_2_A
## 2.1問題
重み付き有向グラフ $G(V,E)$ について、以下の条件を満たす最短経路の距離を求めて下さい:– ある頂点から出発し、出発点へ戻る閉路である。
– 各頂点をちょうど1度通る。### 入力
$|V|$ , $|E|$ はそれぞれグラフ $G$ の頂点の数と辺の数を示す。グラフ $G$ の頂点にはそれぞれ $0, 1, …, |V|-1$ の番号が付けられている。$s_i$, $t_i$ はグラフ $G$
【競技プログラミング】巨大ナップサック問題をやってみた【組合せ最適化】
# 1.初めに
・アルゴリズムを学ぶために、競技プログラミングを始めました。
・AOJのコースをやっていくので、その備忘録を残します。https://qiita.com/kindamu24005/private/c7e07ff2e30a87115490
・前回は個数制限付きナップサック問題を解いたので、今回は「巨大ナップサック問題」を解いていきます。
# 2.巨大ナップサック問題
https://onlinejudge.u-aizu.ac.jp/problems/DPL_1_H
## 2.1問題
価値が $v_i$ 重さが $w_i$ であるような $N$ 個の品物と、容量が $W$ のナップザックがあります。次の条件を満たすように、品物を選んでナップザックに入れます:・選んだ品物の価値の合計をできるだけ高くする。
・選んだ品物の重さの総和は $W$ を超えない。価値の合計の最大値を求めてください。
### 入力
1行目に2つの整数 $N$、$W$ が空白区切りで1行に与えられます。 続く $N$ 行で $i$ 番目の品物の価値 $v_i$ と重さ
DjangoでXSS対策を確認してみた
## 環境
以下のサイトを参考に入力した値を取得するようにしています
https://docs.djangoproject.com/ja/4.1/intro/tutorial01/
https://bsf40.blogspot.com/2020/02/djangoform.html
## Djangoは自動でサニタイズをしている
結果としてはDjangoはデフォルトで文字列のサニタイズを行っているようでした
そのためHTMLタグを含んだ文
処理のレイヤーを意識する
# 処理のレイヤー
処理にはレイヤー、階層がある。
階層Aの処理は階層Aで行い、階層Bの処理は階層Bで行う。
このレイヤーがちゃんと分けられていないとコードが汚くなる。# たとえば関数
たとえば関数の処理である。
関数はレイヤーとみなすことができる。
よってその関数にはその関数の仕事があり、その関数以外の仕事は他のレイヤー(関数)に処理を任せる。たとえばファイル結合処理を行う関数を見てみよう。
“`py:
def join_files_to_stream(fout, fnames, last_newline=False):
for fname in fnames:
data = read_file(fname, last_newline=last_newline)
fout.write(data)
“`この時、関数の引数`last_newline`はオプションであり、ファイルデータの末尾に改行を付加するかどうかのフラグである。
現状は`read_file()`という関数にオプションを渡している。“`py:
def re
【Pythonista3】ActivityIndicatorの使い方
# Abstract
本記事では、日本語情報が皆無に近いPythonista3のuiモジュールの中でも特に情報が少ない`ui.ActivityIndicator`の使い方と注意点を共有します。本記事ではドキュメントに書かれている内容を日本語でサンプルコードと共に注意点を含めて紹介します。
## Pythonista3とは
(任意のPythonやってる人向け説明, リンクはApp store)
https://apps.apple.com/jp/app/pythonista-3/id1085978097
Pythonista3とは、Pythonが動く**スマホアプリ**です。それだけだと他の競合がいくつかありますが、Pythonista3はuiモジュールやsceneモジュールを提供しており、Pythonで比較的簡単に**スマホで動くGUIアプリを作ることができる**のです!!
1200円と少々高いですが、私は4,5年使っていますが価値はあったと十分に感じています。~~最近アプデがなくて不安です。~~## 前提
– uiモジュール自体の説明は省略します
– pyui
Blenderボーンコンストレイントを名前基準で一括設定
Blenderでリグを作成する場合に
実際にオブジェクトの変形に使うボーンと IK等の計算をするボーンを分けて作成する場合があります
そんな場合に「回転コピー」等のコンストレイントを一つ一つ設定するのは面倒なものです。
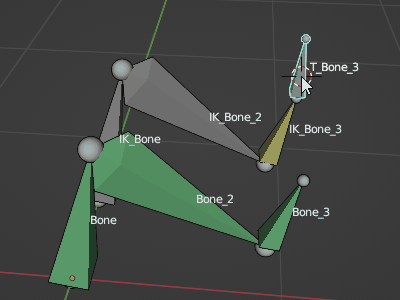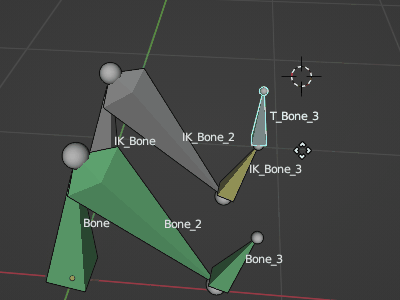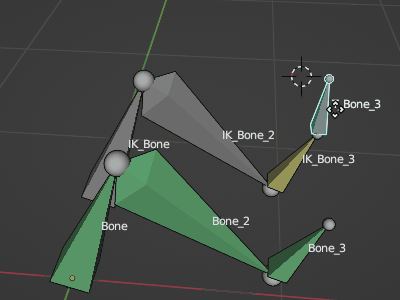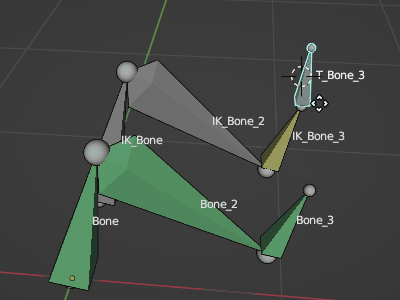そこで選択ボーンにコンストレイント設定するスクリプトを作成してみたのでメモ
(多分 探せばいっぱい出てくるだろうけれど 自分の学習目的です)“`py:
import bpy
target_hedder = “IK_” #設定のターゲットにしボーンに付いている接頭語
obj = bpy.context.active_object
bone_names = obj.data.bones.keys() #選択したオブジェクト内のボーン名の一覧
for pose_bone in obj.pose.bones:
if
pythonシミュレーションでネット麻雀(天鳳、雀魂)の段位の比較をやってみた
## 今回の試みのきっかけ
天鳳や雀魂といったネットで遊べる麻雀ゲームでは、段位という制度が存在し、天鳳では10級から10段、天鳳位まで、雀魂では初心、雀士、雀傑、雀豪、雀聖、魂天(各段位に1,2,3の小区分けがある)となっています。段位は上にいくにつれて昇段する難易度が上がっていきます。
ネット麻雀をプレイされる方の中には、両方プレイしている人もいたり、片方だけをプレイされる人もいたりと様々です。Twitter上の麻雀関係のコミュニティでは度々「天鳳と雀魂の段位はどう対応するのか」という話題が上がります。具体的には、天鳳7段と雀魂の魂天はどっちが強いのかとかそういう話です。ここに関しては主観的な議論が多く、定量的な分析はあまり行われてきませんでした。## 今回やること
テーマは「**天鳳と雀魂の段位を定量的に比較すること**」です。
これに対して様々なアプローチが考えられますが、今回の手法は以下のようなものになります。
1. 両ゲームの最高段位である天鳳位と魂天両方を達成した4名の成績を使用。
2. 4名それぞれについて、天鳳での成績を用いて天鳳での昇段確率、雀魂での成績を用いて




